







文章目录
一、条件概率
1. 介绍
条件概率:指在事件B发生的情况下,事件A发生的概率,用P(A|B)表示。

在事件B发生的情况下,事件A发生的概率:
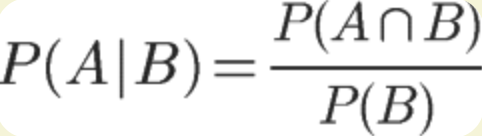
推导得:
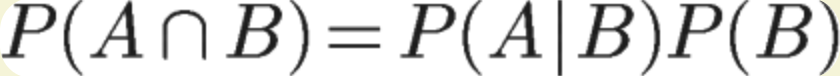
同理得:
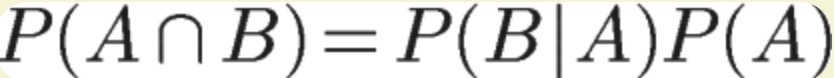
因此:
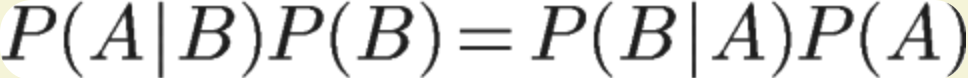
贝叶斯公式:
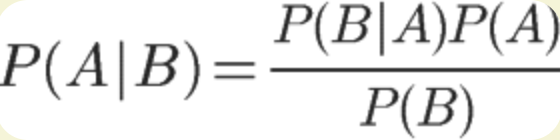
这里把P(A)称为“先验概率”,也就是在B事件发生之前,我们对A事件概率进行一个判断。P(A|B)称为“后验概率”,即在B事件发生之后,对A事件概率进行重新评估。
转化为分类任务的表达式:根据特征判断类别
P(类别|特征)= P(类别)*P(特征|类别)/P(特征)
2. 举例
有两个一模一样的碗,A1代表1号碗(有30颗水果糖,10颗巧克力糖),A2代表2号碗(有20颗水果糖,20颗巧克力糖)。现在随机选择一个碗,从中摸出一颗糖,发现是水果糖。请问这颗水果糖来自一号碗的概率有多大?
2.1 分析
在取出水果糖之前,这两个碗被选中的概率相同,P(A1)=0.5,这个就是先验概率,B代表水果糖,问题是在已知B的情况下,来自一号碗的概率有多大,即求
P(A1|B)。
2.2 计算
已知P(A1)=0.5,P(B|A1)表示从一号碗中取出水果糖的概率为0.75(30/40)
P(B)=P(B|A1)P(A1)+P(B|A2)P(A2)
P(B)=0.750.5+0.50.5=0.625
P(A1|B)=0.5*0.75/0.625=0.6
所以来自一号碗的概率是0.6
二、朴素贝叶斯种类
1、高斯朴素贝叶斯
先验为正态分布,需要计算的就是均值和方差
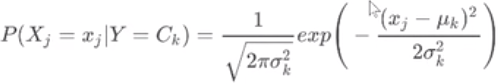
2、多项式朴素贝叶斯
先验为多项式分布的朴素贝叶斯,描述各种样本出现次数的概率。该模型常用于文本分类,特征表示的是次数,例如某个词语出现的次数。
3、伯努利朴素贝叶斯
先验为伯努利分布的朴素贝叶斯,只有两种取值,出现为1,不出现为0。在文本分类中,就是一个词语有没有在文档里出现。
三、拼字纠错案例
1. 介绍
当用户输入了一个不在字典中的单词,我们需要去猜测:“这个家伙到底真正想输入的单词是什么呢?”比如用户输入thew,那么猜测他到底想输入the,还是thaw,还是其他的单词?到底哪一个单词的可能性比较大?这时候我们就可以用贝叶斯去求出每个词语的可能性。
把我们的猜测记为h1、h2、…hn,他们都属于一个有限且离散的猜测空间H(单词总共就只有那么多,H代表hypothesis),将用户实际输入的单词记为D(D代表data,即观测数据)
目标求:P(我们猜测他想输入的单词 | 他实际输入的单词)=P(H|D)=P(H)*P(D|H)/P(D)
对于猜测1,可以表示为P(h1|D),对于猜测2,则表示为P(h2|D),我们需要计算这些概率值,取最大的。因为不论对哪一个具体猜测h1、h2、…hn,其中的P(D)都是一样的,所以在计算或比较P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略P(D)这个常数。公式简化为:
P(H | D) ∝ P(H) * P(D | H),其中∝代表正比例于。
解释:对于各种猜测,计算下P(H) * P(D | H) 这个值,然后取值为最大的那个猜测即可。
P(H) :某个正确的词的出现"概率",它可以用"频率"代替。
P(D | H):在试图拼写 H的情况下,出现拼写错误 D 的概率。
2. 代码实现
2.1 计算词频
# 定义 words() 函数,用来取出文本库的每一个词, 转成小写, 并且去除单词中间的特殊符号
def words(text): return re.findall('[a-z]+', text.lower())
# 做词频的统计,定义一个 train() 函数,用来建立一个"字典"结构。文本库的每一个词,都是这个"字典"的键;它们所对应的值,就是这个词在文本库的出现频率。
def train(features):
# 使用匿名函数,频数统一为1,避免先验概率为0的情况出现
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(open('big.txt').read()))
NWORDS
输出:

2.2 编辑距离
编辑距离:使用几步插入、替换、删除、交换的操作可以把一个词变为另外一个词,这几个步骤就叫作编辑距离,比如有the变为thy的编辑距离为1。根据用户输入的单词,得到其所有可能的拼写相近的形式。
alphabet = 'abcdefghijklmnopqrstuvwxyz'
# 返回所有单词与输入单词编辑距离=1的集合
def edits1(word):
n = len(word)
return set([word[0:i]+word[i+1:] for i in range(n)] + # 循环删除一个字符,比如the处理后为[th,he,te]
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # 调换一次位置,比如the处理后为[hte,teh]
[word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # 替换一个字符
[word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # 插入一个字符
比如“the”,运算结果为:
word = edits1('the')
word

# 返回一个与输入单词编辑距离为2的列表
def edits2(word):
# 返回只在词库中出现的单词
return set(e2 for e1 in editsl(word) for e2 in editsl(el))
2.3 计算拼错概率
# 在单词库中识别单词,并返回
def known(words):
return set(w for w in words if w in NWORDS)
# 定义correct()函数,用来从所有备选的词中,选出用户最可能想要拼写的词。
# 返回最优单词,如果是文本库现有的词,说明该词拼写正确,直接返回这个词;如果word不是现有的词,则返回"编辑距离"为1的词之中,在文本库出现频率最高的那个词;如果"编辑距离"为1的词,都不是文本库现有的词,则返回"编辑距离"为2的词中,出现频率最高的那个词;如果上述三条规则,都无法得到结果,则直接返回word。
def correct(word):
candidates = known([word]) or known(edits1(word)) or known_edit2(word) or [word]
return max(candidates, key=lambda w: NWORDS[w])
correct('clifw')
输出:
'cliff'















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









