






文章目录
一、在线量化基础概念
(1)在线量化概念比喻和出现原因
-
在线量化概念比喻
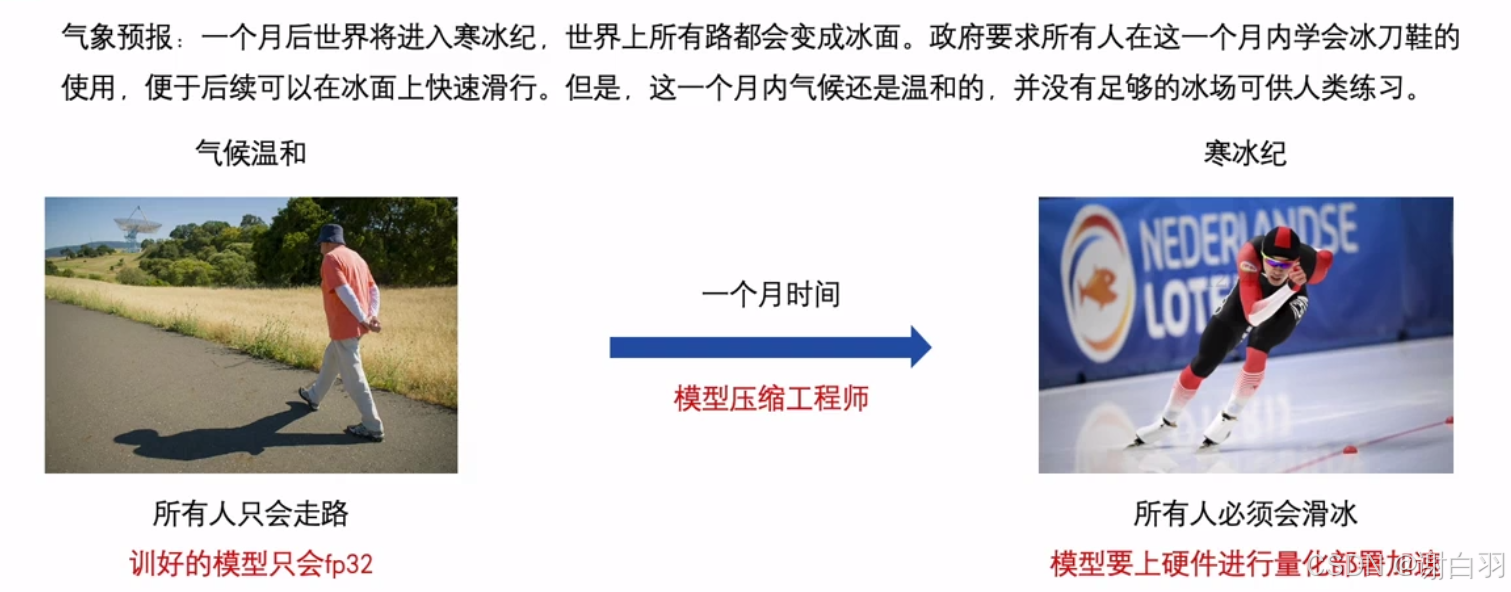
-
在线量化出现的原因
在使用离线量化的时候,大部分模型量化精度没问题,但还是少部分模型掉了很多精度 -
在线量化的背景
真实量化的硬件(手机等)没法训练网络,只能在显卡上模拟量化来训网络,一直训到网络完全适应模拟量化为止
(2)模拟量化过程
思路:模拟这个量化带来的误差,然后用带量化节点的网络去训练模型
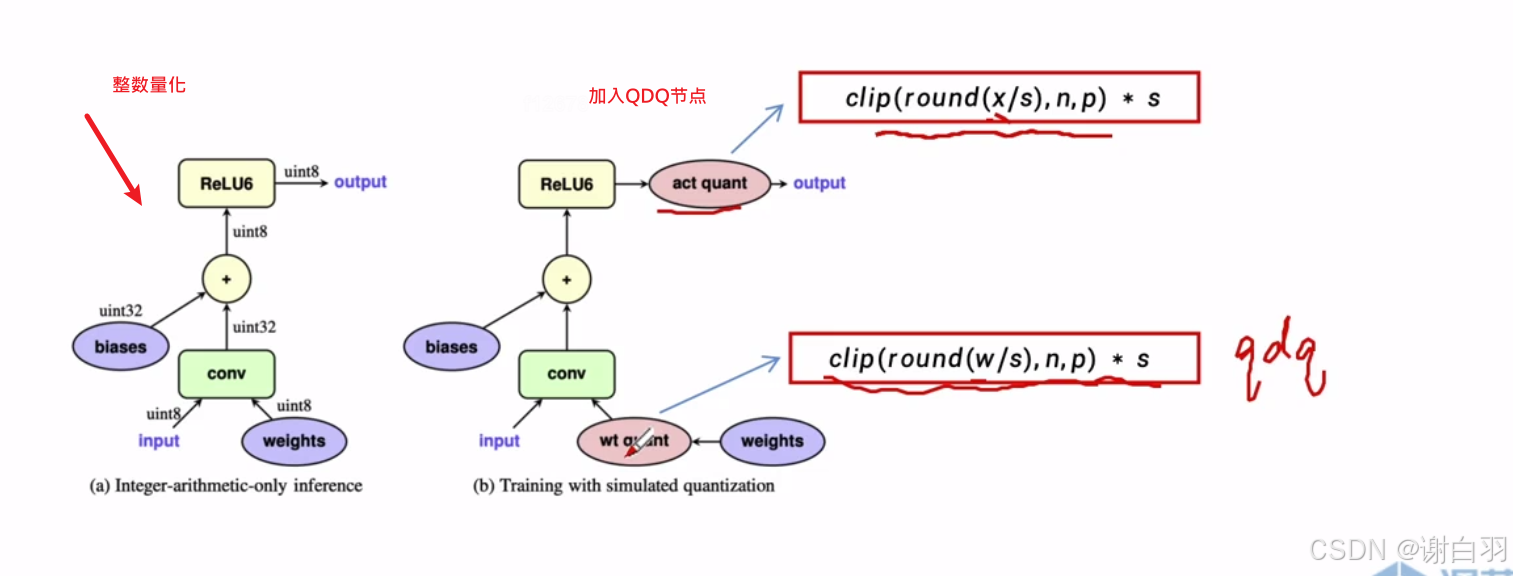
- 伪代码展示

- 重点
只改网络,loss不变 - 前向推导解释(用对称量化举例子)
①n和p代表的是量化之后的最小值和最大值
②round(w/s)表示四舍五入w/s的值
③clip(round(w/s),n,p)是量化的部分
④乘上s表示反量化
(3)离线量化和在线量化区别
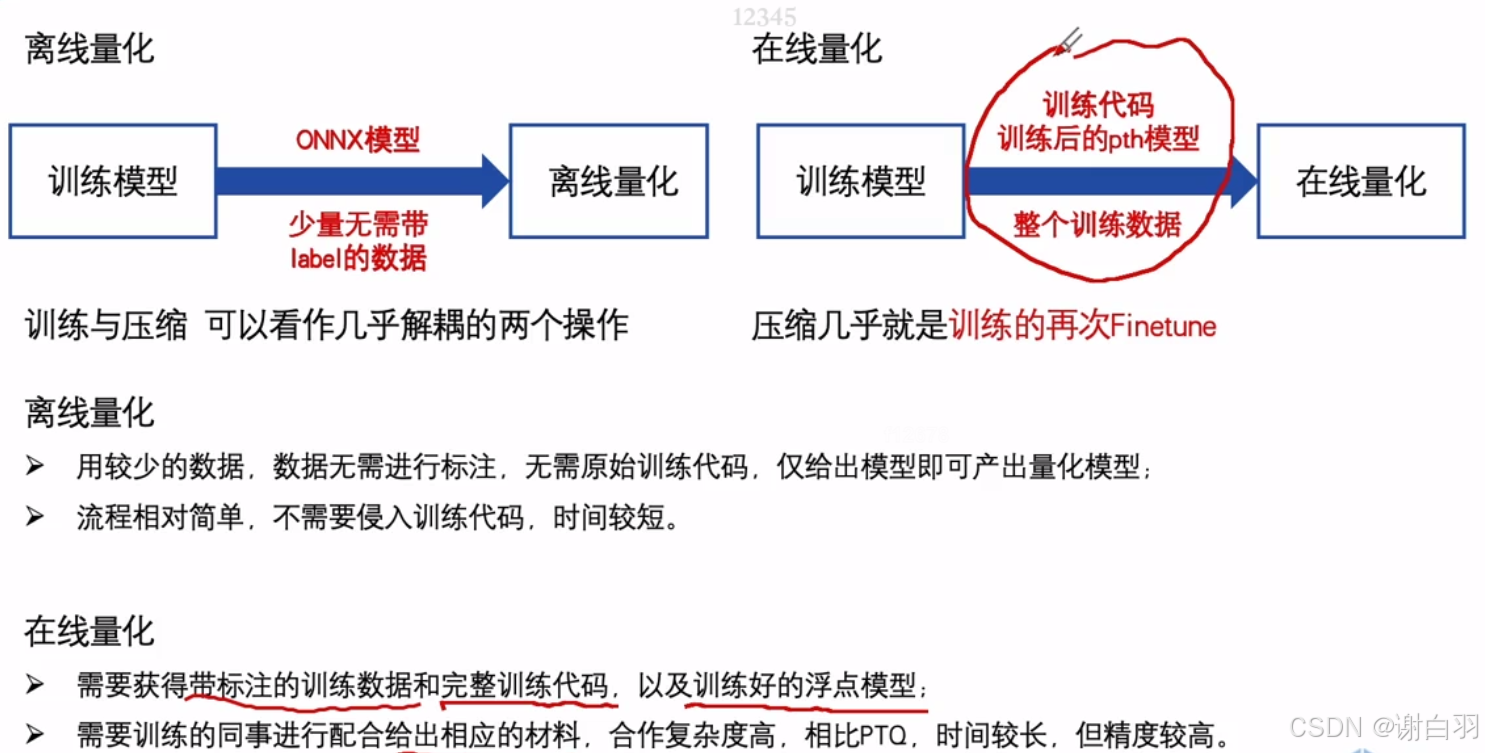
- 如何抉择

二、在线量化基本流程
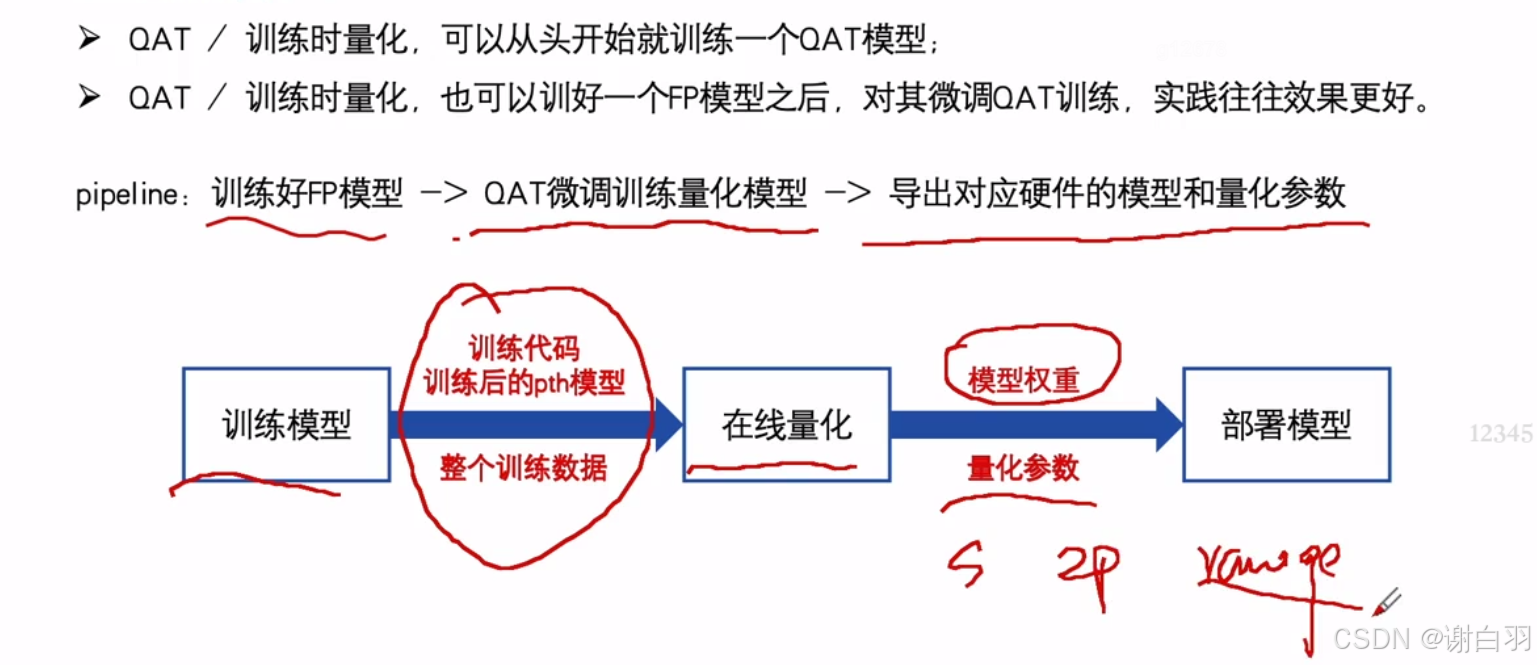
(1)QAT整体的pipeline
导出的数据:
①模型权重weight
②scale
③zero point
④dynamic range
(2)QAT超参选择
①学习率选择(初始学习率应该比较低)

②BN层的统计参数(均值和方差)可以冻住,只学习他的gamma和beta参数
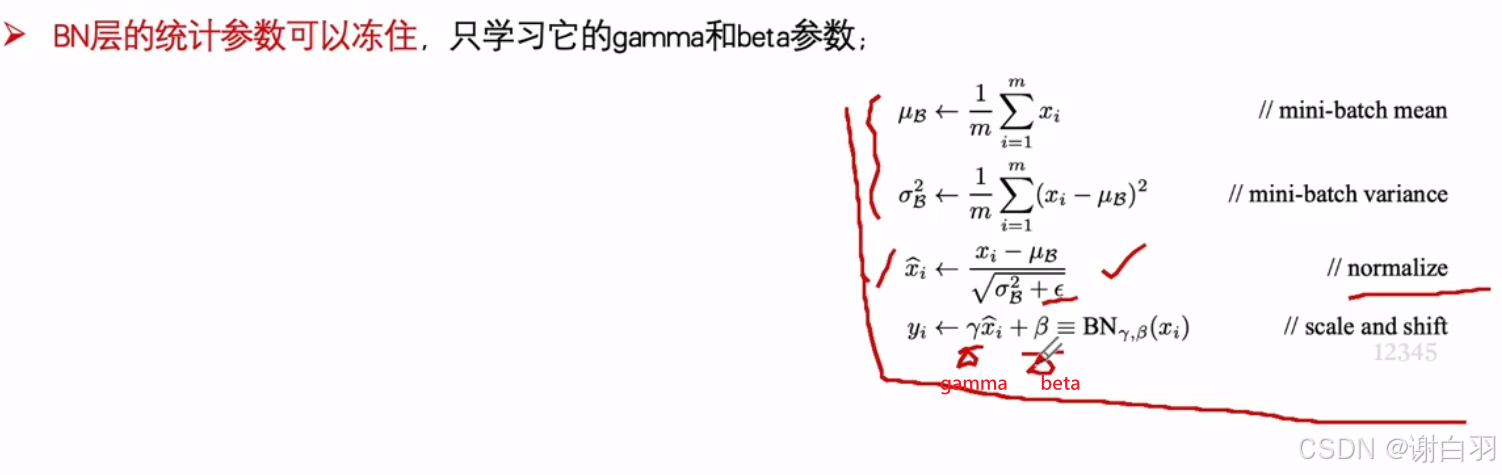
③数据增强可以和测试过程对齐

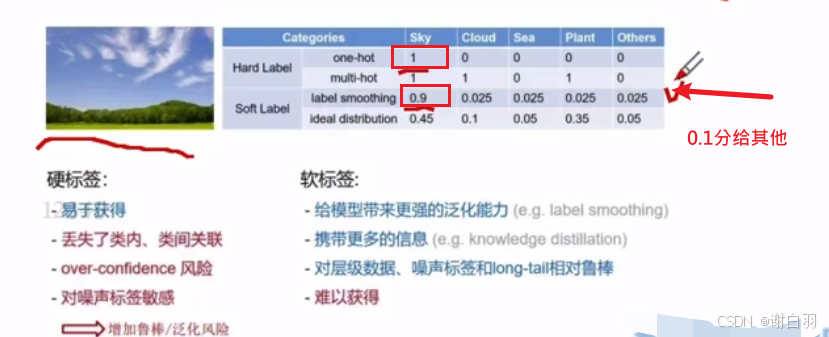
④分类任务可以使用label smooth
原理:把一些分类的confidence分给其他类
⑤QAT的量化参数初始化可以来源PTQ的结果:
原理:可以先做一遍PTQ,得到scale和zero_point
(3)QAT的几个关键点
- 总结
①对齐硬件的setting
②通过插入伪量化节点,来模拟量化误差,从而在微调QAT中,用训练方式减缓这种量化误差
③对齐硬件的拓扑图的量化特性
④BN的fuse也要被模拟
①对齐硬件的setting
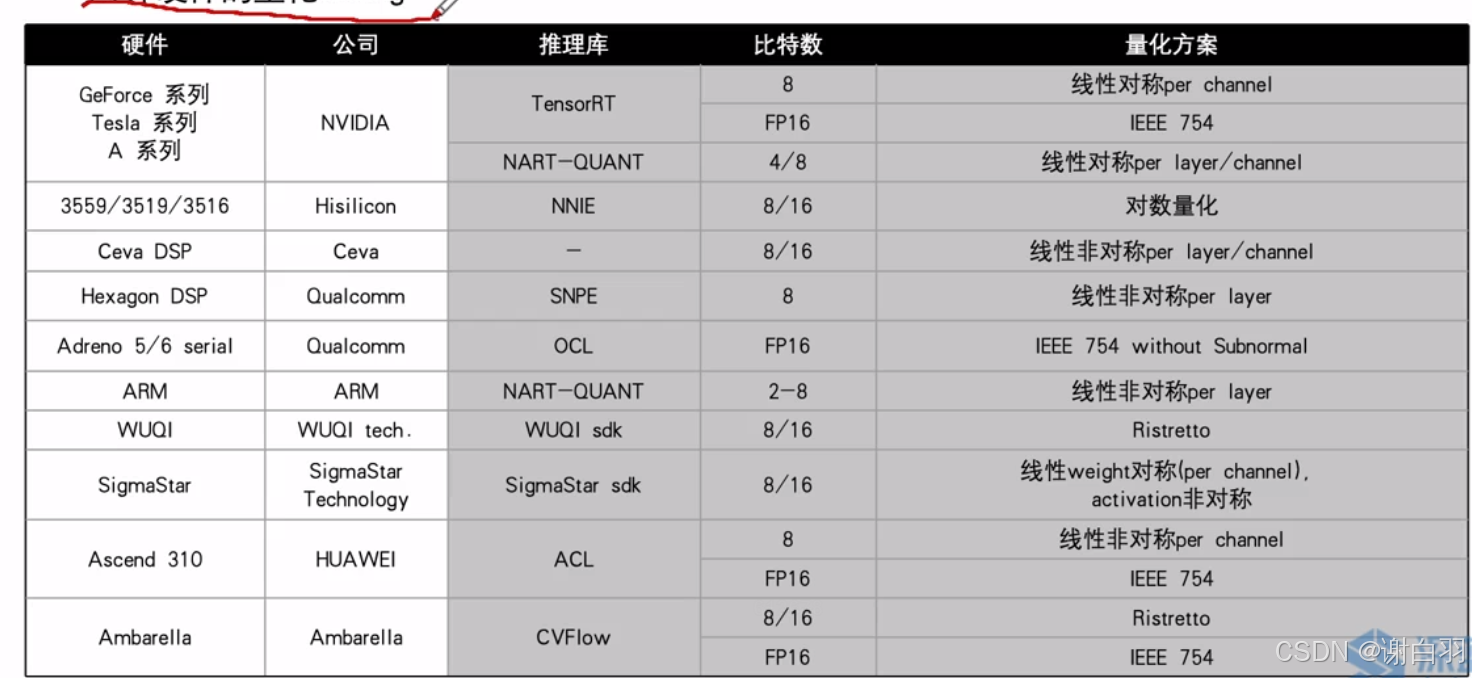
- 备注
1)之前做的是线性对称方案
2)若是不对称的话,得需要加上zero_point

②通过插入伪量化节点,来模拟量化误差,从而在微调QAT中,用训练方式减缓这种量化误差
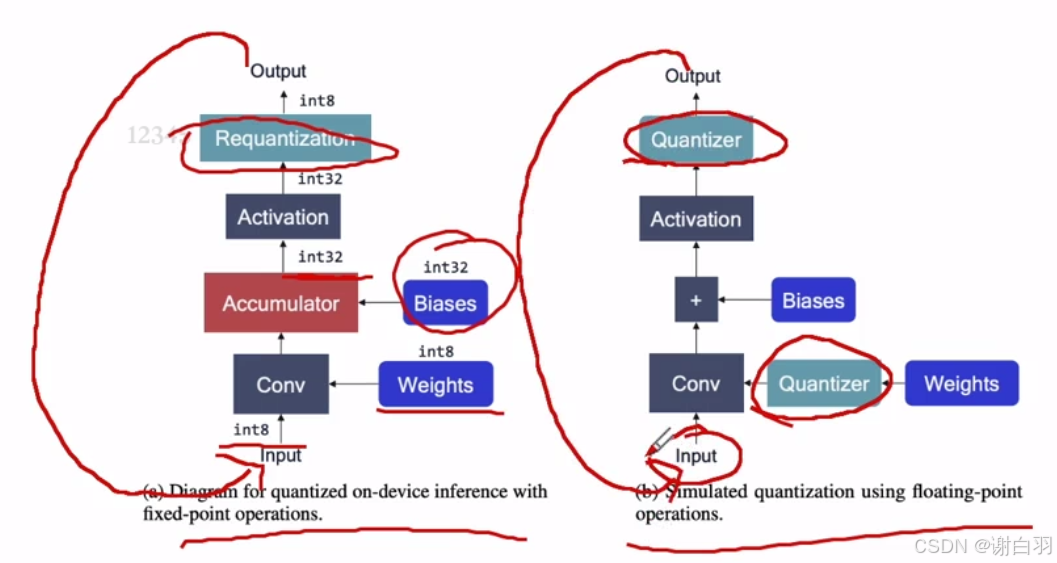
③对齐硬件的拓扑图的量化特性
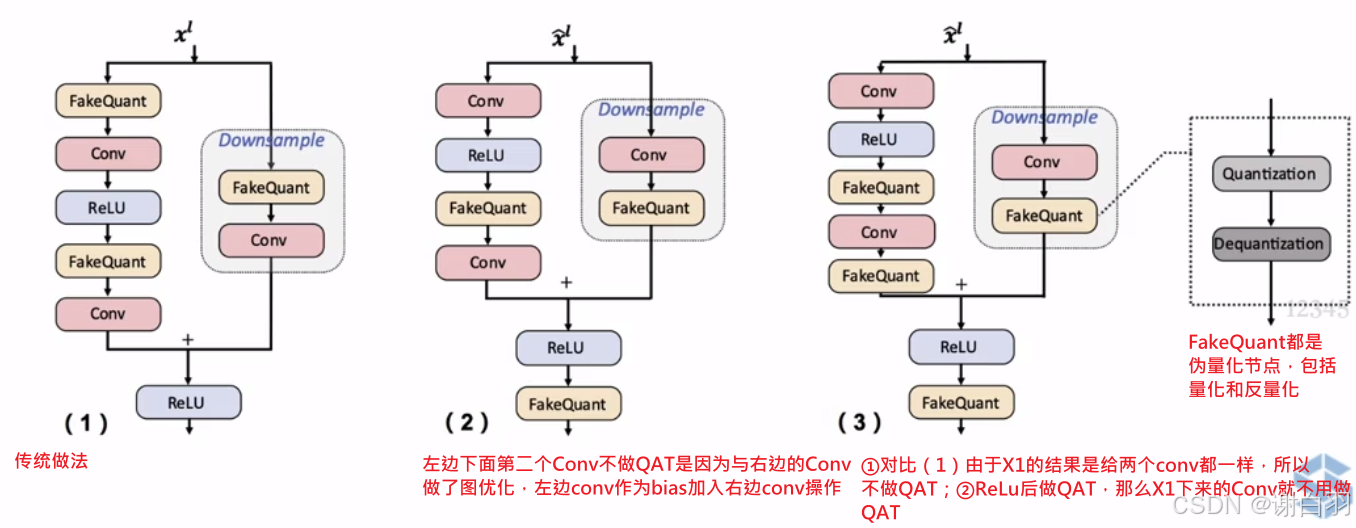
④BN的fuse(也叫fold)也要被模拟
原因:conv和BN一般在做推理的时候会被融合成一个conv,但是在训练的时候需要把bn加上
做法:网上搜索BN的fold融合,下图是BN和卷积层融合的过程

思路:在量化感知训练(QAT)中,需要还原BN层中的一些参数,通常是将BN层的参数融合到卷积层权重中,这样做的原因是在量化过程中,能够更好地保证模型的精度,使模型适应量化带来的数值表示变化。
import torch
import torch.nn as nn
def fuse_bn_to_conv(conv_layer, bn_layer):
# 获取 BN 层的参数
gamma = bn_layer.weight
beta = bn_layer.bias
running_mean = bn_layer.running_mean
running_var = bn_layer.running_var
eps = bn_layer.eps
# 计算卷积层的新权重和偏置
if conv_layer.weight.shape[0] == gamma.shape[0]:
new_weight = gamma.view(-1, 1, 1, 1) * conv_layer.weight * torch.rsqrt(running_var + eps)
new_bias = beta - gamma * running_mean / torch.sqrt(running_var + eps)
else:
new_weight = gamma.view(conv_layer.weight.shape[0] // gamma.shape[0], -1, 1, 1) * conv_layer.weight * torch.rsqrt(running_var + eps)
new_bias = beta - gamma.view(conv_layer.weight.shape[0] // gamma.shape[0], -1).mean(dim=1) * running_mean / torch.sqrt(running_var + eps)
# 更新卷积层的参数
conv_layer.weight.data = new_weight
conv_layer.bias.data = new_bias
# 示例用法
conv = nn.Conv2d(3, 16, 3, stride=1, padding=1)
bn = nn.BatchNorm2d(16)
# 假设已经训练好了 conv 和 bn 层,进行参数融合
fuse_bn_to_conv(conv, bn)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









