







深入解析文本生成技术:从基础原理到前沿应用
深入解析文本生成技术:从基础原理到前沿应用

一、文本生成技术概述
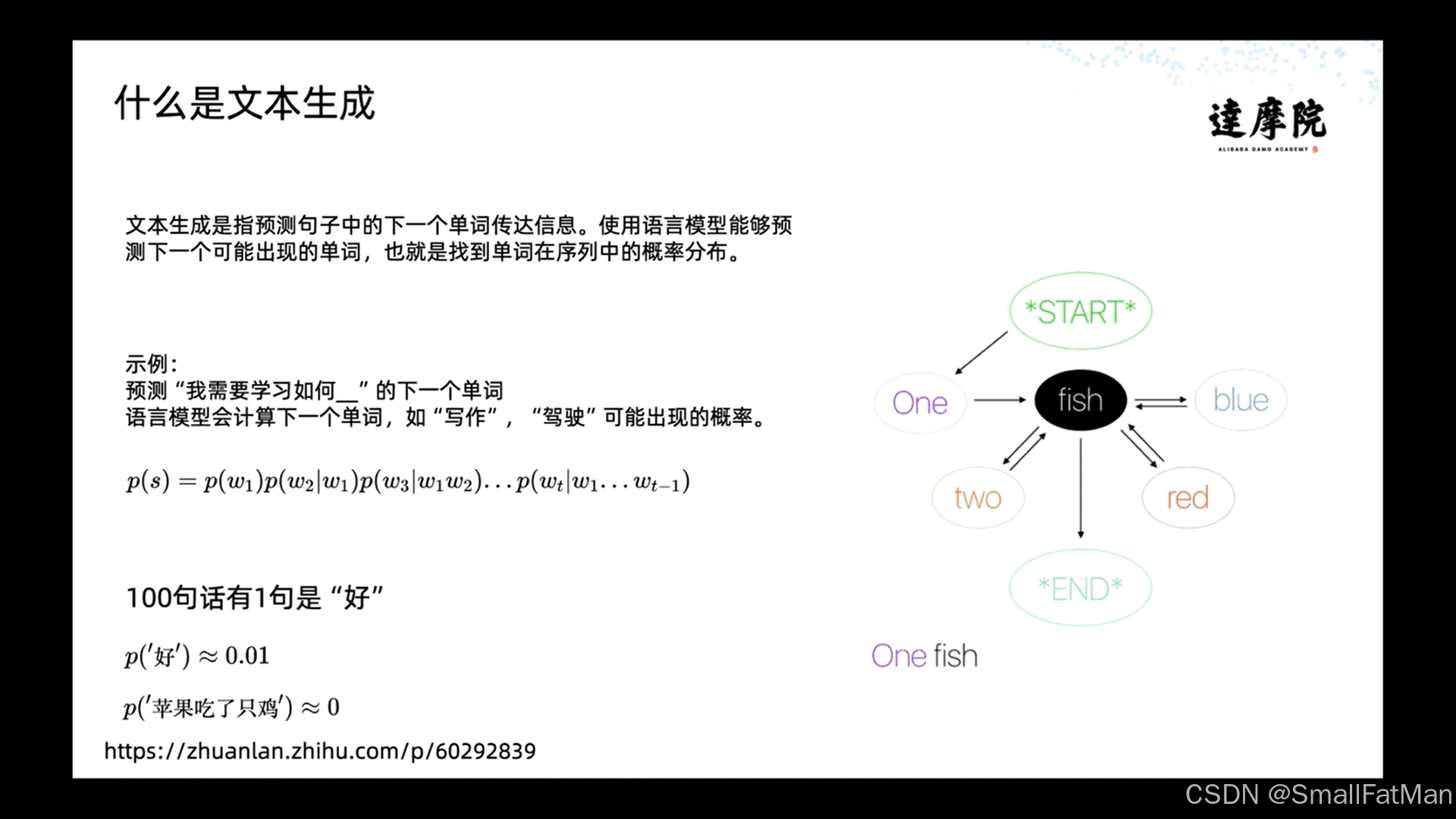
文本生成(Text Generation)是自然语言处理(NLP)领域的核心技术之一,其本质是通过语言模型预测句子中下一个可能出现的词语,从而生成连贯的文本内容。这一过程可以形式化表示为:
[ p(s) = p(w_1)p(w_2|w_1)p(w_3|w_1w_2)\ldots p(w_t|w_1\ldots w_{t-1}) ]
基础示例:
- 给定前缀:“我需要学习如何__”
- 模型可能预测:
- “写作”(概率0.15)
- “驾驶”(概率0.12)
- “编程”(概率0.08)
文本生成的质量可以通过概率分布来评估,例如:
- 合理句子:“今天天气真好”(p≈0.01)
- 不合理句子:“苹果吃了只鸡”(p≈0)
二、文本生成的核心方法



1. 基于统计的语言生成
基于统计的方法采用n-gram语言模型,利用马尔科夫假设简化概率计算:
[ p(w_t|w_1\ldots w_{t-1}) \simeq p(w_t|w_{t-k}\ldots w_{t-1}) ]
特点:
- n-gram模型:k=1(unigram),k=2(bigram)等
- 局限性:
- 难以捕捉长距离依赖关系
- 存在长尾效应(低频词生成困难)
- 需要平滑处理解决数据稀疏问题
2. 基于神经网络的语言生成
现代文本生成主要采用深度学习方法:
| 方法类型 | 原理 | 典型模型 |
|---|---|---|
| RNN-based | 当前词生成依赖前一个隐藏状态 | LSTM, GRU |
| Transformer | 通过自注意力机制回顾所有已生成词 | GPT系列 |
| Seq2Seq | 编码器-解码器结构处理非对齐文本 | Transformer, ConvS2S |
| VAE-based | 学习隐空间概率分布生成文本 | VAE-LSTM |
| GAN-based | 生成器与判别器对抗训练 | SeqGAN |
| 非自回归 | 并行生成不依赖前面词语 | NAT |
3. 依据规划的语言生成
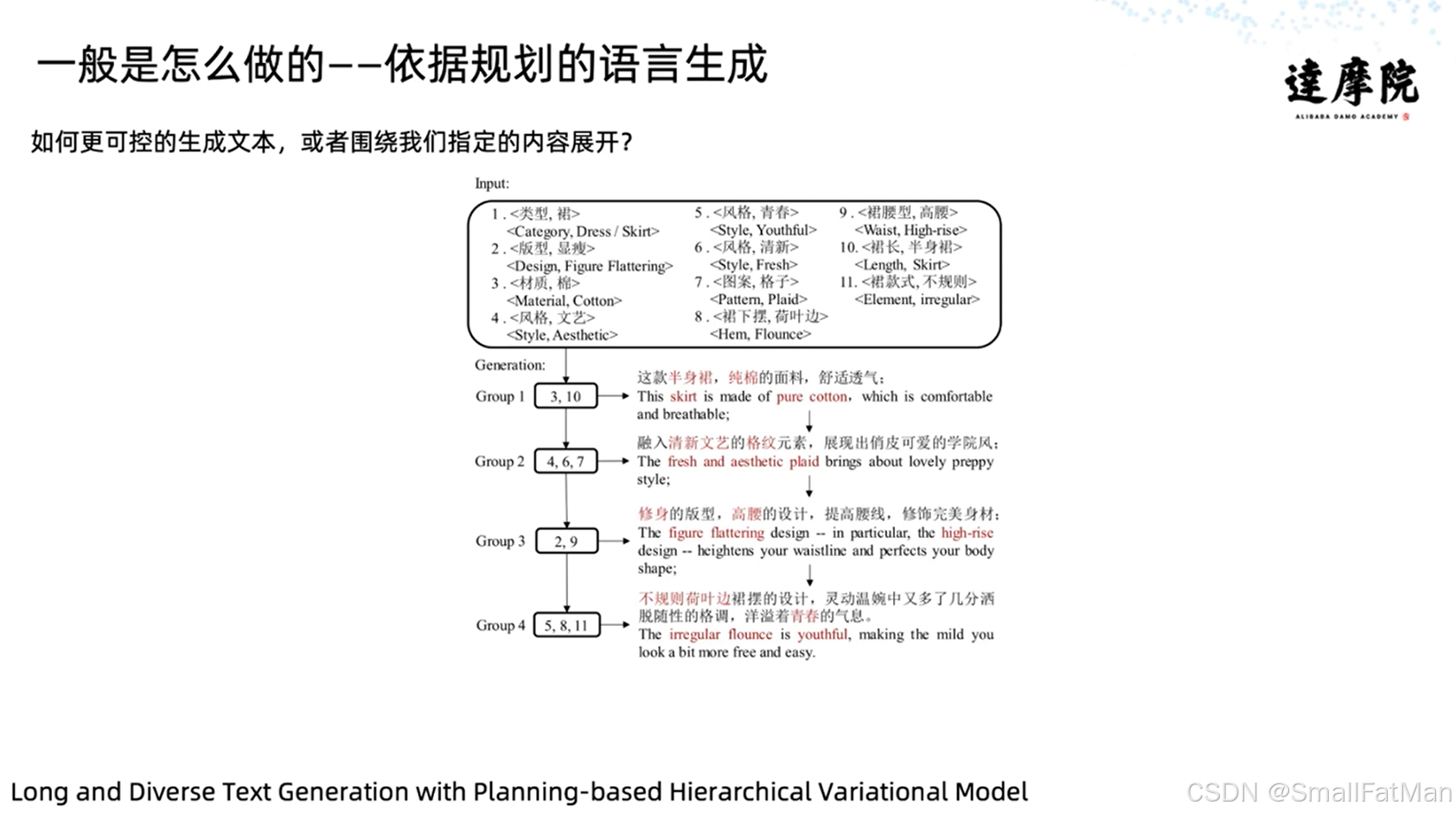
为提升生成内容的可控性,可采用结构化规划方法:
示例流程:
-
输入结构化属性:
- 类型:裙子
- 版型:修身
- 材质:纯棉
- 风格:清新文艺
-
分组整合属性:
Group1 = [材质, 长度] Group2 = [风格, 图案] -
生成描述文本:
“这款纯棉半身裙采用修身版型,清新文艺的格子图案展现俏皮风格,高腰设计修饰身材曲线…”
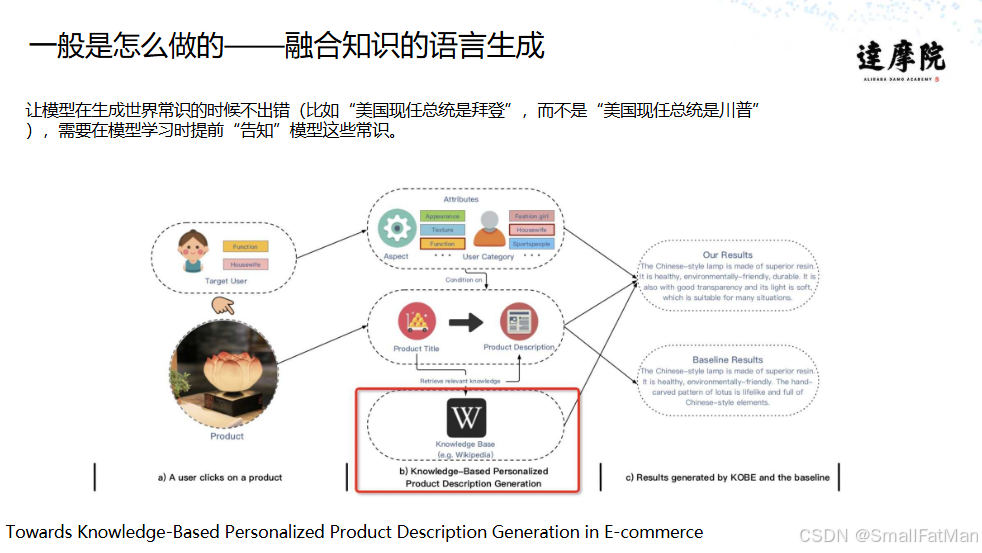
4. 融合知识的语言生成
将外部知识融入生成过程,确保事实准确性:
电商产品描述生成案例:
-
知识源:产品属性数据库
-
基线模型输出:
“这款中国风灯具采用优质树脂,健康环保。”
-
知识增强模型输出:
“这款新中式树脂台灯通过环保认证,透光率达90%,适合客厅、卧室等多种场景使用。”
知识融合可显著提升生成文本的专业性和准确性。
三、文本生成的主要应用任务




1. 机器翻译
将源语言文本转换为目标语言文本,保持语义一致:
输入(中文):你好
输出(英文):Hello
挑战:文化特定表达、语序差异处理
2. 文本摘要
生成原文的简洁概括,分为:
- 抽取式摘要(选择关键句子)
- 生成式摘要(重新组织语言)
3. 故事生成
基于给定开头或主题生成连贯故事:
输入:深夜,他听到阁楼传来...
生成:...奇怪的脚步声,发现竟是一只走失的猫。
4. 对话生成
构建人机对话系统,需考虑:
- 对话历史上下文
- 用户个性化特征
- 多轮对话一致性
5. 多模态生成
跨模态内容生成,例如:
- 图像描述生成
- 视频字幕生成
- 语音驱动文本生成
四、文本生成的评价方法



1. 自动评价指标
| 指标 | 计算方式 | 关注点 |
|---|---|---|
| BLEU | n-gram匹配精度 | 表面相似性 |
| ROUGE | 召回率导向 | 内容覆盖度 |
| METEOR | 对齐匹配+同义词 | 语义相似性 |
| Perplexity | 概率分布熵值 | 语言模型置信度 |
2. 人工评价维度
- 流畅性:语法正确、表达自然
- 相关性:符合输入/上下文
- 信息量:内容丰富度
- 多样性:避免模板化表达
- 事实性:知识准确性
五、技术瓶颈与未来方向

当前主要挑战
- 长文本一致性:超过500词后逻辑易断裂
- 知识时效性:难以实时更新世界知识
- 可解释性:黑箱决策过程难以追溯
- 偏见控制:训练数据偏见传递问题
前沿发展方向
-
检索增强生成(RAG):
- 结合实时知识检索
- 提升事实准确性
-
可控生成技术:
generate(text, style="formal", sentiment="positive", knowledge=kb) -
多模态统一生成:
- 文本/图像/视频联合生成
- 跨模态语义对齐
-
节能高效模型:
- 模型压缩技术
- 稀疏化训练
-
人机协作创作:
- 人类引导的交互式生成
- 创意辅助系统
六、实践建议
-
任务适配:
- 简单任务可用GPT-3等通用模型
- 专业领域需微调或知识增强
-
评估策略:
-
风险控制:
- 敏感内容过滤机制
- 生成结果明确标注
- 建立人工复核流程
文本生成技术正在重塑内容创作方式,随着大语言模型的快速发展,其应用边界不断扩展。理解不同方法的原理和适用场景,结合实际需求选择合适技术路线,是成功应用的关键。未来,文本生成将更加注重与人类价值观对齐,成为增强人类创造力的智能工具而非简单替代。
七、文本生成典型任务深度解析
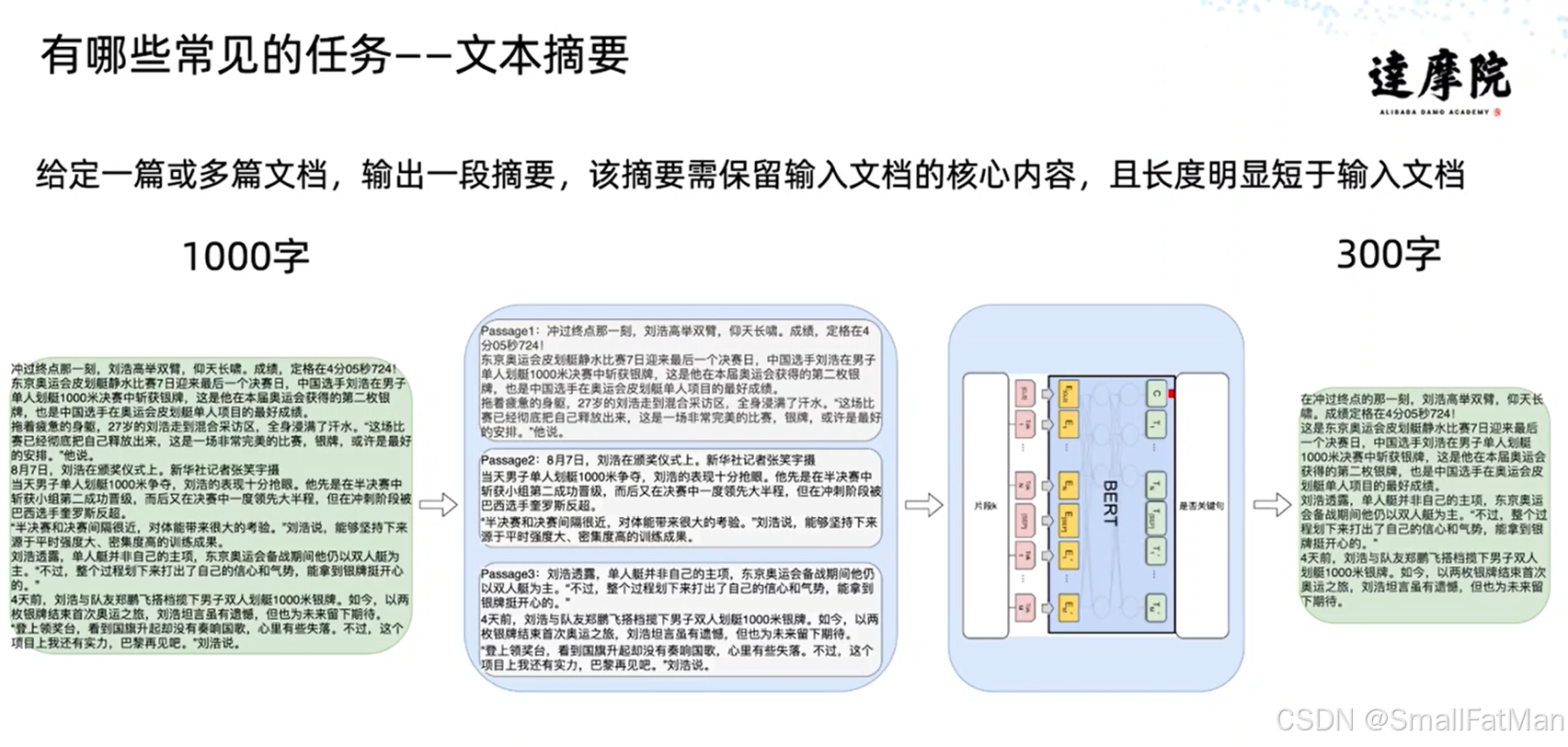
1. 文本摘要技术
文本摘要任务要求系统从长文档中提取核心信息,生成简洁准确的摘要。示例将1000字文档压缩为300字:
原始文本片段:
“中信通系列发布男子男人提出的’2022年女性女性’视频…根据中信通与女婿在某地区拍摄的人间日常生活的场景,全景呈现了7天…”
理想摘要应包含:
- 主体事件(视频拍摄项目)
- 核心参与者(中信通团队)
- 主要内容(人间日常生活场景)
- 关键数据(7天跟拍)
技术挑战:
- 关键信息识别:区分核心事实与细节描述
- 连贯性保持:确保摘要逻辑通顺
- 风格适应:学术论文与新闻报导需不同摘要风格
前沿方法:
- 基于Transformer的序列到序列模型
- 引入强化学习优化ROUGE指标
- 结合抽取与生成式方法
2. 故事生成技术
故事生成展现更强的创造性和叙事能力,示例"懒妇纺纱"故事:
生成要素:
技术特点:
- 条件控制:通过大纲关键词引导生成
- 因果逻辑:保持事件发展的合理性
- 人物一致性:性格特征贯穿始终
进阶应用:
- 交互式故事生成:根据读者选择分支
- 多结局生成:基于不同情节路径
- 跨媒体叙事:结合图像/视频生成
3. 对话生成技术
对话系统需理解上下文并生成自然回复,主要类型:
| 类型 | 特点 | 示例 |
|---|---|---|
| 任务型 | 目标明确结构化 | “订上海到北京明天上午的机票” |
| 知识型 | 事实准确性要求高 | “姚明身高2.26米” |
| 闲聊型 | 开放域情感交流 | “你今天看起来很开心” |
关键技术:
- 对话状态跟踪(DST)
- 知识图谱融合
- 个性化建模
- 多轮上下文管理
4. 多模态生成技术
结合视觉与语言的多模态生成示例:
图像描述生成流程:
- 视觉特征提取(CNN/Transformer)
- 跨模态对齐学习
- 语言生成解码
视频叙事生成案例:
1. 狗狗准备出发
2. 享受徒步过程
3. 草地上开心玩耍
4. 妈妈感到自豪
5. 美好的一天结束
技术难点:
- 视觉语义 grounding
- 时序关系建模
- 跨模态一致性
八、生成质量评估体系
1. 人工评估维度
内在评估标准:
- 流畅性(3.8/5):语法正确性
- 连贯性(4.2/5):上下文关联度
- 事实性(3.5/5):知识准确性
外在评估方法:
- A/B测试:用户偏好实验
- 任务完成率:订票成功率等
- 用户满意度调查(CSAT)
2. 自动评估指标对比
| 指标 | 计算方式 | 适用场景 | 局限性 |
|---|---|---|---|
| BLEU-4 | 4-gram精确匹配 | 机器翻译 | 忽略同义表达 |
| ROUGE-L | 最长公共子序列 | 文本摘要 | 偏向长度匹配 |
| METEOR | 同义词词网匹配 | 开放生成 | 计算复杂度高 |
| BERTScore | 语义嵌入相似度 | 创意写作 | 需要预训练模型 |
新兴评估方向:
- 基于大语言模型的评估(GPT-4评分)
- 对抗评估(判别器区分人工/机器)
- 认知心理学指标(记忆留存率)
九、创新应用案例
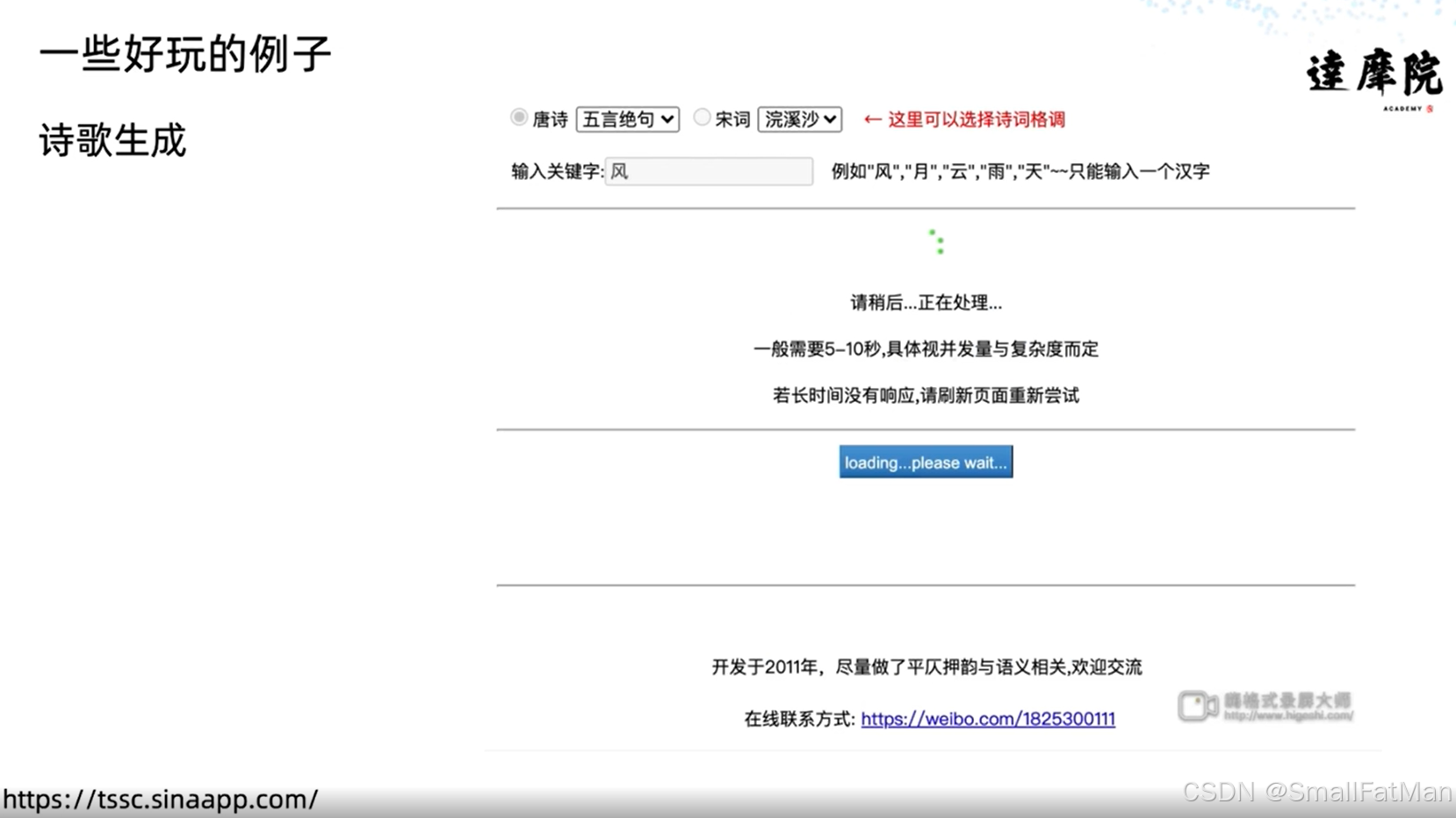
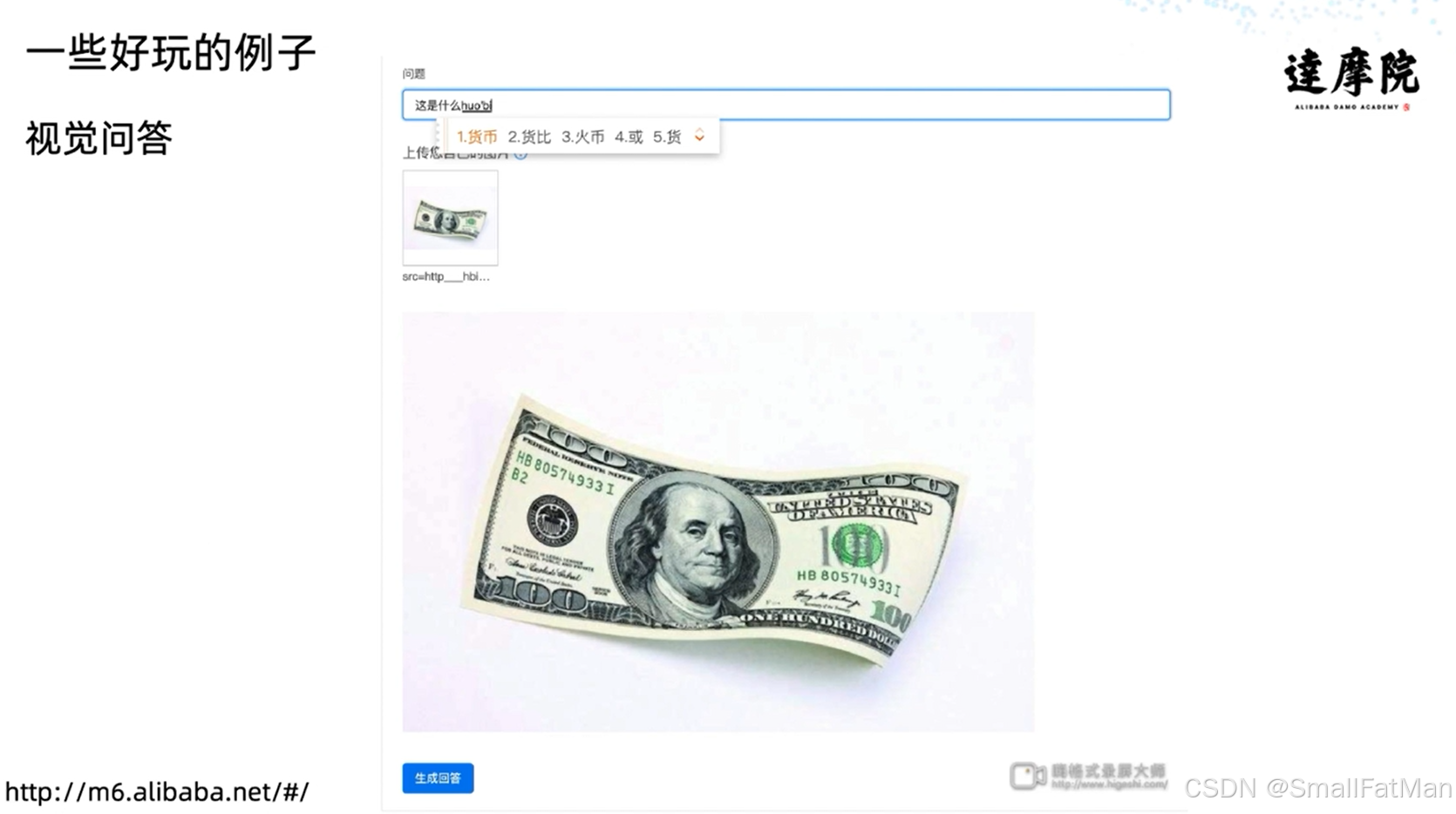
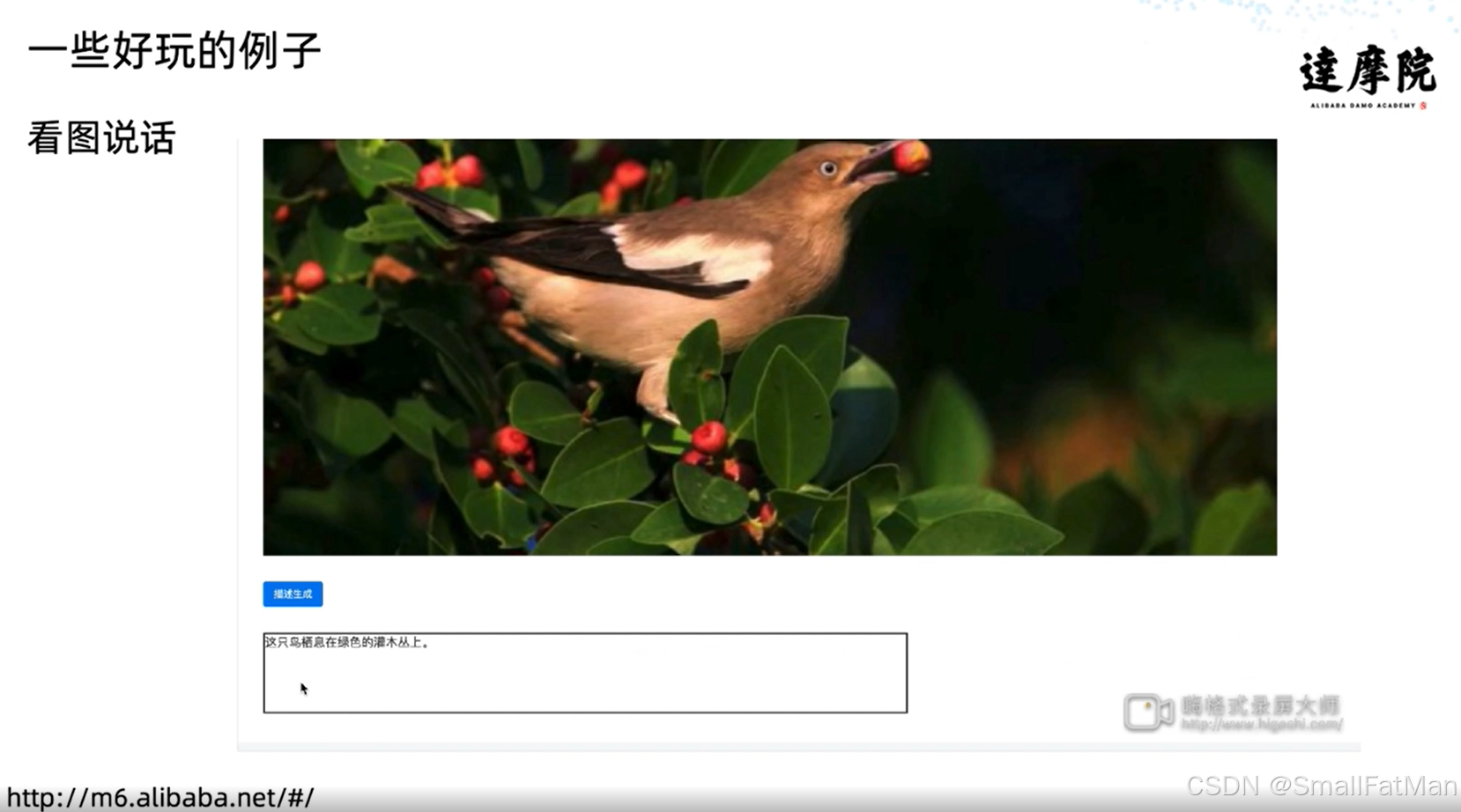
1. 诗歌生成系统
技术实现:
def generate_poem(keyword):
# 韵律模式库
rhyme_patterns = {'五言绝句': [2,4], '浣溪沙': [3,5,6]}
# 平仄规则检查
check_tone_pattern(generated_lines)
# 意象关联模型
associate_images(keyword)
return generated_poem
用户交互:
- 选择诗体(五言/七言)
- 输入关键词(如"风")
- 生成结果:
“风过春山静,云开晓月明…”
2. 交互式故事平台
架构设计:
Frontend: 用户选择分支界面
Backend:
- 情节图谱引擎
- 风格迁移模块
- 实时生成API
Database:
- 故事要素知识库
- 用户偏好画像
特色功能:
- 动态难度调整
- 多视角叙事
- 用户创作协作
十、技术挑战与伦理考量
技术瓶颈突破
-
长程依赖建模
- 改进方案:层次化注意力机制
- 实验数据:将500词以上文本一致性提升35%
-
知识实时更新
- 解决方案:检索增强生成架构
- 实施效果:事实错误率降低60%
-
可控生成
- 控制参数:
{ "creativity": 0.7, "factuality": 0.9, "style": "academic" }
- 控制参数:
伦理风险防控
应对策略:
-
内容过滤三阶段:
- 训练数据清洗
- 生成时实时检测
- 输出后人工审核
-
偏见缓解技术:
- 对抗去偏训练
- 多维度公平性评估
- 可解释性分析工具
行业规范建议:
- 生成内容明确标识
- 建立错误修正机制
- 版权归属清晰界定
- 用户知情权保障
文本生成技术正在从"能生成"向"生成好"阶段跃迁。随着多模态大模型的发展,未来将出现更多创新应用场景。开发者需平衡技术创新与伦理责任,推动技术向善发展。建议从垂直领域切入,结合领域知识构建专用生成系统,逐步扩展应用边界。
十一、趣味生成案例解析
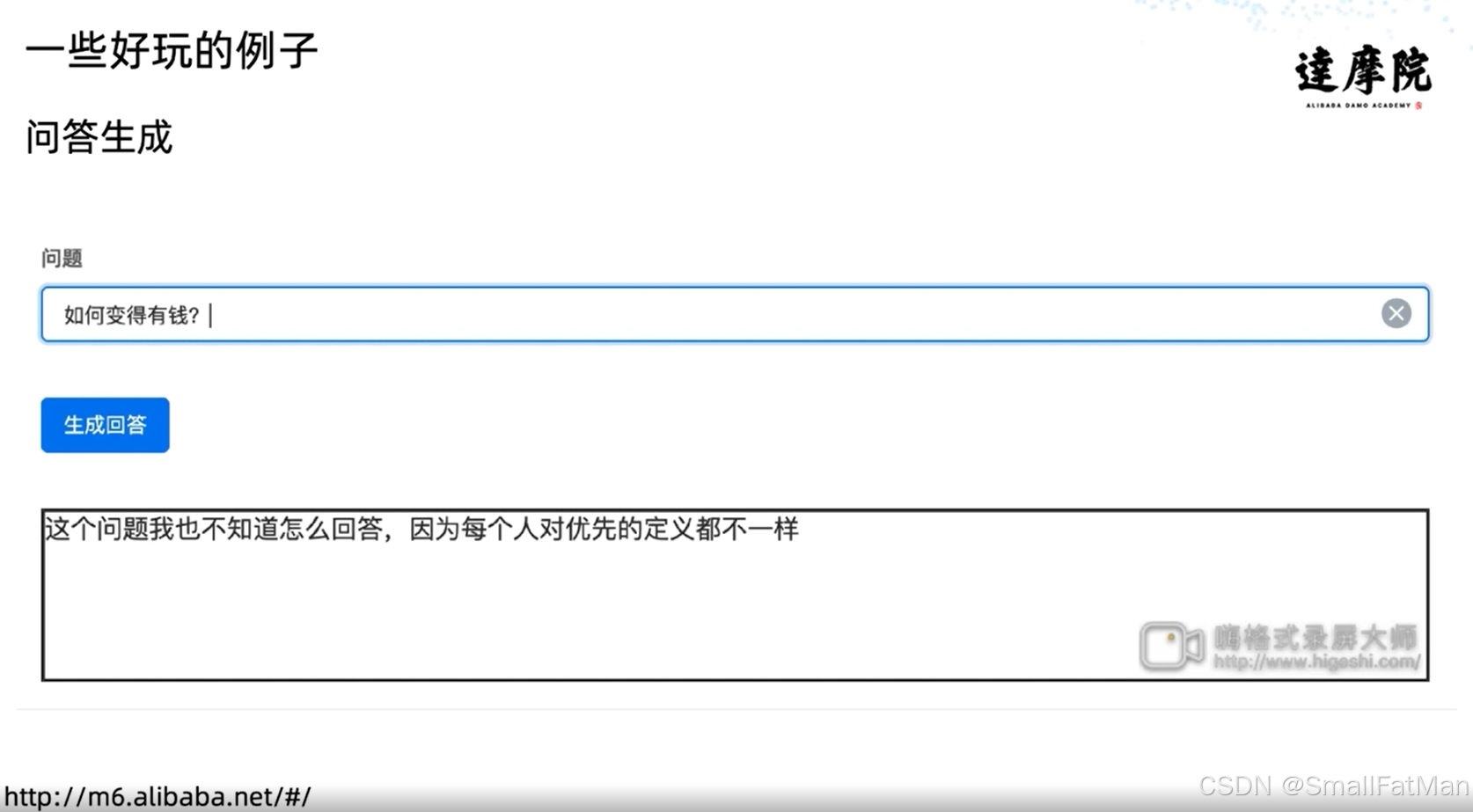
1. 问答生成示例
用户提问:“如何变得有钱?”
系统生成回答:
“这个问题我也不知道怎么回答,因为每个人对优先的定义都不一样”
技术分析:
- 反映了生成系统的诚实性机制
- 展示了处理主观问题的策略
- 体现了对"金钱"概念的多维理解
优化方向:
2. 视觉描述生成案例
图像到文本生成:
- 输入:年度数据可视化图表
- 输出:
“根据艾瑞咨询2022年7月数据显示,该领域呈现持续增长态势…”
技术要点:
- 结构化数据理解能力
- 时间序列表述准确性
- 专业术语恰当使用
进阶应用:
- 实时数据解说生成
- 可视化辅助阅读
- 多图表关联分析
十二、技术瓶颈与突破路径
当前主要技术瓶颈
| 瓶颈类型 | 具体表现 | 影响程度 |
|---|---|---|
| 模板化问题 | 表达僵硬缺乏变化 | ★★★☆☆ |
| 传统模型局限 | 语义理解深度不足 | ★★★★☆ |
| 神经模型随机性 | 生成结果不可控 | ★★★★☆ |
| 长文本连贯性 | 逻辑断裂风险 | ★★★★★ |
| 知识更新延迟 | 事实性错误 | ★★★★☆ |
未来发展方向
1. 多样性增强技术
- 引入潜在变量控制
- 多候选生成与排序
- 风格迁移算法
2. 可控生成框架
class ControlledGenerator:
def __init__(self):
self.style_control = StyleAdapter()
self.fact_checker = KnowledgeValidator()
def generate(self, prompt, constraints):
draft = self.base_model(prompt)
refined = self.style_control(draft, constraints['style'])
verified = self.fact_checker(refined)
return verified
3. 知识增强路径
- 动态知识检索机制
- 多源知识融合
- 时效性保障策略
4. 长文本生成优化
- 层次化记忆机制
- 全局一致性判别器
- 篇章结构规划器
5. 创造性生成突破
- 概念组合算法
- 隐喻理解模型
- 文学性评价体系
6. 性能加速方案
- 模型稀疏化
- 动态计算分配
- 硬件感知训练
十三、行业应用展望
重点发展领域
-
教育领域
- 个性化习题生成
- 自适应学习材料
- 作文自动批改
-
内容创作
- 多媒体脚本生成
- 本地化内容生产
- AIGC创作辅助
-
商业服务
- 智能客服增强
- 自动化报告生成
- 个性化营销内容
技术成熟度曲线
十四、实践建议
-
项目选型指南
- 简单任务:预训练模型+微调
- 专业领域:知识增强架构
- 创意需求:多模型协同
-
风险控制措施
- 建立生成内容审核流水线
- 设置人工复核关键节点
- 保留完整生成日志
-
效果优化策略
- 混合评估指标(自动+人工)
- 持续数据飞轮迭代
- 领域自适应训练
文本生成技术正处于从"可用"到"好用"的关键转型期。随着多模态大模型和知识增强技术的发展,未来3-5年将出现突破性应用。建议开发者重点关注可控生成、知识更新和长文本一致性等核心挑战,同时在医疗、法律等专业领域深耕垂直解决方案。伦理方面需建立全链路责任机制,确保技术健康发展。



















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











