









信息熵理论和概率模型
信息熵知识
独立熵:
H
(
X
)
=
−
∑
x
∈
X
log
P
(
x
)
独立熵:H(X) = -\sum_{x \in X} \log P(x)
独立熵:H(X)=−∑x∈XlogP(x),表示X的不确定性
条件熵:
H
(
Y
∣
X
)
=
−
∑
x
∈
X
∑
y
∈
Y
P
(
x
,
y
)
log
P
(
y
∣
x
)
条件熵:H(Y|X) = -\sum_{x \in X} \sum_{y \in Y} P(x, y) \log{P(y|x)}
条件熵:H(Y∣X)=−∑x∈X∑y∈YP(x,y)logP(y∣x),表示在已知 X 的情况下,Y 的不确定性。
联合熵:
H
(
X
,
Y
)
=
H
(
X
)
+
H
(
Y
∣
X
)
=
H
(
Y
)
+
H
(
X
∣
Y
)
联合熵:H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)
联合熵:H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)
互信息:
I
(
X
;
Y
)
=
H
(
X
)
+
H
(
Y
)
−
H
(
X
,
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
互信息:I(X;Y)=H(X)+H(Y)-H(X,Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)
互信息:I(X;Y)=H(X)+H(Y)−H(X,Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
如果X与Y独立,则互信息为0
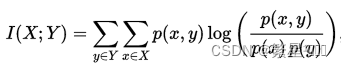
参考文章:信息论(3)——联合熵,条件熵,熵的性质

简单理解条件熵:条件越多,事件的不确定性就越小,熵就越小
概率模型
采用的是均值为0,方差为 σ \sigma σ的高斯概率模型
高斯概率模型公式(正态分布模型):
p ( x ) = 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 p(x) =\frac{1}{\sqrt{2{\pi}{\sigma}^2}} e^{-\frac{(x-{\mu})^2}{2{\sigma}^2}} p(x)=2πσ21e−2σ2(x−μ)2
其中, x x x 是随机变量的取值, μ \mu μ 是均值(期望), σ \sigma σ 是标准差。公式中的 e e e 是自然对数的底数
深度学习熵编码演进
1. 2017 Factorized Prior(独立熵编码)
[1] Ballé, Johannes, et al. “End-to-end optimized image compression.” in ICLR. 2017.
下式为估计的平均码长。
只有概率估计的越准,才能逼近平均码长的理论下限值——
y
^
\hat{y}
y^的独立熵

2. 2018 Scale Hyper Prior(条件熵编码)
[2] Ballé, Johannes, et al. “Variational image compression with a scale hyperprior.” in ICLR. 2018.
这篇工作其实是利用 y ^ \hat{y} y^的条件概率来编码 y ^ \hat{y} y^,条件概率进一步挖掘了 y ^ \hat{y} y^空间相关性,此时平均码长的理论下限值是—— y ^ \hat{y} y^的条件熵
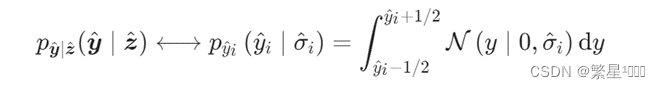
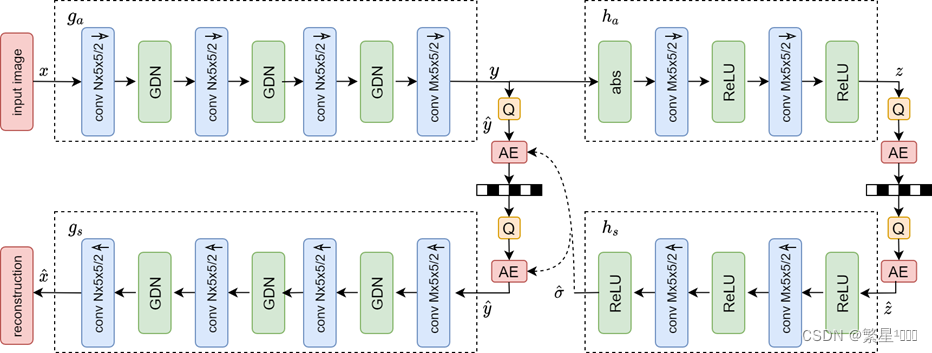
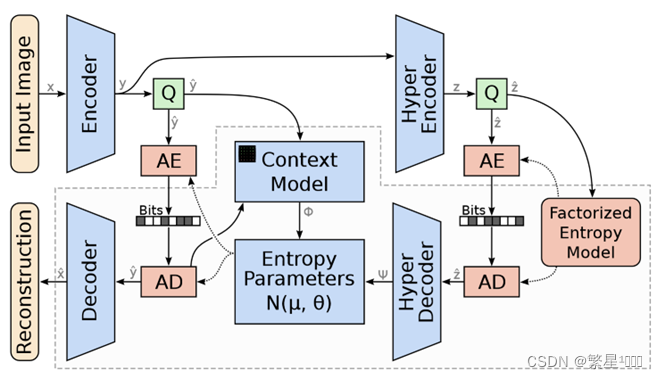
3. 2018 Joint Autoregressive Hierarchical Prior
[3] Minnen, David, et al. “Joint autoregressive and hierarchical priors for learned image compression.” in NeruIPS. 2018.
-
Auto-encoder:学习量化的图像隐式特征,称为latent
-
概率估计模块:学习量化后的latent的概率模型用于熵编码
-
Context model(上下文模型):latent的上下文自回归模型。利用的是已解码的数据,当前解码字符之前的(<i)
-
Hyper-network(超先验网络):学习有用的表征信息来修正上下文预测
-
Entropy Parameters network(熵参数网络):结合上面两个模块的信息来生成条件高斯熵模型的参数(均值+方差)
-
理解context model中的两根线
-
从Q出来的线:编码时用的 y ^ < i \hat{y}_{<i} y^<i
-
从AD出来的线:解码时用的 y ^ < i \hat{y}_{<i} y^<i

















 5093
5093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











