







Spark Local模式环境搭建和使用
Spark是一个开源的可应用于大规模数据处理的分布式计算框架,该框架可以独立安装使用,也可以和Hadoop一起安装使用。为了让Spark可以使用HDFS存取数据,本次采取和Hadoop一起安装的方式使用。
Spark的部署模式主要有4种:Local(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为管理器)。本实验介绍Local模式(单机模式)+Hadoop伪分布式的Spark安装。
实验内容与步骤:
一、Spark的安装与配置
1.Spark的下载
在Ubuntu下打开官网:http://spark.apache.org/downloads.html进行下载。
或者https://archive.apache.org/dist/spark/下载。
下载完成后,会自动下载到Downloads目录下:

注:如果windows系统下载该安装文件的话,需要通过FTP软件将安装文件上传到Linux系统的Downloads目录下。
1.Spark安装
1)打开终端,解压安装包spark-2.3.2-bin-hadoop2.7.tgz至路径 /opt,命令如下:
sudo tar -zxvf Downloads/spark-2.3.2-bin-hadoop2.7.tgz -C /opt
2)查看是否解压成功
ls /opt

3)将解压的文件夹重命名为spark并添加spark的权限
sudo mv spark-2.3.2-bin-hadoop2.7/ spark #更名为spark
sudo chown -R hadoop:hadoop spark #把spark文件夹的权限赋给hadoop用户和hadoop组。

4)修改配置文件
将/opt/spark/conf目录下的配置文件spark-env-template.sh复制一份,重命名为spark-env.sh,命令如下:
cd /opt/spark/conf
cp spark-env-template.sh >> spark-env.sh

5)添加配置信息。
(1)使用vim编辑器编辑spark-env.sh文件,在第一行添加如下配置信息:
vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/bigdata/hadoop-3.1.1/bin/hadoop classpath)

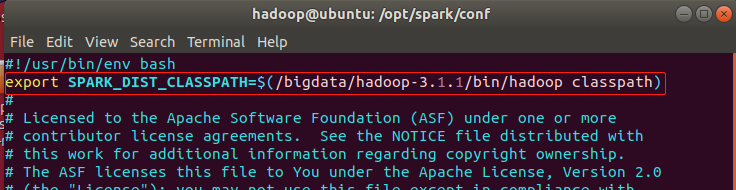
上述配置信息的目的是使得Spark可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果不进行配置,Spark只能读写本地数据。
(2)再添加一行配置信息:
SPARK_WORKER_MEMORY=4g #指定Spark的运行内存

(3)配置PATH路径。使用vim编辑器编辑/etc/profile文件,添加如下配置信息:
sudo vim /etc/profile
export SPARK_HOME=/opt/spark
export $SPARK_HOME/bin

重新载入/etc/profile配置文件
source /etc/proflie
6)验证Spark是否安装成功
Spark配置完成就可以直接使用,不需要像Hadoop那样运行启动命令。通过运行Spark自带的实例,就可以验证Spark是否安装成功,命令如下:
cd /opt/spark/bin/
run-example SparkPi

执行后会输出大量信息,可以通过grep命令进行查找我们想要的执行结果。命令如下:
run-example SparkPi 2>&1 | grep "Pi is roughly"

如果出现上述运行结果,表明安装成功。
二、Spark Shell基础编程实践
Spark Shell通过API提供了交互式的方式来分析数据,通过输入一条语句并立即执行返回结果的交互方式可以很大程度上提高开发效率。
Spark Shell支持Scala和Python,本实验分别使用Scala和Python来进行介绍。Scala是一门现代多范式编程语言,它可以简练、优雅以及类型安全的方式来表达常用的编程模式,集成了面向对象和函数语言的特性,运行在JVM上,并兼容现有的Java程序。
Scala方式:
1.启动Spark Shell
执行如下命令启动Spark Shell:
cd /opt/spark/bin
spark-shell
命令执行成功后,就会进入scala>命令提示符状态,如下图所示。

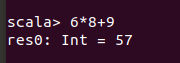
现在就可以在Scala命令提示符后面输入一个表达式6*8+9,然后按回车键,就可以立即得到结果了。如下图所示。
如果退出,可以使用命令“:quit”退出Spark Shell,或者直接按ctrl+D键,如下图所示。

Python方式:
(1)通过Spark自带的pyspark程序直接运行。pyspark是Spark官方提供的API接口,同时pyspark也是Spark中的一个程序。Spark是用Scala语言开发的,与Java非常相似,它将程序代码编译为用于Spark大数据处理的JVM的字节码。为了支持Spark和Python,Apache Spark社区发布了PySpark。
要运行pyspark,必须安装python,由于Linux16.04默认集成了Python2.7,也可以直接在终端命令行运行pyspark,如下图所示。

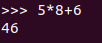
现在就可以在Python命令提示符后面输入一个表达式5*8+6,然后按回车键,就可以立即得到结果了。如下图所示。
如果退出,可以使用命令“exit()”退出Spark Shell,或者直接按ctrl+D键,如下图所示。

(2)如果想使用高版本的Python3或者ipython3,请到/opt/spark/bin目录下在pyspark文件中加入如下配置信息即可:
sudo vim pyspark

export PYSPARK_PYTHON=python3
或者
export PYSPARK_DRIVER_PYTHON=ipython3

终端运行pyspark,结果如下图所示。

三、读取文件(python方式;scala方式在前面文章已完成)
1.读取本地文件
打开一个终端,在终端中输入如下命令启动pyspark
cd /opt/spark/bin
pyspark

注:如果在profile中设置了全局变量,linux中任何路径都可以输入pyspark,否则要切换到bin目录下。
启动成功后,进入pyspark窗口,也即>>>命令提示符状态。
我们读取Linux本地文件系统中的文件/opt/spark/NOTICE,并显示第一行内容,命令如下:
textFile=sc.textFile("file:///opt/spark/NOTICE")
textFile.first()
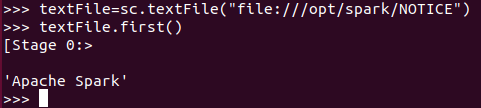
执行上面语句后,就能够看到已经读取到本地Linux文件系统中的NOTICE中的第一行内容了,即Apache Spark
2.读取HDFS文件
前面的实验已经安装了Hadoop和Spark,如果Spark不使用HDFS存储数据,那么不启动Hadoop也可以正常使用Spark。如果需要用到HDFS,就需要首先启动Hadoop,因此,在Spark读取HDFS文件之前,需要首先启动Hadoop,新建一个终端,执行如下命令:
start-dfs.sh
启动成功以后,把本地文件/opt/spark/NOTICE上传到HDFS的/user/hadoop目录下,命令如下:
hdfs dfs -put /opt/spark/NOTICE
(我这里是上传过了,所以显示“File exists”)
查看是否上传成功:
hdfs dfs -ls /user/hadoop
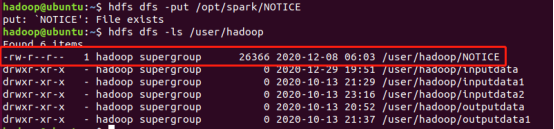
(我这里是上传过了,所以显示“File exists”)
使用-cat命令输出HDFS中的NOTICE中的内容,执行如下命令:
hdfs dfs -cat /user/hadoop/NOTICE
该命名执行后,会显示整个NOTICE文件的内容。
现在切换到已经打开的Spark Shell窗口,编写语句从HDFS中加载NOTICE文件,并显示第一行文本内容,命令如下:
textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/NOTICE")
textFile.first()
和上面命令等效的命令如下:
textFile=sc.textFile("/user/hadoop/NOTICE")
textFile.first()
还可以等效如下命令:
textFile=sc.textFile("NOTICE")
textFile.first()

如上图所示,执行上面的语句后,可以看到已经读取到HDFS文件系统中的NOTICE文件的第一行内容了,即Apache Spark。
四.使用Python编写词频统计程序
1.首先在/opt/spark目录下新建一个文本文件word.txt,文本文件内容是一段英文短文,内容如下:
hello spark
hello kafka
hello hadoop spark
hello spark python

2.启动pyspark,进入Spark Shell命令行。
3.假设要从这个文本文件中读取数据,进行词频统计,那么就要先读取文本文件,命令如下:
textFile= sc.textFile("file:///opt/spark/word.txt")
4.textFile是一个方法,可以用来加载文本数据,如果要加载本地文件,就必须使用file:///加路径的形式从文本中读取数据后就要开始进行词频统计了,命令和结果如下:
wordCount= textFile.flatMap(lambda line: line.split(" ")).map(lambda word:(word,1)).reduceByKey(lambda a, b : a + b)
wordCount.collect()

解释说明:flatMap会逐行遍历文本内容,然后对每行内容进行flatMap函数括号内的操作,即lambda line:line.split(" “),该操作会把每一行内容赋值给line,然后对每一个line进行split(” “)操作,即对每一行用空格分隔成单独的单词,这样每一行都是一个由单词组成的集合,因为有很多行,所以就有很多个这样的单词集合,执行完textFile.flatMap(lambda line: line.split(” "))后会把这些单词集合组成一个大的单词集合
map(lambdaword: (word,1))中的map会对这个所有单词的集合进行遍历,对于每一个单词进行map函数内的操作,即lambda word: (word,1),该操作会把每个单词赋值给word,然后组成一个键值对,这个键值对的key是这个单词,而value是1,这样就把每一个单词变成了这个单词的键值对形式(此时word是会有重复的,键值对也是相应重复的,只是把单词变成了键值对),执行完map之后已经获得了一个RDD,RDD中的每一个元素是很多个键值对reduceByKey(lambdaa, b : a + b)会对RDD中的每个元素根据key进行分组,然后对该分组进行括号内的操作,即lambda a, b : a + b,通过对具有相同key的元素进行该操作进行reduce操作,reduce操作会把具有相同key的元素的value进行相加,然后每一个相同key的键值对,最后变成一个键值对,key是一样的key,而value是具有相同key的键值对的个数,这样,词频统计的过程就完成了输出每一个统计后的键值对即可















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









