







文章目录
MySQL索引
关于[MySQL]索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。``对于没有索引的表,单表查询可能几十万数据就是瓶颈`,而通常大型网站单日就可能会产生几十万甚至几百万的数据,没有索引查询会变的非常缓慢。还是以WordPress来说,其多个数据表都会对经常被查询的字段添加索引,比如wp_comments表中针对5个字段设计了BTREE(二叉树)索引。
合理的设计自己的数据库表和索引可以大大提高数据的检索速度,如果在大表中滥用索引反而会影响你的数据库性能,下边数据库优化有详细提到。
Alter table employees add index first_name (first_name);
2.1 索引类型
2.1.1 B树
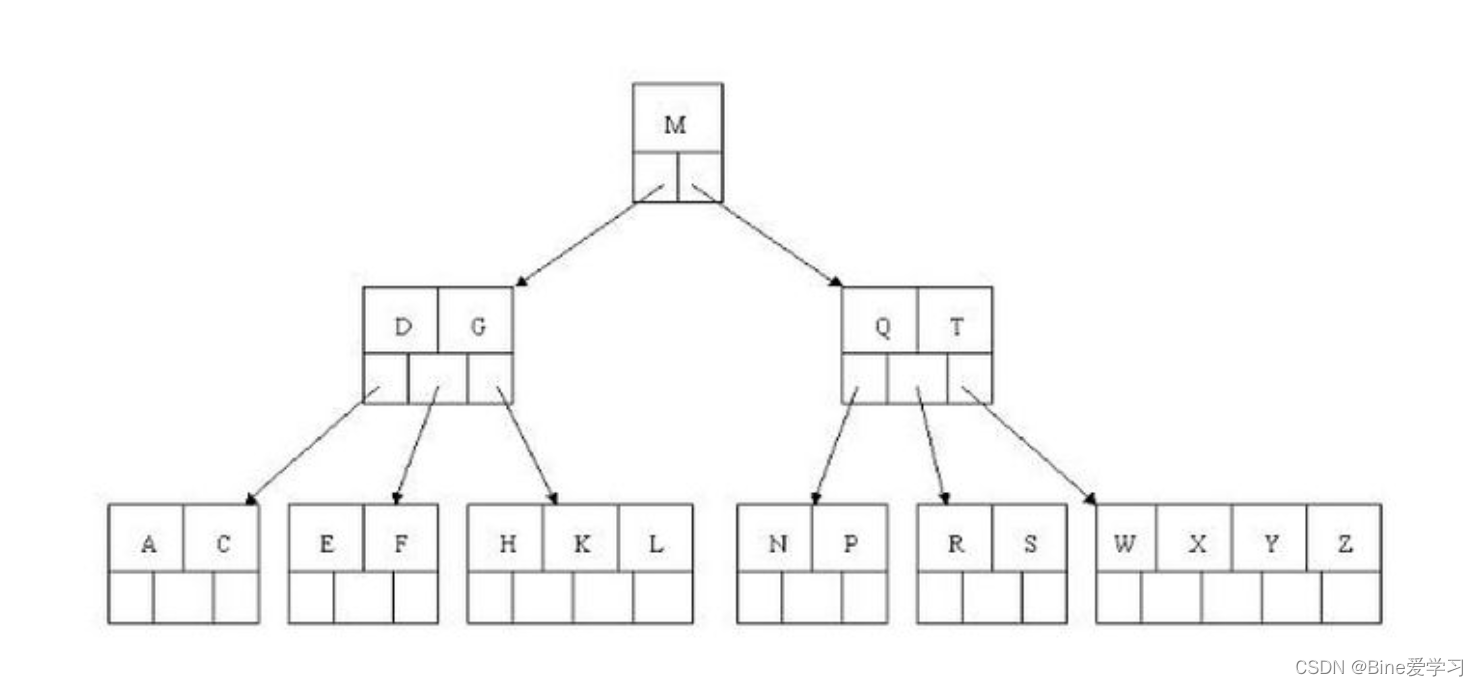
大多数存储引擎都支持B树索引。B树通常意味着所有的值都是按顺序存储的,并且每一个叶子也到根的距离相同。B树索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取数据。下图就是一颗简单的B🌲。
2.1.2 B+树
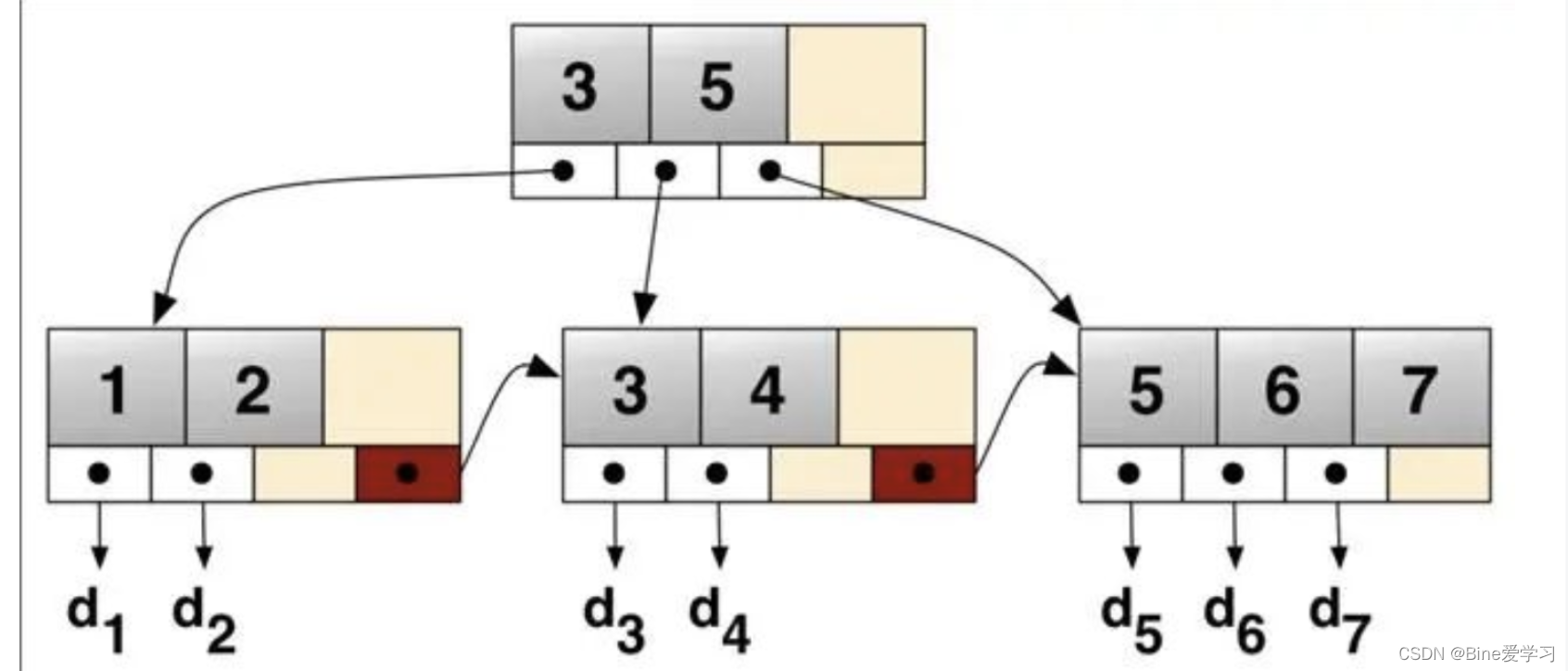
下图为B+树的结构,B+树是B树的升级版,我们可以观察一下,B树和B+树的区别是什么?
2.1.3 B+树和B树的区别是:
-
B树的节点中没有重复元素,B+树有(因为B树的节点是储存信息的)。
-
B树的中间节点会存储数据指针信息,而B+树只有叶子节点才存储。
-
B+树的每个叶子节点有一个指针指向下一个节点,把所有的叶子节点串在了一起。
-
B+树最大的区别就是所有的数据都是存储在叶子节点上的,而非叶子节点中存储的都是数据索引。并且所有的叶子结点再连接成一个链表!
从下图我们可以直观的看到B树和B+树的区别:紫红色的箭头是指向被索引的数据的指针,大红色的箭头即指向下一个叶子节点的指针。
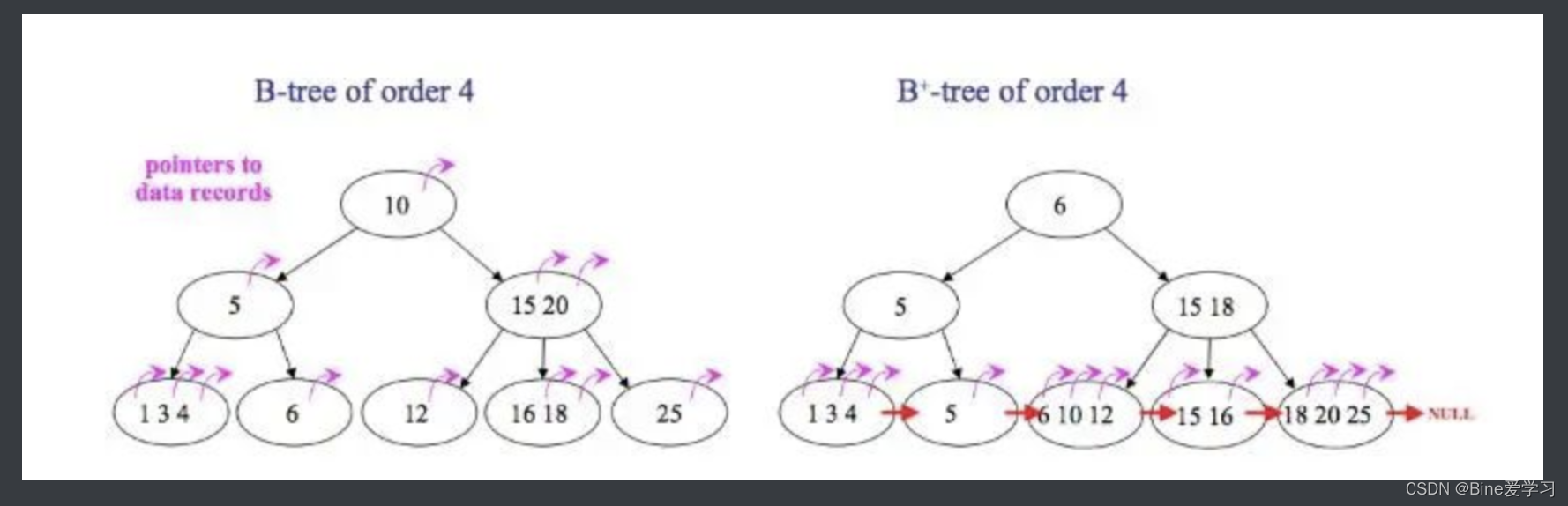
我们假设被索引的列是主键,现在查找主键为5的记录,模拟一下查找的过程:
B树,在倒数第二层的节点中找到5后,可以立刻拿到指针获取行数据,查找停止。B+树,在倒数第二层的节点中找到5后,由于中间节点不存有指针信息,则继续往下查找,在叶子节点中找到5,拿到指针获取行数据,查找停止。
B+树每个父节点的元素都会出现在子节点中,是子节点的最大(或最小)元素。叶子节点存储了被索引列的所有的数据。
2.1.4 B+树比起B树有什么优点呢?
- 由于中间节点不存指针,同样大小的磁盘页可以容纳更多的节点元素,树的高度就小。(数据量相同的情况下,B+树比B树更加“矮胖”),查找起来就更快。
- B+树每次查找都必须到叶子节点才能获取数据,而B树不一定,B树可以在非叶子节点上获取数据。因此B+树查找的时间更稳定。
- B+树的每一个叶子节点都有指向下一个叶子节点的指针,方便范围查询和全表查询:只需要
从第一个叶子节点开始顺着指针一直扫描下去即可,而B树则要对树做中序遍历。
了解了B+树的结构之后,我们对一张具体的表做分析:
create table Student(
last_name varchar(50) not null,
first_name varchar(50) not null,
birthday date not null,
gender int(2) not null,
key(last_name, first_name, birthday)
);
对于表中的每一行数据,索引中包含了name,birthday列的值。下图显示了该索引的结构:
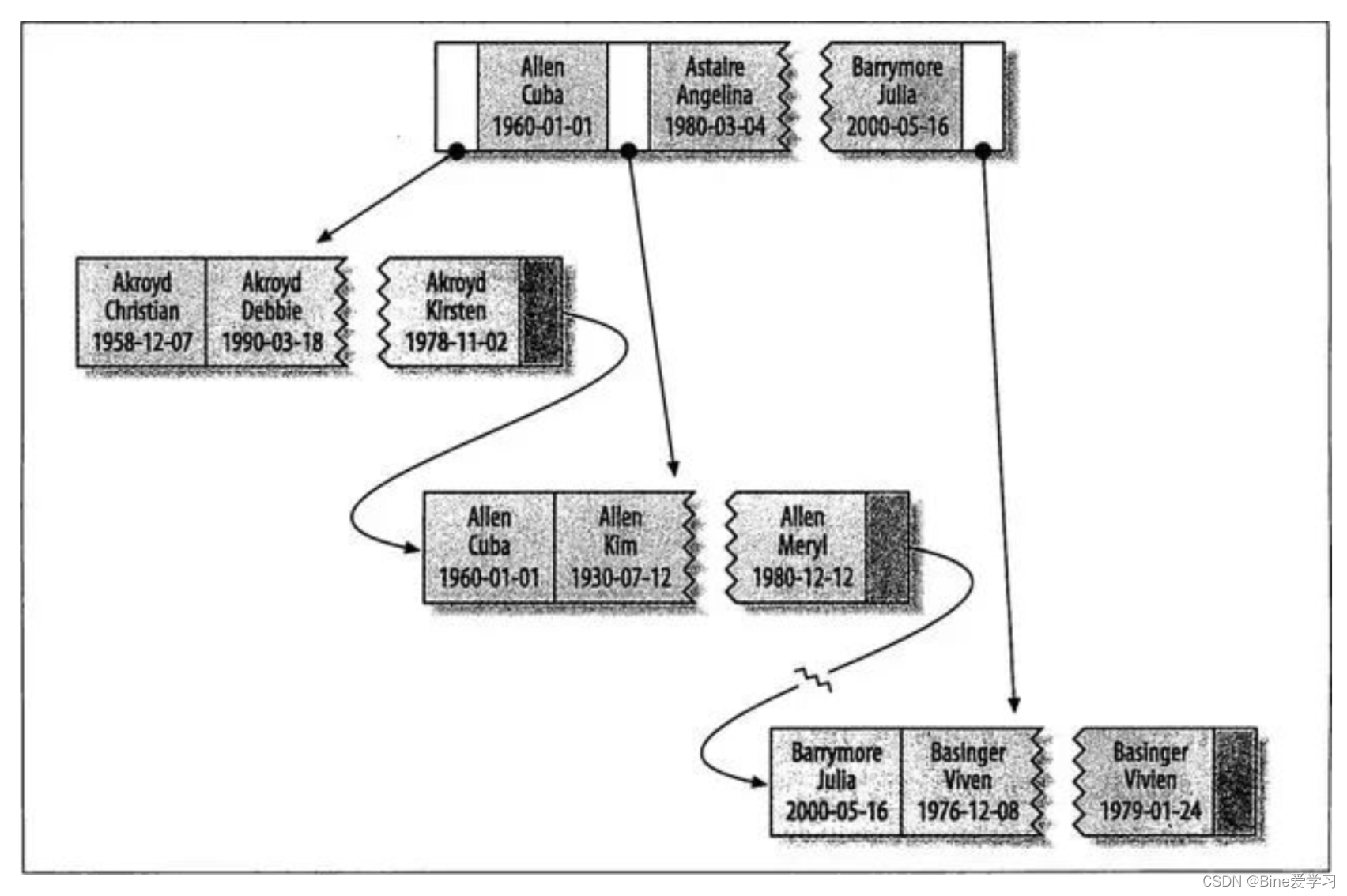
索引对多个值进行排序的依据是create table语句中定义索引时列的顺序,即如果名字相同,则根据生日来排序。
B+树的结构决定了这种索引对以下类型的查询有效:
- 全值匹配 和索引中所有的列进行匹配,例如查找姓名为Cuba Allen,生日为1960-01-01的人。
- 匹配最左前缀 查找姓为Allen的人,即只用索引的第一列。
- 匹配列前缀 匹配某一列的值的开头部分,例如查找所有以J开头的姓的人。
- 匹配范围值 查找姓在Allen和Barrymore之间的人。
- 精确匹配某一列并范围匹配另外一列 查找姓为Allen,名字是字母K开头的人。即第一列last_name全匹配,第二列first_name范围匹配。
- 只访问索引的查询 查询只需要访问索引,无需访问数据行。这种索引叫做覆盖索引。
一些限制:
-
如果不是按照索引的最左列开始查找,无法使用索引。例如上面例子中的索引无法用于查找某个特定生日的人,因为生日不是最左数据列。也不能查找last_name以某个字母结尾的人。
-
不能跳过索引的列。上述索引无法用于查找last_name为Smith并且某个特定生日的人。如果不指定first_name,则mysql只能使用索引的第一列。
-
如果查询中有某个列的范围查询,则右边所有的列都无法使用索引优化查找。例如查询WHERE last_name=’Smith’ AND first_name LIKE ‘J%’ AND birthday=‘1996-05-19’,这个查询只能使用索引的前两列。
2.2 MySQL中InnoDB的一级索引、二级索引
每个InnoDB表具有一个特殊的索引称为聚簇索引(也叫聚集索引,聚类索引,簇集索引)。如果表上定义有主键,该主键索引就是聚簇索引。如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。
表中的聚簇索引(clustered index )就是一级索引,除此之外,表上的其他非聚簇索引都是二级索引,又叫辅助索引(secondary indexes)。
原文链接:https://blog.csdn.net/RoxLiu/article/details/70160664
2.3 数据库Mysql-索引的最左前缀匹配原则
最左前缀匹配原则:
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时如果范围查询(>、<、between、like)就会停止匹配。
2.3.1 例子来理解最左前缀匹配原则
前一篇文中,我们已经了解到Mysql数据库的索引的底层存储是一棵B+树,那么联合索引的底层也还是一棵B+树。只不过联合索引的键值对数量不是一个,而是多个。
假如:构建一个(a,b)的联合索引,那么它在数据库底层的索引树是下列这样的:
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
2.3.2 最左前缀匹配原则适用场景
假如建立联合索引(a,b,c)
1 全值匹配查询时
select * from table_name where a = '1' and b = '2' and c = '3'
select * from table_name where b = '2' and a = '1' and c = '3'
select * from table_name where c = '3' and b = '2' and a = '1'
用到了索引
where子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序
2 匹配左边的列时
select * from table_name where a = '1'
select * from table_name where a = '1' and b = '2'
select * from table_name where a = '1' and b = '2' and c = '3'
都从最左边开始连续匹配,用到了索引
select * from table_name where b = '2'
select * from table_name where c = '3'
select * from table_name where b = '1' and c = '3'
这些没有从最左边开始,最后查询没有用到索引,用的是全表扫描
select * from table_name where a = '1' and c = '3'
如果不连续时,只用到了a列的索引,b列和c列都没有用到
3 匹配列前缀
如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相通,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As'//全表查询
select * from table_name where a like '%As%'//全表查询
4 匹配范围值
select * from table_name where a > 1 and a < 3
可以对最左边的列进行范围查询
select * from table_name where a > 1 and a < 3 and b > 1;
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引,在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤
- 精准匹配某一列并范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找
select * from table_name where a = 1 and b > 3;
a=1的情况下b是有序的,进行范围查找走的是联合索引
6 排序
一般情况下,我们只能把记录加载到内存中,再用一些排序算法,比如快速排序,归并排序等在内存中对这些记录进行排序,有时候查询的结果集太大不能在内存中进行排序的话,还可能暂时借助磁盘空间存放中间结果,排序操作完成后再把排好序的结果返回客户端。Mysql中把这种再内存中或磁盘上进行排序的方式统称为文件排序。文件排序非常慢,但如果order子句用到了索引列,就有可能省去文件排序的步骤
select * from table_name order by a,b,c limit 10;
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了
order by的子句后面的顺序也必须按照索引列的顺序给出,比如
select * from table_name order by b,c,a limit 10;
这种颠倒顺序的没有用到索引
select * from table_name order by a limit 10;
select * from table_name order by a,b limit 10;
这种用到部分索引
select * from table_name where a =1 order by b,c limit 10;
联合索引左边列为常量,后边的列排序可以用到索引
————————————————
原文链接:https://blog.csdn.net/Mind_programmonkey/article/details/114693532
2.4 哈希索引
哈希索引,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。如果多个列的哈希值相同,索引会以链表的方式存放多个指针记录到同一个哈希条目中。
hash索引的特点
1、hash索引是基于hash表实现的,只有查询条件精确匹配hash索引中的所有列的时候,才能用到hash索引。
2、对于hash索引中的所有列,存储引擎都会为每一行计算一个hash码,hash索引中存储的就是hash码。
3、hash索引包括键值、hash码和指针 。
因为hash索引本身只需要存储对应的hash值,所以索引的结构十分紧凑,这也让hash索引查找的速度非常快。然而,hash索引也是存在其限制的:
hash索引的限制
1、Hash索引必须进行二次查找
使用哈市索引两次查找,第一次找到相应的行,第二次读取数据,但是被频繁访问到的行一般会缓存在内存中,这点对数据库性能的影响不大。
原文链接:https://blog.csdn.net/z_ryan/article/details/82322418
因为索引自身只存储对应的哈希值,所以索引的结构十分紧凑,哈希索引查找的速度非常快。但是哈希索引也有它的限制:
- 哈希索引
不是按照索引顺序存储的,无法用于排序。 不支持部分索引列匹配查找。不支持范围查找。
SQL,考察联合语句,如何分页以及复杂语句的优化
8.1、分页
一:分页需求:
客户端通过传递start(页码),limit(每页显示的条数)两个参数去分页查询数据库表中的数据,那我们知道MySql数据库提供了分页的函数limit m,n,但是该函数的用法和我们的需求不一样,所以就需要我们根据实际情况去改写适合我们自己的分页语句,具体的分析如下:
比如:
查询第1条到第10条的数据的sql是:select * from table limit 0,10; ->对应我们的需求就是查询第一页的数据:select * from table limit (1-1)*10,10;
查询第10条到第20条的数据的sql是:select * from table limit 10,20; ->对应我们的需求就是查询第二页的数据:select * from table limit (2-1)*10,10;
查询第20条到第30条的数据的sql是:select * from table limit 20,30; ->对应我们的需求就是查询第三页的数据:select * from table limit (3-1)*10,10;
*二:通过上面的分析,可以得出符合我们自己需求的分页sql格式是:select * from table limit (start-1)limit,limit; 其中start是页码,limit是每页显示的条数。
8.2、复杂语句的优化
-
1.
使用EXPLAIN关键词检查SQL。EXPLAIN可以帮你分析你的查询语句或是表结构的性能瓶颈,就得EXPLAIN 的查询结果还会告诉你,你的索引主键被如何利用的,你的数据表是如何被搜索和排序的,是否有全表扫描等; -
2.
查询的条件尽量使用索引字段,如某一个表有多个条件,就尽量使用复合索引查询,复合索引使用要注意字段的先后顺序。 -
3.
多表关联尽量用join,减少子查询的使用。表的关联字段如果能用主键就用主键,也就是尽可能的使用索引字段。如果关联字段不是索引字段可以根据情况考虑添加索引。在MySQL中,尽量使用JOIN来代替子查询.
因为子查询需要嵌套查询,嵌套查询时会建立一张临时表,临时表的建立和删除都会有较大的系统开销,而连接查询不会创建临时表,因此效率比嵌套子查询高. -
4.
尽量使用limit进行分页批量查询,不要一次全部获取。 -
5.
绝对避免seect *的使用,尽量select具体需要的字段,减少不必要字段的查询; -
6.避免遇到索引失效的情况
- 原则:
- LIKE关键字匹配%开头的字符串,不会使用索引.
- OR关键字的两个字段必须都是用了索引,该查询才会使用索引.
- 使用多列索引必须满足最左匹配.
-
7.
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤,这个处理需要排序,总计等操作。如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销
————————————————
原文链接:https://blog.csdn.net/qq_45283095/article/details/121995569
联合索引
遇到多条件查询时,不可避免会使用到多列索引。联合索引又叫复合索引。
b+tree结构如下:
每一个磁盘块在mysql中是一个页,页大小是固定的,mysql innodb的默认的页大小是16k,每个索引会分配在页上的数量是由字段的大小决定。当字段值的长度越长,每一页上的数量就会越少,因此在一定数据量的情况下,索引的深度会越深,影响索引的查找效率。
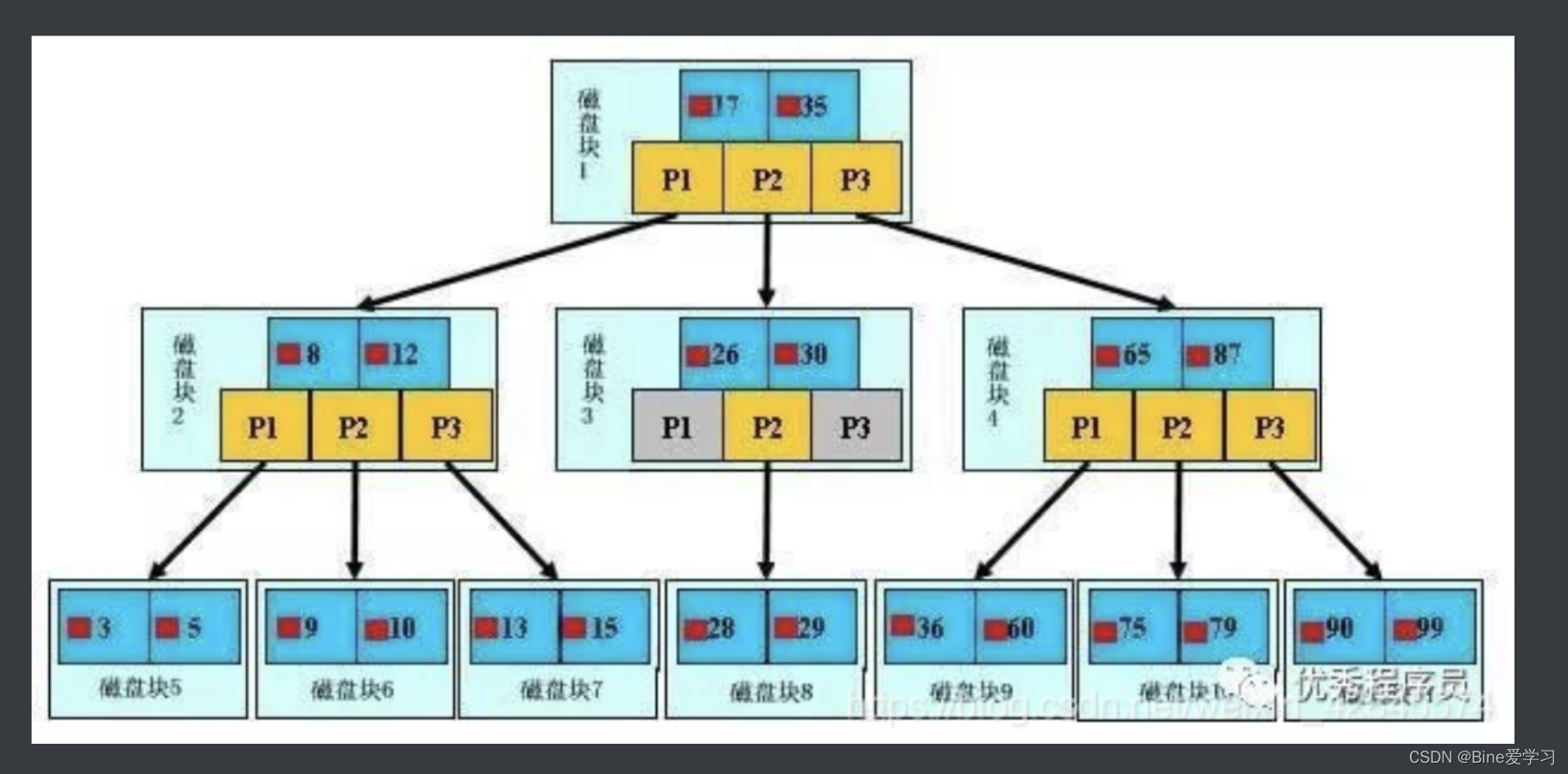
对于(多列b+tree,使用多列值组合而成的b+tree索引)。遵循最左侧原则,从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a a,b a,b,c 3种组合进行查找,但不支持 b,c进行查找。当使用最左侧字段时,索引就十分有效。
创建表test如下:
create table test(
a int,
b int,
c int,
KEY a(a,b,c));
比如(a,b,c)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(a=? and b=? and c=?)这样的数据来检索的时候,b+树会优先比较a列来确定下一步的所搜方向,如果a列相同再依次比较b列和c列,最后得到检索的数据;但当(b=? and c=?)这样的没有a列的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候a列就是第一个比较因子,必须要先根据a列来搜索才能知道下一步去哪里查询。比如当(a=? and c=?)这样的数据来检索时,b+树可以用a列来指定搜索方向,但下一个字段b列的缺失,所以只能把a列的数据找到,然后再匹配c列的数据了, 这个是非常重要的性质,即索引的最左匹配特性。以下通过例子分析索引的使用情况,以便于更好的理解联合索引的查询方式和使用范围。
一、多列索引在and查询中应用
select * from test where a=? and b=? and c=?;查询效率最高,索引全覆盖。
select * from test where a=? and b=?;索引覆盖a和b。
select * from test where b=? and a=?;经过mysql的查询分析器的优化,索引覆盖a和b。
select * from test where a=?;索引覆盖a。
select * from test where b=? and c=?;没有a列,不走索引,索引失效。
select * from test where c=?;没有a列,不走索引,索引失效。
1234567891011
二、多列索引在范围查询中应用
select * from test where a=? and b between ? and ? and c=?;索引覆盖a和b,因b列是范围查询,因此c列不能走索引。
select * from test where a between ? and ? and b=?;a列走索引,因a列是范围查询,因此b列是无法使用索引。
select * from test where a between ? and ? and b between ? and ? and c=?;a列走索引,因a列是范围查询,b列是范围查询也不能使用索引。
12345
三、多列索引在排序中应用
select * from test where a=? and b=? order by c;a、b、c三列全覆盖索引,查询效率最高。
select * from test where a=? and b between ? and ? order by c;a、b列使用索引查找,因b列是范围查询,因此c列不能使用索引,会出现file sort。
四,总结联合索引的使用在写where条件的顺序无关,mysql查询分析会进行优化而使用索引。但是减轻查询分析器的压力,最好和索引的从左到右的顺序一致。使用等值查询,多列同时查询,索引会一直传递并生效。因此等值查询效率最好。索引查找遵循最左侧原则。但是遇到范围查询列之后的列索引失效。排序也能使用索引,合理使用索引排序,避免出现file sort。














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









