







最近好像对这方面需求比较高,总有人问我爬过携程没,我寻思着拿selenium也没太大难度吧,晚上就做了个demo。
这里做的是携程上面天津市酒店的所有评论信息demo,你要问我为啥不拿信息价格类型标签之类的,毕竟是demo嘛,评论跟那些数据在同一页面的,有需要可以自己花点时间改一下。我提的数据直接界面上copy xpath的,只拿了用户的id和他的评论。
下面是测试图,这次放上面。
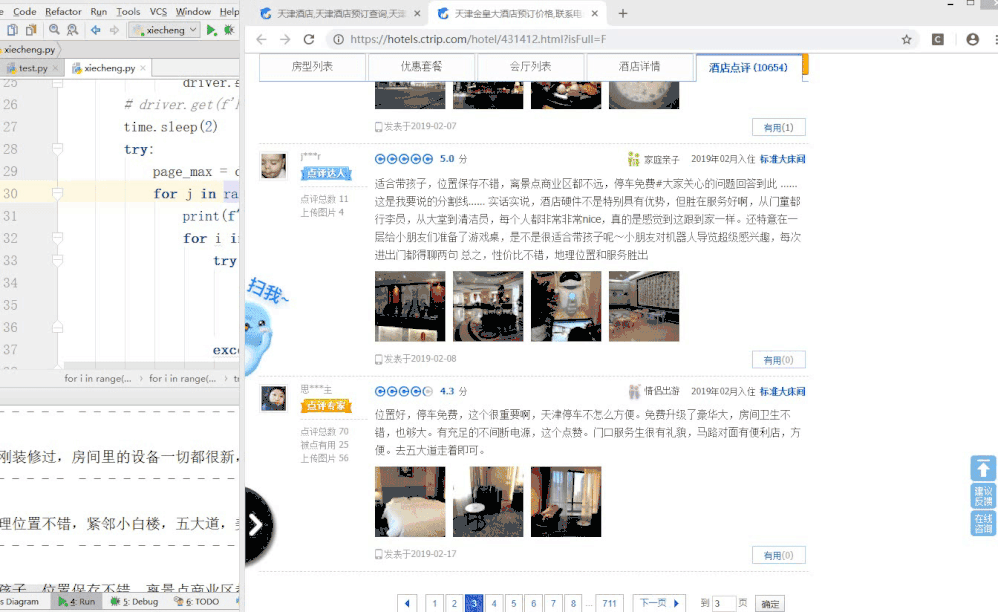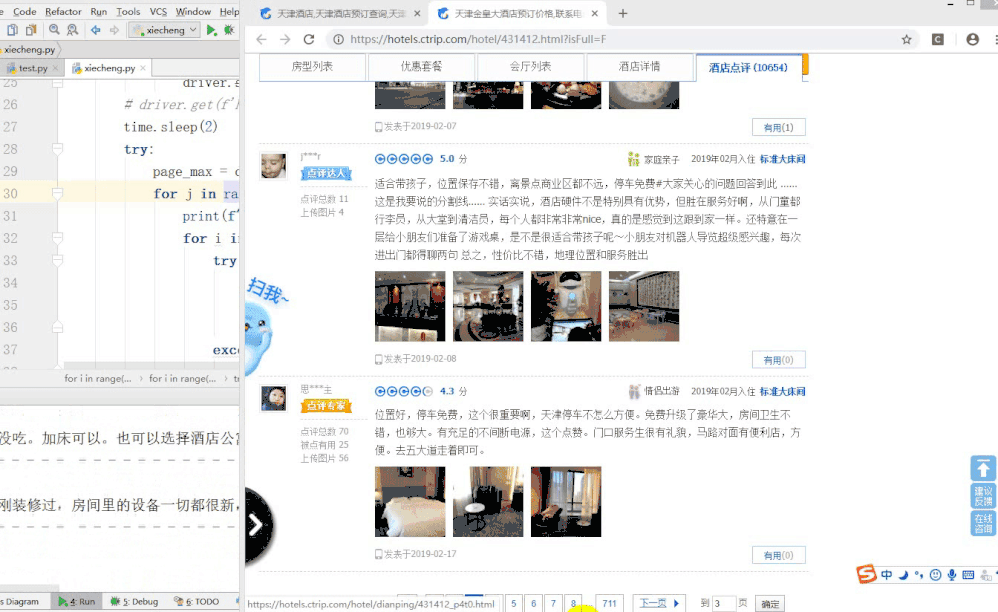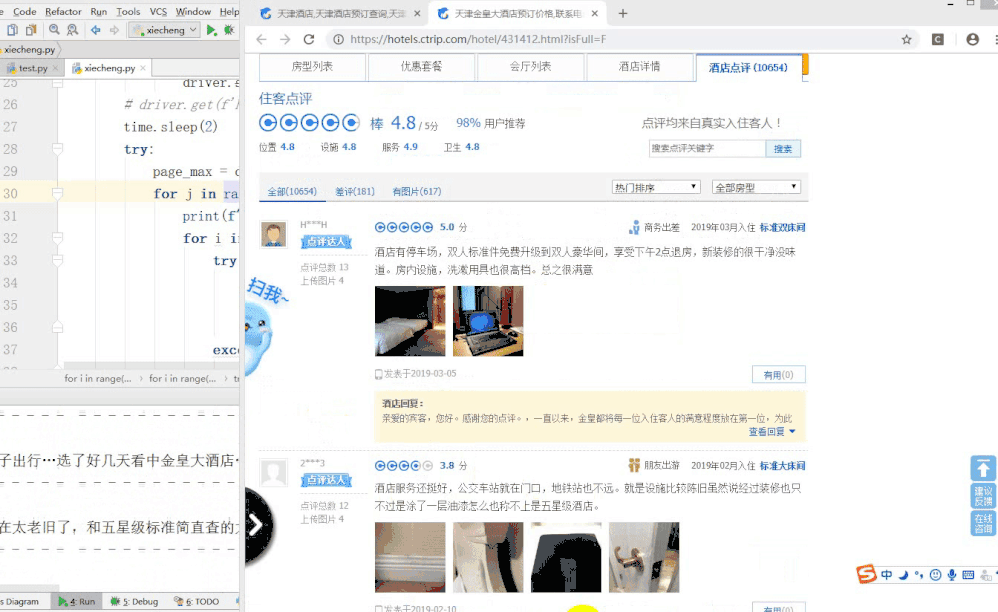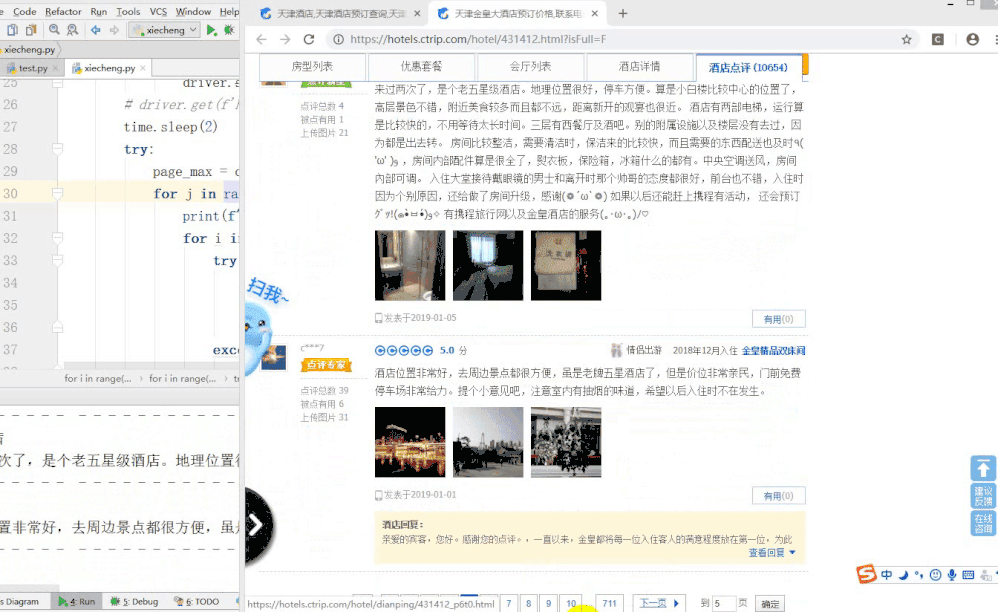
那就先说下用selenium拿这个数据时候的坑吧。
刚开始就直接driver.get()看了下,唉发现有数据啊,没啥难度啊,一想又感觉不对劲,就对比了下数据,
观察了下发现,我用webdriver启动的浏览器没有评论,并且酒店的价格也不一样。原来是一个假数据。。。
这么一看那就是 selenium 被检测到了,所以也不考虑到底检测到了哪条属性,为了省时间,我直接用 ChromeOptions 切换成了开发者模式。(方法下面讲)
再次请求,对比数据后发现是一致的。

这个完成之后,感觉可以直接拿数据了吧,在采集时我发现,他的所有页面都是异步加载的。
也就是说,我在点击下一页的时候,url是不会改变的。
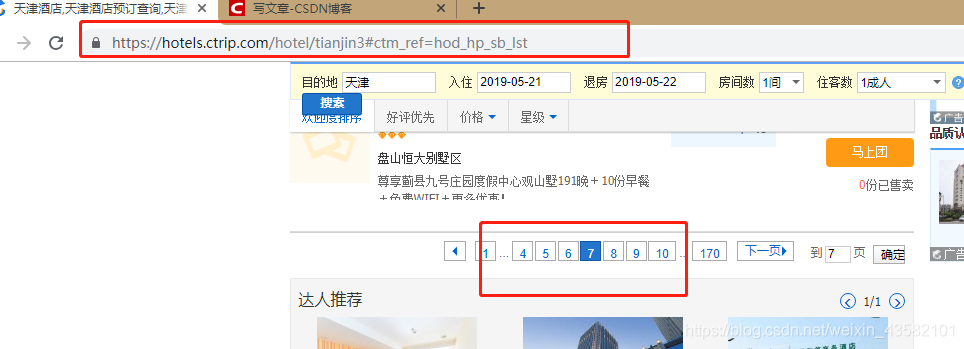
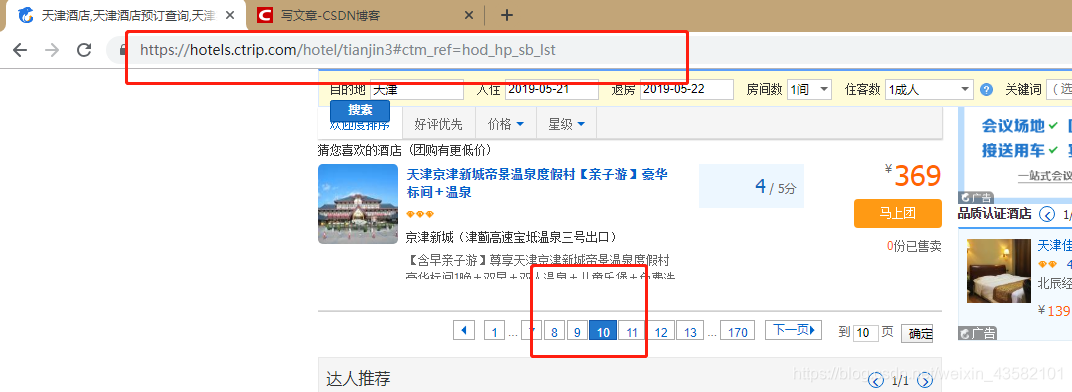
这个放代码讲吧。
首先绕过webdriver检测机制
from selenium import webdriver
import time
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
#option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path=“你的路径”,options=option)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
""" })
上面方法失效了,更换下面这个
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('useAutomationExtension',False)
chrome_options.add_argument("disable-blink-features")
chrome_options.add_argument("disable-blink-features=AutomationControlled")
driver=webdriver.Chrome(executable_path=r'你的路径',chrome_options =chrome_options)
然后请求我已经确定好的天津酒店列表页 url。
driver.get(‘https://hotels.ctrip.com/hotel/tianjin3#ctm_ref=hod_hp_sb_lst’)
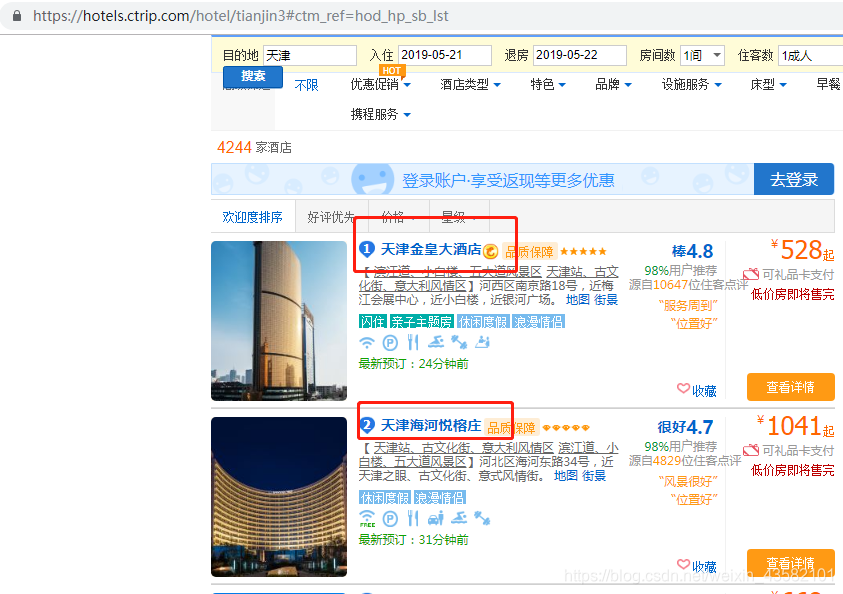
这里我要通过点击标题来访问到详情页,然后拿评论信息。
在这直接获取 xpath 来进行点击是不行的,因为有的标题他对应的xpath 并不是完全规范的。
所以我就观察了页面,他的这个data-id是每个都有的,所以可以通过获取他的ID来进行访问,
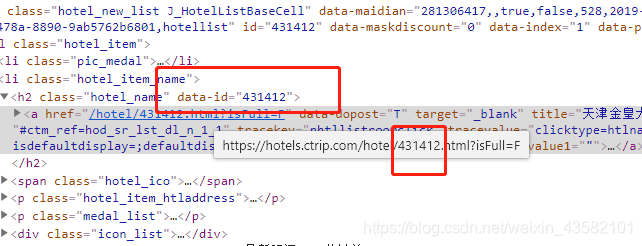
但是又有新问题了,在通过获取id后,来get新页面。在selenium中会覆盖当前窗口,一开始我用的是 driver.back(),在采集完后返回之前的列表页,但是因为上面说的他是异步加载的,每次back都只会返回到第一页。
所以这里我就换了种策略,在通过id打开窗口的时候,我新建一个窗口,然后对新窗口里面的属性进行操作,这样就不会影响之前的页面了,翻到了第几页都没事。
对了,页码是通过最下面的最大页数来判断的。
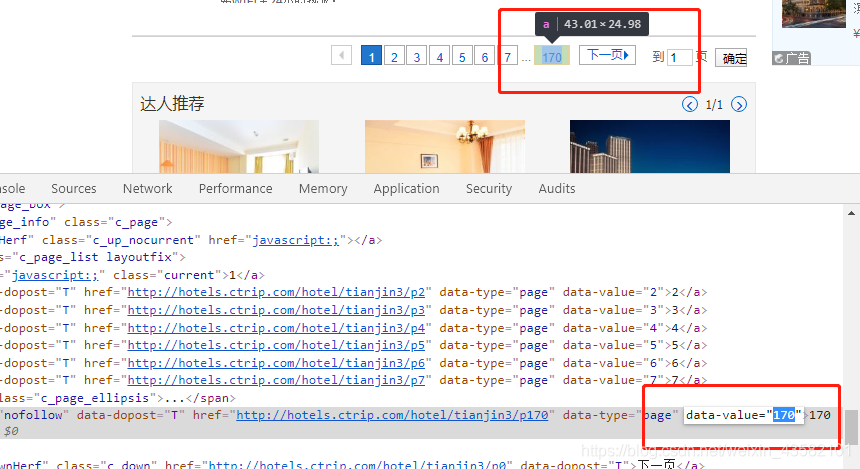
这里的代码:
mainWindow = driver.current_window_handle #保存主页面句柄
jiudian_page_max = driver.find_element_by_xpath('//*[@id="page_info"]/div[1]/a[8]').get_attribute('data-value')
for i in range(1,int(jiudian_page_max)):
time.sleep(2)
for i in range(1,26):
jiudian_id = driver.find_element_by_xpath('//*[@id="hotel_list"]/div[{}]'.format(i)).get_attribute('id')
#打开新的窗口,通过句柄来切换页面。
js = "window.open('{}')".format(f'https://hotels.ctrip.com/hotel/{jiudian_id}.html?isFull=F')
driver.execute_script(js)
new_handle = driver.current_window_handle
Handles = driver.window_handles
for handle in Handles:
if handle != mainWindow:
driver.switch_to_window(handle)
接着就是评论数据的采集了,这个倒是没有什么难度,也是通过给出的页数来获取最大页,然后循环去点击下一页。但是有些酒店是没有评论的 =。= 所以要加上try 异常操作
try:
page_max = driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[4]/div/div[1]/a[7]').get_attribute('value')
for j in range(int(page_max)):
print(f"* * * * * * ID:{jiudian_id} * * 第{j+1}页 * * * * * * * ")
for i in range(1,16):
try:
print(driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[3]/div[{}]/div[1]/p[2]/span'.format(i)).text)
print(driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[3]/div[{}]/div[2]/div/div[1]'.format(i)).text)
print('- - - - - - - - - - - - - - - - - - - - - ')
except:
pass
driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[4]/div/a[2]').click()
time.sleep(2)
driver.close() # close关闭当前的这个窗口,quit是关闭所以 !
except:
pass
在采集完一个酒店的所有评论数据之后,记得要关闭当前的窗口,然后再切换到最开始的窗口句柄。
time.sleep(2)
driver.switch_to_window(mainWindow)
最后是列表页的一页跑完了再去点击下一页。
driver.find_element_by_xpath('//*[@id="downHerf"]').click()
差不多了,可能说的不是很详细,有问题可以留言或者QQ联系我。
完整代码:
from selenium import webdriver
import time
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
# 按前文的绕过检测方法修改
option.add_experimental_option()
driver = webdriver.Chrome(executable_path=r'',options=option)
driver.get('https://hotels.ctrip.com/hotel/tianjin3#ctm_ref=hod_hp_sb_lst')
mainWindow = driver.current_window_handle #保存主页面句柄
jiudian_page_max = driver.find_element_by_xpath('//*[@id="page_info"]/div[1]/a[8]').get_attribute('data-value')
for i in range(1,int(jiudian_page_max)):
time.sleep(2)
for i in range(1,26):
jiudian_id = driver.find_element_by_xpath('//*[@id="hotel_list"]/div[{}]'.format(i)).get_attribute('id')
js = "window.open('{}')".format(f'https://hotels.ctrip.com/hotel/{jiudian_id}.html?isFull=F')
driver.execute_script(js)
new_handle = driver.current_window_handle
Handles = driver.window_handles
for handle in Handles:
if handle != mainWindow:
driver.switch_to_window(handle)
time.sleep(2)
try:
page_max = driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[4]/div/div[1]/a[7]').get_attribute('value')
for j in range(int(page_max)):
print(f"* * * * * * ID:{jiudian_id} * * 第{j+1}页 * * * * * * * ")
for i in range(1,16):
try:
print(driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[3]/div[{}]/div[1]/p[2]/span'.format(i)).text)
print(driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[3]/div[{}]/div[2]/div/div[1]'.format(i)).text)
print('- - - - - - - - - - - - - - - - - - - - - ')
except:
pass
driver.find_element_by_xpath('//*[@id="divCtripComment"]/div[4]/div/a[2]').click()
time.sleep(2)
driver.close()
except:
pass
time.sleep(2)
driver.switch_to_window(mainWindow)
driver.find_element_by_xpath('//*[@id="downHerf"]').click()


















 1640
1640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











