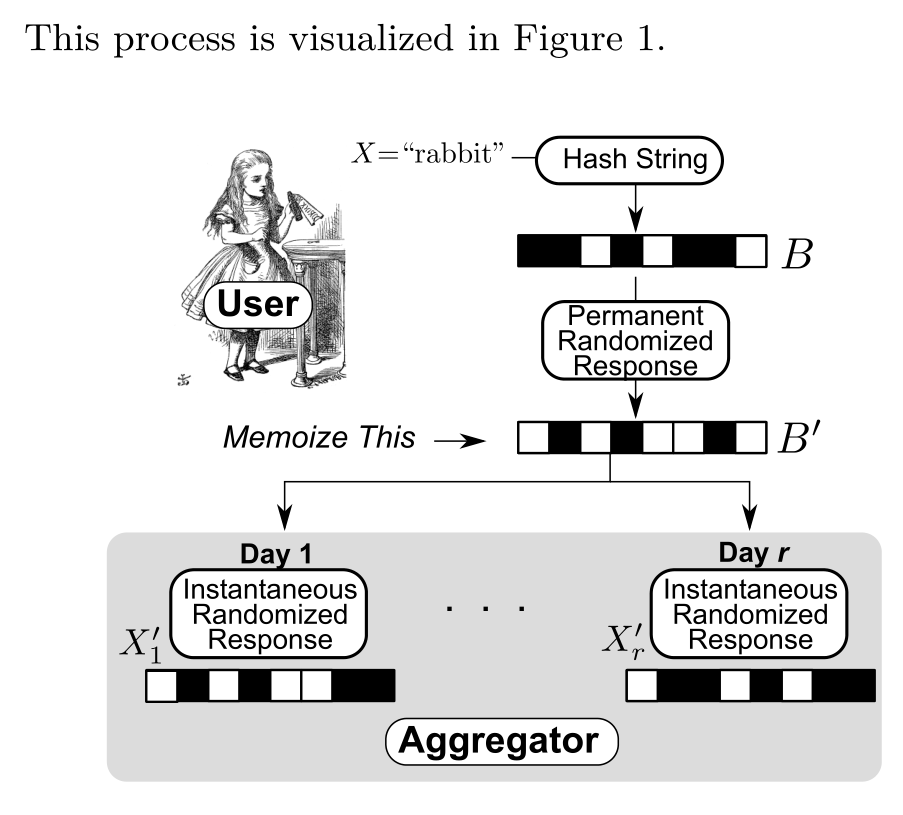
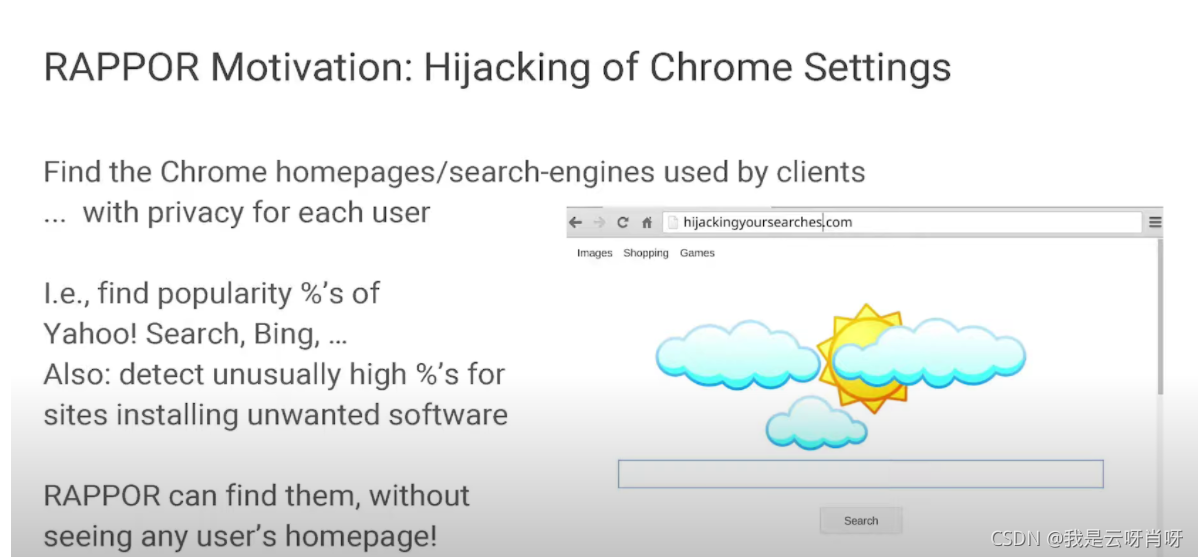
RAPPOR: Utilizing Large-Scale RAndomized Response at Google 参考视频 源码 1. 背景 希望收集用户使用的默认主页和搜索引擎,但同时不涉及用户的个人隐私 Metaphor for RAPPOR Mona lisa 举例 一副图像由多个独立的信息组成,就如同我们的统计信息来自于多个独立的统计个体 如果不加以噪声,可能会导致隐私问题








 RAPPOR是一种在不侵犯用户隐私的情况下收集数据的方法,它使用随机响应和两层随机化来实现差分隐私。在谷歌中,RAPPOR被用来收集如默认主页和搜索引擎等信息,同时通过添加噪声来保护用户隐私。RAPPOR算法包括使用Bloom Filter处理数据碰撞,以及应对成长中的挑战。
RAPPOR是一种在不侵犯用户隐私的情况下收集数据的方法,它使用随机响应和两层随机化来实现差分隐私。在谷歌中,RAPPOR被用来收集如默认主页和搜索引擎等信息,同时通过添加噪声来保护用户隐私。RAPPOR算法包括使用Bloom Filter处理数据碰撞,以及应对成长中的挑战。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4461
4461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






