







Audit
JAGIELSKI M, ULLMAN J, OPREA A. Auditing differentially private machine learning: How private is private SGD?[C]//Advances in Neural Information Processing Systems. .
正式版论文链接
预收论文链接(更加详细)
视频链接

Differential privacy gives a strong worst-case guarantee of individual privacy:
a differentially private algorithm ensures that, for any set of training examples, no attacker, no matter how powerful attack, can not learn much more information about a single training example than they could have learned had that example been excluded from the training data.
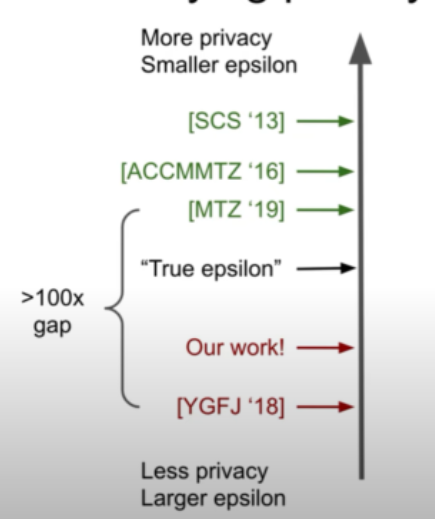
So, how closely can we measure privacy loss ?
here upper bounds means more privacy and smaller epsilon
lower bounds means less privacy and larger epsilon
A privacy proof will only give an upper bound for privacy level (smaller epsilon, more privacy). Improvements into the proof will get closer and closer to the true value of the privacy loss. Indeed, the analysis of the algorithm is always pessimistic, and recently theoretical analysis is not tight.
Besides, differential privacy is a worst-case notion. That is it usually provide more privacy guarantee on the realistic datasets and realistic attacks. So, privacy attacks can only get closer and close to the worst-case. That’s also what we do in the after work——construct an efficient attack.
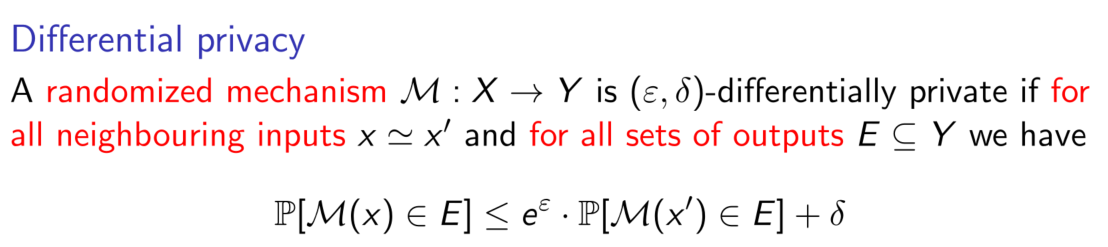
DP-SGD

In this paper, mainly discuss the audit in DP-SGD
DP-SGD is a modifaction of SGD, DP-SGD makes two modifications to the learning process to preserve privacy: clipping gradients and adding noise.
Every iteration it take a random sample L, and for each i ∈Lt ,we compute gradient and clip it. then sum all gradient and add noise
Poisoning Attacks
目的:构造数据集 D0, D1
BackGround Attacks


Implement
-
Xp = GETRANDOMROWS(X, k)
随机选择k个x进行投毒
-
Pert(x):置x的前5*5的像素点为1
-
yp:置y为1
However
Clipping provides no formal privacy on its own,but many poisoning attacks perform significantly worse in the presence of clipping
The objective of attack is to decrease the loss on (xp, yp). That is, we need to increasing gradient at every times iteration. In traditional SGD: gt = 1/L Σigt(xi)
∇wl(w · xp+ b, yp) =l’(w · xp+ b, yp)·xp
By doubling this quantity of gradient , if |xp| is fixed, half as many poisoning points are required for the same effect.
However in the presence of clipping ,this relationship broken
Clipping-Aware Poisoning
the attack must produce not only large gradients,but also distinguished gradients. (That is, the distribution of gradients arising from poisoned and cleaned data must be significantly different.)
minimizing Var(x,y)∈D[l’(w · xp+ b, yp)xp· l’(w · x+ b, y)x]
V a r ( x , y ) ∈ D [ ℓ ′ ( w ⋅ x p + b , y p ) x p ⋅ ℓ ′ ( w ⋅ x + b , y ) x ] Var_{(x,y)\in D}[\ell^{'}(w·x_p+b,y_p)x_p · \ell^{'}(w·x+b,y)x] Var(x,y)∈D[ℓ′(w⋅xp+b,yp)xp⋅ℓ′(w⋅x+b,y)x]

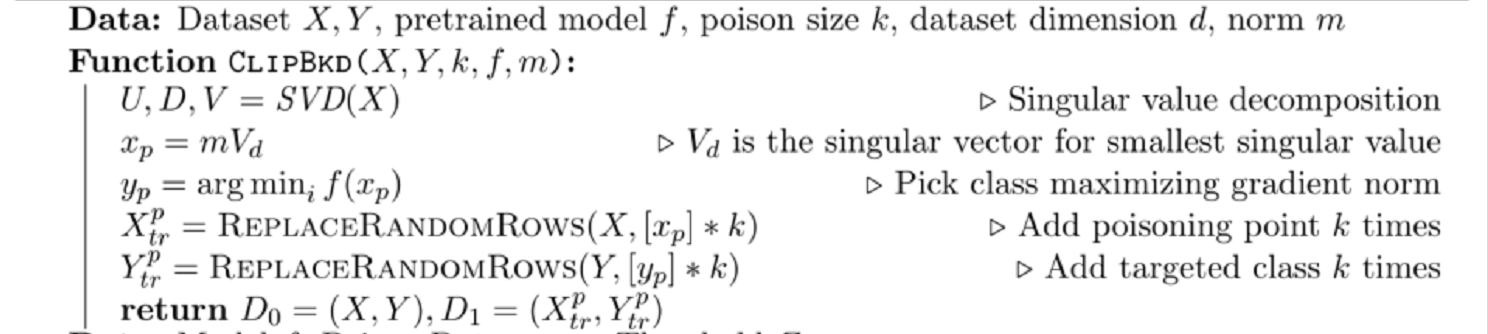

Audit

- in the case of δ = 0 \delta = 0 δ=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









