







task1-3:第一章:第三节探索性数据分析
在前面我们已经学习了Pandas基础,知道利用Pandas读取csv数据的增删查改,今天我们要学习的就是探索性数据分析,主要介绍如何利用Pandas进行排序、算术计算以及计算描述函数describe()的使用。
1 第一章:探索性数据分析
开始之前,导入numpy、pandas包和数据
#加载所需的库
import numpy as np
import pandas as pd
#载入之前保存的train_chinese.csv数据,关于泰坦尼克号的任务,我们就使用这个数据
df=pd.read_csv('train_chinese.csv')
df.head()

1.6 了解你的数据吗?
教材《Python for Data Analysis》第五章
1.6.1 任务一:利用Pandas对示例数据进行排序,要求升序
# 具体请看《利用Python进行数据分析》第五章 排序和排名 部分
#自己构建一个都为数字的DataFrame数据
#xample=pd.DataFrame(np.arange(8).reshape((2, 4)),
example=pd.DataFrame(np.random.randint(0, 20, size=(2,4)),
index=[2,1],
columns=['d', 'a', 'b', 'c'])
example

【代码解析】
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(2*4),第一列:0,1,2,3 第二列:4,5,6,7
index=['2, 1] :DataFrame 对象的索引列
columns=[‘d’, ‘a’, ‘b’, ‘c’] :DataFrame 对象的索引行
【问题】:大多数时候我们都是想根据列的值来排序,所以将你构建的DataFrame中的数据根据某一列,升序排列
#回答代码
example.sort_values(by='b')

【思考】通过书本你能说出Pandas对DataFrame数据的其他排序方式吗?
【总结】下面将不同的排序方式做一个总结
1.让行索引升序排序
#代码
example.sort_index()
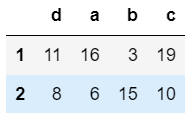
2.让列索引升序排序
#代码
example.sort_index(axis=1)
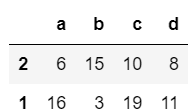
3.让列索引降序排序
#代码
example.sort_index(axis=1,ascending=False)
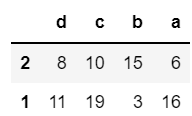
4.让任选两列数据同时降序排序
#代码
example.sort_values(by=['b','d'],ascending=False)

1.6.2 任务二:对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从这个数据中你可以分析出什么?
#代码
df.sort_values(by=['票价','年龄'],ascending=False).head(20)

【思考】排序后,如果我们仅仅关注年龄和票价两列。根据常识我知道发现票价越高的应该客舱越好,所以我们会明显看出,票价前20的乘客中存活的有14人,这是相当高的一个比例,那么我们后面是不是可以进一步分析一下票价和存活之间的关系,年龄和存活之间的关系呢?当你开始发现数据之间的关系了,数据分析就开始了。
当然,这只是我的想法,你还可以有更多想法,欢迎写在你的学习笔记中。
#代码
df.sort_values(by=['票价','年龄']).head(20)

票价最低的生还率很低
1.6.3 任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
# 具体请看《利用Python进行数据分析》第五章 算术运算与数据对齐 部分
#自己构建两个都为数字的DataFrame数据
#代码
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
print(frame1_a)
print(frame1_b)

将frame_a和frame_b进行相加
#代码
frame1_a+frame1_b

【提醒】两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
当然,DataFrame还有很多算术运算,如减法,除法等,有兴趣的同学可以看《利用Python进行数据分析》第五章 算术运算与数据对齐 部分,多在网络上查找相关学习资料。
1.6.4 任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人?
#代码
#还是用之前导入的chinese_train.csv如果我们想看看在船上,最大的家族有多少人(‘兄弟姐妹个数’+‘父母子女个数’),我们该怎么做呢?
max(df['兄弟姐妹个数']+df['父母子女个数'])

【提醒】我们只需找出”兄弟姐妹个数“和”父母子女个数“之和最大的数,当然你还可以想出很多方法和思考角度,欢迎你来说出你的看法。
1.6.5 任务五:学会使用Pandas describe()函数查看数据基本统计信息
#(1) 关键知识点示例做一遍(简单数据)
# 具体请看《利用Python进行数据分析》第五章 汇总和计算描述统计 部分
#自己构建一个有数字有空值的DataFrame数据
#代码
example2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
example2
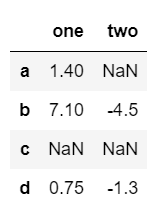
调用 describe 函数,观察frame2的数据基本信息
#代码
example2.describe()
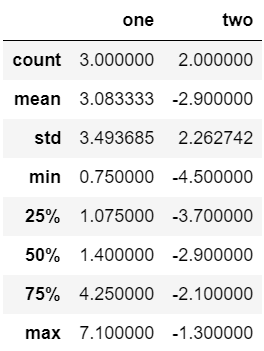
‘’’
count : 样本数据大小
mean : 样本数据的平均值
std : 样本数据的标准差
min : 样本数据的最小值
25% : 样本数据25%的时候的值
50% : 样本数据50%的时候的值
75% : 样本数据75%的时候的值
max : 样本数据的最大值
‘’’
1.6.6 任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么?
#看看泰坦尼克号数据集中 票价 这列数据的基本统计数据
#代码
df['票价'].describe()

import matplotlib.pyplot as plt
plt.hist(df['票价'],bins=10)

#看看泰坦尼克号数据集中 票价 这列数据的基本统计数据
#代码
df['父母子女个数'].describe()

import matplotlib.pyplot as plt
plt.hist(df['父母子女个数'],bins=10)

备注:本次学习资料源自DataWhale
动手学数据分析
航路开辟者:陈安东、金娟娟、杨佳达、老表、李玲、张文涛、高立业
领航员:范淑卷
航海士:武者小路、曾心怡
内容属性:精品入门课系列
开源内容:https://github.com/datawhalechina/hands-on-data-analysis
开源内容:https://gitee.com/datawhalechina/hands-on-data-analysis
B 站视频:https://www.bilibili.com/video/BV1Uv411p77r
内容说明:以项目为主线,通过边学,边做以及边被引导的方式,既掌握知识点又能掌握数据分析的大致思路和流程。
定位人群:懂一些python,希望入门数据分析的学习者。
http://datawhale.club















 6273
6273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









