







 本文介绍了如何在Python环境中快速安装wordcloud库,特别是针对通过cmd和PyCharm常规方法安装不成功的情况。提供了检查Python版本、下载对应版本文件及手动安装的详细步骤,确保安装成功。
本文介绍了如何在Python环境中快速安装wordcloud库,特别是针对通过cmd和PyCharm常规方法安装不成功的情况。提供了检查Python版本、下载对应版本文件及手动安装的详细步骤,确保安装成功。
大家好我是冈坂日川,今天和大家分享一下怎么快速安装wordcloud库,我也是为了它吃了不少苦呀,因此写成笔记,希望不要有人和我一样踩坑,希望今天的分享能给你带来帮助。
安装wordcloud的几种方法
- 在cmd 中 pip intsall xxxx(这里指文件名)
- 在Pycharm 中 setting 项目中搜索后install
- 自己动手下载文件安装
今天我们采用的就是第三种方法,事实上前两种方法都比较简单,但是对wordcloud我就是行不通呀,所以给各位情况和我一样的提供第三种方法的介绍,ok我们进入正题!
一. 检查python的版本
进入cmd界面,输入python,如下图
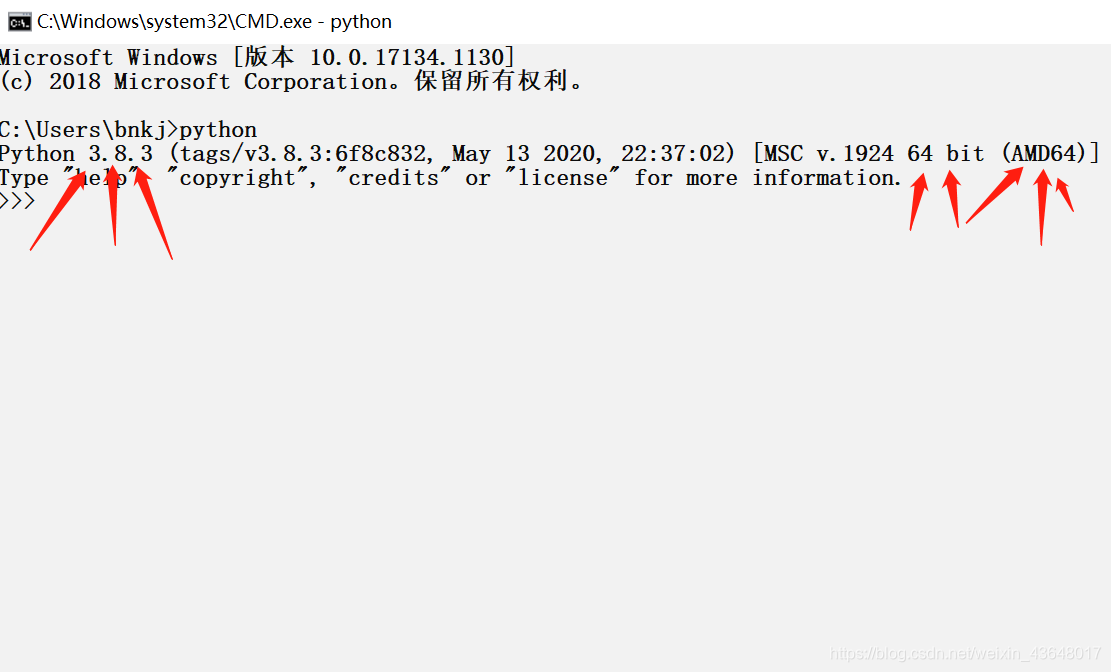
找到python版本,我的是38,以及后面的参数,我是64bit
二. 下载对应版本的文件
某盘链接
链接:https://pan.baidu.com/s/176xk83qs0TcyjADp3_15eQ
提取码:deua
文件下载后有一下内容&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3138
3138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









