







补充一下MCAN-VQA:

对图片的处理:首先输入图片到Faster R-CNN,会先设定一个判断是否检测到物体的阈值,这样动态的生成m∈[10,100]个目标,然后从检测到的对应的区域通过平均池化提取特征。第i个物体特征表示为:![]() ,所以一张图片就被表示为一个特征矩阵:
,所以一张图片就被表示为一个特征矩阵:![]() 。
。
对问题的处理:首先分成词,最多分为14个词,然后用300-D GloVe word embeddings变成向量,然后过LSTM,使用LSTM所有单词的输出,得到问题特征矩阵:![]() ,n是分成的单词个数。
,n是分成的单词个数。
m和n可能不一样,用0填充到max(m,n)。
然后有了图片和问题的特征矩阵X和Y,送入下面的Deep Co-Attention Learning模块,由L层MAC层堆叠![]() 。
。
这个MAC层分为两种,stacking和encoder-decoder,和transformer很像,大概如下图:
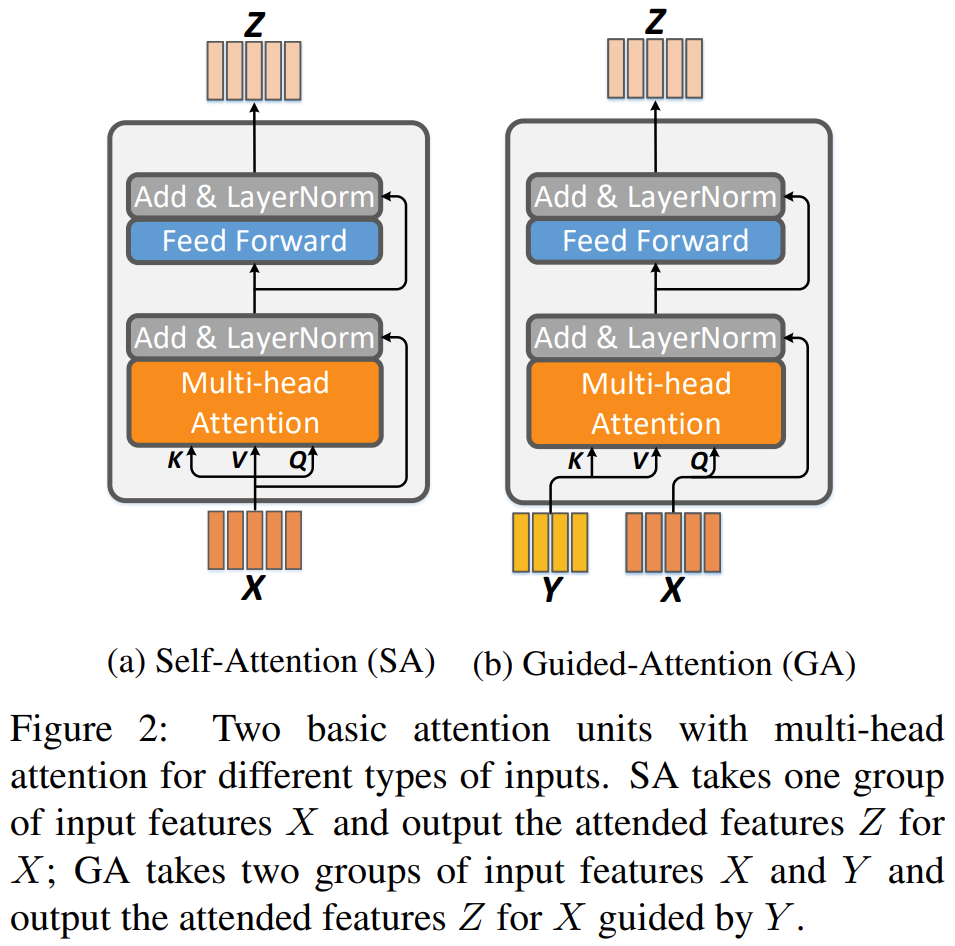


Deep Co-Attention Learning模块输出的![]() ,
,![]() ,送入Multimodal Fusion and Output Classifier模块,这个模块有个两层的MLP
,送入Multimodal Fusion and Output Classifier模块,这个模块有个两层的MLP![]() ,做attention reduction
,做attention reduction

![]()
α是学习到的权重。
然后线性多模态融合:
![]()
![]()
得到Z之后后面就是做分类,sigmoid。
一些实验结果:
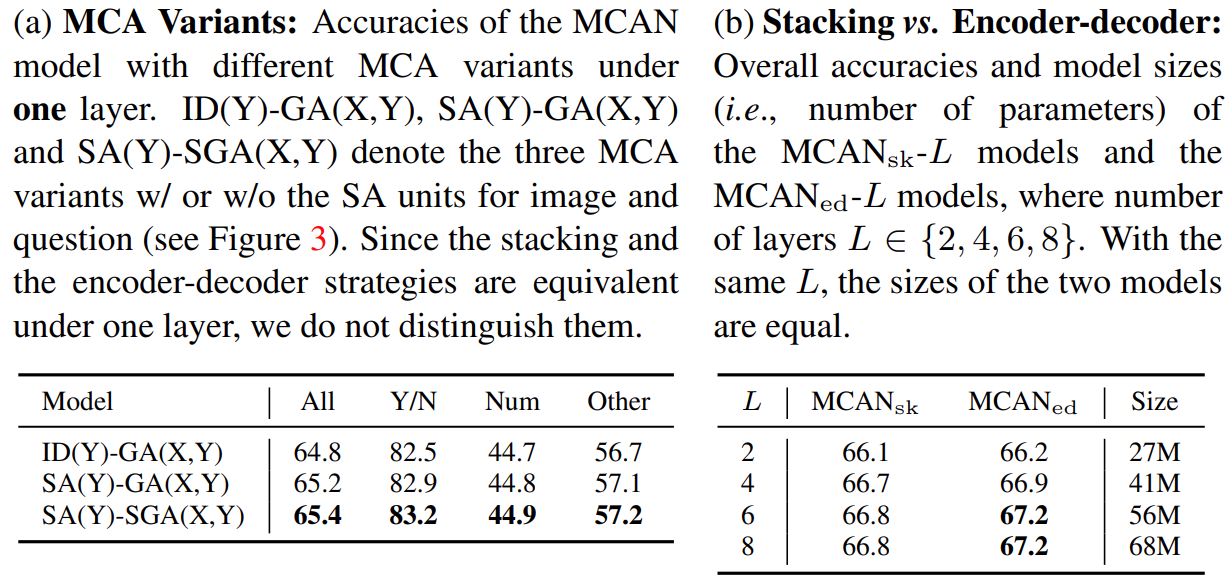
所以SA(Y)-SGA(X,Y)比较好,Encoder-decoder比较好。














 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









