







ARIMA模型的定阶原理与建模分析
前言
ARIMA模型是很经典的自回归模型,这篇文章将全面的讲述ARIMA的建模步骤。从定阶原理解释到实际数据代码编写模型来进行回归预测。基于理论推导和代码编写一气呵成!
岁月如云,匪我思存,写作不易,望路过的朋友们点赞收藏加关注哈,在此表示感谢!
一:AR ( p ) (p) (p)模型的定阶原理
AR模型是一个线性模型,p阶自回归模型的一般表达式为:
x t = ϕ 0 + ϕ 1 x t − 1 + ϕ 2 x t − 2 + . . . + ϕ p x t − p + ε t ( # ) x_t=\phi_0+\phi_1x_{t-1}+\phi_2x_{t-2}+...+\phi_px_{t-p}+\varepsilon_t(\#) xt=ϕ0+ϕ1xt−1+ϕ2xt−2+...+ϕpxt−p+εt(#) ,
其中 { ε t } \{\varepsilon_t\} {εt} 是一个白噪声序列,既然AR模型被建立,此AR模型是满足弱平稳条件的,则存在 ∣ ϕ p ∣ < 1 \left| \phi_p \right|<1 ∣ϕp∣<1和自相关系数,以及 E ( ε t ) = 0 ; V a r ( ε t ) = σ 2 ; E ( ε s ε t ) = 0 , ∀ s ≠ t E(\varepsilon_t)=0;Var(\varepsilon_t)=\sigma^2;E(\varepsilon_s\varepsilon_t)=0,\forall s\ne t E(εt)=0;Var(εt)=σ2;E(εsεt)=0,∀s=t。
- 首先我们先建立AR(2)模型
x t = ϕ 0 + ϕ 1 x t − 1 + ϕ 2 x t − 2 + ε t , ∣ ϕ 1 ∣ < 1 , ∣ ϕ 2 ∣ < 1 ( ∗ ) x_t=\phi_0+\phi_1x_{t-1}+\phi_2x_{t-2}+\varepsilon_t,\left| \phi_1 \right|<1,\left| \phi_2\right|<1(*) xt=ϕ0+ϕ1xt−1+ϕ2xt−2+εt,∣ϕ1∣<1,∣ϕ2∣<1(∗)
那么我们对上式 (*) 左右两边各减去
u
u
u 得:
x
t
−
μ
=
ϕ
0
+
ϕ
1
(
x
t
−
1
−
u
)
+
ϕ
2
(
x
t
−
2
−
u
)
+
(
ϕ
1
+
ϕ
2
−
1
)
μ
+
ε
t
(
1
)
x_t-\mu=\phi_0+\phi_1(x_{t-1}-u)+\phi_2(x_{t-2}-u)+(\phi_1+\phi_2-1)\mu+\varepsilon_t (1)
xt−μ=ϕ0+ϕ1(xt−1−u)+ϕ2(xt−2−u)+(ϕ1+ϕ2−1)μ+εt(1) ,
又由弱平稳性质, ( ∗ ) (*) (∗) 两边取均值可得:
μ = ϕ 0 + ϕ 1 E ( x t − 1 ) + ϕ 2 E ( x t − 2 ) + E ( ε t ) \mu=\phi_0+\phi_1E(x_{t-1})+\phi_2E(x_{t-2})+E(\varepsilon_t) μ=ϕ0+ϕ1E(xt−1)+ϕ2E(xt−2)+E(εt) ,
即 μ = ϕ 0 + ϕ 1 μ + ϕ 2 μ + 0 ⇒ μ = ϕ 0 1 − ϕ 1 − ϕ 2 \mu=\phi_0+\phi_1\mu+\phi_2\mu+0\Rightarrow \mu=\frac{\phi_0}{1-\phi_1-\phi_2} μ=ϕ0+ϕ1μ+ϕ2μ+0⇒μ=1−ϕ1−ϕ2ϕ0 ,
那么把此结果带入 ( 1 ) (1) (1) 式可得:
x t − μ = ϕ 1 ( x t − 1 − μ ) + ϕ 2 ( x t − 2 − u ) + ε t ( 2 ) x_t-\mu=\phi_1(x_{t-1}-\mu)+\phi_2(x_{t-2}-u)+\varepsilon_t(2) xt−μ=ϕ1(xt−1−μ)+ϕ2(xt−2−u)+εt(2) ,
( 2 ) (2) (2) 式两边乘以 ( x t − 1 − u ) (x_{t-1}-u) (xt−1−u):
( x t − μ ) ( x t − 1 − u ) = ϕ 1 ( x t − 1 − μ ) ( x t − 1 − u ) + ϕ 2 ( x t − 2 − u ) ( x t − 1 − u ) + ε t ( x t − 1 − u ) ( 3 ) (x_t-\mu)(x_{t-1}-u)=\phi_1(x_{t-1}-\mu)(x_{t-1}-u)+\phi_2(x_{t-2}-u)(x_{t-1}-u)+\varepsilon_t(x_{t-1}-u)(3) (xt−μ)(xt−1−u)=ϕ1(xt−1−μ)(xt−1−u)+ϕ2(xt−2−u)(xt−1−u)+εt(xt−1−u)(3)
( 3 ) (3) (3) 式两边同时取期望后得:
E [ ( x t − μ ) ( x t − 1 − u ) ] = ϕ 1 E [ ( x t − 1 − μ ) ( x t − 1 − u ) ] + ϕ 2 E [ ( x t − 2 − u ) ( x t − 1 − u ) ] ( 4 ) E\left[ (x_t-\mu)(x_{t-1}-u) \right]=\phi_1E\left[ (x_{t-1}-\mu)(x_{t-1}-u) \right]+\phi_2E\left[ (x_{t-2}-u)(x_{t-1}-u) \right](4) E[(xt−μ)(xt−1−u)]=ϕ1E[(xt−1−μ)(xt−1−u)]+ϕ2E[(xt−2−u)(xt−1−u)](4)
对
(
4
)
(4)
(4) 式两边再除以方差
σ
0
\sigma_0
σ0 之后得
ρ
1
=
ϕ
1
+
ϕ
2
ρ
1
\rho_1=\phi_1+\phi_2\rho_1
ρ1=ϕ1+ϕ2ρ1 ,这里的
ρ
1
\rho_1
ρ1 为自相关系数。
则可得
ρ
1
=
ϕ
1
/
(
1
−
ϕ
2
)
\rho_1=\phi_1/(1-\phi_2)
ρ1=ϕ1/(1−ϕ2) ,同理 (2) 式两边同时乘以
(
x
t
−
2
−
μ
)
(x_{t-2}-\mu)
(xt−2−μ)
可得 ρ 2 = ϕ 1 ρ 1 + ϕ 2 \rho_2=\phi_1\rho_1+\phi_2 ρ2=ϕ1ρ1+ϕ2。
同理我们推广 ( 2 ) (2) (2) 式两边乘以 ( x t − k − μ ) ( k ≥ 3 ) (x_{t-k}-\mu)(k\geq3) (xt−k−μ)(k≥3) ,
可得 ρ k = ϕ 1 ρ k − 1 + ϕ 2 ρ k − 2 \rho_k=\phi_1\rho_{k-1}+\phi_2\rho_{k-2} ρk=ϕ1ρk−1+ϕ2ρk−2 。
从 ρ k \rho_k ρk 的表达式我们容易发现尽管 ∣ ϕ 1 ∣ < 1 , ∣ ϕ 2 ∣ < 1 \left| \phi_1 \right|<1,\left| \phi_2\right|<1 ∣ϕ1∣<1,∣ϕ2∣<1 ,但 ρ k \rho_k ρk 永远不会为0,所以会出现拖尾现象。
- 接着我们拓展至AR ( p ) (p) (p)模型
在平稳的前提下,我们容易得 μ = ϕ 0 1 − ϕ 1 − ϕ 2 − . . . − ϕ p \mu=\frac{\phi_0}{1-\phi_1-\phi_2-...-\phi_p} μ=1−ϕ1−ϕ2−...−ϕpϕ0 ,
将 ( # ) (\#) (#) 两边减去均值 μ \mu μ 可得: x t − μ = ϕ 1 ( x t − 1 − μ ) + ϕ 2 ( x t − 2 − u ) + . . . + ϕ p ( x t − p − μ ) + ε t ( 5 ) x_t-\mu=\phi_1(x_{t-1}-\mu)+\phi_2(x_{t-2}-u)+...+\phi_p(x_{t-p}-\mu)+\varepsilon_t(5) xt−μ=ϕ1(xt−1−μ)+ϕ2(xt−2−u)+...+ϕp(xt−p−μ)+εt(5) ,
那么对 ( 5 ) (5) (5) 左右两边同乘以 ( x t − μ ) 、 ( x t − 1 − μ ) 、 . . . 、 (x_t-\mu)、(x_{t-1}-\mu)、...、 (xt−μ)、(xt−1−μ)、...、 并除以方差 σ 0 \sigma_0 σ0 可得:
1 = ϕ 1 ρ 1 + ϕ 2 ρ 2 + . . . + ϕ p ρ p , ρ 1 = ϕ 1 + ϕ 2 ρ 2 + ϕ 3 ρ 3 + . . . + ϕ p ρ p − 1 , ρ 2 = ϕ 1 ρ 1 + ϕ 2 + ϕ 3 ρ 3 + . . . + ϕ p ρ p − 2 , . . . , ρ p = ϕ 1 ρ p − 1 + ϕ 2 ρ p − 2 + ϕ 3 ρ p − 3 + . . . + ϕ p 1=\phi_1\rho_1+\phi_2\rho_2+...+\phi_p\rho_p , \rho_1=\phi_1+\phi_2\rho_2+\phi_3\rho_3+...+\phi_p\rho_{p-1} , \rho_2=\phi_1\rho_1+\phi_2+\phi_3\rho_3+...+\phi_p\rho_{p-2 },..., \rho_p=\phi_1\rho_{p-1}+\phi_2\rho_{p-2}+\phi_3\rho_{p-3}+...+\phi_p 1=ϕ1ρ1+ϕ2ρ2+...+ϕpρp,ρ1=ϕ1+ϕ2ρ2+ϕ3ρ3+...+ϕpρp−1,ρ2=ϕ1ρ1+ϕ2+ϕ3ρ3+...+ϕpρp−2,...,ρp=ϕ1ρp−1+ϕ2ρp−2+ϕ3ρp−3+...+ϕp ,
根据这些关系式,模仿AR(2)的递推关系式可得:
ρ
k
=
ϕ
1
ρ
k
−
1
+
ϕ
2
ρ
k
−
2
+
.
.
.
+
ϕ
k
ρ
k
−
p
(
k
≥
p
)
\rho_k=\phi_1\rho_{k-1}+\phi_2\rho_{k-2}+...+\phi_k\rho_{k-p}(k\geq p)
ρk=ϕ1ρk−1+ϕ2ρk−2+...+ϕkρk−p(k≥p) ,
因此符合 A R ( p ) AR(p) AR(p)的平稳序列模型,其自相关系数在 p p p 阶之后一直不会为0,存在所谓拖尾现象。
二:MA ( q ) (q) (q)模型的定阶原理
M
A
(
q
)
MA(q)
MA(q)模型被称为移动平均模型,一个
q
q
q 阶的移动平均模型可以用数学式表达为:
x
t
=
μ
+
ε
t
+
θ
1
ε
t
−
1
+
θ
2
ε
t
−
2
+
.
.
.
+
θ
q
ε
t
−
q
x_t=\mu+\varepsilon_t+\theta_1\varepsilon_{t-1}+\theta_2\varepsilon_{t-2}+...+\theta_q\varepsilon_{t-q}
xt=μ+εt+θ1εt−1+θ2εt−2+...+θqεt−q ,
那么满足的性质有
E ( ε t ) = 0 ; V a r ( ε t ) = σ 2 ; E ( ε s ε t ) = 0 , ∀ s ≠ t E(\varepsilon_t)=0;Var(\varepsilon_t)=\sigma^2;E(\varepsilon_s\varepsilon_t)=0,\forall s\ne t E(εt)=0;Var(εt)=σ2;E(εsεt)=0,∀s=t;
E ( x t ) = μ ; V a r ( x t ) = ( 1 + θ 1 2 + θ 2 2 + . . . + θ q 2 ) σ 2 E(x_t)=\mu;Var(x_t)=(1+\theta_1^2+\theta_2^2+...+\theta_q^2)\sigma^2 E(xt)=μ;Var(xt)=(1+θ12+θ22+...+θq2)σ2
- 首先我们还是建立 M A ( 2 ) MA(2) MA(2)模型
如 x t = μ + ε t + θ 1 ε t − 1 + θ 2 ε t − 2 x_t=\mu+\varepsilon_t+\theta_1\varepsilon_{t-1}+\theta_2\varepsilon_{t-2} xt=μ+εt+θ1εt−1+θ2εt−2 ,
则 E ( x t ) = μ , V a r ( x t ) = ( 1 + θ 1 2 + θ 2 2 ) σ ϵ 2 E(x_t)=\mu,Var(x_t)=(1+\theta_1^2+\theta_2^2)\sigma_\epsilon^2 E(xt)=μ,Var(xt)=(1+θ12+θ22)σϵ2
对于 V a r ( x t ) Var(x_t) Var(xt) ,两边同时被 σ 1 = C o v ( x t , x t − 1 ) \sigma_1=Cov(x_t,x_{t-1}) σ1=Cov(xt,xt−1) 相除有
ρ 1 = C o v ( x t , x t − 1 ) ( 1 + θ 1 2 + θ 2 2 ) σ 2 \rho_1=\frac{Cov(x_t,x_{t-1})}{(1+\theta_1^2+\theta_2^2)\sigma^2} ρ1=(1+θ12+θ22)σ2Cov(xt,xt−1) ,
又 C o v ( x t , x t − 1 ) = E [ ( x t − μ ) ( x t − 1 − μ ) ] = E [ ( ε t + θ 1 ε t − 1 + θ 2 ε t − 2 ) ( ε t − 1 + θ 1 ε t − 2 + θ 2 ε t − 3 ) ] = Cov(x_t,x_{t-1})=E\left[ (x_t-\mu)(x_{t-1}-\mu) \right]=E\left[ (\varepsilon_t+\theta_1\varepsilon_{t-1}+\theta_2\varepsilon_{t-2})(\varepsilon_{t-1}+\theta_1\varepsilon_{t-2}+\theta_2\varepsilon_{t-3}) \right]= Cov(xt,xt−1)=E[(xt−μ)(xt−1−μ)]=E[(εt+θ1εt−1+θ2εt−2)(εt−1+θ1εt−2+θ2εt−3)]=
E
(
ε
t
−
1
ε
t
+
θ
1
ε
t
−
2
ε
t
+
θ
2
ε
t
−
3
ε
t
+
θ
1
ε
t
−
2
ε
t
−
1
+
θ
1
θ
2
ε
t
−
3
ε
t
−
1
+
θ
2
ε
t
−
2
ε
t
−
1
+
θ
2
ε
t
−
3
ε
t
−
2
+
θ
1
ε
t
−
1
2
+
θ
1
θ
2
ε
t
−
2
2
)
E\left( \varepsilon_{t-1}\varepsilon_t+\theta_1\varepsilon_{t-2}\varepsilon_t+\theta_2\varepsilon_{t-3}\varepsilon_t+\theta_1\varepsilon_{t-2}\varepsilon_{t-1}+\theta_1\theta_2\varepsilon_{t-3}\varepsilon_{t-1}+\theta_2\varepsilon_{t-2}\varepsilon_{t-1}+\theta_2\varepsilon_{t-3}\varepsilon_{t-2}+\theta_1\varepsilon_{t-1}^2+\theta_1\theta_2\varepsilon_{t-2}^2\right)
E(εt−1εt+θ1εt−2εt+θ2εt−3εt+θ1εt−2εt−1+θ1θ2εt−3εt−1+θ2εt−2εt−1+θ2εt−3εt−2+θ1εt−12+θ1θ2εt−22)
=
θ
1
E
(
ε
t
−
1
2
)
+
θ
1
θ
2
E
(
ε
t
−
2
2
)
=\theta_1E(\varepsilon_{t-1}^2)+\theta_1\theta_2E(\varepsilon_{t-2}^2)
=θ1E(εt−12)+θ1θ2E(εt−22)
那么最终 ρ 1 = θ 1 + θ 1 θ 2 1 + θ 1 2 + θ 2 2 \rho_1=\frac{\theta_1+\theta_1\theta_2}{1+\theta_1^2+\theta_2^2} ρ1=1+θ12+θ22θ1+θ1θ2。
如果我们相同的方法求解 ρ 2 = θ 2 1 + θ 1 2 + θ 2 2 \rho_2=\frac{\theta_2}{1+\theta_1^2+\theta_2^2} ρ2=1+θ12+θ22θ2 ,那么 ρ 3 = 0 \rho_3=0 ρ3=0 这是显然的。
- 接着我们建立 M A ( q ) MA(q) MA(q)模型
同理对于 M A ( q ) MA(q) MA(q)模型,我们经过相同的运算可得最终表达式
ρ l = θ l + θ 1 θ l + 1 + θ 2 θ l + 2 + . . . + θ q − l θ q 1 + θ 1 2 + θ 2 2 + . . . + θ q 2 \rho_l=\frac{\theta_l+\theta_1\theta_{l+1}+\theta_2\theta_{l+2}+...+\theta_{q-l}\theta_q}{1+\theta_1^2+\theta_2^2+...+\theta_q^2} ρl=1+θ12+θ22+...+θq2θl+θ1θl+1+θ2θl+2+...+θq−lθq ,
那么当 l > q l>q l>q 时同理可得 ρ l = 0 \rho_l=0 ρl=0 。
所以,通过上述推导我们有理由相信: M A ( q ) MA(q) MA(q)模型的自相关系数 q q q 阶截尾。所谓 q q q 阶截尾意思是在 q q q 阶以后 M A ( q ) MA(q) MA(q)模型的自相关系数立马截止, q + 1 q+1 q+1 阶起就为0。
以上就是通过理论解释了AR§模型和MA(q)模型的拖尾和截尾的底层逻辑。
三:ARMA模型
- 参数估计过程
当把 A R ( p ) AR(p) AR(p)模型和 M A ( q ) MA(q) MA(q)模型相结合时,我们得到 A R M A ( p , q ) ARMA(p,q) ARMA(p,q)模型如下:
x t = ϕ 0 + ϕ 1 x t − 1 + . . . + ϕ p x t − p + ε t + θ 1 ε t − 1 + . . . + θ q ε t − q x_t=\phi_0+\phi_1x_{t-1}+...+\phi_px_{t-p}+\varepsilon_t+\theta_1\varepsilon_{t-1}+...+\theta_q\varepsilon_{t-q} xt=ϕ0+ϕ1xt−1+...+ϕpxt−p+εt+θ1εt−1+...+θqεt−q
相较于前两个模型,此模型是更具有普遍性。首先我们通过一些定阶模型确定 p , q p,q p,q,当阶数确定后,可以根据最小二乘最大似然估计或者梯度下降法更新所有方程系数。根据模型的表达式一直迭代下去即可完成“无穷的”预测。但是作为长期预测,理论上是可行的,实际确实长期预测所受的干扰因素太多了,除非你的预测数据是周期性、趋势性或者季节性的,那长期还是有点实际意义,否则任何回归模型,还是作为短期预测才有更大的实际意义。
- 建模过程
1:序列判断
(a):判断我们需要建立的模型数据是否为平稳序列,若非平稳序列我们要对其进行变换处理(一般用差分方法即可)至平稳序列,
(b):接着再判断平稳序列时候为白噪声序列,若为白噪声序列则建模结束(白噪声序列无法构成ARMA模型),否则进行下一步。
2:模型估计与建立
(a):判断 p p p 和 q q q 的值。当我们建立好自回归模型时,为了得到最优的模型结构,我们需要定下 p p p 和 q q q 值。这里的定阶一是可以通过自相关系数 A C F ACF ACF和偏自相关系数 P A C F PACF PACF大致决定。由上面的理论分析,我们知道 A R ( p AR(p AR(p)将出现 p p p 阶拖尾, M A ( q ) MA(q) MA(q)将出现 q q q 阶截尾,
(b):如果序列的 A C F ACF ACF和 P A C F PACF PACF不是很明确的话,我们可以用其他模型来定阶。其中就包括AIC和BIC信息准备判别。AIC是一种用于模型选择的指标,同时考虑模型的拟合程度以及简单性,BIC是对AIC的改进,一般来说较小的AIC或者BIC表示在保持模型简单的同时,能够更好的对时间序列进行拟合。
3:模型诊断
即对模型残差进行验证,确保其为服从正态分布的白噪声序列,当模型的残差为白噪声时,说明我们已经将序列的信息充分提取到模型中,建模彻底结束。
在上一篇文章我们对于ARMA模型 x t = ∑ i = 1 q θ i ε t − i + ϕ 0 + ∑ j = 1 p ϕ j L j x t x_t=\sum_{i=1}^{q}\theta_i{\varepsilon_{t-i}}+\phi_0+\sum_{j=1}^{p}{\phi_jL^jx_t} xt=∑i=1qθiεt−i+ϕ0+∑j=1pϕjLjxt 分析发现,ARMA其实和AR模型在平稳性上的判断是一样的,都有这相同的特征方程,同样可以通过单位根方法判断是否平稳性成立。
四:实际建模运用
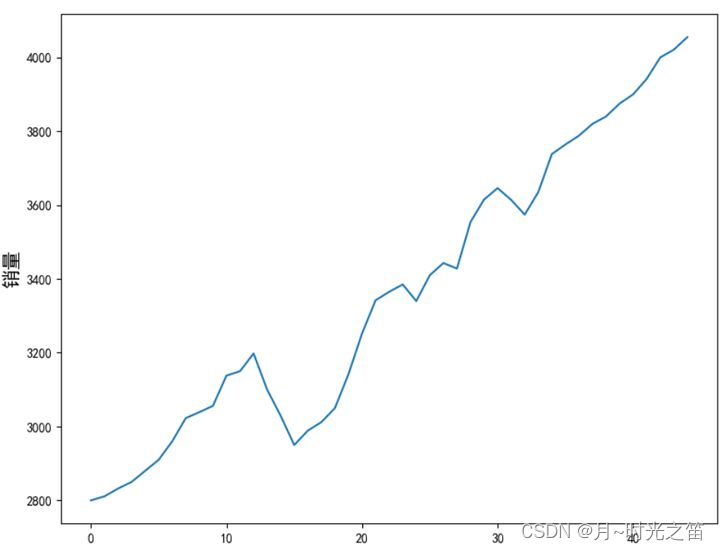
我们接下来基于实际销量数据开始建立时序模型,首先观察下销量数据可视化结果,由曲线图发现销量的变化明显具有上涨的趋势性,符合自回归移动平均模型的建模直观要求。
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
from statsmodels.tsa.stattools import adfuller as ADF
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.tsa.arima_model import ARIMA
import statsmodels.api as sm
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
yv = np.array([2800,2811,2832,2850,2880,2910,2960,3023,3039,3056,3138,3150,3198,3100,3029,2950,2989,3012,3050,3142,3252,3342,3365,3385,3340,3410,3443,3428,3554,3615,3646,3614,3574,3635,3738,3764,3788,3820,3840,3875,3900,3942,4000,4021,4055])
yv_serie = pd.Series(yv[:-10])##样本外数据
def testwhitenoise(data):
m = 10# 检验10个自相关系数
acf,q,p = sm.tsa.acf(data,nlags=m,qstat=True)
out = np.c_[range(1,m+1),acf[1:],q,p]
output = pd.DataFrame(out,columns=['lag','自相关系数','统计量Q值','p_values'])
output = output.set_index('lag')# 设置第一列索引名称,可省略重复索引列1
print(output)
def teststeady(data,count=0):
res_ADF = ADF(data)
print('ADF检验结果为:', res_ADF)
Pv = res_ADF[1]
if Pv > 0.05:
print('\033[1;31mP值:%s,原始序列不平稳,要进行差分!\033[0m' % round(Pv,5))
count = count + 1
print('\033[1;32m进行了%s阶差分后的结果如下\033[0m' % count)
data = data.diff(1).dropna()
teststeady(data,count)
else:
print('\033[1;34mP值:%s,原始序列平稳,继续建模\033[0m'% round(Pv,5))
testwhitenoise(yv_serie)
teststeady(yv_serie)

图2就是平稳性和自相关性(白噪声)检验的结果,我们发现当进行一阶差分后序列平稳,按照建模步骤我们接下来开始定阶。
def confirm_p_q(data):
fig = plt.figure(figsize=(8,6))
testwhitenoise(data)
train = teststeady(data)
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_pacf(train, lags=10, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_acf(train, lags=10, ax=ax2)
plt.show() ###可视化定阶
pmax = int(len(data) / 10)
qmax = int(len(data) / 10)
AIC = sm.tsa.arma_order_select_ic(train,max_ar=pmax,max_ma=qmax,ic='aic')['aic_min_order']
BIC = sm.tsa.arma_order_select_ic(train,max_ar=pmax,max_ma=qmax,ic='bic')['bic_min_order']
HQIC = sm.tsa.arma_order_select_ic(train,max_ar=pmax,max_ma=qmax,ic='hqic')['hqic_min_order']
print('AIC:',AIC)
print('BIC:',BIC)
print('HQIC:',HQIC)
return AIC
pq = confirm_p_q(yv_serie)##返回p,q值
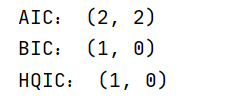
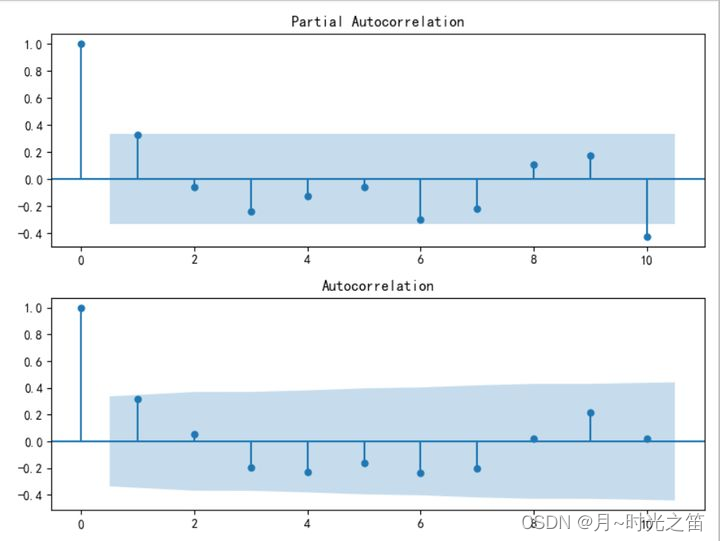
由上面图4自相关函数图可知,定阶在 p , q = ( 1 , 1 ) p,q=(1,1) p,q=(1,1) 阶比较合理,再由相应的信息准则,我们最终定阶 p , q = ( 2 , 2 ) p,q=(2,2) p,q=(2,2) 也是合理的。
这里的定阶结果都是理论给的结果,实际中的定阶还是要根据模型表现不断调整,一般阶数越高越复杂,拟合效果越强,但过拟合概率也越高,所以要不断尝试不断调整。
接着我们正式开始预测
def prediction(data):
tempmodel = ARMA(teststeady(data),pq).fit(disp=-1)
print(tempmodel.summary())
#num = 10
#predictoutside1 = tempmodel.forecast(num)[0]#预测样本外的
predictoutside2 = tempmodel.predict(len(tempmodel.predict()),len(tempmodel.predict()) + 9,dynamic=True)##也是样本外预测,预测结果一致
predictinside = tempmodel.predict()##样本内预测
init_value = yv[0]
fig = plt.figure(figsize=(8, 6))
predictinside = predictinside.cumsum()##差分还原
pretrueinside = init_value + predictinside
startprevalue = list(pretrueinside)[-1]
predictoutside2 = predictoutside2.cumsum()##差分还原
pretrueoutside = startprevalue + predictoutside2
##作图
plt.plot(yv,label='原始值')
plt.plot([init_value] + list(pretrueinside),label='样本内预测值')
X = [i for i in range(len(yv)-11,len(yv))]
plt.plot(X,[startprevalue] + list(pretrueoutside), label='样本外预测值')
allpredata = [init_value] + list(pretrueinside) + list(pretrueoutside)
plt.legend()
plt.show()
return tempmodel,allpredata
preres = prediction(yv_serie)
最后我们对模型进行评价
def evaluate_model(model,apd):
delta = model.fittedvalues - tsres
score = 1 - delta.var() / tsres.var()
print('R^2:', score)
allmse = mean_squared_error(apd,yv)##所有预测值跟所有原始值的MSE
print('ALLMSE:',allmse)
###残差白噪声检验
testwhitenoise(delta)
evaluate_model(preres[0],preres[1])
五:建模结果比较分析
- 当我们选择阶数 p , q = ( 1 , 1 ) p,q=(1,1) p,q=(1,1) 时看下建模效果:
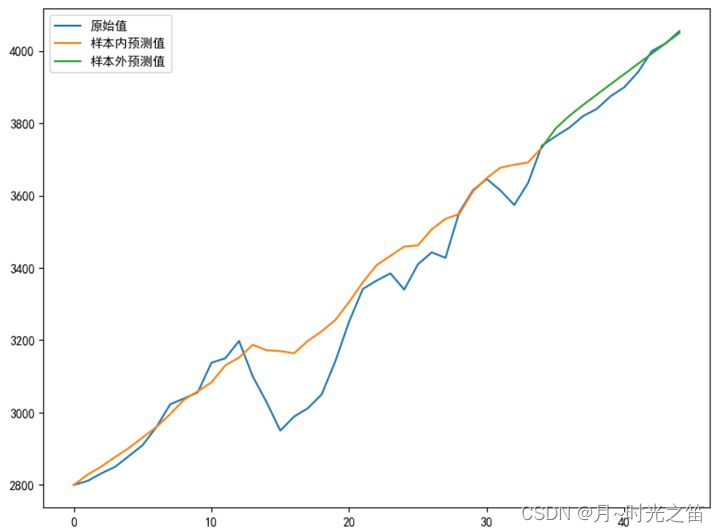
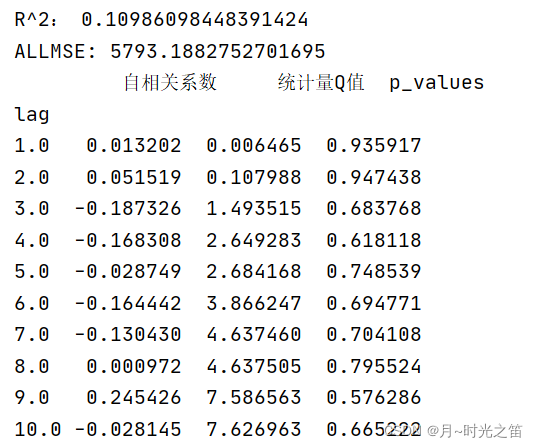
注:这里涉及两个评价指标,一个是拟合优度 R 2 R^2 R2 值,公式如下: R 2 = 1 − V a r 残 差 V a r 样 本 内 x t R^2=1-\frac{Var_{残差}}{Var_{样本内x_{t}}} R2=1−Var样本内xtVar残差 , V a r Var Var 是方差意思, R 2 R^2 R2 越接近1,说明拟合越好。 另一个是均方误差,公式如下: M S E = 1 n ∑ i = 1 n ( x i − x i ˉ ) 2 MSE=\frac{1}{n}\sum_{i=1}^{n}{(x_i-\bar{x_i})^2} MSE=n1∑i=1n(xi−xiˉ)2 , x i ˉ \bar{x_i} xiˉ 是样本估计量(预测值),此实验中,预测值指的是样本内预测值+样本外预测值,样本值是全体原数据值。
从残差检验是白噪声序列后,我们完整的建模算正式结束!
当我们选择阶数 p , q = ( 2 , 2 ) p,q=(2,2) p,q=(2,2) 时看下建模效果:
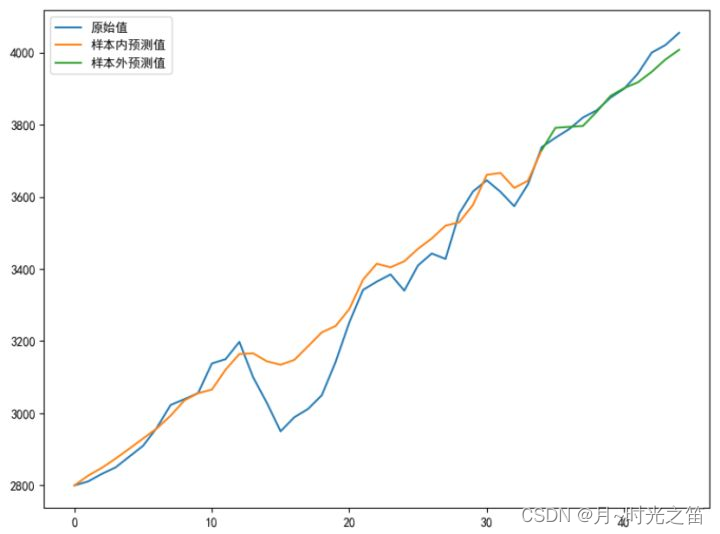
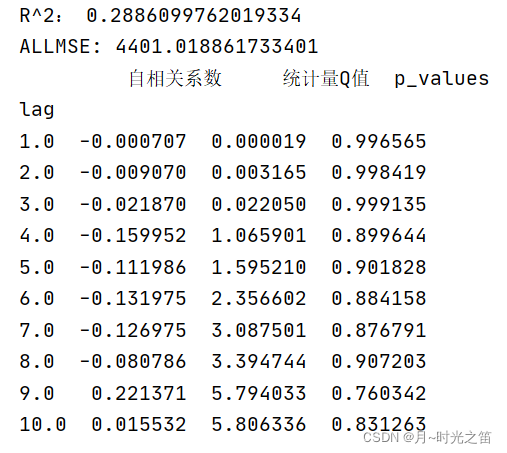
由图5和图6比较,直观上感觉图6总体拟合效果更好,再观察理论评价指标,也是 p , q = ( 2 , 2 ) p,q=(2,2) p,q=(2,2) 表现的更好,所以具体定阶时,我们不妨多个指标一起观察。
六:总结
- 此篇文章涉及的内容很多,有详细的理论推导解释AR§拖尾和MA(q)截尾的缘故,并最终一步一步建立ARMA模型来解决实际问题,
- 在上一篇文章我们也谈到ARMA对趋势性,周期性和季节性数据做短期预测是非常有效的,这篇文章主要是对趋势性数据做预测,周期性和季节性当然也是同理而得,
- 对于阶数
p
,
q
p,q
p,q 的取定,一直是个非常重要的步骤,所以在实际中,我们一定要结合实际结合多种方法综合定阶。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









