







一、大数据带来的安全挑战
- 什么是隐私?
狭义:个人联系方式、朋友关系信息、私人信息( 年龄、月薪、职业等 ) 。
广义:散落在互联网各个角落的信息。eg. 搜索引擎的搜索记录、浏览器的访问痕迹、电商平台的购物记录、地图应用的搜索记录。 - 数据匿名化
数据匿名化是将数据库中的部分敏感信息隐匿,使数据主体( 个人信息的属主 ) 难以被识别。数据管理者试图通过匿名数据来保护数据主体的隐私。 - 去匿名化
攻击者通过将匿名记录与外部信息关联起来再识别匿名后的数据,并希望能够发现数据主体的真实身份。
二、隐私保护的概念与技术
-
隐私保护技术手段
1)元组抑制
2)属性泛化
比元组抑制更 准确的 不确定性形式。
3)属性置换
比泛化更 准确的 不确定性形式。
4)属性扰动
能唯一识别元组,但获得有噪声的敏感属性值。 -
K-匿名和不确定性
- 一个 K-匿名 的表 T’ 代表所有 “可能” 表 T 的集合,使得 T’ 是 T 的一个 K-匿名。
- 最初推导 T’ 的表 T 是所有 “可能” 表中的一个。
- 如果没有背景知识,所有的可能表都是同等概率的。
-
查询应答
查询应答:从 K-匿名 表中查询得到有用的信息,即查询应答。
K-匿名表:
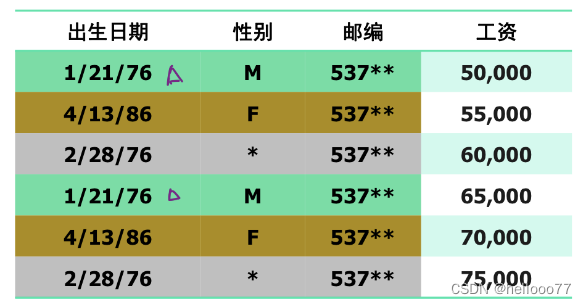
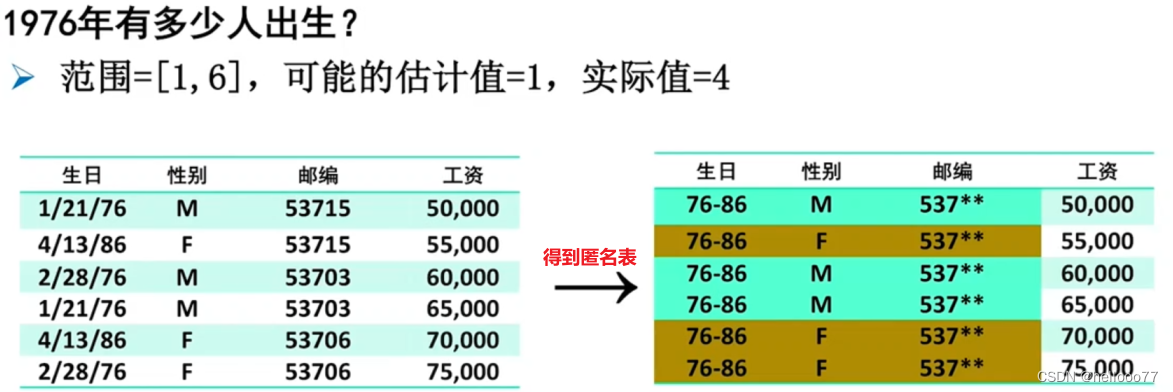
查询举例1:某人 (1/21/76,M,53715) 的工资是多少?
答:最好的猜测是57500。 ( 50000 和 65000 的加权平均 )
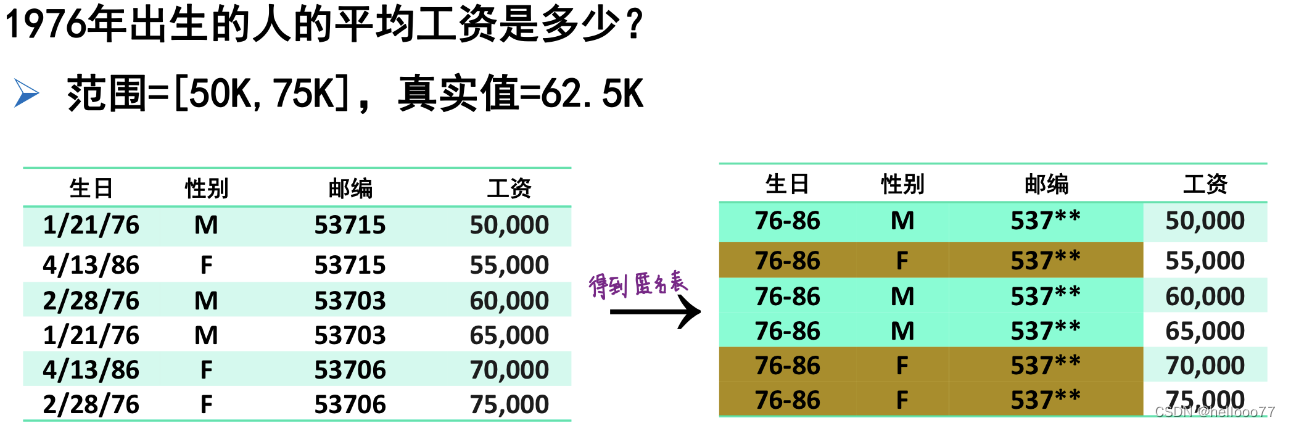
查询举例2:53706 这名女性的最高工资是多少?是同50000一样小还是同75000一样大。
答:可使 [ 50000,75000 ] 中的 max值 作为 53706 最高工资的估计。 -
计算 K-匿名表
- 基于泛化和基于元组抑制的算法
- 基于全局(例如,全域)和基于局部(例如,多维)记录的算法
- 基于层次和基于划分(例如,数值数据)的算法
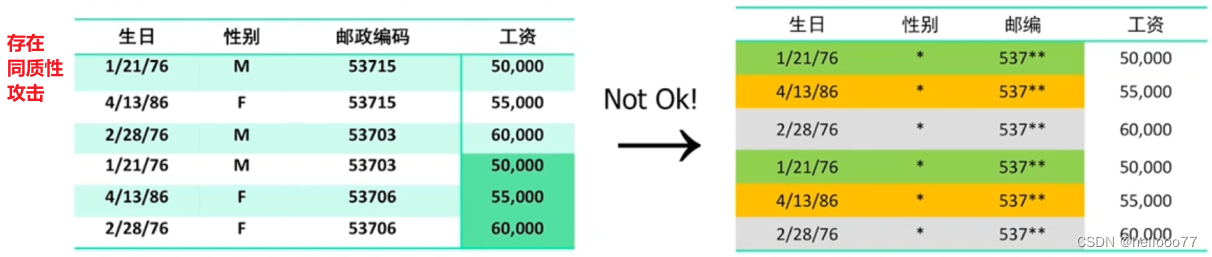
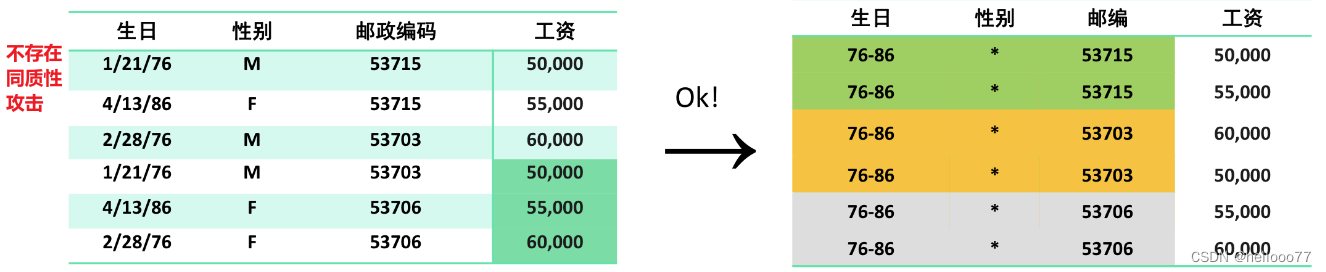
- 同质性攻击
问题出现的原因:在于分组的选择,而不在于数据。
eg. 同一数据因为分组方式的不同而带来的差异。
- l - 多样性
-
l - 多样性原理:如果每个等价组包含至少 l 个 “良好表示” 的敏感值,则该表是多样的。
-
l - 多样性的不同定义 ( 如何定义 “良好表示” ? )
- 熵 l - 多样性

熵值越大,数据越均匀,越随机;熵值越小,数据越确定。 - 递归 (c,l) - 多样性

效果:与等价组中较不频繁的敏感值相比,最常见的敏感值不会显得太频繁。
- 熵 l - 多样性
-
关键性质:熵 l - 多样性和递归 (c,l) - 多样性具有子集性质和泛化性质。
-
l - 多样性的算法思路:
- 采用任何 K-匿名算法,用 l - 多样性测试替换 K-匿名性测试,若某一 K-匿名计算结果满足 l - 多样性,则算法结束。
-
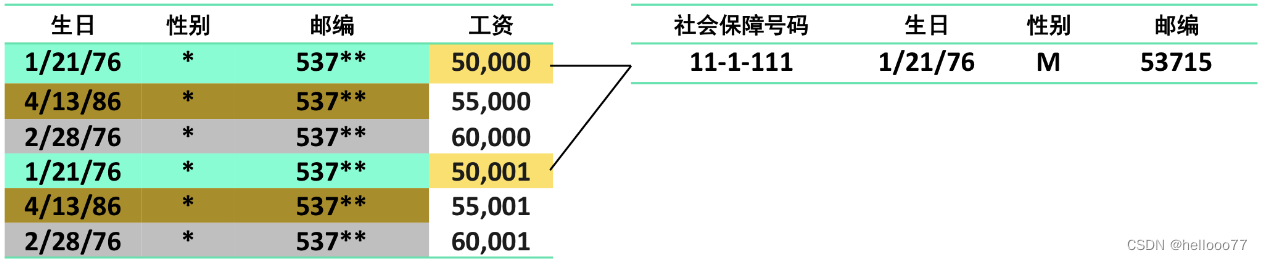
l - 多样性的局限性:只能保证敏感属性值的多样性,但这些值在语义上可能相似。
- 泛化表的查询处理
- 例一
- 例二















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











