







RDD持久化 和 checkpoint
RDD持久化
RDD复用存在重复计算的问题

如果一个RDD重复使用,只是RDD对象重用,但是数据不重用,因此会从头再次执行来获取数据;
代码演示RDD复用问题
package SparkCore._05_持久化
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* yatolovefantasy
* 2021-10-10-20:10
*/
object Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List("Hello Scala","Hello Spark")
val rdd =sc.makeRDD(list)
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(word => {
println("###########")
(word, 1)
})
// mapRDD 使用1
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("***************")
// mapRDD 使用2
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
}
}
执行结果: 可以看出来复用会导致从源头重复计算
###########
###########
###########
###########
(Hello,2)
(Spark,1)
(Scala,1)
***************
###########
###########
###########
###########
(Hello,CompactBuffer(1, 1))
(Spark,CompactBuffer(1))
(Scala,CompactBuffer(1))
RDD 持久化后复用 不需要从头计算
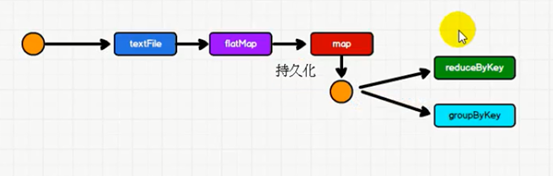
RDD持久化使用演示
package SparkCore._05_持久化
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* yatolovefantasy
* 2021-10-10-20:10
*/
object Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
val list = List("Hello Scala","Hello Spark")
val rdd =sc.makeRDD(list)
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(word => {
println("###########")
(word, 1)
})
//todo 1.对RDD做持久化
mapRDD.cache()
//todo 2.RDD复用
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("***************")
//todo 2.RDD复用
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
}
}
执行结果:
###########
###########
###########
###########
(Hello,2)
(Scala,1)
(Spark,1)
***************
(Hello,CompactBuffer(1, 1))
(Scala,CompactBuffer(1))
(Spark,CompactBuffer(1))
从执行结果来看,第二次直接从mapRDD后面开始执行,前面的代码没有再被执行
5.1 持久化的两种方式
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中。
cache与persist()
① RDD.cache() : 将数据保存到内存中
② RDD.persist()
cache()方法底层调用的就是persist(StorageLevel.MEMORY_ONLY)方法,持久化在内存中


5.2 持久化级别
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
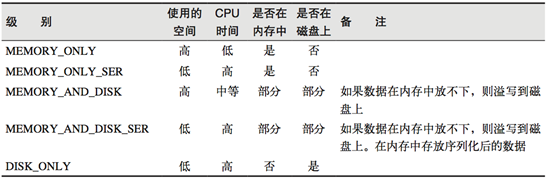
- Memory_only:只持久化到内存,内存不足,则丢弃数据
- 后缀有2的表示会做备份。
5.3持久化时机
- cache()和persist()两个方法不是被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
- 因为没有action算子,就不会执行,就不会有数据
5.4 持久化的应用场景
① RDD的数据重用
② RDD的血缘依赖比较长,某个RDD数据比较重要的时候,可以对这个RDD做持久化
5.5 持久化扩展知识
(1)持久化数据丢失,只重算受影响分区
RDD持久化数据是以分区为单位的,如果某个分区的缓存丢失了,比如存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition
(2)shuffle也会持久化
- Spark的Shuffle操作,中间数据也会做持久化操作(比如:reduceByKey),也就是一个stage和下一个stage交接处会产生持久化。
- 这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
CheckPoint
- 检查点其实就是通过将RDD中间结果写入磁盘
- CheckPoint必须要设置检查点路径,一般都是分布式文件系统中比如HDFS
1.使用演示
package SparkCore._05_持久化
import org.apache.spark.{SparkConf, SparkContext, rdd}
import org.apache.spark.rdd.RDD
/**
* yatolovefantasy
* 2021-10-10-20:29
*/
object checkpoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
//todo 1.设置检查点路径
sc.setCheckpointDir("hdfs://xxx")
val list = List("Hello Scala","Hello Spark")
val rdd =sc.makeRDD(list)
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(word => {
println("###########")
(word, 1)
})
//todo 2.ck
mapRDD.checkpoint()
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("***************")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
}
}
}
2.checkpoint源码

- Collect()算子再调用runjob方法后,会调用一个doCheckpoint(),如果设置了checkpoint()就会执行doCheckpoint();
- doCheckpoint()中会重新提交job,所以会执行两遍job
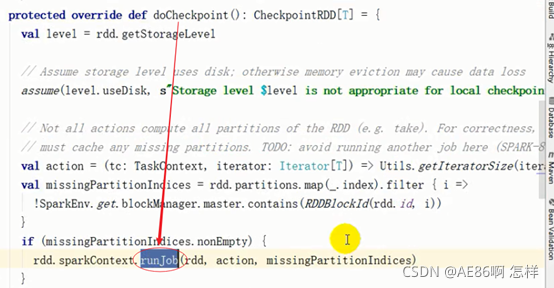
3.checkPoint()执行时机
- RDD的checkpoint操作并不会马上被执行,必须执行Action操作才能触发;
此时会将RDD中的数据写到检查点目录下; - 做checkpoint的时候,写入hdfs的数据主要包括:RDD每个分区的实际数据
4.checkpoint和cache的联合使用
- 由于在行动算子触发执行的时候,checkpoint会再次独立执行一遍作业,所以会在调用checkpoint()之前先做一个cache()操作,可以从缓存中取数据,避免了重头执行。
//todo 2.ck
mapRDD.cache()
mapRDD.checkpoint()
5.checkpoint会切断血缘关系
checkpoint 将数据写到hdfs之后,会调用rdd的markCheckPoint()方法,斩断该RDD对上游的依赖
(1)cache对血缘关系的影响
package SparkCore._05_持久化
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* yatolovefantasy
* 2021-10-10-20:29
*/
object checkpoint_血缘关系 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
//todo 1.设置检查点路径
//sc.setCheckpointDir("checkpoint")
val list = List("Hello Scala","Hello Spark")
val rdd =sc.makeRDD(list)
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(word => {
(word, 1)
})
mapRDD.cache()
//todo 1.在行动算子之前查看血缘关系
println(mapRDD.toDebugString)
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("***************")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
//todo 2.在行动算子之后查看血缘关系
println(mapRDD.toDebugString)
}
}
执行结果:
# 行动算子执行前的依赖关系
(16) MapPartitionsRDD[2] at map at checkpoint_血缘关系.scala:22 [Memory Deserialized 1x Replicated]
| MapPartitionsRDD[1] at flatMap at checkpoint_血缘关系.scala:20 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at makeRDD at checkpoint_血缘关系.scala:19 [Memory Deserialized 1x Replicated]
(Hello,2)
(Scala,1)
(Spark,1)
***************
# 行动算子执行后的依赖关系
(Hello,CompactBuffer(1, 1))
(Scala,CompactBuffer(1))
(Spark,CompactBuffer(1))
(16) MapPartitionsRDD[2] at map at checkpoint_血缘关系.scala:22 [Memory Deserialized 1x Replicated]
| CachedPartitions: 16; MemorySize: 624.0 B; ExternalBlockStoreSize: 0.0 B; DiskSize: 0.0 B
| MapPartitionsRDD[1] at flatMap at checkpoint_血缘关系.scala:20 [Memory Deserialized 1x Replicated]
| ParallelCollectionRDD[0] at makeRDD at checkpoint_血缘关系.scala:19 [Memory Deserialized 1x Replicated]
Process finished with exit code 0
1.行动算子执行之前,可以看到mapRDD的三个血缘关系
2.行动算子执行之后,会在血缘关系中添加新的依赖,一旦持久化失效了或者出现问题了,可以重头读取数据。
(2)checkpoint对血缘关系的影响
package SparkCore._05_持久化
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* yatolovefantasy
* 2021-10-10-20:29
*/
object checkpoint_血缘关系 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
//todo 1.设置检查点路径
sc.setCheckpointDir("checkpoint")
val list = List("Hello Scala","Hello Spark")
val rdd =sc.makeRDD(list)
val flatRDD: RDD[String] = rdd.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatRDD.map(word => {
(word, 1)
})
mapRDD.checkpoint()
//todo 1.在行动算子之前查看血缘关系
println(mapRDD.toDebugString)
val reduceRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("***************")
val groupRDD: RDD[(String, Iterable[Int])] = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
//todo 2.在行动算子之后查看血缘关系
println(mapRDD.toDebugString)
}
}
行动算子执行前:
 行动算子执行后:
行动算子执行后:

- Checkpoint执行后,会切断血缘关系,重新建立血缘关系。
- 因为checkpoint将rdd的结果保存到分布式文件系统中,等同于数据源发生了改变。
5.checkpoint和persist持久化的区别
1.checkpoint是持久化到磁盘中,persist可以持久化到内存也可以持久化到磁盘
2.persist持久化到磁盘中不需要设置路径,是因为persist持久化是临时文件,当作业(Job)执行完毕,该文件就会被删除,检查点则不会被删除,因此checkpoint是用于作业恢复的
3.血缘关系切断与否














 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









