







基于CDH 6.3.0 搭建 Hive on Spark 及相关配置和调优 Hive默认使用的计算框架是MapReduce,在我们使用Hive的时候通过写SQL语句,Hive会自动将SQL语句转化成MapReduce作业去执行,但是MapReduce的执行速度远差于Spark。通过搭建一个Hive On Spark可以修改Hive底层的计算引擎,将MapReduce替换成Spark,从而大幅度提升计算速度。接下来就如何搭建Hive On Spark展开描述。 注:集群使用的是CDH6.3.0,使用的Spark版本是2.4.0,使用的集群配置为5个NodeManager节点,每台内存62.8G(64G),cpu 32 Core。
配置Spark 给Yarn分配完资源后,需要配置一些Spark的参数,设置Spark可使用的资源。包括executor和Driver的内存,分配executor和设置并行度。
1) 配置executor内存
在配置executor的内存大小的时候,需要考虑以下因素: 增加executor的内存可以优化map join。但是会增加GC的时间。在某些情况下,HDFS客户端没有并行处理多个写请求,在有多个请求竞争资源的时候会出现一个executor使用过多的core。尽可能的减少空闲的core的个数,cloudera推荐设置spark.executor.cores为4,5,6,这取决于给yarn分配的资源。本集群有155个core可用,将spark.executor.cores设置为5,这样155/5余数为0,设置为6的话会剩余5个空闲,设置为4的话有3个空闲。这样配置之后可以同时运行31个executor,每个executor最多可以运行5个任务(每个core一个)。 spark.executor.memory,hive中设置,代表Hive 在 Spark 上运行时每个 Spark 执行程序的 Java 堆栈内存的最大大小,本集群设为8G,该值不能太大也不能太小,都会导致任务直接失败。executor执行的时候,用的内存可能会超过该值设置的大小,所以会为executor额外预留一部分内存。spark.yarn.executor.memoryOverhead(hive中设置)代表了这部分内存,本集群设置为2G。 yarn.scheduler.maximum-allocation-mb这个参数表示每个container能够申请到的最大内存,一般是集群统一配置。Spark中的executor进程是跑在container中,所以container的最大内存会直接影响到executor的最大可用内存。但是当设置一个比较大的内存时,日志中会报错,同时会打印这个参数的值。还有一点是要spark.yarn.executor.memoryOverhead和spark.executor.memory的和不能超过yarn.scheduler.maximum-allocation-mb(yarn参数)设置的值。本集群scheduler请求最大内存分配的是60G,即某些情况下允许所有可用内存都给某一个executor使用,预留2.8G给系统。
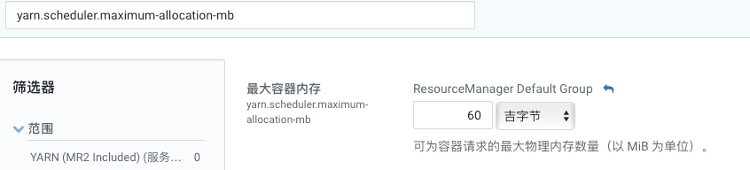
2) 配置Driver内存
SparkDriver 端的配置如下:
spark.driver.memory:当hive运行在spark上时,driver端可用的最大Java堆内存。
spark.yarn.driver.memoryOverhead:每个driver可以额外从yarn请求的堆内存大小。这两个参数和就是yarn为driver端的JVM分配的总内存。
Spark在Driver端的内存不会直接影响性能,但是在没有足够内存的情况下在driver端强制运行Spark任务需要调整。本集群分别设置为3G和1G。
3) 动态分配executor(hive中设置)
设置spark.executor.instances到最大值可以使得Spark集群发挥最大性能。但是这样有个问题是当集群有多个用户运行Hive查询时会有问题,应避免为每个用户的会话分配固定数量的executor,因为executor分配后不能回其他用户的查询使用,如果有空闲的executor,在生产环境中,计划分配好executor可以更充分的利用Spark集群资源。
Spark允许动态的给Spark作业分配集群资源,cloudera推荐开启动态分配,本集群也开启该设置。

4) 设置并行度
为了更加充分的利用executor,必须同时允许足够多的并行任务。在大多数情况下,hive会自动决定并行度,但是有时候我们可能会手动的调整并行度。在输入端,maptask 的个数等于输入端按照一定格式切分的生成的数目,HiveOn Spark 的输入格式是CombineHiveInputFormat,可以根据需要切分底层输入格式。调整hive.exec.reducers.bytes.per.reducer控制每个reducer处理多少数据。但是实际情况下,Spark相比于MapReduce,对于指定的hive.exec.reducers.bytes.per.reducer不敏感。我们需要足够的任务让可用的executor保持工作不空闲,当Hive能够生成足够多的任务,尽可能的利用空闲的executor。
-
G1 GC 调优
参数配置的位置:spark-defaults.conf,在 spark 配置中查看如下:
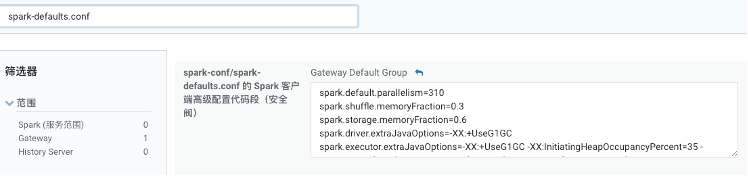
具体属性名称为:spark.executor.extraJavaOptions,在“=“后面添加相关属性,本次调优中加入的参数如下:
spark.executor.extraJavaOptions=-XX:+UseG1GC
-XX:InitiatingHeapOccupancyPercent=35
-XX:ConcGCThreads=20 -XX:+PrintFlagsFinal
-XX:+PrintReferenceGC
-verbose:gc -XX:+PrintGCDetails
-XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
-XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
-XX:NewRatio=1
本次针对调优的sql为:

在executor页面查看显示GC占用运行时间超过10%至30%以上,严重影响程序运行效率,通过分析sql本身和gc信息发现,新生代对象很对,占用空间很大:
在新生代空间不足的情况下会放到老年代,容易触发full gc,因此将NewRatio参数调至1,有效缓解。也试过将参数调至1以下,但是会导致程序挂起长时间不执行,原因未知。另外考虑到本例中子查询数据量很大,在G1调优时适当的增加spark.executor.memory的值。
完整的G1参数和说明如下:
| 选项/默认值 | 说明 |
| -XX:+UseG1GC | 使用 G1 (Garbage First) 垃圾收集器 |
| -XX:MaxGCPauseMillis=n | 设置最大GC停顿时间(GC pause time)指标(target). 这是一个软性指标(soft goal), JVM 会尽量去达成这个目标. |
| -XX:InitiatingHeapOccupancyPercent=n | 启动并发GC周期时的堆内存占用百分比. G1之类的垃圾收集器用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比. 值为 0 则表示"一直执行GC循环". 默认值为 45. |
| -XX:NewRatio=n | 新生代与老生代(new/old generation)的大小比例(Ratio). 默认值为 2. |
| -XX:SurvivorRatio=n | eden/survivor 空间大小的比例(Ratio). 默认值为 8. |
| -XX:MaxTenuringThreshold=n | 提升年老代的最大临界值(tenuring threshold). 默认值为 15. |
| -XX:ParallelGCThreads=n | 设置垃圾收集器在并行阶段使用的线程数,默认值随JVM运行的平台不同而不同. |
| -XX:Cnotallow=n | 并发垃圾收集器使用的线程数量. 默认值随JVM运行的平台不同而不同. |
| -XX:G1ReservePercent=n | 设置堆内存保留为假天花板的总量,以降低提升失败的可能性. 默认值是 10. |
| -XX:G1HeapReginotallow=n | 使用G1时Java堆会被分为大小统一的的区(region)。此参数可以指定每个heap区的大小. 默认值将根据 heap size 算出最优解. 最小值为 1Mb |
| -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy | 这些参数用来在stdout中打印gc相关信息,用于查看JVM中垃圾回收情况 |















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









