







吴恩达-从人类反馈中进行强化学习RLHF
https://www.bilibili.com/video/BV1R94y1P7QX?p=1&vd_source=e7939b5cb7bc219a05ee9941cd297ade

1、公开的LLM,Llama2,
使用LLM对同一个提示产生多个不同输出,然后人类评估这些输出。评估方法是对比两个输出,找出他们喜欢的那个。于是形成的就是偏好数据集。preference dataset。数据集捕捉的是标注员的偏好而不是人类整体的偏好。偏好数据集比较难建立,取决于你希望你的模型更积极还是更有用。
2、用这个偏好数据集训练奖励模型。
通常奖励模型是另一个LLM。
推理阶段,奖励模型接收一个提示和答案,返回一个标量值,这个标量值表明了答案有多好。奖励模型本质上是一个回归模型,输出数字。
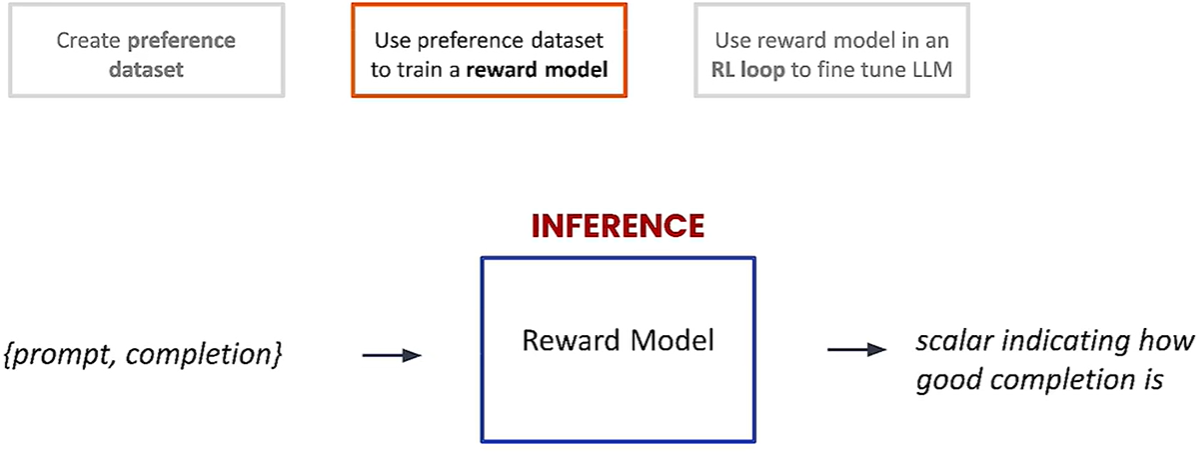
输入是三元组:(提示,完成1,完成2),输出一个分数。
损失函数:分数的结合

第二个数据集,提示数据集
强化学习:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









