






1.概述
对于多值输出的问题,投票法是最常用也是最基本的结合方法。以分类问题为例解释投票法的工作机理。假设我们有 T T T 个不同的分类器 { h 1 , … , h T } \left \{ h_1,\dots,h_T\right \} {h1,…,hT} ,任务是结合它们的输出以从 l l l 个类别标记 { c 1 , … , c l } \left \{ c_1,\dots,c_l\right \} {c1,…,cl} 中预测出最终输出类别。对于示例 x x x ,分类器 h i h_i hi 的输出结果为一个 l l l 维标记向量 ( h i 1 ( x ) , … , h i l ( x ) ) T \left ( h_i^1\left ( x \right ),\dots,h_i^l\left ( x \right ) \right ) ^T (hi1(x),…,hil(x))T ,其中 h i j ( x ) h_i^j\left ( x \right ) hij(x) 为分类器 h i h_i hi 在类别标记 c j c_j cj 上的预测输出。 h i j ( x ) h_i^j\left ( x \right ) hij(x) 会根据个体分类器提供的信息取不同类型的值,包括:
- 二值标记: h i j ( x ) ∈ { 0 , 1 } h_i^j\left ( x \right )\in \left \{ 0,1 \right \} hij(x)∈{0,1} ,若 h i h_i hi 预测 c j c_j cj 为类别,则为1,否则为0;
- 类别概率: h i j ( x ) ∈ [ 0 , 1 ] h_i^j\left ( x \right )\in \left [0,1 \right ] hij(x)∈[0,1] , 可以认为是后验概率 P ( c j ∣ x ) P\left ( c_j|x \right ) P(cj∣x) 的估计。
大多数分类器估计出来的类别概率会比较差,而基于类别概率的结合方法,特别是精心校准后,常比基于二值标记的方法更有竞争力。
2.绝对多数投票法
绝对多数投票法是最常用的投票法方法。其中,每个分类器都会给一个类别标记进行投票,最终输出类别标记为获取票数过半的标记;如果所有类别标记获取票数均不过半,则拒绝预测。集成的输出类别标记可表示为:
H ( x ) = { c j 若 ∑ i = 1 T h i j ( x ) > 1 2 ∑ k = 1 l ∑ i = 1 T h i k ( x ) 拒 绝 其他 H\left ( x \right ) =\begin{cases}c_j & \text{ 若 } {\textstyle \sum_{i=1}^{T}h_i^j\left ( x \right )>\frac{1}{2} {\textstyle \sum_{k=1}^{l} {\textstyle \sum_{i=1}^{T}h_i^k\left ( x \right ) } } } \\ 拒绝& \text{ 其他 } \end{cases} H(x)={cj拒绝 若 ∑i=1Thij(x)>21∑k=1l∑i=1Thik(x) 其他
当使用由
T
T
T 个分类器组成的集成求解二分类问题时,只有
⌊
T
/
2
+
1
⌋
\left \lfloor T/2+1 \right \rfloor
⌊T/2+1⌋ 个或更多分类器分类正确时,集成才会分类正确。假设这些分类器相互独立且精度为
p
p
p ,即:每个分类器正确分类的概率为
p
p
p ,那么集成分类正确的概率可以基于二项分布计算获得,即:在
T
T
T 个分类器中至少
⌊
T
/
2
+
1
⌋
\left \lfloor T/2+1 \right \rfloor
⌊T/2+1⌋ 个分类正确的概率为
P
m
v
=
∑
k
=
⌊
T
/
2
+
1
⌋
T
(
T
k
)
p
k
(
1
−
p
)
T
−
k
P_{mv}=\sum_{k=\left \lfloor T/2+1 \right \rfloor }^{T} \begin{pmatrix}T \\ k\end{pmatrix}p^k\left ( 1-p \right )^{T-k}
Pmv=k=⌊T/2+1⌋∑T(Tk)pk(1−p)T−k
- 如果 p > 0.5 p>0.5 p>0.5 ,则 p m v p_{mv} pmv 随着 T T T 单调递增,且 lim T → + ∞ P m v = 1 \textstyle \lim_{T \to +\infty } P_{mv}=1 limT→+∞Pmv=1
- 如果 p < 0.5 p<0.5 p<0.5 ,则 p m v p_{mv} pmv 随着 T T T 单调递减,且 lim T → + ∞ P m v = 0 \textstyle \lim_{T \to +\infty } P_{mv}=0 limT→+∞Pmv=0
- 如果 p = 0.5 p=0.5 p=0.5 ,对任意 T T T , p m v = 0.5 p_{mv}=0.5 pmv=0.5
需要注意以上分析的基本假设,即个体分类器在统计上是相互独立的,在实际问题中,由于分类器为同一问题所训练,通常会强相关。因此,期望绝对多数投票法的精度随着个体训练器数目的增长而收敛到1,并不现实。
3.相对多数投票法
绝对多数投票法要求获胜方至少获票一半,与之不同的是,相对多数投票法仅需获胜方获取票数最多即可。也就是说,集成输出标记可表示为
H
(
x
)
=
c
a
r
g
max
j
∑
i
=
1
T
h
i
j
(
x
)
H\left ( x \right ) =c_{arg\max_{j} {\textstyle \sum_{i=1}^{T}}h_i^j\left ( x \right ) }
H(x)=cargmaxj∑i=1Thij(x)
而平局时则任选一个。相对多数投票法总是可以找到获得票数最多的标记,因此并无拒绝选项。在二分类问题中,它和绝对多数投票法一致。
4.加权投票法
若个体分类器性能不均等,直观来讲,投票时给性能强的分类器更高权重是合理的。这一策略可以通过加权投票法实现。此时,集成输出类别可表示为
H
(
x
)
=
c
a
r
g
max
j
∑
i
=
1
T
w
i
h
i
j
(
x
)
H\left ( x \right ) =c_{arg\max_{j} {\textstyle \sum_{i=1}^{T}w_ih_i^j\left (x \right ) } }
H(x)=cargmaxj∑i=1Twihij(x)
其中,
w
i
w_i
wi 表示分类器
h
i
h_i
hi 的权重。在实际应用中,权重系数往往会归一化,且被约束为
w
i
≥
0
w_i\ge 0
wi≥0 和
∑
i
=
1
T
w
i
=
1
{\textstyle \sum_{i=1}^{T}w_i=1}
∑i=1Twi=1 。
当赋予合适的权重时,加权投票法可以做到既优于最优的个体分类器,又优于绝对多数投票法。问题的关键在于如何获取合适的权重。
设
l
=
(
l
1
,
…
,
l
T
)
T
l=\left ( l_1,\dots,l_T \right )^T
l=(l1,…,lT)T 为个体分类器的输出,其中
l
i
l_i
li 表示分类器
h
i
h_i
hi 在示例
x
x
x 上的类别标记预测结果, 设
p
i
p_i
pi 为
h
i
h_i
hi 的精度,则类别标记
c
j
c_j
cj 的结合输出可以用一种贝叶斯最优判别函数来表达,即
H
j
(
x
)
=
log
(
P
(
c
j
)
P
(
l
∣
c
j
)
)
H^j\left ( x \right ) =\log_{}\left ( {P\left ( c_j \right )P\left ( l|c_j \right ) } \right )
Hj(x)=log(P(cj)P(l∣cj))
假设个体分类器的输出条件独立,即
P
(
l
∣
c
j
)
=
∏
i
=
1
T
P
(
l
i
∣
c
j
)
P\left ( l|c_j \right )= {\textstyle \prod_{i=1}^{T}P\left ( l_i|c_j \right ) }
P(l∣cj)=∏i=1TP(li∣cj) ,则该函数遵从
H
j
(
x
)
=
log
P
(
c
j
)
+
∑
i
=
1
T
log
P
(
l
i
∣
c
j
)
=
log
P
(
c
j
)
+
log
(
∏
i
=
1
,
l
i
=
c
j
T
P
(
l
i
∣
c
j
)
∏
i
=
1
,
l
i
≠
c
j
T
P
(
l
i
∣
c
j
)
)
=
log
P
(
c
j
)
+
log
(
∏
i
=
1
,
l
i
=
c
j
T
p
i
∏
i
=
1
,
l
i
≠
c
j
T
(
1
−
p
i
)
)
=
log
P
(
c
j
)
+
∑
i
=
1
,
l
i
=
c
j
T
log
p
i
1
−
p
i
+
∑
i
=
1
T
log
(
1
−
p
i
)
\begin{aligned} H^j(x) &= \log_{}{P( c_j ) }+\sum_{i=1}^{T}\log_{}{P(l_i|c_j )}\\ &=\log_{}{P\left ( c_j \right ) }+\log_{}{\left (\prod_{i=1,l_i=c_j}^{T} P\left ( l_i|c_j \right ) \prod_{i=1,l_i\ne c_j}^{T} P\left ( l_i|c_j \right ) \right ) } \\ &=\log_{}{P\left ( c_j \right ) }+\log_{}{\left (\prod_{i=1,l_i=c_j}^{T} p_i\prod_{i=1,l_i\ne c_j}^{T}\left (1-p_i \right ) \right ) } \\ &=\log_{}{P\left ( c_j \right ) }+\sum_{i=1,l_i=c_j}^{T}\log_{}{\frac{p_i}{1-p_i} } +\sum_{i=1}^{T}\log_{}{\left (1-p_i \right ) } \end{aligned}
Hj(x)=logP(cj)+i=1∑TlogP(li∣cj)=logP(cj)+log⎝⎛i=1,li=cj∏TP(li∣cj)i=1,li=cj∏TP(li∣cj)⎠⎞=logP(cj)+log⎝⎛i=1,li=cj∏Tpii=1,li=cj∏T(1−pi)⎠⎞=logP(cj)+i=1,li=cj∑Tlog1−pipi+i=1∑Tlog(1−pi)
由于
∑
i
=
1
T
log
(
1
−
p
i
)
\sum_{i=1}^{T}\log_{}{\left (1-p_i \right ) }
∑i=1Tlog(1−pi) 并不依赖类别标记
c
j
c_j
cj ,且
l
i
=
c
j
l_i=c_j
li=cj 可以使用
h
i
j
(
x
)
h_i^j(x)
hij(x) 来表示,上述判别函数可以约减为
H
j
(
x
)
=
log
P
(
c
j
)
+
∑
i
=
1
T
h
i
j
(
x
)
log
p
i
1
−
p
i
H^j(x)=\log_{}{P(c_j)}+\sum_{i=1}^{T}h_i^j(x)\log_{}{\frac{p_i}{1-p_i} }
Hj(x)=logP(cj)+i=1∑Thij(x)log1−pipi
等式右侧第一项并不依赖于个体分类器,而第二项表明加权投票法的最优权重满足
w
i
∝
log
p
i
1
−
p
i
w_i\propto \log_{}{\frac{p_i}{1-p_i} }
wi∝log1−pipi
即:最优权重需和个体分类器的性能保持一致。
需要注意的是,上式成立的前提是个体分类器的输出相互独立,但是个体分类器都是针对同一问题训练获得,其输出通常强相关,独立性假设并不成立。此外,该方法需要预估个体分类器真实的预测精度,并且不考虑类别先验。所以按照上式取权重在实际应用中并不保证性能一定优于绝对多数投票法。
5.软投票法
对于生成二值类别标记的个体分类器,可以使用绝对多数投票法、相对多数投票法和加权投票法,而对于生成类概率的个体分类器,通常会采用软投票法。在软投票过程中,个体分类器
h
i
h_i
hi 对示例
x
x
x 输出一个
l
l
l 维的向量
(
h
i
1
(
x
)
,
…
,
h
i
l
(
x
)
)
T
\left ( h_i^1(x),\dots,h_i^l(x) \right )^T
(hi1(x),…,hil(x))T ,其中
h
i
j
(
x
)
∈
[
0
,
1
]
h_i^j(x)\in [0,1]
hij(x)∈[0,1] 可以看成是对后验概率
P
(
c
j
∣
x
)
P(c_j|x)
P(cj∣x) 的预估结果。
如果平等对待全部个体分类器,则可以使用简单软投票法来生成结合输出,即对各个个体分类器的输出进行简单平均,类别
c
j
c_j
cj 的最终输出可以表示为
H
j
(
x
)
=
1
T
∑
i
=
1
T
h
i
j
(
x
)
H^j(x)=\frac{1}{T}\sum_{i=1}^{T}h_i^j(x)
Hj(x)=T1i=1∑Thij(x)
如果考虑赋予不同个体分类器不同的结合权重,加权软投票法可以采取如下任一形式:
-
分类器专属权重:为每一类分类器赋予特定的权重,类别 c j c_j cj 的结合输出为
H j ( x ) = 1 T ∑ i = 1 T w i h i j ( x ) H^j(x)=\frac{1}{T}\sum_{i=1}^{T}w_ih_i^j(x) Hj(x)=T1i=1∑Twihij(x)
其中 w i w_i wi 表示赋予分类器 h i h_i hi 的权重。 -
类别专属权重:为每个分类器 的每个类别赋予特定的权重,类别 c j c_j cj 的结合输出为
H j ( x ) = 1 T ∑ i = 1 T w i j h i j ( x ) H^j(x)=\frac{1}{T}\sum_{i=1}^{T}w_i^jh_i^j(x) Hj(x)=T1i=1∑Twijhij(x)
其中 w i j w_i^j wij 表示赋予分类器 h i h_i hi 中类别 c j c_j cj 的权重。 -
样本专属权重:为每一分类器中的每个类别的样本赋予不同的权重,类别 c j c_j cj 的结合输出为
H j ( x ) = 1 T ∑ i = 1 T ∑ k = 1 m w i k j h i j ( x ) H^j(x)=\frac{1}{T}\sum_{i=1}^{T}\sum_{k=1}^{m} w_{ik}^jh_i^j(x) Hj(x)=T1i=1∑Tk=1∑mwikjhij(x)
其中 w i k j w_{ik}^j wikj 表示赋予分类器 h i h_i hi 中类别 c j c_j cj 的样本 x k x_k xk 的权重。
实践中,第三种方法涉及大量权重系数,一般不会采用;第一种方法类似于加权平均法或加权投票法;这里主要研究第二种方法,即类别专属权重。由于 h i j ( x ) h_i^j(x) hij(x) 可视为 P ( c j ∣ x ) P(c_j|x) P(cj∣x) 的一个预估,遵从
h i j ( x ) = P ( c j ∣ x ) + ϵ i j ( x ) h_i^j(x)=P(c_j|x)+\epsilon_i^j(x) hij(x)=P(cj∣x)+ϵij(x)
其中 ϵ i j ( x ) \epsilon_i^j(x) ϵij(x) 表示近似误差。在分类问题中,目标输出是一个类别标记。如果预估无偏,结合获得的输出 H j ( x ) = 1 T ∑ i = 1 T w i j h i j ( x ) H^j(x)=\frac{1}{T}\sum_{i=1}^{T}w_i^jh_i^j(x) Hj(x)=T1∑i=1Twijhij(x) 也是无偏的。对于 P ( c j ∣ x ) P(c_j|x) P(cj∣x) ,通过设定权重,可以得到一个方差最小化的无偏估计 H j ( x ) H^j(x) Hj(x) 。在约束 w i j ≥ 0 w_i^j\ge 0 wij≥0 和 ∑ i = 1 T w i j = 1 {\textstyle \sum_{i=1}^{T}}w_i^j=1 ∑i=1Twij=1 下,最小化近似误差 ∑ i = 1 T w i j ϵ i j ( x ) {\textstyle \sum_{i=1}^{T}}w_i^j\epsilon_i^j(x) ∑i=1Twijϵij(x) ,可以得到优化问题
w j = a r g min w j ∑ k = 1 m ( ∑ i = 1 T w i j h i j ( x k ) − 1 ( f ( x k ) = c j ) ) 2 , j = 1 , … , l w^j=arg\min_{w^j}\sum_{k=1}^{m}\left (\sum_{i=1}^{T}w_i^jh_i^j(x_k)-\mathbb{1}\left (f(x_k)=c_j \right ) \right )^2,j=1,\dots ,l wj=argwjmink=1∑m(i=1∑Twijhij(xk)−1(f(xk)=cj))2,j=1,…,l
求解该问题可以得到所需权重。
需要注意的是,软投票法通常用于同质集成。对于异质集成,在没有经过精细校准的情况下,不同类型学习器生成的类别概率通常是不能直接比较的。此时,通常现将类别概率输出转换为类别标记输出,然后使用针对硬标记的投票方法来解决。
6.具体案例
(1)硬投票法
首先我们创建一个1000个样本,20个特征的随机数据集:

我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:

然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。

下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。

然后,我们可以报告每个算法的平均性能,还可以创建一个箱形须状图来比较每个算法的精度分数分布。

knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard_voting 0.902 (0.034)

显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
(2)加权硬投票法
根据模型准确率,计算模型的权重:

因为各模型准确率接近,所以各模型的权重也差不多。
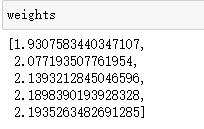
使用加权硬投票法的模型,需要利用计算好的权重:

运行加权硬投票法模型‘h_w’,查看结果并比较:

加权硬投票法的结果与普通硬投票法相同,原因是各分类模型性能相近,导致权重接近,加权对最终结果无影响。
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard_voting 0.902 (0.034)
h_w 0.902 (0.034)

(3)软投票法
只要把硬投票法里的参数 voting=‘hard’ 改成 voting=‘soft’ 即可得到相对应的软投票法,这里代码不再赘述,直接呈现结果。
在这个实验中,软投票结果准确率不如硬投票,采用与加权硬投票法相同的权重系数加权后,准确率也几乎没有变化。
knn1 0.873 (0.030)
knn3 0.889 (0.038)
knn5 0.895 (0.031)
knn7 0.899 (0.035)
knn9 0.900 (0.033)
hard 0.902 (0.034)
h_w 0.902 (0.034)
soft 0.897 (0.029)
s_w 0.897 (0.030)

本文理论部分来自《集成学习:基础与算法》/周志华著;李楠译。
后面实验部分借鉴了Datawhale的开源学习内容,链接是https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning
感谢Datawhale对开源学习的贡献!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









