







一、recastnavigation使用介绍
1)模式选择
Solo Mesh:单块生成
Tile Mesh:分块生成
Temp Obstacles:分块并支持动态阻挡
这里测试的话选单块生成
2)模型选择
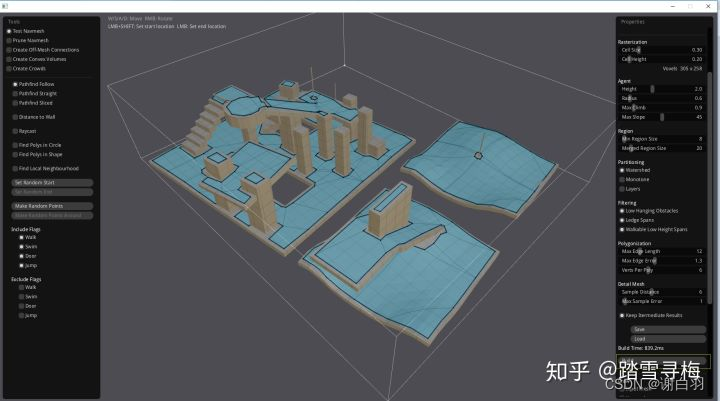
官方自带3块地图,这里测试选择 nav_test.obj,点击build,生成NavMesh
二、导航网格介绍
- 基础概念介绍
一个导航网格是由多个凸多边形(Convex Polygon, Poly Mesh)组成的。Poly Mesh 有些时候也会简称为 Poly,即上图中的一个个色块部分。 - 单位
在导航网格中的寻路是以 Poly 为单位的。 - 寻路简述
在同个 Poly 中的两点,在忽略地形高度的情况下, 是可以直线到达的;如果两个点位于不同的 Poly,那么就会利用导航网格 + 寻路算法(比如A*算法)算出需要经过的 Poly,再算出具体路径。
1)子集介绍
- 1.
Recast:负责根据提供的模型生成导航网格。 - 2.
Detour:利用导航网格做寻路操作。这里的导航网格可以是 Recast 生成的,也可以是其他工具生成的。 - 3.
DetourCrowd:提供了群体寻路行为的功能。 - 4.
Recast Demo:一个很完善的 Demo,基本上将 Recast 、 Detour 提供的功能都很好地展现了出来。弄懂了这个 Demo 的功能,基本也就了解了 RecastNavigation 究竟可以干什么事。
2)导航网格的生成分为以下几个步骤:(目前生成Navmesh数据主要有两种方式:多边形裁剪和体素化,这里讲体素化)
- 生成navmesh的两种方式
1)多边形裁剪
多边形裁剪是直接对地形的多边形网格数据进行裁剪及合并,从而生成导航网格。方法比较直观,但难度更高,目前havok引擎使用了此方法。
2)体素化
体素化是对地形多边形网格进行栅格化,然后用这些“格子”重新生成导航网格,方法更复杂,但难度更低,Recast使用了此方案,而UE4使用了Recast。
3)recast流程介绍
- 总体概述
将以三角形集合形式表示的空间场景转化为可供寻路使用的导航数据(navmesh)
recast导航网格的生成会分为下面几个步骤:
1、场景模型体素化(Voxelization),或者叫“栅格化”(Rasterization)。
2、过滤出可行走面(Walkable Suface)
3、生成 Region
4、生成 Contour(边缘)
5、生成 Poly Mesh
6、生成 Detailed Mesh
- 部分参数显示
cellSize------x、z方向上的体素精度
walkableSlopeAngle------agent的可行走最大坡度
walkableHeight------agent的可行走的最小高度空间
walkableClimb------agent的可攀爬高度
walkableRadius------agent的行走半径
float* bmin和float* bmax------场景的AABB包围盒
int* tris数组------场景的三角形序列
ntris------场景的三角形个数
float* verts------场景三角形各个顶点的坐标
nverts------场景三角形的顶点总数
- 用图举例
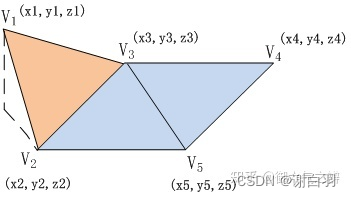
- 上图参数介绍
(如上图这个场景,包含3个三角形和5个顶点)
1)5个顶点的坐标用float* verts[3 * nverts]数组存储,分别表示nverts个顶点的x、y、z坐标,
nverts的值为5;
2)3个三角形用int* tris[3 * ntris]数组存储,分别表示ntris个三角形的3*ntris个顶点在verts数组中
的下标,ntris的值为3。
3)在这个例子中,verts[3 * nverts]数组的内容是
[x1,y1,z1,x2,y2,z2,x3,y3,z3,x4,y4,z4,x5,y5,z5],而tris[3 * ntris]数组的内容是
[0,1,2,1,2,4,2,3,4]。
(1)体素化
-
简单介绍
就是将整个场景模型,都转化为体素(Voxel)。 -
过程介绍
这一步处理和 GPU 渲染管线的光栅化流程概念是一样的,都是将矢量的模型信息(三角形),转化为点阵信息(像素或者体素)。开个脑洞, 假设将来有个全息显示器,可以在一个空间内渲染出制定的模型内容,渲染的最基本单位是体素而不是像素。那么到时的“显卡”很可能就是采取类似的模型体素化过程。

在讲体素化之前,我们先来看下如何将一个凸多边形分隔成两个凸多边形。如下图的五边形,我们分析下 V6-V7 这条切割线分隔凸多边形的流程。
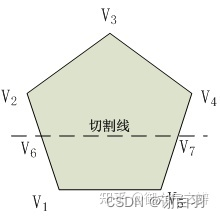
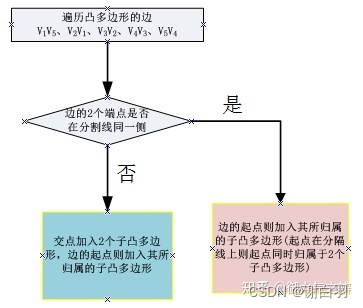
当遍历完所有边之后,我们就得到了两个子凸多边形 V1-V6-V7-V5和V6-V2-V3-V4-V7 。对应的代码为:
convex polygon 凸多边形
// divides a convex polygons into two convex polygons on both sides of a line
static void dividePoly(const float* in, int nin,
float* out1, int* nout1,
float* out2, int* nout2,
float x, int axis)
{
float d[12];
for (int i = 0; i < nin; ++i)
d[i] = x - in[i*3+axis];
int m = 0, n = 0;
for (int i = 0, j = nin-1; i < nin; j=i, ++i)
{
bool ina = d[j] >= 0;
bool inb = d[i] >= 0;
if (ina != inb)
{
float s = d[j] / (d[j] - d[i]);
out1[m*3+0] = in[j*3+0] + (in[i*3+0] - in[j*3+0])*s;
out1[m*3+1] = in[j*3+1] + (in[i*3+1] - in[j*3+1])*s;
out1[m*3+2] = in[j*3+2] + (in[i*3+2] - in[j*3+2])*s;
rcVcopy(out2 + n*3, out1 + m*3);
m++;
n++;
// add the i'th point to the right polygon. Do NOT add points that are on the dividing line
// since these were already added above
if (d[i] > 0)
{
rcVcopy(out1 + m*3, in + i*3);
m++;
}
else if (d[i] < 0)
{
rcVcopy(out2 + n*3, in + i*3);
n++;
}
}
else // same side
{
// add the i'th point to the right polygon. Addition is done even for points on the dividing line
if (d[i] >= 0)
{
rcVcopy(out1 + m*3, in + i*3);
m++;
if (d[i] != 0)
continue;
}
rcVcopy(out2 + n*3, in + i*3);
n++;
}
}
*nout1 = m;
*nout2 = n;
}
基于上面分隔凸多边形的原理,我们每相隔cellsize个单位(体素精度),分别在平行于x轴和z轴的方向设置分隔线就可以将三角形平面切割成cellsize精度的体素格子,体素格子的y坐标下沿取多边形顶点中的最小y坐标,体素格子的y坐标上沿取多边形顶点中的最大y坐标。如下图所示:
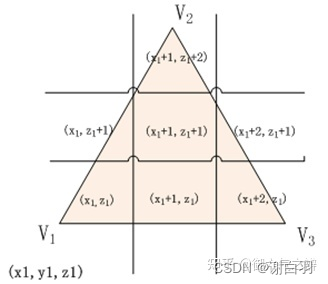
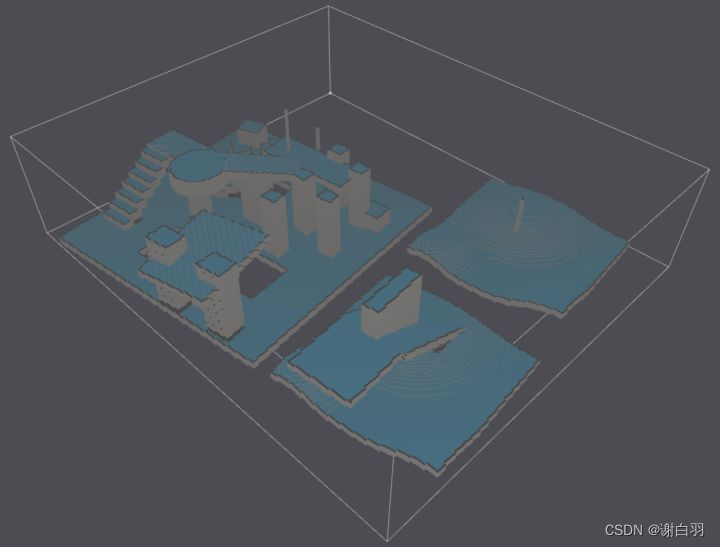
(2)过滤出可行走面(Walkable Suface)
- 概念介绍
根据哪些体素顶部有足够的空间可供行走,以及根据设置的参数,剔除过滤掉一些不符合要求的体素,初步计算出行走面。
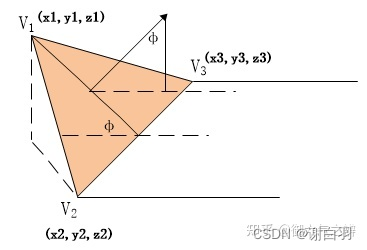

- 参数说明
rcContext* ctx 操作中需要的上下文信息
const float walkableSlopeAngle 坡度可行走的最大上限
const float* verts 三角形顶点坐标信息(x,y,z坐标)
int nv 顶点个数
const int* tris 三角形顶点参数
int nt 三角形个数
unsigned char* areas 标记是否是可行走区域(可行走的多边形)
/// The default area id used to indicate a walkable polygon.
/// This is also the maximum allowed area id, and the only non-null area id
/// recognized by some steps in the build process.
static const unsigned char RC_WALKABLE_AREA = 63;
- 源码接口
/// Sets the area id of all triangles with a slope below the specified value
/// to #RC_WALKABLE_AREA.
/// @ingroup recast
/// @param[in,out] ctx The build context to use during the operation.
/// @param[in] walkableSlopeAngle The maximum slope that is considered walkable.
/// [Limits: 0 <= value < 90] [Units: Degrees]
/// @param[in] verts The vertices. [(x, y, z) * @p nv]
/// @param[in] nv The number of vertices.
/// @param[in] tris The triangle vertex indices. [(vertA, vertB, vertC) * @p nt]
/// @param[in] nt The number of triangles.
/// @param[out] areas The triangle area ids. [Length: >= @p nt]
void rcMarkWalkableTriangles(rcContext* ctx, const float walkableSlopeAngle,
const float* verts, int /*nv*/,
const int* tris, int nt,
unsigned char* areas)
{
rcIgnoreUnused(ctx);
const float walkableThr = cosf(walkableSlopeAngle/180.0f*RC_PI);
float norm[3];
for (int i = 0; i < nt; ++i)
{
const int* tri = &tris[i*3];
calcTriNormal(&verts[tri[0]*3], &verts[tri[1]*3], &verts[tri[2]*3], norm);
// Check if the face is walkable.
if (norm[1] > walkableThr)
areas[i] = RC_WALKABLE_AREA;
}
}
(3)构建高度场HeightField
高度场是一个链表数组,每个链表是由一系列x、z坐标相同的体素格子链接而成。存储高度场的数据结构如下图所示:
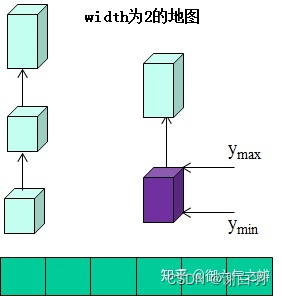
某个体素插入到链表数组里的哪个链表中,由x + z * width的值来决定(这个值是下标),这个值代表所插入链表在数组中的下标。比如x=1,z=1处的体素(在图中被标记为紫色)就插入到下标为3的链表中。如果待插入体素的y坐标范围与链表中已有体素的y坐标范围有重合,需要做体素合并。构建高度场的代码如下:
- 源码(while循环处)
static bool addSpan(rcHeightfield& hf, const int x, const int y,
const unsigned short smin, const unsigned short smax,
const unsigned char area, const int flagMergeThr)
{
int idx = x + y*hf.width;
rcSpan* s = allocSpan(hf);
if (!s)
return false;
s->smin = smin;
s->smax = smax;
s->area = area;
s->next = 0;
// Empty cell, add the first span.
if (!hf.spans[idx])
{
hf.spans[idx] = s;
return true;
}
rcSpan* prev = 0;
rcSpan* cur = hf.spans[idx];
// Insert and merge spans.
while (cur)
{
if (cur->smin > s->smax)
{
// Current span is further than the new span, break.
break;
}
else if (cur->smax < s->smin)
{
// Current span is before the new span advance.
prev = cur;
cur = cur->next;
}
else
{
// Merge spans.
if (cur->smin < s->smin)
s->smin = cur->smin;
if (cur->smax > s->smax)
s->smax = cur->smax;
// Merge flags.
if (rcAbs((int)s->smax - (int)cur->smax) <= flagMergeThr)
s->area = rcMax(s->area, cur->area);
// Remove current span.
rcSpan* next = cur->next;
freeSpan(hf, cur);
if (prev)
prev->next = next;
else
hf.spans[idx] = next;
cur = next;
}
}
// Insert new span.
if (prev)
{
s->next = prev->next;
prev->next = s;
}
else
{
s->next = hf.spans[idx];
hf.spans[idx] = s;
}
return true;
}
(4)高度场的可行走标记修正
-
定义:
walkableHeight ---- actor行走所需要的最小垂直高度
walkableClimb ----actor所能攀爬的最大垂直高度 -
场景1
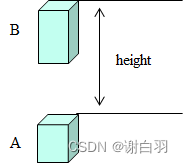
如果体素A是可行走的,并且height < walkableClimb,则体素B必然也是可行走的。 -
场景2
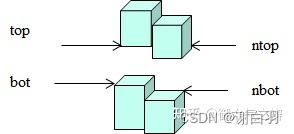
定义邻居体素可达的条件为:min(top, ntop) - max(bot, nbot) > walkableHeight。则对于某个体素,其所有可达的邻居体素中:
1.如果存在(bot - nbot > walkableClimb),则将该体素修正为不可行走。
2.如果max(nbot) - min(nbot) > walkableClimb,则将该体素修正为不可行走。
- 场景三
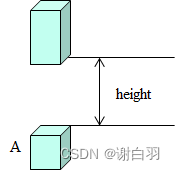
如果height < walkableHeight,则体素A需要修正为不可行走。
(5)构建紧凑高度场CompactHeightfield(反体素化)
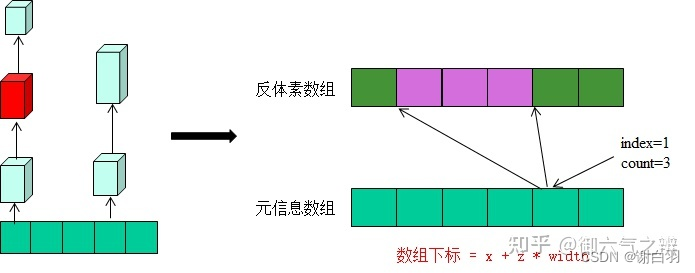
遍历之前的高度场数据,将体素信息转为反体素,反体素的y=体素的上沿y坐标,反体素的h=(链表下一个体素的下沿y坐标或者最大y坐标-该体素的上沿y坐标),不可行走的体素不用转换为反体素,
反体素的数据存储如上图所示。某个地点(x、z坐标)处的体素访问,首先计算值(x + z * width),用这个值去元信息数组中访问rcCompactCell数据。元信息数据中的index代表该处位置的反体素在反体素数组中的开始下标,count字段表示该地点(x、z坐标)有几层反体素
struct rcCompactCell
{
unsigned int index : 24; ///< Index to the first span in the column.
unsigned int count : 8; ///< Number of spans in the column.
};
(6)计算反体素的连通性
- 如下图所示,2个反体素要连通,需要满足两个条件。
1.2个反体素的y坐标差值要小于等于agent的可攀爬高度walkableClimb。
2.2个反体素的重叠部分的h要大于等于walkableHeight。
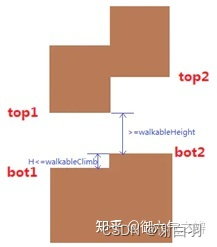
某个反体素与左右前后4个邻居反体素的连通信息存储在反体素结构的con字段,每个方向占6个bit,相应bit值表征连通邻居反体素的layer层。
/// Represents a span of unobstructed space within a compact heightfield.
struct rcCompactSpan
{
unsigned short y; ///< The lower extent of the span. (Measured from the heightfield's base.)
unsigned short reg; ///< The id of the region the span belongs to. (Or zero if not in a region.)
unsigned int con : 24; ///< Packed neighbor connection data.
unsigned int h : 8; ///< The height of the span. (Measured from #y.)
};
- 举例体素联通参数
比如con字段的二进制值为000001 000010 000000 000100时,意义如下:
- 左方向,该体素与layer为1的体素连通
- 上方向,该体素与layer为2的体素连通
- 右方向,该体素无连通体素
- 下方向,该体素与layer为4的体素连通
(7)裁剪可行走区域
我们采用dist数组来保存每个反体素与可行走区域边缘的最近距离。

对于上图的中间那个体素:
1.从左到右、由下及上扫描反体素时,绿色的那4个邻居体
素已先被扫描到。
2.从右到左、由上及下扫描反体素时,蓝色的那4个邻居体
素已先被扫描到。
因此,我们可以通过上述两次对所有反体素的扫描可以得到每个反体素与可行走区域边缘的最近距离。对于dist值小于agent直径的反体素,将其标记为不可行走
(8)标记体素掩码值
通过部署一些多边形柱子,然后遍历所有反体素,对于在多边形柱子内的反体素,将其areaId标记为相应值。areaId表示该体素是否可行走,是否是山地、草地之类。后续的区域划分会确保1个区域不会包含两种areaId,detour寻路也支持对于不同的areaId定义不同的单位路径损耗cost。
// (Optional) Mark areas.
const ConvexVolume* vols = m_geom->getConvexVolumes();
for (int i = 0; i < m_geom->getConvexVolumeCount(); ++i)
rcMarkConvexPolyArea(m_ctx, vols[i].verts, vols[i].nverts, vols[i].hmin, vols[i].hmax, (unsigned char)vols[i].area, *m_chf);
(9)区域划分算法
- 算法分类(略,不做详解)
1) 分水岭(watershed) :recast默认算法,效果好,速度慢。
2) Monotone:速度快。但是生成的 Region 可能会又细又
长,效果一般。
3) layers:类同monotone,只是区域在生成过程中不会有
叠层(不会跨相同x、z坐标的多个y坐标体素)
(10)生成 Region并裁剪
做区域裁剪前,需要找出每个区域的邻接区域。寻找邻接区域的流程如下图所示:
-
region定义
根据计算出来的行走面,使用特定算法,将这些可行走面切分为一个个尽量大的、连续的、不重叠的、中间没有“洞”的“区域”,这个区域就叫Region -
注意
由于不重叠,也就不再需要高度信息,因此在这一步就把问题从三维空间转换到了二维空间。 -
生成region的方法
1、分水岭算法(Watershed partitioning):最经典、效果最好,但处理比较慢,一般
用于离线处理。
2、Monotone partioning:最快且可以保证生成的是不重叠、没有洞的 Region,但是生
成的 Region 可能会又细又长,效果不好。
3、[Layer partitoining][Layer partitoining]:速度、效果都介乎分水岭算法和 Monotone
partioning 之间,比较依赖于初始数据。

-
流程图
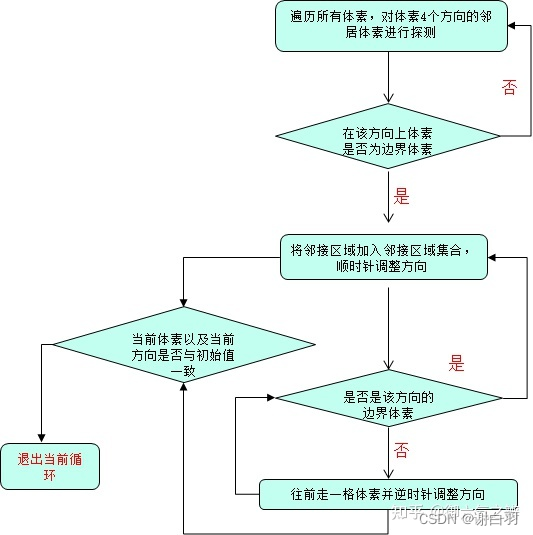
比如下面这个图中:(用区域算法生成区域)
1.区域7的邻接区域为区域6、3、8、9、5
2.区域5的邻接区域为区域4、6、7、9
-
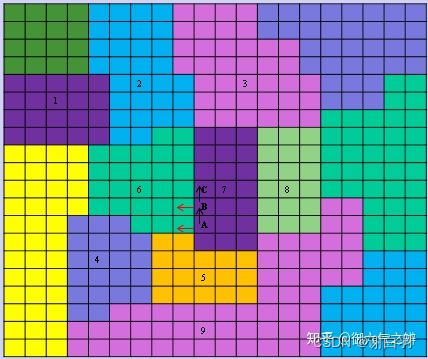
找出邻接区域后,再做如下处理来完成区域裁剪。
1.针对每个区域,采用深度优先遍历其所有邻接区域,如果
最终包含的体素数目小于minRegionArea,则将遍历到的所
有区域裁剪掉。我理解这个操作是为了减少比较小的孤立区
域。
2.对体素数量过少的区域A进行合并,合并到最小的邻接区
域B中。合并过程中,需要将A的邻接区域合并到B的邻接区
域中,针对所有区域的邻接区域,需要将其中的A区域需要
替换为B区域。
3.经过区域裁剪和合并后,region会变少,需要对区域的
regionID重新remap赋值,以此来降低regionID的最大值。
()中间打断总结
-
前面
Region 虽然是不重叠且没有洞的区域,但仍然有可能是凹多边形,但是无法保证 Region 内任意两点在二维平面一定可以直线到达。 -
后面的目的(将region拆分为多个多边形)
因此,接下来的步骤,就是为了将每个 Region 拆分为多个凸多边形。
(11)生成轮廓线Contour(边缘)
- 粗略流程概念
1)在这一步中,根据体素化信息和 Region,首先构建出描绘 Region 的 Detailed Contours(精确轮廓)。由于 Detailed Contour 以体素为单位构建边缘的,因此是锯齿状的。
2)接着,再将 Detailed Contours简化为 Simplified Contours(简化轮廓),方便后面的做三角形化(Triangulation)。在这一步之后,体素化数据就不再会被使用了。

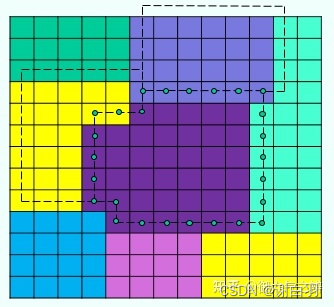
- 精细流程
与寻找邻接区域类似,都是沿着区域边界顺时针行走。行走过程中取轮廓点的规则为:
1) 体素左方是边界,轮廓点取其上方体素。
2) 体素上方是边界,轮廓点取其右上方体素。
3) 体素右方是边界,轮廓点取其右方体素。
4) 体素下方是边界,轮廓点取其自身。
这样做的目的是,使得各个区域的轮廓线多边形的边互相重合。最终效果如下图所示:
- 轮廓线简化
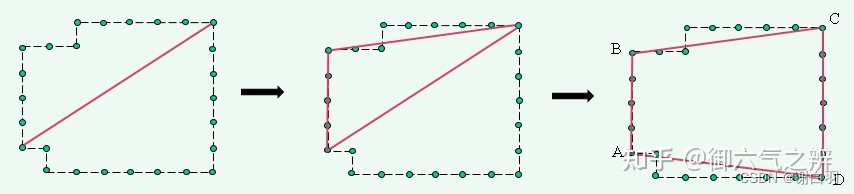
简化的目的是使用尽可能少的直线段来逼近带毛刺的边界。整个简化过程如下:
1) 左下角和右上角顶点作为初始轮廓。
2) 对于轮廓线段,遍历线段中间的其它顶点,找到偏离线段
最远的顶点,如果偏离距离大于指定值,则将该顶点加入轮
廓。
3) 一直迭代,直到所有顶点与轮廓的距离在指定值内。
- 检查轮廓线的空洞
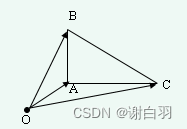
在说检测空洞之前,先讲下三角形面积与向量叉乘的关系。
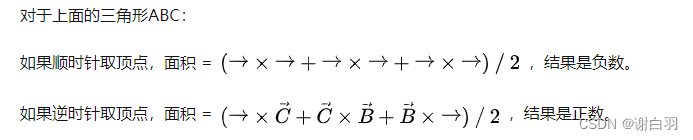
而正常轮廓线的顶点是顺时针存储,空洞轮廓线的顶点是逆时针存储。如下图所示:
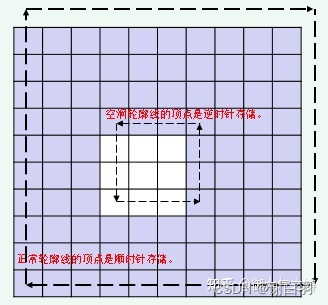

static int calcAreaOfPolygon2D(const int* verts, const int nverts)
{
int area = 0;
for (int i = 0, j = nverts-1; i < nverts; j=i++)
{
const int* vi = &verts[i*4];
const int* vj = &verts[j*4];
area += vi[0] * vj[2] - vj[0] * vi[2];
}
return (area+1) / 2;
}
- 合并空洞
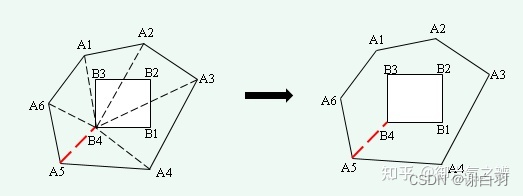
如上图所示,合并空洞的步骤分为:
1) 找到空洞的左下方顶点B4。
2) 将轮廓线所有顶点与B4相连,如果连线与轮廓线、空洞都不相交,则连线构成1条对角线。
3) 选择其中长度最短的1条对角线,将空洞合并到轮廓线中。
最终轮廓线的顶点序列为A5、A6、A1、A2、A3、A4、A5、B4、B1、B2、B3、B4。(如果包含多个空洞的话,将空洞按左下方顶点排序,依次迭代将外围轮廓与空洞进行合并。)
- 轮廓线三角剖分(耳切法)
耳尖的定义:
1.顶点是一个凸点
2.左右顶点相连的对角线与其它边不相交

- 图片解释
在上图中,V1、V4、V5、V6是耳尖,将对角线最短的耳尖V1进行切割,切割后需要对左右相邻的顶点是否为耳尖重新判断,
切割后耳尖为V2、V4、V5、V6、V7。经过多次迭代后,最终形成的三角形如下图所示:
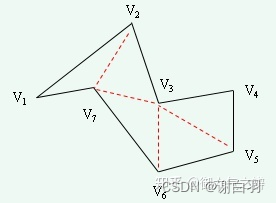
(12)凸多边形合并
- 定义
轮廓线经过三角剖分后形成了一系列凸多边形(三角形是最简单的凸多边形)。为了提升detour寻路的效率,我们需要凸多边形进行合并。 - 合并的条件(2个凸多边形必须满足下面两个条件才可以合并:)
1) 必须要有公共边
2) 合并后,公共边的2个顶点是否能维持凸点
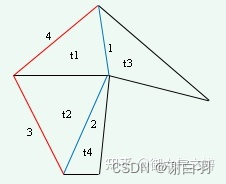
以上图举例说明,两个凸多边形合并后,其公共边的2个顶点能维持凸点的条件是:
(1) 边2在边1的右边(包括共线)。
(2) 边4在边3的右边(包括共线)。
在合并过程中,两个凸多边形的合并权重是其公共边的长度,每次都挑选合并权重最大的两个凸多边形进行合并。在上面这个图中,t1与t2可以合并,t2和t4可以合并。最终形成的效果如下图所示:
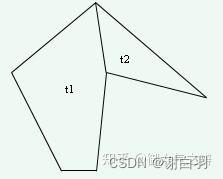
(12)生成 Poly Mesh
- 流程的目的和流程
由于大多数算法处理需要基于凸多边形,因此这一步就是将 Simplified Contours 切分为多个凸多边形。凸多边形在代码中会简称为 Polygon 或 Poly。在一个 Polygon 中,任意两个点在二维平面内都是可以直线到达的。因此,Polygon 是 Detour 的基本寻路单元。

(13)生成 Detailed Mesh(就是把 Polygon 继续做三角形化,生成了 Detailed Mesh)
-
概念介绍
如果把场景的拓扑结构看成一个无向图,其中每个 Polygon 是一个顶点。那么 Polygon 只是在拓扑结构上解决了寻路问题, -
目的
但是为了在具体寻路过程中,让角色更加贴合地面地行走,需要一些更精确的地形信息(比如高度)。因此还需要 -
流程
将 Polygon 拆分为更贴近地表形状的 Detailed Mesh。

(14)保存Poly Mesh 和 Detailed Mesh,其他的中间数据都被释放掉
3)Detour利用导航网格寻路的方法
(构建一个 dtNavMeshQuery 实例)
- 概念定义
通过前面的体素化、构建高度场、区域划分、轮廓线生成、三角剖分、凸多边形合并,我们将场景构建成了一系列可用于寻路的凸多边形。
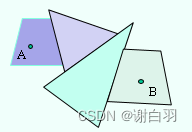
- Detour寻路算法步骤分为:(流程)
1) 寻找离起点A和终点B距离最近的凸多边形。
2) 通过A*寻路算法找出A点到B点所经过的凸多边形序列。
3) 通过漏斗算法确认出最终的路径。
(1)如何寻找最近的凸多边形(构建一颗BVH树)
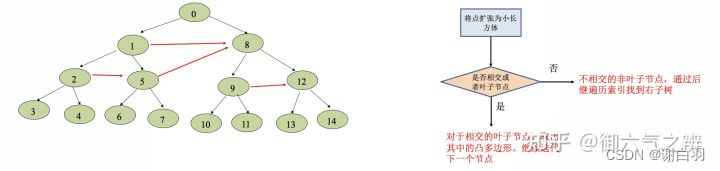
- 这颗BVH树的特点有:
1) 根节点的包围盒包含左右子树的包围盒
2) 叶子节点才存储凸多边形数据。
3) 划分左右子树的时候,选择最能均匀分隔凸多边形的坐标轴。
- 构建BVH树的代码如下所示
static void subdivide(BVItem* items, int nitems, int imin, int imax, int& curNode, dtBVNode* nodes)
{
int inum = imax - imin;
int icur = curNode;
dtBVNode& node = nodes[curNode++];
if (inum == 1)
{
// Leaf
node.bmin[0] = items[imin].bmin[0];
node.bmin[1] = items[imin].bmin[1];
node.bmin[2] = items[imin].bmin[2];
node.bmax[0] = items[imin].bmax[0];
node.bmax[1] = items[imin].bmax[1];
node.bmax[2] = items[imin].bmax[2];
node.i = items[imin].i;
}
else
{
// Split
calcExtends(items, nitems, imin, imax, node.bmin, node.bmax);
int axis = longestAxis(node.bmax[0] - node.bmin[0],
node.bmax[1] - node.bmin[1],
node.bmax[2] - node.bmin[2]);
if (axis == 0)
{
// Sort along x-axis
qsort(items+imin, inum, sizeof(BVItem), compareItemX);
}
else if (axis == 1)
{
// Sort along y-axis
qsort(items+imin, inum, sizeof(BVItem), compareItemY);
}
else
{
// Sort along z-axis
qsort(items+imin, inum, sizeof(BVItem), compareItemZ);
}
int isplit = imin+inum/2;
// Left
subdivide(items, nitems, imin, isplit, curNode, nodes);
// Right
subdivide(items, nitems, isplit, imax, curNode, nodes);
int iescape = curNode - icur;
// Negative index means escape.
node.i = -iescape;
}
}
(2)A星算法确定路径的凸多边形序列
A星算法的关键概念:
F = G + H
-
参数说明
1)G是初始顶点到当前凸多边形的真实代价。
2)H是启发式函数,表示当前凸多边形到终点的预估代价。
3)OpenList
待检查的凸多边形集合,利用F值作为排序key的最小堆。
4)CloseList
不会再被考虑的多边形集合。 -
以图举例
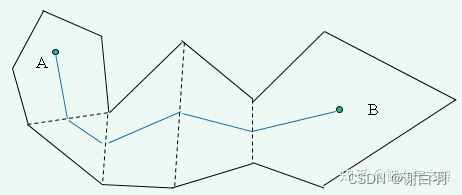
以上图为例,整个A星寻路的流程如下图所示:
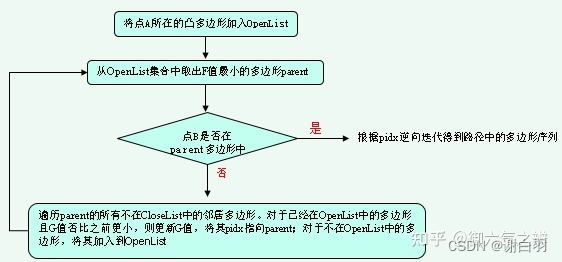
-
在算法迭代过程中,多边形的F值如何确定?
1) 多边形的G值 = parent凸多边形的G值 + 代表parent凸多边形的顶点到parent与该多边形公共边中
点的欧几里得距离。这里选择顶点代表凸多边形的规则为:parent凸多边形与其本身公共边的中点。
2) 多边形的H值 = parent与该多边形公共边中点到终点的欧几里得距离。
算法迭代过程中,顶点所用的数据结构如下所示,
cost 代表起点到此所用的开销
total 表示F值
pidx 代表parent凸多边形
flags 代表该点当前是在openList还是closeList中
id 代表其所属的凸多边形
struct dtNode
{
float pos[3]; ///< Position of the node.
float cost; ///< Cost from previous node to current node.
float total; ///< Cost up to the node.
unsigned int pidx : DT_NODE_PARENT_BITS; ///< Index to parent node.
unsigned int state : DT_NODE_STATE_BITS; ///< extra state information. A polyRef can have multiple nodes with different extra info. see DT_MAX_STATES_PER_NODE
unsigned int flags : 3; ///< Node flags. A combination of dtNodeFlags.
dtPolyRef id; ///< Polygon ref the node corresponds to.
};
(3)漏斗算法平滑路径
-
以图显示算法的过程
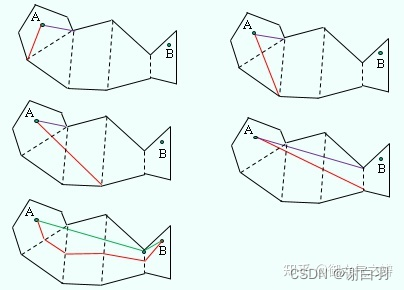
(起点A不仅作为漏斗的初始顶点,也作为漏斗的初始两个端口,此后两个端口不停地向公共边的两个端点移动。) -
漏斗左右端点继续移动,需要满足下面2个条件
1.移动端点后的边是朝向漏斗收缩的方向。
2.移动端点后的边没有跨过另外1条边。
-
条件原因解释
如果移动端点后的边是朝向漏斗收缩的方向,但会跨过另外1条边。— 此时将另外1个端点加入路径,并将其更新为新漏斗的顶点。 -
漏斗算法的相关代码如下(往右边走的代码, Right vertex):
在函数 dtNavMeshQuery::findStraightPath中
// Right vertex.
if (dtTriArea2D(portalApex, portalRight, right) <= 0.0f)
{
if (dtVequal(portalApex, portalRight) || dtTriArea2D(portalApex, portalLeft, right) > 0.0f)
{
dtVcopy(portalRight, right);
rightPolyRef = (i+1 < pathSize) ? path[i+1] : 0;
rightPolyType = toType;
rightIndex = i;
}
else
{
// Append portals along the current straight path segment.
if (options & (DT_STRAIGHTPATH_AREA_CROSSINGS | DT_STRAIGHTPATH_ALL_CROSSINGS))
{
stat = appendPortals(apexIndex, leftIndex, portalLeft, path,
straightPath, straightPathFlags, straightPathRefs,
straightPathCount, maxStraightPath, options);
if (stat != DT_IN_PROGRESS)
return stat;
}
dtVcopy(portalApex, portalLeft);
apexIndex = leftIndex;
unsigned char flags = 0;
if (!leftPolyRef)
flags = DT_STRAIGHTPATH_END;
else if (leftPolyType == DT_POLYTYPE_OFFMESH_CONNECTION)
flags = DT_STRAIGHTPATH_OFFMESH_CONNECTION;
dtPolyRef ref = leftPolyRef;
// Append or update vertex
stat = appendVertex(portalApex, flags, ref,
straightPath, straightPathFlags, straightPathRefs,
straightPathCount, maxStraightPath);
if (stat != DT_IN_PROGRESS)
return stat;
dtVcopy(portalLeft, portalApex);
dtVcopy(portalRight, portalApex);
leftIndex = apexIndex;
rightIndex = apexIndex;
// Restart
i = apexIndex;
continue;
}
}
至此,我们就找到1条起点到终点的平滑路径。
(4)补充:Poly Mesh和Detailed Mesh的寻路区别(返回结果不同)
1)Poly Mesh 颗粒度的寻路
- 返回值
返回结果是路径途径的 Poly 数组
2)Detailed Mesh 寻路 - 返回值
返回的是一个坐标点数组形式的路径
三、RecastNavigation 的局限性
1)使用recastNavigation的局限性(涉及前提)
1、假设 Agent 都是在地面行走且收到重力影响的。
2、假设 Agent 始终保持直立姿态的,即平行于重力方向。
3、Agent 不能飞,甚至不能跳。即使“走”在一些斜坡上,也始终应该是直立姿态,而不
能是垂直于地表(即地表法线方向)。
4、对于开放地图并不友好。如果需要判断远距离的两个点是否互相可到达,则需要将
这个范围内的所有导航网格加载完,才可计算出路径,才可以判断是否可达到。
- 补充备注
有了这些设计前提,才可以更方便地简化体素化时的数据结构,简化 Walking Surface 的计算生成。
2)难点未完待续(博主不懂的地方)
(1)现在国产武侠类 MMORPG 里大行其道的轻功、甚至御剑飞行,是无法只单纯依赖 RecastNavigation 的数据去实现的。特别是对于某些具有层次错落结构的地形,就非常容易出现掉到两片导航网格的夹缝里的情况。这类机制的实现需要其他场景数据的支持。
(2)像《塞尔达传说:旷野之息》的爬山、《忍者龙剑传》的踩墙这种机制,则会在生成导航网格的阶段就会遇到麻烦。因为设计前提2的存在,RecastNavigation 是无法对与地面夹角小于或等于90°的墙面生成导航网格的。因此需要从另外的机制、设计上去规避或处理。不过,貌似 Unity 2017 已经可以支持了在各种角度的墙面生成导航网格了:Ceiling and Wall Navigation in Unity3D。
四、A*算法、导航网格、路径点寻路对比(A-Star VS NavMesh VS WayPoint)
1)A*算法插件
- 特点
与贪婪算法不一样,贪婪算法适合动态规划,寻找局部最优解,不保证最优解。A*是静态网格中求解最短路最有效的方法。也是耗时的算法,不宜寻路频繁的场合。一般来说适合需求精确的场合。 - 备注
与启发式的搜索一样,能够根据改变网格密度、网格耗散来进行调整精确度 - 适用点
a.策略游戏的策略搜索
b.方块格子游戏中的格子寻路
2)U3D自带的导航网格系统
- 特点
U3D内置了NavMesh导航网格系统,一般来说导航网格算法大多是“拐角点算法”,具体大家可以去查下。效率是比较高的, - 缺点
但是不保证最优解算法。 - 适用点
a.游戏场景的怪物寻路
b.动态规避障碍
3)WayPoint寻路插件
- 特点
速度最快,但相应来说表现也非常局限,它常常走“Z”型的轨迹,并不适合复杂场合的使用。例如它不能根据宽度、高度、路径点耗散等来改变行进路径。 - 适用点
a.塔防怪物行进路径
b.AI巡逻路线

















 2595
2595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









