







数据预处理
1.无量纲化
1.1 最值归一化(MinMaxScaler)
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
minMaxScaler = MinMaxScaler().fit_transform(X_train)
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。
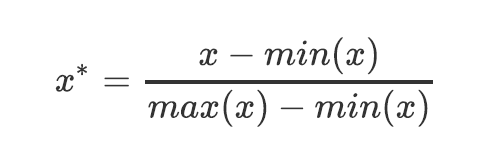
缺点:
- 这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义;
- MinMaxScaler对异常值的存在非常敏感。
1.2 均值方差归一化(StandardScaler)
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
standardScaler = StandardScaler().fit_transform(X_train)
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),就叫做数据标准化(Standardization,又称Z-score normalization)
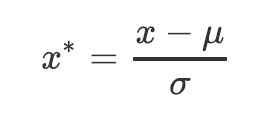
优点:
- Z-Score最大的优点就是简单,容易计算,Z-Score能够应用于数值型的数据,并且不受数据量级的影响,因为它本身的作用就是消除量级给分析带来的不便。
缺点:
- 估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代;
- Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的;
- Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值;
- 在存在异常值时无法保证平衡的特征尺度。
一般来说,建议优先使用标准化。对于输出有要求时再尝试别的方法,如归一化或者更加复杂的方法。
2.缺失值处理
2.1 impute.SimpleImputer
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer()
imp_mean = imp_mean.fit_transform(Age)
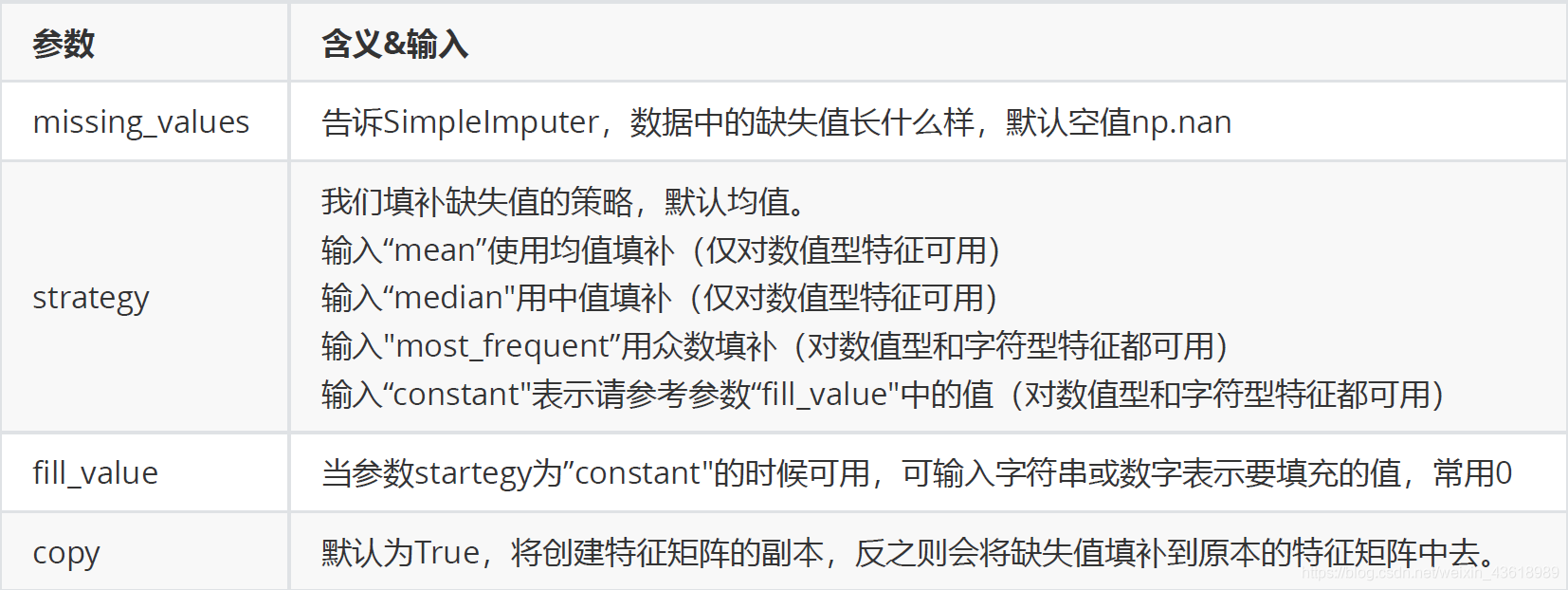
class sklearn.impute.SimpleImputer (missing_values=nan, strategy=’mean’, fill_value=None, verbose=0,copy=True)
3.处理分类型特征
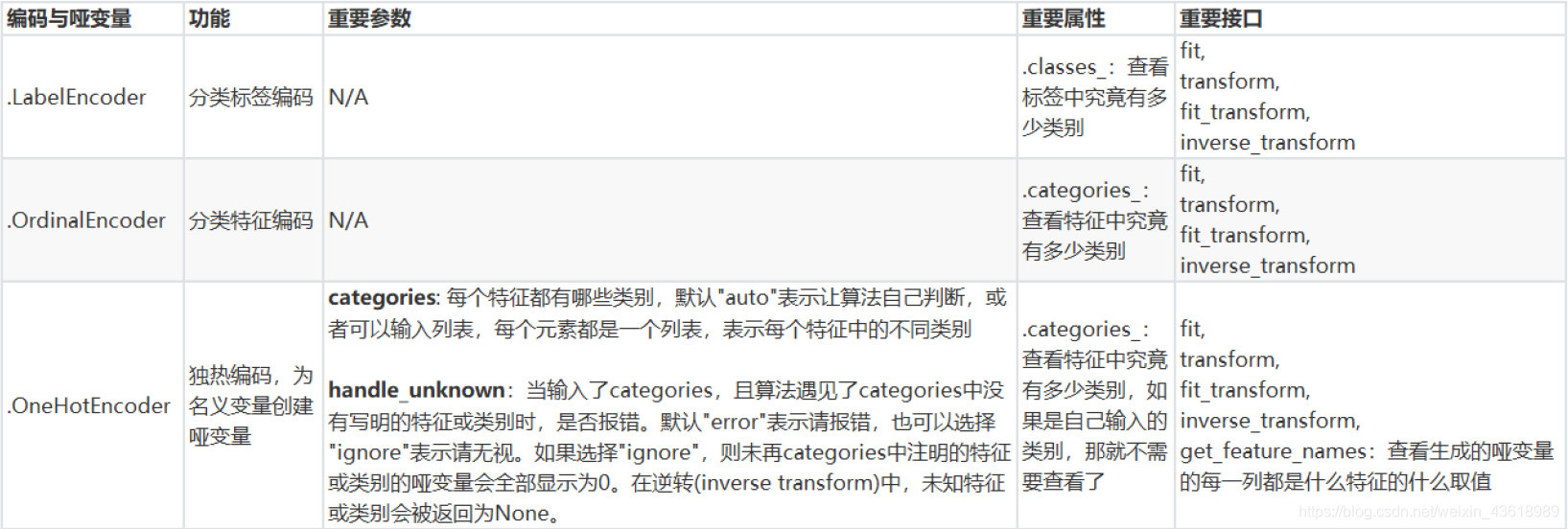
3.1 标签编码(preprocessing.LabelEncoder)
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
LabelEncoder:标签专用,能够将分类转换为分类数值
3.2 特征编(preprocessing.OrdinalEncoder)
from sklearn.preprocessing import OrdinalEncoder
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
3.3 哑变量(preprocessing.OneHotEncoder)
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
result
OneHotEncoder:独热编码,创建哑变量
4.处理连续型特征
4.1 二值化(preprocessing.Binarizer)
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X)
preprocessing.Binarizer:根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量
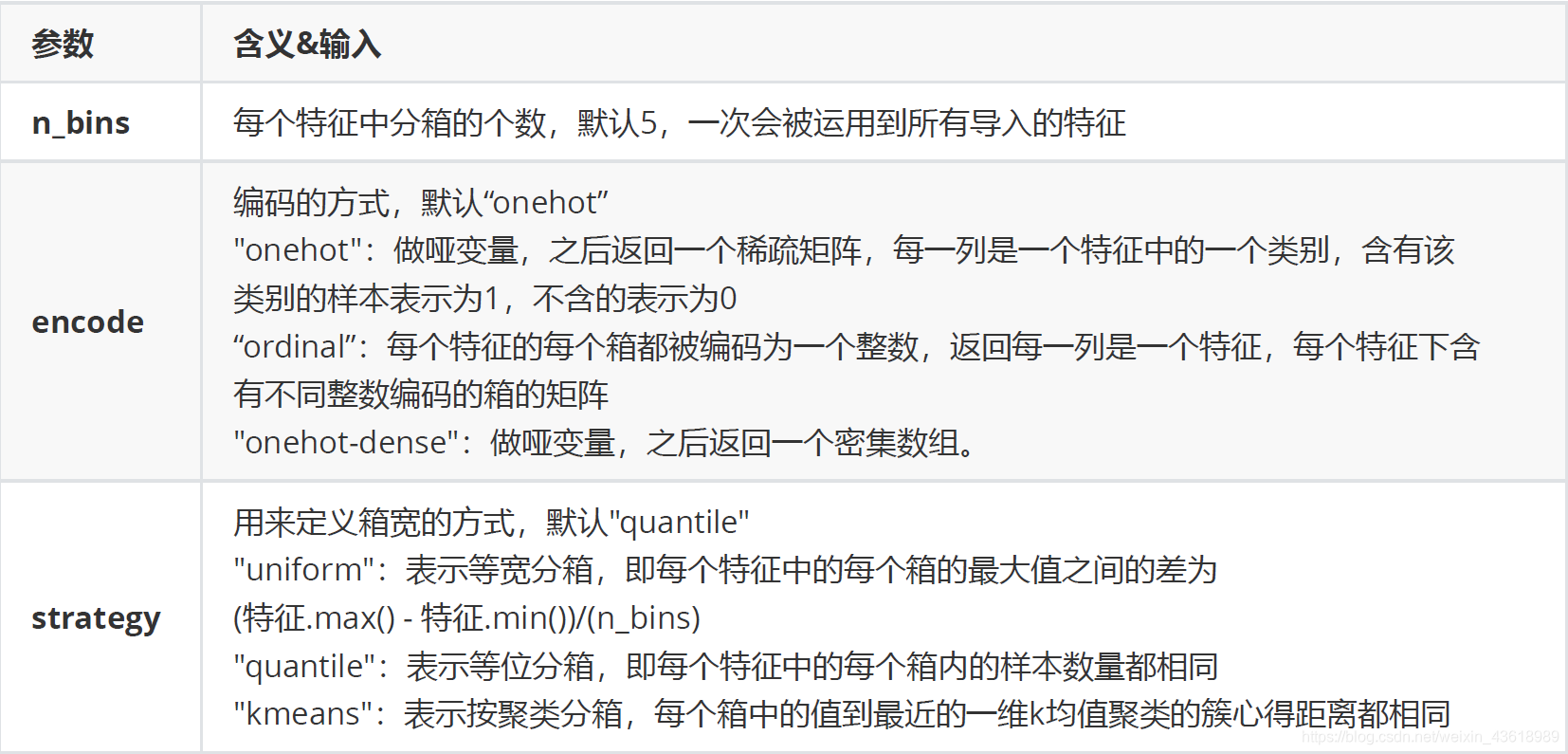
4.2 分段(preprocessing.KBinsDiscretizer)
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)
preprocessing.KBinsDiscretizer:将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码














 2963
2963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









