






文本情感法分析的一般流程
原始数据获取(取得数据集或者网络爬虫)—>数据预处理(清洗去噪、分词、过滤等)—> 特征提取(依靠不同工具获得文本的数值向量表征“词频计数、词袋模型”)—> 分类器(输出得到文本的最终情感的极性“softmax、SVM”)
文本情感法分析的方法
文本情感分析方法大致分为三类,基于情感词典的情感分析方法、基于传统机器学习的分析方法、基于深度学习的分析方法。其中基于深度学习的分析方法中包含了单一神经网络的情感分析、混合(组合、融合)神经、网络的情感分析、引入注意力机制的情感分析、使用预训练模型的情感分析。
基于情感词典的情感分析方法
根据不同情感词典所提供的情感词的情感极性,来实现不同粒度下的情感极性 划分,主要过程是文本输入—>(预处理后)分词 —> 训练情感词典(将情感词典中的不同类型和程度的词语放入模型中进行训练)—> 根据判断规则输出。
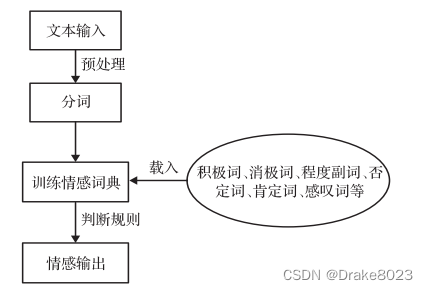
情感词典构建需要花费很大代价,对词语,情感强度需要有不同程度的标注。最早有SentiWordNet情感词典,它根据WordNet将含义一致的词语合并在一起,同时赋予词语正反面的极性分值,以此来表示情感态度。 中文情感词典主要有NTUSD、How Net 、情感词汇本体库组成,其分别包含了很多褒义词贬义词。
基于情感词典的方法可以准确反映文本的非结构化特征,易于分析和理解。在这种方法中,当情感词覆盖率和准确率高的情况下,情感分类效果比较准确。但这种方法仍然存在一定的缺陷:基于情感词典的情感分类方法主要依赖于情感词典的构建,而新型的网络用语等等迭代速度非常快以至于需要不停的扩充情感词典;情感词典中的同一情感词可能在不同时间、不同语言或不同领域中所表达的含义不同,因此基于情感词典的方法在跨领域和跨语言中的效果不是很理想;同时利用情感词典对于上下文的理解和语义关系没有涉及,故为提高解读的准确性,开始了对基于传统机器学习的情感分析研究。
基于传统机器学习的分析方法
是指通过大量有标注的或无标注的语料,使用统计机器学习算法,特征抽取,情感分析输出。其主要分为三类:有监督、半监督、无监督 的方法。
有监督的方法:通过给定带有情绪极性的样本集,可以分类得到不同的情感类别。依靠数据样本,和人工标记进行分类训练,从而得到相对准确的模型来进行情感分析。(KNN、朴素贝叶斯、SVM)
半监督的方法:通过对未标记的文本进行特征提取可以有效地改善文本情感分类结果,此方法在具有少量标记数据的情况下,可以有效的提高情感分析的准确度。
无监督的方法:根据文本间的相似性对未标记的文本进行分类,一般很少见。
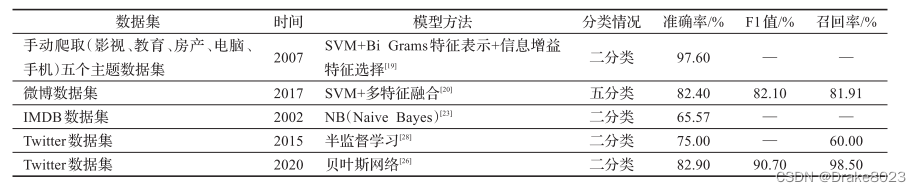
在有监督的机器学习方法中,有研究表明通过大量的对比实验发现采用BiGrams特征表示方法、信息增益特征选择方法和SVM方法时,在大量训练集和适量的特征选择时情感分类效果可以达到最优。基于传统机器学习的情感分类方法主要在于情感特征的提取以及分类器的组合选择,不同分类器的组合选择对情感分析的结果有存在一定的影响,这类方法在对文本内容进行情感分析时常常不能充分利用上下文文本的语境信息,因此其分类准确性有一定的影响。为了不忽略上下文语义问题,许多学者对基于深度学习的情感分析方法进行深入的研究。
基于深度学习的分析方法
基于深度学习的情感分析方法细分,可以分为:单一神经网络的情感分析方法、混合(组合、融合)神经网络的情感分析方法,引入注意力机制的情感分析和使用预训练模型的情感分析。
单一神经网络的情感分析方法
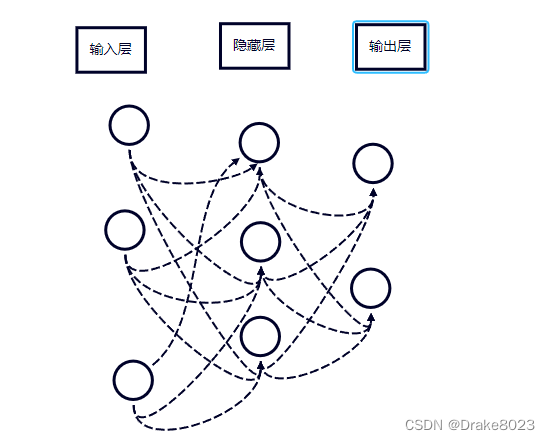
早在2003年就提出了神经网络语言模型——使用了三层前馈神经网络建模,主要由输入层、隐藏层、输出层构成。在该网络的输入层的每个神经元代表一个特质,隐藏层层数及隐藏层神经元是由人工设定,输出层代表分类标签的个数。语言模型的本质就是根据上下文信息来预测下一个词的内容,而不依赖人工标注语料,这种方法能够有效解决基于传统情感分析方法中忽略上下文语义的问题。
典型的神经网络学习方法有:卷积神经网络(Con-volutional Neural Network,CNN)、递归神经网络(Recurrent Neural Network,RNN)[31]、长短时记忆(Long Short-Term Memory,LSTM)网络等。
混合(组合、融合)神经网络的情感分析方法
在对单一神经网络方法研究之余,考虑到不同方法的优点进行结合改进产生了许多混合神经网络情感分析的方法。比如SCASRN一种顺序卷积注意递归网络结合了循环神经网络与卷积结构的优点。也有利用联合循环神经网络和卷积神经网络形成一种多层网络模型H-RNN-CNN,使用了两层RNN对文本建模,实现对长文本的情感分类。等等还有许多,参数化卷积神经网络使用了参数化过滤器(PF-CNN)和参数化门机制(PG-CNN)。共享时间卷积网络Bi-TCN,单向多层空洞因果卷积结构分别对文本进行前向和后向特征提取,将两个方向的序列特征融合后进行情感分类。基于CNN-LSTM神经网络的情感分类方法,在短文本评论中对含有隐含的语义的短文本评论中的情感倾向性识别取得不错的效果。基于多通道双向长短期记忆网络的情感分析模型(Multi-channels Bi-directional Long Short Term Memory net-work,Multi-Bi-LSTM),该模型对情感分析任务中现有的语言知识和情感资源进行建模,生成不同的特征通道,让模型充分学习句子中的情感信息。
采用神经网络的方法在文本特征学习方面有显著优势,能主动学习特征,并对文本中的词语的信息主动保留,从而更好地提取到相应词语的语义信息,来有效实现文本的情感分类。
引入注意力机制的情感分析
基于深度学习的方法是采用连续、低维度的向量来表示文档和词语,因此能有效解决数据稀疏的问题;此外,基于深度学习的方法属于端到端的方法,能自动提取文本特征,降低文本构建特征的复杂性。
注意力机制(attention mechanism)最早的应用是在视觉图像领域,研究者在RNN模型上使用了注意力机制来实现图像分类,随后通过将注意力机制应用在机器翻译任务中,这也意味着注意力机制开始应用到自然语言处理领域中。2017年Google机器翻译团队提出用 Attention机制代替传统RNN方法搭建了整个模型框架,并提出了多头注意力(Multi-head attention)机制:
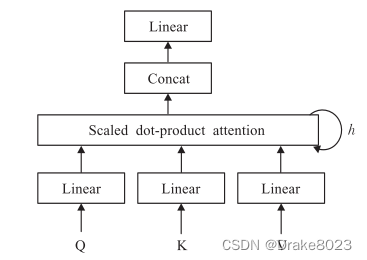
其中Q、K、V首先经过一个线性变换,然后输入到放缩点积Attention(Scaled Dot-Product attention)中,进行 h 次计算(多头)。将h次的放缩点积Attention结果进行拼接和线性变换得到的值作为多头Attention的结果。
注意力机制可以扩展神经网络的能力,允许近似更加复杂函数,关注输入的特定部分,在神经网络上使用这种机制可以有效地提NLP任务性能。
预训练模型的情感分析
预训练模型是指用数据集已经训练好的模型。通过对预训练模型的微调,可以实现较好的情感分类结果,因此最新的方法大多是使用预训练模型,最新的预训练模型有:ELMo、BERT、XL-NET、ALBERT等。
Peters等人在2018年的NAACL会议(The North American Chapter of the Association for Computational Linguistics,计算机语言学协会北美分会)提出一个新方法ELMo,该方法使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然值。和传统词向量方法相比,这种方法的优势在于每一个词只对应一个词向量。ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。
2018年10月谷歌公司提出一种基于BERT[59]的新方法,它将双向的transformer机制用于语言模型,充分考虑到单词的上下文语义信息。在模型的输入方面BERT使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。许多研究者通过对BERT模型的微调训练,在情感分类中取得了不错的效果。
通过和传统方法相比,使用语言模型预训练的方法充分利用了大规模的单语语料,可以对一词多义进行建模,使用语言模型预训练的过程可以被看作是一个句子级别的上下文词表示。通过对大规模语料预训练,使用一个统一的模型或者将特征加到一些简单的模型中,在很多NLP任务中取得了不错的效果,说明这种方法在缓解对模型结构的依赖问题上有明显的效果。因此,可以预知未来的情感分析方法将更加专注于研究基于深度学习的方法,并且通过对预训练模型的微调,实现更好的情感分析效果。
参考文献:《文本情感分析方法研究综述》 来源:文本情感分析方法研究综述 (ceaj.org)

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









