








Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction(中文翻译-机翻)
链接
源项目链接:https://chenhsuanlin.bitbucket.io/3D-point-cloud-generation
文章链接:https://arxiv.org/pdf/1706.07036.pdf
代码(pytorch版):https://github.com/lkhphuc/pytorch-3d-point-cloud-generation
代码(tensorflow版):https://github.com/chenhsuanlin/3D-point-cloud-generation
翻译
Abstract
传统的三维对象生成建模方法学习体积预测使用深度网络与三维卷积运算,这是直接类比经典的二维模型。然而,这些方法在试图预测三维形状时计算量很大,因为只有在表面上信息丰富。在本文中,我们提出了一种新的三维生成建模框架,以高效地生成密集点云形式的物体形状。我们使用二维卷积运算从多个视点预测三维结构,并将几何推理与二维投影优化相结合。我们引入伪渲染器,一个近似真实渲染操作的可微模块,合成新的深度图进行优化。对单幅图像三维物体重建任务的实验结果表明,该方法在形状相似度和预测密度方面优于现有方法。
1 Introduction
使用卷积神经网络(ConvNets)的生成模型在图像/物体生成问题上达到了最先进的水平。该类的著名作品包括变分自编码器[14]和生成对抗网络[7],两者都在各种应用中取得了巨大成功[11,20,35,27,30]。随着最近大型公开可用的3D模型库的引入[291,1],使用类似框架对3D数据进行生成建模的研究也变得越来越有兴趣。
在计算机视觉和图形学中,3D对象模型可以采用各种形式的表示。其中,三角形网格和点云因其向量化(因此可伸缩)的数据表示以及形状信息的紧凑编码(可选择嵌入纹理)而流行。然而,这种有效的表示有一个固有的缺陷,每个3D形状样本的维度可以变化,使学习方法的应用有问题。此外,由于不能直接应用欧氏卷积运算,这样的数据表示不适合传统的ConvNets。迄今为止,大多数现有的三维模型生成工作诉诸于体积表示,允许三维欧氏卷积在规则离散体素网格上操作。3D ConvNets(与经典的2D形式相反)已成功应用于鉴别[29,18,9]和生成[6,2,31,28]问题的3D体积表示。
尽管它们最近取得了成功,但3D ConvNets在用体积表示的形状建模时存在固有的缺陷。二维图像的每个像素都包含有意义的空间和纹理信息,与之不同的是,体积表示是信息稀疏的。更具体地说,3D对象被表示为体素占位网格,其中对象“外部”(设置为关闭)和对象“内部”(设置为打开)的体素不重要,基本上没有什么特别的意义。换句话说,形状表示的最丰富的信息存在于3D对象的表面,它只占占用网格中所有体素的一小部分。因此,3D ConvNets在试图使用高复杂度的3D卷积预测大量无用数据时,在计算和内存方面都是极其浪费的,严重限制了3D体积形状的粒度,甚至可以在深度学习研究中常用的高端gpu节点上建模。在本文中,我们提出了一个有效的框架来表示和生成带有密集点云的三维物体形状。我们通过学习从多个视点预测三维结构,通过三维几何推理共同优化来实现这一目标。与现有技术采用3D ConvNets对体积数据进行操作相比,我们利用2D卷积操作来预测塑造3D物体表面的点云。我们的实验结果表明,我们生成的形状比最先进的3D预测方法更密集、更精确。
我们的贡献总结如下:
- 我们主张2D ConvNets能够生成稠密的点云,在非离散的3D空间中塑造3D物体的表面。
- 我们引入了一个伪渲染管道,作为真实渲染的可微近似。我们进一步利用伪渲染深度图像进行二维投影优化,以学习密集的3D形状。
- 我们展示了我们的方法在单幅图像三维重建问题上的有效性,它明显优于最先进的方法。
2 Related Work
三维形状的生成。由于2D ConvNets在许多图像生成问题上取得了巨大的成功,大多数3D形状生成的工作都遵循使用3D ConvNets生成体积形状的模拟方法。先前的工作包括使用3D自动编码器[6]和循环网络[2]学习潜在表示的体积数据生成。类似的应用包括使用附加的编码姿势嵌入来学习形状变形[33],以及使用对抗训练来学习更真实的形状生成[28,5]。研究人员还探索了从2D投影观测中学习体积预测[31,22,5],该方法使用体素网格上的3D可微采样进行空间转换[12]。限制二维观测的射线一致性也是最近才提出的。
上述大多数方法都使用3D卷积运算,计算成本高,且只允许粗3D体素分辨率。在这些作品之后,缺乏这种体积生成的粒度一直是一个公开的问题。Riegler等人[23]提出通过在体素网格上使用自适应分层八进制树来解决这一问题,以鼓励对3D形状中信息量更大的部分进行编码。并发工作使用类似的概念[8,25]来预测更高粒度的3D体积数据。
最近,Fan等人[4]也试图通过使用多层感知器的变体来预测多个3D坐标,从而生成无序点云。然而,所需的可学习参数与三维点预测的数量成线性正比,并不能很好地伸缩;此外,使用三维距离度量作为优化标准对于大量的点是难以处理的。相比之下,我们利用卷积运算和联合的2D项目准则来捕获生成的点云之间的相关性,并以更易于处理的计算方式进行优化。
3D视图合成。在学习合成图像中2D对象的新颖3D视图方面也进行了研究。大多数使用ConvNets的方法都遵循编码器-解码器框架的约定。通过将3D姿态信息混合到合成解码器的潜在嵌入向量中,可以探索这一问题[24,34,19]。这些工作的一部分还讨论了将三维姿态表示从物体身份信息中分离出来的问题[16,32,21],允许进一步控制身份表示空间。
这些方法的缺点是它们在表示3D几何图形时效率低——正如我们稍后在实验中展示的那样,人们应该显式地分解底层3D几何图形,而不是隐式地将其编码到混合表示中。在一些工作中(如空间变压器网络/Transformer Networks[12,17]),已经证明解决几何问题比容忍问题更有效。
3 Approach (此节符号对应着英文看)

图1:网络架构。从编码的潜在表示中,我们建议使用基于二维卷积运算的结构生成器(章节3.1)来预测N个视点的三维结构。通过将每个视点处的三维结构转换为标准坐标来融合点云。伪渲染器(第3.2节)从新的视点合成深度图像,进一步用于联合2D投影优化。这并不包含纯粹基于3D几何的可学习参数和原因
我们的目标是生成3D预测,用密集的点云紧凑地塑造表面几何形状。整个管道如图1所示。我们从一个将输入数据映射到潜在表示空间的编码器开始。编码器可以根据应用程序采用各种形式的数据;在我们的实验中,我们专注于编码RGB图像的单幅图像三维重建任务。从潜在表示中,我们提出使用基于二维卷积和联合二维投影准则的结构生成器生成密集点云,具体描述如下。
3.1 Structure Generator
结构生成器预测物体在N个不同视点上的三维结构(以及它们的二进制掩码),即三维坐标为:ˆxi = [ˆxi ˆyi ˆzi] ;在每个像素位置。自然图像中的像素值可以通过卷积生成模型合成,这主要是由于它们表现出很强的局部空间依赖性;当把点云作为二维网格上的(x, y, z)多通道图像处理时,可以观察到类似的现象。基于这种洞察力,结构生成器主要基于二维卷积运算来预测(x, y, z)表示三维表面几何形状的图像。这种方法避免了体积预测所需的耗时和占用内存的三维卷积运算。实验结果验证了该方法的有效性。
设N个视点的三维刚变换矩阵(R1, t1)…(RN, tN)是给定先验的,在视点n处的每一个三维点ˆxi都可以通过公式1转化为规范的三维坐标 ˆpi
 其中K为预定义的摄像机内参数矩阵。这定义了预测的3D点和标准3D坐标中点云的融合集合之间的关系,这是我们的网络的结果。
其中K为预定义的摄像机内参数矩阵。这定义了预测的3D点和标准3D坐标中点云的融合集合之间的关系,这是我们的网络的结果。
3.2 Joint 2D Projection Optimization
为了学习使用所提供的3D CAD模型作为监督生成点云,标准方法是优化基于3D的度量,该度量定义了点云和地面真实CAD模型之间的距离(例如,切角距离[4])。这种度量通常涉及计算每个生成点的曲面投影,这对于非常密集的预测来说计算成本很高,使其难以处理。
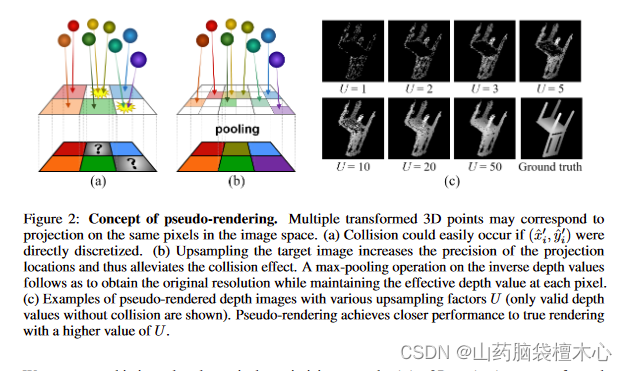
图2:伪渲染的概念。多个转换后的3D点可以对应于图像空间中相同像素上的投影。(a)如果将(x.x ’ i, x.y ’ i)直接离散化,很容易发生碰撞。(b)目标图像的上采样提高了投影位置的精度,从而缓解了碰撞效应。然后对反向深度值进行最大池化操作,以获得原始分辨率,同时保持每个像素处的有效深度值。©具有不同上采样因子U的伪渲染深度图像示例(仅显示没有碰撞的有效深度值)。伪渲染通过更高的U值实现与真实渲染更接近的性能。
我们通过交替优化新视点的联合二维投影误差来克服这个问题。我们不只是使用投影的二元掩模作为监督[31,5,22],我们推测一个生成良好的3D形状也应该具有从任何视点渲染合理深度图像的能力。为了实现这一概念,我们引入了伪渲染器,一个近似真实渲染的可微模块,从密集的点云合成新的深度图像。
伪渲染器
此部分看英文

优化
此部分看英文


4 Experiments (此部分看英文,这里给出提纲)
我们通过分析其在单幅图像三维重建中的应用性能,并与现有的方法进行比较,来评价我们提出的方法。
Data preparation-数据准备
Architectural details- 网络构建细节
Training details-训练细节
Quantitative metrics-定量指标
4.1 Single Object Category
我们首先评估我们的密集点云表示在单个对象类别的3D重建上的有效性。我们使用ShapeNet的椅子类别,它由6778个CAD模型组成。我们将其与(a) Tatarchenko等人24和(b)透视变压器网络(PTN)31进行比较。我们包括PTN的两个变体以及Yan等人的基线3D ConvNet。[31]。我们使用Yan等人提供的80%-20%的训练/测试分割。[31]
我们为200K次迭代预先训练我们的网络,并为100K次迭代微调端到端。对于Tatarchenko et al.[24]的方法,我们通过预测来自相同N个视点的深度图像进行评估,并将得到的点云转换为规范坐标。这与我们的网络架构相同,但使用3个线性层(带有64个过滤器)额外编码3D姿势信息,并与潜在向量连接。我们使用新的深度/掩码对作为解码器输出的直接监督,并以恒定的学习率1e-2训练该网络进行300K迭代。对于PTN[31],我们提取表面体素(通过用它的侵蚀版本减去预测)并缩放它们,以便预测的最紧密的3D边界框和地面真实的CAD模型具有相同的体积。我们使用作者提供的预先训练的模型。
试验分割的定量结果见表2。尽管我们的方法优化了联合2D投影,而不是这些3D误差指标,但在这两个指标中,我们实现了比所有基线更低的平均3D距离。这表明,我们可以用更高的密度和更细的粒度预测更准确的形状。与PTN[31]等3D ConvNet方法相比,这突出了我们使用2D ConvNet方法生成3D形状的效率,因为PTN[31]等3D ConvNet方法试图预测3D网格空间中的所有体素占用率。与Tatarchenko等人[24]相比,一个重要的收获是3D几何应该在可能的情况下显式分解,而不是通过网络参数隐式学习。从足够多的视点集中预测几何形状,并将它们与已知的几何变换结合起来,效率会高得多。
 表2 单类实验的平均3D测试误差。我们的方法在这两个指标上优于所有基线,表明在细粒度形状相似性和点云覆盖表面上的优势。(所有数字都按比例乘以0.01)
表2 单类实验的平均3D测试误差。我们的方法在这两个指标上优于所有基线,表明在细粒度形状相似性和点云覆盖表面上的优势。(所有数字都按比例乘以0.01)
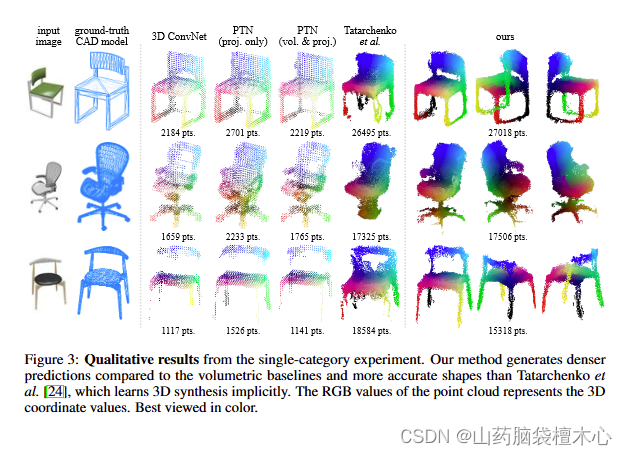 图3:单类别实验的定性结果。与体积基线相比,我们的方法产生了更密集的预测,比Tatarchenko等人[24]更精确的形状,后者隐式地学习3D合成。点云的RGB值代表三维坐标值。最佳观赏色彩。
图3:单类别实验的定性结果。与体积基线相比,我们的方法产生了更密集的预测,比Tatarchenko等人[24]更精确的形状,后者隐式地学习3D合成。点云的RGB值代表三维坐标值。最佳观赏色彩。
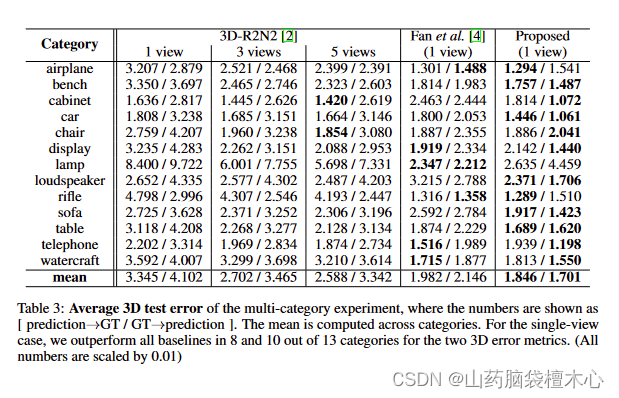 表3 多类实验的3D测试平均误差,其中数值表示为[预测→GT / GT→预测]。平均值是跨类别计算的。对于单视图情况,我们在两个3D错误度量的13个类别中,有8个和10个优于所有基线。(所有数字都按比例乘以0.01)
表3 多类实验的3D测试平均误差,其中数值表示为[预测→GT / GT→预测]。平均值是跨类别计算的。对于单视图情况,我们在两个3D错误度量的13个类别中,有8个和10个优于所有基线。(所有数字都按比例乘以0.01)
我们在图3中可视化生成的3D形状。与基线相比,我们预测了更精确的对象结构,点云密度更高(比32^3体积方法高约10倍)。这进一步强调了我们的方法的可取性——我们能够有效地使用二维卷积运算,并在相似的内存预算下利用高分辨率监督。
4.2 General Object Categories
我们还在多目标分类训练的单幅图像三维重建任务中评估了我们的网络。我们比较了(a) 3D- r2n2[2]和(b) Fan等人[4],前者通过循环网络学习体积预测,后者预测1024个3D点的无序集合。我们使用13类ShapeNet进行评估(见表3),其中80%-20%的训练/测试分割由Choy等人[2]提供。我们通过3D-R2N2的表面体素,使用第4.1节所述的相同程序来评估它。我们为300K次迭代预先训练我们的网络,并为100K次迭代微调端到端;对于基线,我们使用作者提供的预先训练的模型。
我们在表3中列出了量化结果,其中指标是按类别报告的。我们的方法实现了两个指标的整体较低的误差。在大多数情况下,我们比体积基线(3D-R2N2)具有更好的预测性能。我们还将图4中的预测可视化;我们再次看到,我们的方法预测更准确的形状与更高的点密度。我们发现,当物体包含非常薄的结构(如灯)时,我们的方法可能更有问题;添加混合线性层[4]可能有助于提高性能
4.3 Generative Representation Analysis
我们通过观察潜在空间中操作的三维预测来分析学习到的生成表示。先前的研究表明,深度生成网络可以通过在潜在空间中执行线性操作来生成有意义的像素/体素预测[20,3,28];在这里,我们探索了在非离散空间中对密集点云进行这种操作的可能性。我们在图5中展示了由嵌入向量插值到潜在空间中生成的结果密集形状。变形过渡是平滑的,有似是而非的插值形状,这表明我们的结构生成器可以从编码潜在向量的凸组合中产生有意义的3D预测。结构生成器还能够从潜在空间的算法结果中生成合理的新形状——从图6中我们观察到桌子高度/形状以及椅子扶手/靠背的语义特征替换。这些结果表明,隐藏向量中编码的高级语义信息可以通过结构生成器对生成的密集点云进行操作和解释。
 ### 5 Conclusion
### 5 Conclusion
本文介绍了一种以密集点云形式生成三维图形的框架。与传统的三维卷积体积预测方法相比,利用二维卷积运算对三维形状的表面信息进行预测效率更高。我们证明,通过引入伪渲染器,我们能够从新的视点合成近似的深度图像,以优化反向传播框架内的2D投影误差。对单幅图像三维重建任务的实验结果表明,与现有的三维重建方法相比,我们生成的三维形状更精确、密度更大。















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









