






阿里云语言识别使用
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
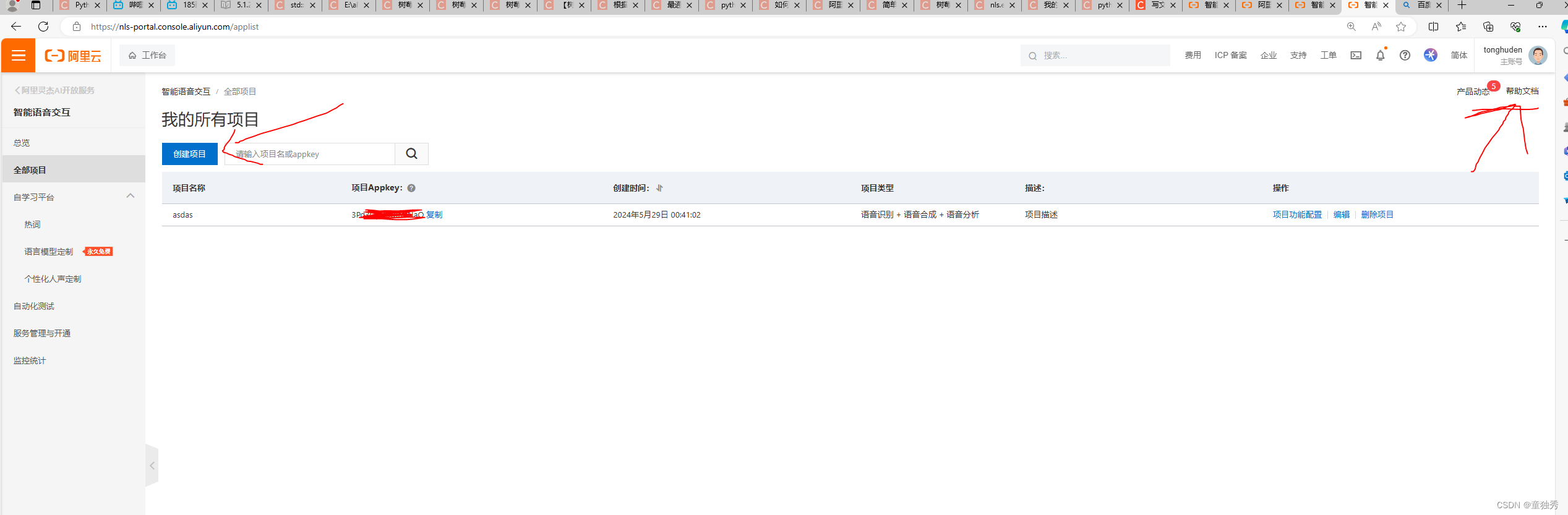
点击文档->语言识别->一句话识别->各类接口
二、使用步骤
import time
import threading
import sys
import nls
URL="wss://nls-gateway-cn-shanghai.aliyuncs.com/ws/v1"
TOKEN="yourToken" #参考https://help.aliyun.com/document_detail/450255.html获取token
APPKEY="yourAppkey" #获取Appkey请前往控制台:https://nls-portal.console.aliyun.com/applist
#以下代码会根据音频文件内容反复进行一句话识别
class TestSr:
def __init__(self, tid, test_file):
self.__th = threading.Thread(target=self.__test_run)
self.__id = tid
self.__test_file = test_file
def loadfile(self, filename):
with open(filename, "rb") as f:
self.__data = f.read()
def start(self):
self.loadfile(self.__test_file)
self.__th.start()
def test_on_start(self, message, *args):
print("test_on_start:{}".format(message))
def test_on_error(self, message, *args):
print("on_error args=>{}".format(args))
def test_on_close(self, *args):
print("on_close: args=>{}".format(args))
def test_on_result_chg(self, message, *args):
print("test_on_chg:{}".format(message))
def test_on_completed(self, message, *args):
print("on_completed:args=>{} message=>{}".format(args, message))
def __test_run(self):
print("thread:{} start..".format(self.__id))
sr = nls.NlsSpeechRecognizer(
url=URL,
token=TOKEN,
appkey=APPKEY,
on_start=self.test_on_start,
on_result_changed=self.test_on_result_chg,
on_completed=self.test_on_completed,
on_error=self.test_on_error,
on_close=self.test_on_close,
callback_args=[self.__id]
)
print("{}: session start".format(self.__id))
r = sr.start(aformat="pcm", ex={"hello":123})
self.__slices = zip(*(iter(self.__data),) * 640)
for i in self.__slices:
sr.send_audio(bytes(i))
time.sleep(0.01)
r = sr.stop()
print("{}: sr stopped:{}".format(self.__id, r))
time.sleep(1)
def multiruntest(num=500):
for i in range(0, num):
name = "thread" + str(i)
t = TestSr(name, "tests/test1.pcm")
t.start()
# 设置打开日志输出
nls.enableTrace(False)
multiruntest(1)
代码如下(示例):















 2213
2213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









