









 本文提出了一种名为RW2AEAD的方法,针对属性网络的异常检测,结合结构、属性和组合信息,利用随机游走获取网络结构,SkipGram和CBOW模型提取特征,自编码器计算重构误差,有效检测异常节点。实验结果显示在BlogCatalog等四数据集上,RW2AEAD优于现有方法。
本文提出了一种名为RW2AEAD的方法,针对属性网络的异常检测,结合结构、属性和组合信息,利用随机游走获取网络结构,SkipGram和CBOW模型提取特征,自编码器计算重构误差,有效检测异常节点。实验结果显示在BlogCatalog等四数据集上,RW2AEAD优于现有方法。
The deep fusion of topological structure and attribute information for anomaly detection in attributed networks
unsupervised Anomaly Detection method in the attributed networks based on Random Walking AutoEncoder, RW2AEAD:基于属性网络的随机游走自编码器无监督异常检测方法
摘要:基于属性网络的异常检测因其在社交媒体、金融交易、网络安全等领域的广泛应用而受到越来越多的研究关注。然而,大多数现有的方法只考虑网络结构或属性信息来检测异常,忽略了网络中节点结构和属性的组合信息。文章提出了一种基于属性网络的游走式自编码器RW2EAD异常检测方法,该方法考虑了网络的结构和属性信息。它除了通过随机游走获取网络的结构信息外,还获取结构以及与其密切相关的属性的组合信息。然后,通过输入由SkipGram和CBOW组成的自编码器,得到节点的结构和组合重建误差。此外,通过多层属性自编码器获得节点的全局属性重建误差。最后,节点的异常评分综合考虑上述三种重建误差,通过设置阈值和评分排名来检测异常节点。实验表明,论文提出的RW2EAD算法的性能在四个真实数据集上优于其他基准算法。
1 Introduction
网络犯罪已经成为当今社会一个重要问题,异常检测是识别网络攻击的有效策略,其目标是识别与大多数预期模式显著不同的的稀少实例。传统的异常检测方法假设实例都是独立且分布相同的,但在许多实际场景中,实例之间往往是相互关联并以复杂网络的形式存在。与普通网络仅使用拓扑信息检测异常不同,属性网络为每个节点或边缘编码了丰富的属性特征集。例如在社交网络中,用户不仅通过各种社交活动相互交流,还有着丰富的个人信息。在属性网络中,异常检测有着广泛的应用,包括入侵检测、欺诈检测和故障诊断。
如何结合网络的拓扑结构和属性信息是基于属性网络异常检测的难题。传统异常检测方法主要是利用结构信息来检测异常,并不适用于属性网络的异常检测。现有的基于特征的方法假设基于节点特征的子集存在复杂异常,但只考虑网络的结构或属性信息,没有考虑网络结构信息和属性信息之间复杂的交互信息,导致检测性能不佳。此外,各个领域对异常的定义不尽相同,因此并没有对异常的统一定义。综上所述,目前基于属性网络的异常检测仍面临以下挑战:
(1)网络的稀疏性和数据的非线性:现实中属性网络的拓扑结构非常稀疏,节点和边的属性本质上是高度非线性的;
(2)节点异常的多样性:除了由于拓扑导致的节点异常外,节点本身的属性也可能导致节点异常;另外也可能因节点的结构和属性的组合而出现异常,因此需要一种综合检测三种异常的方法。
(3)数据集的异常缺乏标签:异常数据与正常数据的不平衡分布导致异常检测效率低下,因此异常检测方法需要在无监督的情况下有效定义属性网络中的异常。
基于以上挑战,利用节点结构和属性之间复杂的交互信息来检测异常更为合适。文章提出了一种基于属性网络的随机游走自编码器无监督异常检测方法RW2AEAD。首先构造原始网络的结构图和属性二分图,然后分别对这两个图进行遍历,得到游走路径,从而获得原始网络的结构信息和组合信息。接着将游走路径中每个节点的独热编码作为包含连续的SkipGram模型和CBOW模型的自编码器的输入,结构异常和组合异常节点得分定义为重构误差。由于上述组合异常分数只考虑了与结构密切相关的属性信息,因此通过属性自编码器重构节点的全局属性信息来定义其属性异常分数。最终节点的异常得分综合考虑了节点的结构异常、组合异常和属性异常,通过排序并设置阈值检测出异常节点。
文章的贡献主要如下:
(1)针对属性网络提出了RW2AEAD无监督异常检测方法,该方法综合考虑属性网络中结构、组合信息和节点的属性重构误差定义了节点的异常得分。
(2)提出了一种基于SkipGram模型和CBOW模型的游走式自编码器的属性图嵌入方法,有效获取网络中的结构特征以及结构和与其密切相关的属性的组合特征。
(3)RW2AEAD更好的利用节点的全局和局部结构、属性信息来检测异常。实验结果表明该算法在4个真实数据集上优于其他几种方法。
2 Related Work
在属性网络的异常检测中,以往主要关注图的拓扑特征或合并节点属性来检测异常模式;只有少数工作尝试使用网络嵌入来检测网络异常。现有的基于属性网络的异常检测方法主要分为三类:
(1)基于结构的方法:识别图结构中的稀有子结构,包括基于拓扑信息和属性内容的子结构。这些方法的主要区别在于所选子结构不同,常见的子结构包括社区和自我中心网络。
(2)基于残差的方法:从残差分析的角度对属性网络进行异常检测,目标是研究回归分析中真实数据与估计数据之间的残差;即异常检测中残差较大的实例更可能是异常的,因为它们的行为不符合大多数其他正常实例的模式。
(3)基于特征的方法:在构造的特征表示空间中检测异常节点。现有方法的主要区别在于特征表示方法和异常检测方法;常用的网络特征表示方法有图嵌入、子空间选择等,异常检测方法有分类、聚类和社区检测等。
现有的这些方法有以下不足:(1)忽略了正常和异常数据之间的不平衡分布;(2)将网络表示学习和异常检测分开训练;(3)使用浅层机制学习属性网络的特征表示;导致现有的异常检测方法在属性网络中表现较差。
3 Basic concepts
3.1 Related definitions
定义1 属性网络:,其中
为节点集且
;
为节点集且
;
为邻接矩阵,第
行向量
为节点
的结构信息;
为属性矩阵,第
行向量
为节点
的属性信息;同时,节点的邻接向量和属性向量也可以记作
。
问题阐述:给定一个属性网络 ,异常检测的任务是根据节点异常得分检测出与大多数节点显著不同的节点。具体来讲我们的目标是学习一个分数函数
并根据阈值
对样本进行分类,其中
为样本类标签,0为正常类,1为异常值:
3.2 Three anomalies in attributed networks
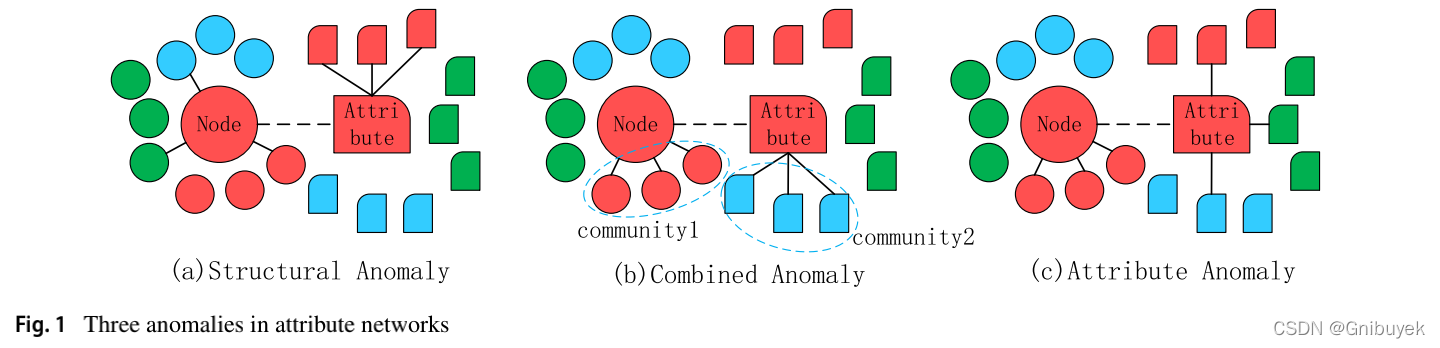
属性网络中节点的异常行为可以通过它的拓扑结构、属性信息和组合信息获取,即属性网络存在三种异常类型。如上图,分别用大圆和矩形突出异常节点及其相关属性,不同的颜色代表不同的群体;节点之间的箭头表示网络的边,属性之间的箭头表示在某种度量上的相似性:
(1)结构异常:节点与来自不同群体的节点连接,其属性与来自同一群体的属性连接,代表它与结构邻域是不一致的。
(2)属性异常:节点与来自相同群体的节点连接,其属性与来自不同群体的属性相似,代表它与属性邻域是不一致的。
(3)组合异常:节点在结构上属于群体1,在属性上属于群体2,但群体1和群体2是不同的,代表结构和属性的域是不一致的。
4 Attributed network anomaly detection based on walk-based autoencoder
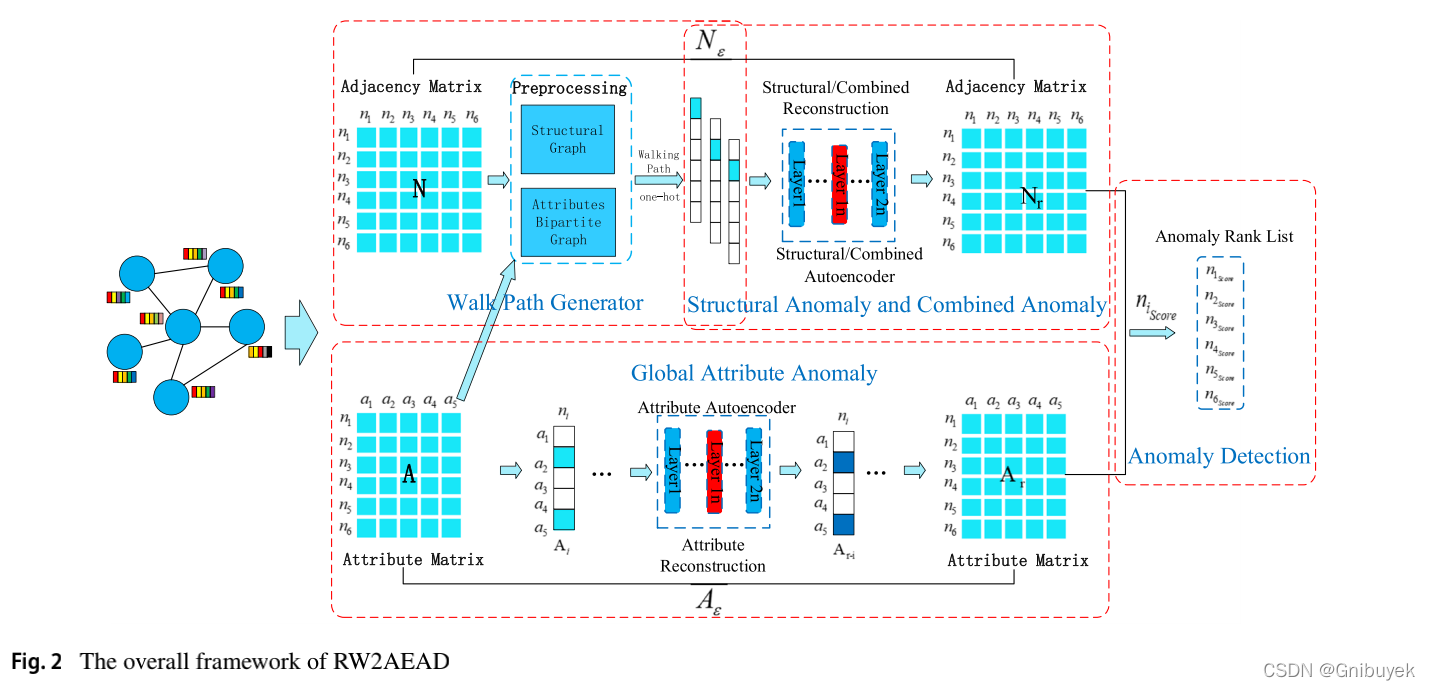
RW2AEAD框架的基本模块是自编码器,主要由四个基本组件组成:1)游走路径生成器:从原始网络生成结构图和属性二分图,接着分别在这两张图上游走并生成路径,从而获取网络的结构信息以及结构和与其密切相关的属性的组合信息;2)结构异常和组合异常:把游走路径中节点的独热编码作为SkipGram和CBOW组成的自编码器的输入,结构异常和组合异常定义为重构误差;3)全局属性异常:将节点的属性向量输入到属性自编码器中,节点的全局属性异常定义为重构损失;4)异常检测:综合结构异常、组合异常和属性异常定义节点的异常分数,通过排序和设置阈值进行异常检测。
4.1 Walk path generator
4.1.1 Structural graph and attribute bipartite graph
给定一个属性网络 并生成两张图:

(1)结构图: ,其中
为节点的子集,
中的节点成为结构节点,
为代表节点之间关系的边集。
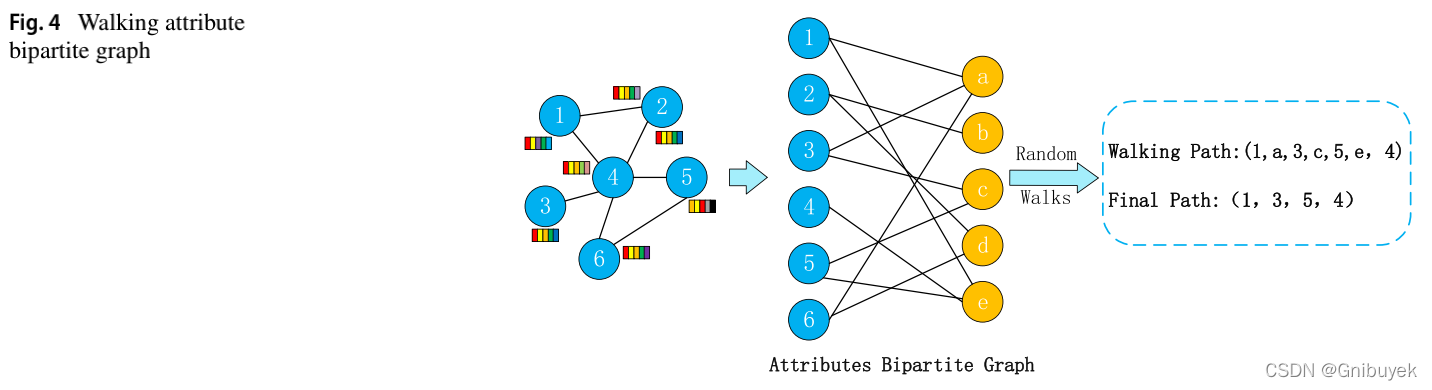
(2)属性二分图: ,其中
为与属性相关的顶点子集,
为与属性相关的属性子集,边集
将与属性相关的节点和与结构相关的属性连接起来。
属性二分图中节点之间的路径包含结构信息和属性信息,因为路径中的属性节点可以通过一些属性节点到达。即如果两个实体连接着相似的对象,则它们是相似的。比如在“用户-产品”二分图中,如果用户狗迷啊了同一个产品,则认为这两个用户是相似的。
4.1.2 Generate walking path
RW2AEAD在结构图 和属性二分图
上游走获得节点的游走路径。已有几种方法被证明能够根据原始网络生成的游走路径来获得节点的信息域。DeepWalk为每个节点生成一组随机漫步;node2vec引入两个参数
控制随机游走路径的跳跃概率,在生成游走路径中引入DFS和BFS,以保留不同的信息。如图3,当前停留在节点4,定义采样节点为
,下一个采样节点为
,定义其到邻居节点的转移概率为:
其中 表示节点到下一节点的转移概率,
代表从节点
到节点
的最短距离。当
时,随机游走偏向于距离更近的节点,使得来自同一集群的节点嵌入更紧密;当
时,随机游走倾向于让具有相同网络特征的节点更紧密地嵌入;当
时,node2vec的游走方式相当于DeepWalk。
在和
上执行不同的游走策略来生成游走路径,文章将DeepWalk中的游走策略标记为RandomWalks,node2vec中的游走策略标记为SelectWalks。在结构图
上使用SelectWalks策略生成游走路径。对于每个节点,执行长度为
的
以建立节点结构路径库
,
代表游走路径中第
个节点;因此
捕获了网络的局部和全局结构信息。如图3,从节点1开始执行长度为4的SelectWalks,得到最终游走路径
。
在属性二分图 上使用RandomWalks策略生成游走路径,节点的属性作为其他节点的跳转节点,获得与结构相关的属性和结构的组合信息。为了确保游走路径输入到相同的自编码器中,将节点属性从路径中删除。与
类似,在属性二分图
上执行长度为
的随机漫步
以建立节点组合路径库
,
代表游走路径中第
个节点;因此
捕获了网络结构和与其密切相关的属性的组合信息。如图4,从节点1开始,进行RandomWalks得到游走路径
,去掉属性之后得到
。
4.2 Structural anomaly and combined anomaly
将结构路径库中和组合路径库
的节点分别输入到结构/组合自编码器,通过重构误差得到节点的结构异常分数和组合异常分数。
4.2.1 Structural (combined) autoencoder
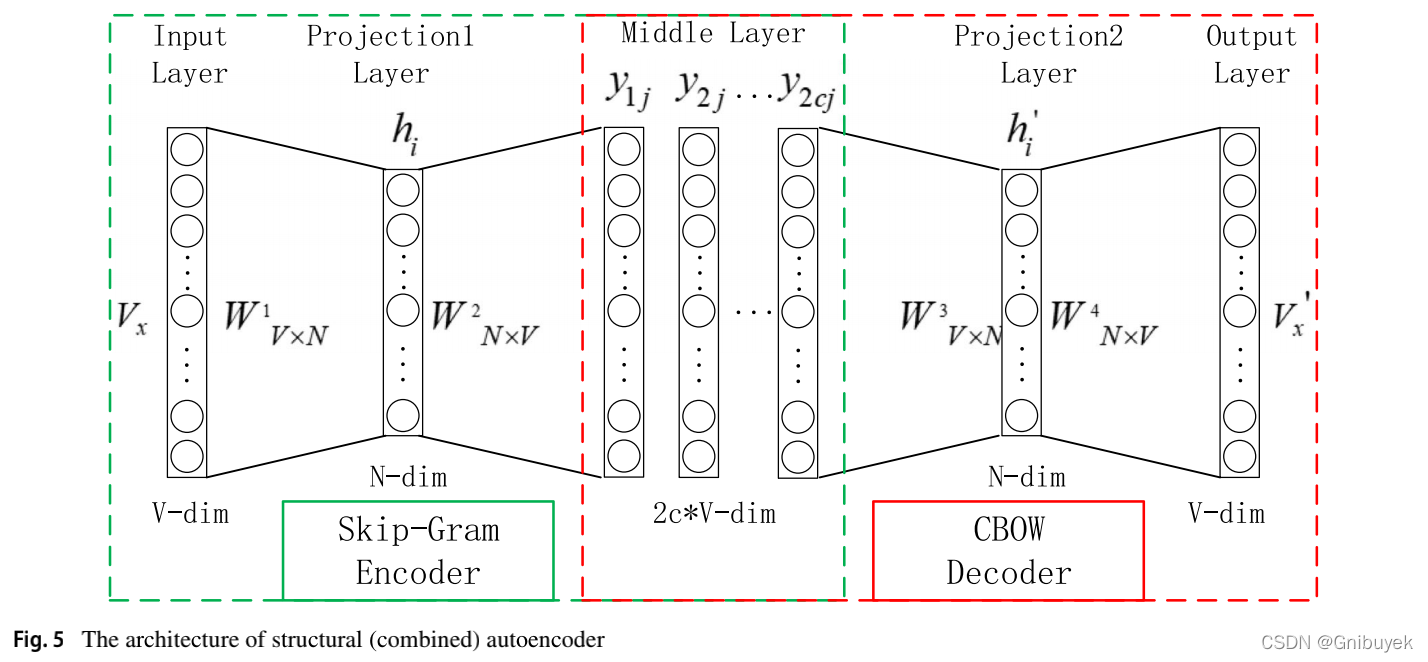
结构/组合自编码器的神经网络如图5所示,使用SkipGram作为编码器,CBOW作为解码器。在Word2vec词嵌入模型中,SkipGram根据给定的中心词预测上下文,CBOW根据给定的上下文预测中心词,结构/组合自编码器通过相同的编码结构哈夫曼树来共享SkipGram和CBOW。哈夫曼树根据节点频率进行编码,它们的训练过程是相反的。SkipGram比CBOW更准确,但CBOW在时间复杂度上比SkipGram低,它们可以相互促进,因此把它们结合到自编码模型以得到更高质量的图嵌入,这也是属性网络异常检测第一次使用这样的自编码器。
4.2.2 The ideas of structural (combined) anomaly detection
RW2AEAD模型中结构/组合自编码器的输入从 和
的游走路径获得(见算法1第6行-10行),从而得到节点的结构信息和组合信息,它们的异常分数分别定义为节点重构损失。具体的算法思想是:首先输入到SkipGram编码器中的节点
是一组独热编码向量;接着中间层通过投影层生成节点
上下文节点的独热编码
;然后
作为CBOW解码器的输入,输出层通过投影层后生成上下文节点的中心节点
的独热编码;最后通过节点
和节点
之间的距离定义其结构异常或组合异常。

4.2.3 Derivation of loss function
SkipGram编码器和CBOW解码器的优化目标是最大化节点的共现概率,即最大化目标节点与其结构或组合上下文节点的共现概率。结构/组合自编码器假设目标节点和上下文节点的概率是相互独立的。假设输入节点为 ,则SkipGram编码器的损失函数表示为:
其中 、
分别表示结构、组合游走路径中第
个节;
分别表示结构、组合游走路径中长度为
的上下文节点。例如
。
假设节点 被输入到SkipGram编码器,优化目标函数后最终生成的上下文节点为
,因此CBOW模型的损失函数为:
其中 ,
同理。同时,结构/组合自编码器通过重构来学习输入数据的潜在特征表征,输入层
近似等于
,结构/组合自编码器的重构损失函数如下,其中
:
综上,结构/组合自编码器总的损失函数表示如下,其中 为超参数:
4.2.4 Optimization of loss function
首先把SkipGram编码器的损失函数写成:
其中 是当
为结构上下文
的中心顶点时第
个顶点的概率,
是当
为属性上下文
中的中心顶点是第
个顶点的概率。这些概率可以通过softmax函数来计算,即
计算公式表示为:
其中 表示节点
的低维向量表示。因为通过softmax函数遍历
中所有节点的时间复杂度是很高的,为减小时间复杂度,使用分层softmax函数代替原始softmax函数。二叉树叶节点的分层结构通过哈夫曼树编码构造,因此叶节点
出现在结构上下文的概率表示为:
其中 表示树的深度;
是路径
中的节点,
为根节点,
。把上面两个式子代入到
的得到:
为路径
的节点,
为二叉树的根,
;
为路径
的节点,
为二叉树的根,
。同理优化分层softmax函数得到:
为路径
的节点,
为二叉树的根,
;
为路径
的节点,
为二叉树的根,
。
因此结构/组合自编码器的总损失函数为:
4.3 Global attribute anomaly
上一节中的组合异常只考虑了与结构密切相关的属性信息,但在复杂的属性网络中,仍存在着大量与结构无关的属性信息。论文利用属性自编码器重构节点的离散和连续属性,以获得网络的全局属性异常。
4.3.1 Encoding attribute information
属性网络中的属性信息是复杂多样的,为避免设计出的模型仅对特定的属性信息有效,文章将所有的属性转换为一个通用的向量表示,分为离散属性和连续属性:
(1)离散属性:即分类属性,如性别、年龄等。文章中节点的所有离散属性通过独热编码的形式表示为连续的向量表示,再对每个离散属性的独热编码进行拼接得到最终的离散属性特征向量。
(2)连续属性:属性网络中最常见的属性,如博客网络中的文本、图像、视频等。对于这种类型的连续属性,使用特定的方法转换为连续向量表示。例如:词袋模型通常用于获取文本的向量表示;TF-IDF算法对文本向量进行降噪处理,得到文本向量的实值表示。论文采用TF-IDF算法对具有属性网络数据集集中的文本属性进行处理。
将连续属性表示为真实值向量后,将节点的所有属性特征向量拼接在一起,得到网络中节点的最终属性特征向量。然后将每个节点的属性信息处理成相同维数的特征向量,缺少每一类属性的节点在对应的属性特征用0填充。
4.3.2 Attribute autoencoder
由于结构/组合自编码器只捕获与网络结构密切相关的属性异常,为了获得网络的全局属性异常,论文使用的属性自编码器与传统的三层自编码器网络不同,而是采用K层自编码器结构来获得网络的属性信息。
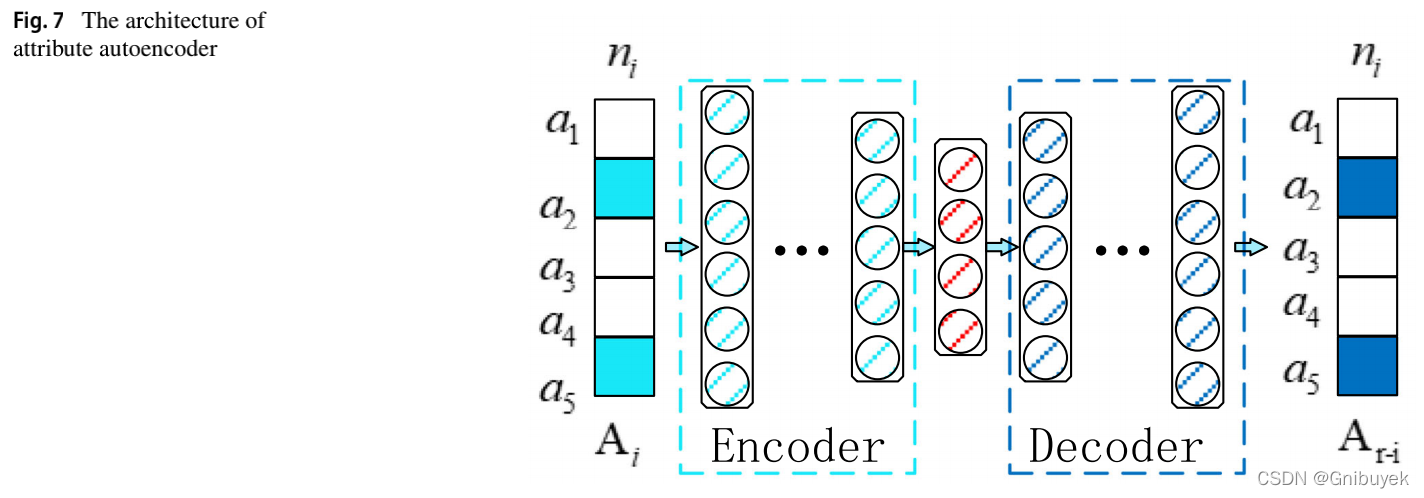
图7的自编码器使用了K层网络结构,公式定义如下,其中 为输入向量,K为编码器和解码器层数,
为激活函数(Relu函数),
分别表示第K层的权重矩阵和偏移向量,
表示第
个节点的低维向量表示:
论文将属性矩阵输入到K层属性自编码器网络中,通过最小化重构误差来优化自编码器的参数。假设输入的属性向量为 ,重构的属性向量为
,则属性自编码器的重构损失函数为:
自编码器的目标函数为: ;其中
为
正则化损失,防止过拟合,定义如下:
通过最小化优化属性自编码器,使用节点的属性重构误差
定义全局属性异常。
4.4 Anomaly detection
RW2AEAD的目标函数是最小化结构/组合自编码器和属性自编码器的总体损失,定义为:
利用随机梯度下降算法使L最小,即迭代优化和
两个耦合分量直到模型收敛。然后利用节点评分函数
进行评估,综合三种异常定义为:
其中 分别表示节点
的邻接向量和属性向量,
分别表示两个自编码器的重构向量,
为平衡参数。
最后根据函数 计算出各点的异常分数,通过设置阈值
检测异常节点:
4.5 Time complexity analysis
1)训练步骤:
结构/组合自编码器是SkipGram模型和CBOW模型的组合。对于每次训练,SkipGram模型的时间复杂度为 ,CBOW模型的时间复杂度为
,即模型总训练时间复杂度为:
其中 为窗口大小,
为嵌入维度,
是原始属性网络的节点数,
是结构图和属性二分图的节点数之和。因为
和
一般都不大,所以训练时间复杂度可以看作
。
属性自编码器的训练时间复杂度为 ,
是原始属性网络的节点数,因为
,所以训练步骤的总时间复杂度为
。
2)检测步骤:
5 Experiment and analysis
5.1 Experimental environment settings
系统为Ubuntu18.04.4,处理器为Intel Core:i7 -9700K 3.6GHZ、GPU为GeForce RTX 2080Ti,硬盘为SSD 2T,内存大小为16G DDR4,编程环境为Python3.6、tensorflow1.15、numpy1.16.6。
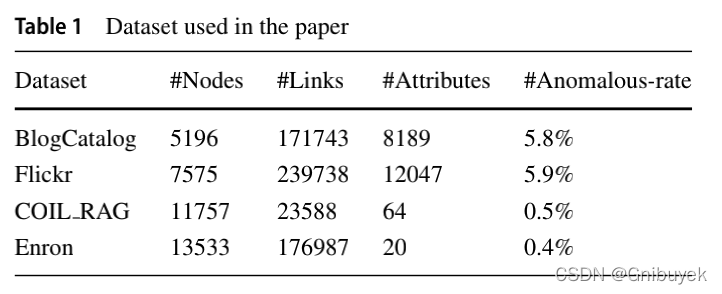
5.2 Dataset
BlogCatalog:博主可以相互关注,形成一个社交网络。利用博主的属性信息来描述用户和博客,作为节点属性。
Flickr:类似于Instagram,用户之间相互关注形成社交网络。用户的节点属性由用户选择的兴趣标签来定义。
COIL-RAG:图像数据集,使用meanshift算法将图像分割为相同颜色的区域,然后用节点表示区域使分割后的图像转换为邻接矩阵。节点的属性代表了对应的颜色直方图,邻接关系由边决定。
Enron:电子邮件通信网络,边表示人与人之间电子邮件的传递,每个节点包括20个描述电子邮件的属性,被广泛用作异常检测的基准,而垃圾邮件发送者即为异常。
5.3 Comparison method & parameter settings
1)对比方法
- LOF(2000):基于密度明显较低的异常检测,但只考虑网络属性信息
- SCAN(2007):基于网络结构聚类检测异常,但只考虑网络结构;
- Radar(2017):基于属性信息残差于网络结构信息一致性检测异常;
- ANOMALOUS(2018):使用CUR分解,基于属性选择和残差分析检测
- DeepAD(2020):属性网络中最新的无监督异常检测方法,基于GCN捕获网络结构和属性信息,通过重构误差检测离群值。
2)参数设置
平衡参数0.7、表示维度128、节点步数10步长80、窗口大小5;所有方法共享的参数设为相同的值,其余参数设为最佳默认值。
5.4 Evaluation indicators
AUC、Precision@K、Recall@K
5.5 Experimental results and analysis
5.5.1 Performance comparison of different anomaly detection methods
1)AUC值
LOF和SCAN是反向预测,COIL_RAG数据集上的Radar和ANOMALOUS方法也是反向预测。
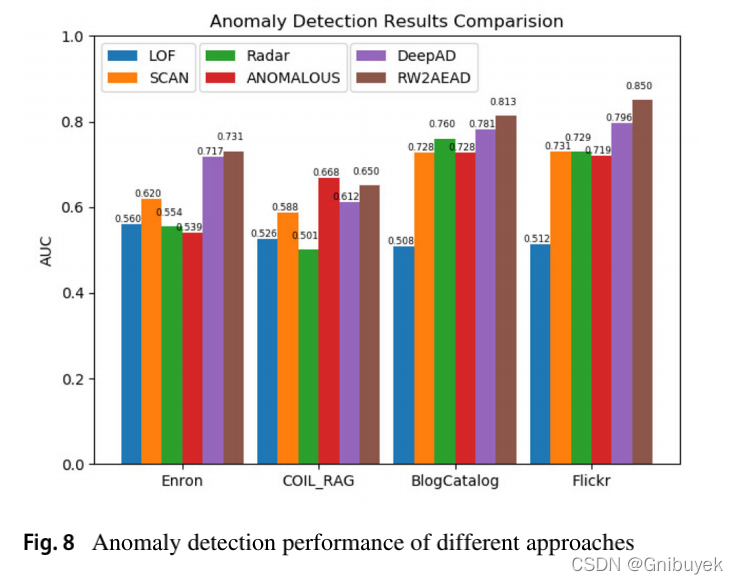
- RW2AEAD、Radar、ANOMALOUS和DeepAD都是同时考虑网络结构和属性信息的异常检测方法,可能是因为RW2AEAD还考虑了组合信息,因此总是得到最好的检测性能;
- SCAN在四个数据集中的表现都是最差,这是因为SCAN方法只考虑网络结构信息,尤其在属性丰富的网络中,如BlogCatalog和Flickr,性能会更差;
- LOF只考虑网络属性信息,SCAN只考虑网络结构信息,因此这两种方法在4个数据集上的AUC值都低于其他4种综合考虑网络结构和属性信息的方法。
- 4种综合考虑网络结构和属性信息的方法RW2AEAD、Radar、ANOMALOUS和DeepAD在丰富属性网络BlogCatalog和Flickr数据集中表现出的AUC值要高于普通属性网络COIL_RAG和Enron数据集上的表现。
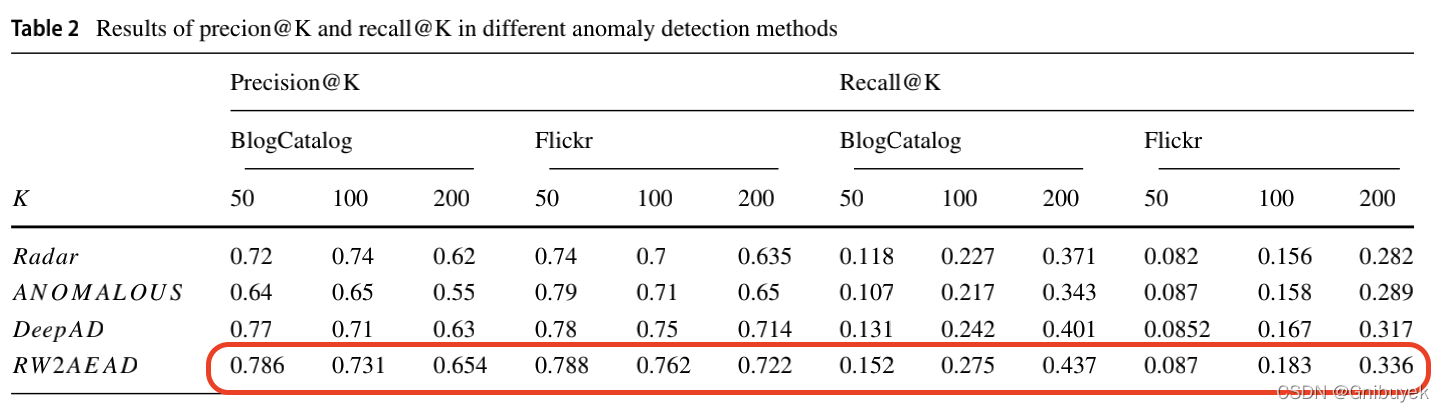
2)Precision@K、Recall@K
由于COIL_RAG和Enron数据集的异常率较低,由图8可以得出:综合考虑网络结构和属性的4种方法在数据集BlogCatalog和Flickr上的性能远远高于数据集COIL_RAG和Enron;因此这部分实验只在数据集BlogCatalog和Flickr上进行比较。除了数据集Flickr上的Precision@50,RW2AEAD的Precision@K 和 Recall@K 都高于其他方法。
5.5.2 Parameter sensitivity
1)不同数据集异常率敏感性分析
由于上述数据集没有异常标注,通过异常注入来生成。利用[30]干扰属性网络的拓扑结构产生结构异常,利用[31]从属性的角度生成属性和组合异常。首先随机选取个节点作为属性干扰的候选节点,对于每个选中的节点
,从数据集中随机选取另外k个节点,通过最大化欧氏距离
,选择属性与节点
偏离最大的节点
,将 节点
的属性
改为
。实验设置k为50,数据集BlogCatalog和Flickr分别注入6%、12%、24%和48%的异常率;数据集COIL_RAG和Enronr分别注入0.5%、1%、2%和4%的异常率。
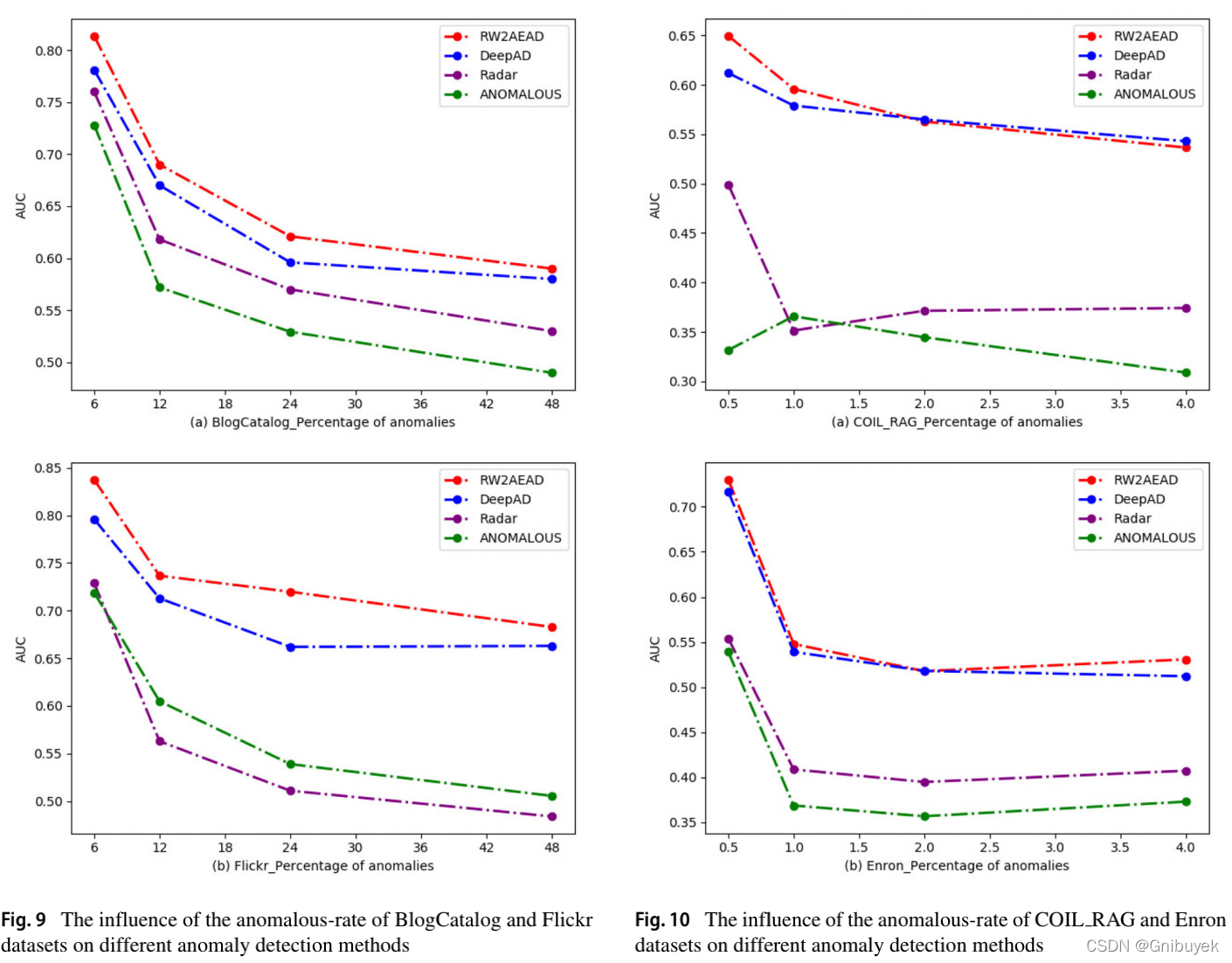
(1) 除了异常率2%的数据集COIL_RAG和Enronr,4%的数据集COIL_RAG,RW2AEAD的AUC值都是最好的;
(2)在数据集BlogCatalog和Flickr中4种异常检测方法的AUC值随异常率的增加而减少,除了DeepAD方法应用在异常率24%-48%的数据集Flickr上的情况;
(3)在数据集COIL_RAG上,RW2AEAD的和DeepAD方法的AUC值随数据集异常率的增加而减少;Radar的AUC值随异常率的增加先减小后增大,当异常率为1%时,AUC达到最低值;ANOMALOUS的AUC值则先增大后减少,在异常率为1%达到最高值;
(4)在数据集Enronr上,RW2AEAD、Radar和ANOMALOUS的AUC值随数据集异常率的变化先增大后减小,当在异常率为2%达到最低值;DeepAD随异常率的增加而减少;
综上,不同数据集的异常率对不同异常检测方法有不同的影响规律,没有一致性。
2)平衡控制参数敏感性分析
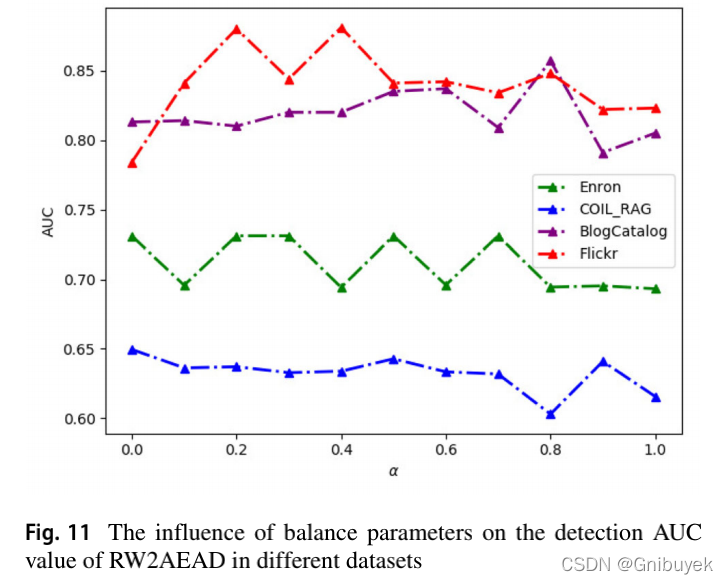
(1)在两种极端情况下,对于具有丰富属性网络数据集BlogCatalog和Flickr无法获得最佳的检测性能。其中,只考虑了网络结构和组合异常;
只考虑了网络属性异常。但在数据集Enronr和Flickr上
得到了较好的表现,这可能是因为这两个数据集中的属性信息大部分与结构相关;
(2)RW2AEAD在4个数据集Enron、COIL_RAG、BlogCatalog和Flickr上分别在,
,
,
得到最好的表现。
(3)综上说明了综合考虑网络结构、属性和组合异常对属性网络异常检测的重要性。
6 Conclusion
论文综合考虑了结构、属性和组合信息来检测属性网络上的异常,提出一种叫做RW2AEAD游走式自编码器异常检测。具体地说主要包括三部分:第一步通过遍历结构图和属性二分图得到游走路径,并将其输入到由SkipGram和CBOW组成的自编码器中得到节点的结构重构误差以及与结构密切相关的组合重构误差;第二部通过多层属性自编码器网络得到节点的全局属性重构误差;第三部综合考虑结构、组合和全局属性重构误差来定义节点的异常得分,通过排序和设置阈值来检测异常节点。实验结果表明,论文提出的RW2AEAD方法在属性网络上的检测性能优于现有的最佳异常检测方法。
不足:只考虑了静态属性网络。

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









