







文章目录
之前在R-数据科学(三 ):向量中已经介绍了字符型向量的操作,但是由于基础函数使用方法不一致,一段时间不用就容易会忘记,那么有没有一个包既可以包含这些基础函数,并且操作更简单呢?当然有了,这就是stringr包,它是一个强大的字符串处理包,内含多个函数,操作简单,堪称字符串处理神器,结合正则表达式,可以满足大多数复杂的字符串处理需求。由于《R数据科学》对这个包的介绍十分全面,所以就在我自己理解的基础上将内容照搬过来了。
1 字符串基础
str_length()函数返回字符串长度
library(stringr)
vec = c('Biobio_Baper','Learn_Programmer','bio_info','R_studio')
str_length(vec)
## [1] 12 16 8 8
str_sub()函数取字符串子串
str_sub(vec,1,4)
## [1] "Biob" "Lear" "bio_" "R_st"
str_split()函数指定字符切割字符串
str_split(vec, '_',simplify = T) # 若“simplify = F”,则生成列表
## [,1] [,2]
## [1,] "Biobio" "Baper"
## [2,] "Learn" "Programmer"
## [3,] "bio" "info"
## [4,] "R" "studio"
str_c()函数合并字符串
str_c(rep('paste',4),vec,sep = ':')
## [1] "paste:Biobio_Baper" "paste:Learn_Programmer"
## [3] "paste:bio_info" "paste:R_studio"
str_c(1:10,collapse = '')
## [1] "12345678910"
str_to_lower()函数将字符串全都变为小写
str_to_lower(vec)
## [1] "biobio_baper" "learn_programmer" "bio_info"
## [4] "r_studio"
str_to_upper()函数将字符串全都变为大写
str_to_upper(vec)
## [1] "BIOBIO_BAPER" "LEARN_PROGRAMMER" "BIO_INFO"
## [4] "R_STUDIO"
2 正则表达式实现模式匹配
2.1 基础匹配
精确匹配字符串
library(stringr)
x <- c("apple", "banana", "pear")
str_view(x, "an")

另一个更复杂一些的模式是使用字符.,它可以匹配任意字符(除了换行符\)
str_view(x, ".a.")

若想匹配字符.和字符\本身,那么在正则表达式中首先需要用转义符\将二者转义为\.,\\,又因为正则表达式是使用字符串来表达的,而字符\在字符串中也表示转义,所在在正则表达式的字符串形式中,凡是遇到字符\,就必须对字符\转义,所以两个正则表达式的字符串形式为\\.和\\\\。
dot <- "\\."
writeLines(dot)
## \.
str_view(c("abc", "a.c", "bef"), "a\\.c")

x <- "a\\b"
writeLines(x)
## a\b
str_view(x, "\\\\")

2.2 锚点
默认情况下,正则表达式会匹配字符串的任意部分。有时我们需要在正则表达式中设置锚点,以便 R 从字符串的开头或末尾进行匹配。我们可以设置两种锚点:
^从字符串开头进行匹配$从字符串末尾进行匹配
x <- c("apple", "banana", "pear")
str_view(x, "^a")

str_view(x, "a$")

如果想要强制正则表达式匹配一个完整字符串,那么可以同时设置 ^ 和 $ 这两个锚点。
x <- c("apple pie", "apple", "apple cake")
str_view(x, "apple")

str_view(x, "^apple$")

2.3 字符类和字符选项
字符类
很多特殊模式可以匹配多个字符,如之前介绍的字符.可以匹配任意字符。除此之外,还有其他 4 种常用的字符类。
\d:匹配任意数字。\s:匹配任意空白字符(如空格、制表符和换行符)。[abc]:匹配 a、b 或 c。[^abc]:可以匹配除 a、b、c 外的任意字符。
x = c('ⅠA','ⅢB','ⅡA')
str_view(x,'^[ⅠⅡ]')

字符选项
字符选项创建多个可选的模式
str_view(c("grey", "gray"), "gr(a|e)y")

x = c('ⅠAing','ⅢBize','ⅡA')
str_view(x,'(ing|ize)$')

2.4 重复
正则表达式的另一项强大功能是,其可以控制一个模式能够匹配多少次:
-
?:0 次或 1 次。 -
+:1 次或多次。 -
*:0 次或多次。
x <- "MDCCCLXXXVIII"
str_view(x, "CC?")

str_view(x, "CC+")
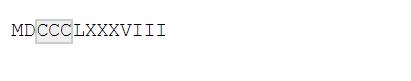
str_view(x, "CC*")
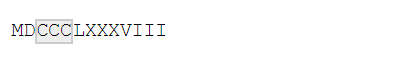
除了以上三种匹配模式,还可以精确设置匹配的次数:
{n}:匹配 n 次。{n,}:匹配 n 次或更多次。{n, m}:匹配 n 到 m 次。
str_view(x, "C{2}")

str_view(x, "C{2,}")
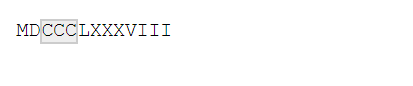
str_view(x, "C{2,3}")
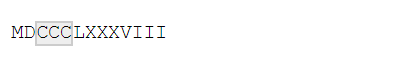
默认的匹配方式是“贪婪的”:正则表达式会匹配尽量长的字符串。通过在正则表达式后 面添加一个?,你可以将匹配方式更改为“懒惰的”,即匹配尽量短的字符串。
str_view(x, 'C{2,3}?')

str_view(x, 'C[LX]+?')
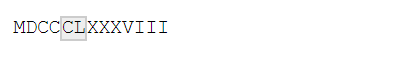
2.5 分组与回溯引用
以下的正则表达式可以找出名称中有重复的一对字母的所有水果。
str_view(fruit, "(..)\\1", match = TRUE)

3 工具
stringr包结合正则表达式可解决的常见问题:
- 确定与某种模式相匹配的字符串;
- 找出匹配的位置;
- 提取出匹配的内容;
- 使用新值替换匹配内容。
3.1 匹配检测
要想确定一个字符向量能否匹配一种模式,可以使用 str_detect()函数。它返回一个与输入向量具有同样长度的逻辑向量:
x <- c("apple", "banana", "pear")
str_detect(x, "e")
## [1] TRUE FALSE TRUE
str_detect() 函数结合dplyr包中filter()函数可以使数据框的筛选更加灵活。
str_detect() 函数的一种变体是 str_count(),后者不是简单地返回是或否,而是返回字符串中匹配的数量:
x <- c("apple", "banana", "pear")
str_count(x, "a")
## [1] 1 3 1
当然如果我们不仅想要确定一个字符向量能否匹配一种模式,还需要提取出来可以匹配到的字符串,可以直接使用str_subset()函数一步完成。
x <- c("apple", "banana", "pear")
str_subset(x, "e")
## [1] "apple" "pear"
3.2 提取匹配内容
如果想要直接取匹配的实际文本,我们可以使用str_extract()函数。
# 创建正则表达式
colors = c( "red", "orange", "yellow", "green", "blue", "purple")
color_match <- str_c(colors, collapse = "|")
color_match
## [1] "red|orange|yellow|green|blue|purple"
# 匹配检测、提取匹配到的字符串。
has_color = str_subset(sentences, color_match) # str_subset()
head(has_color)
## [1] "Glue the sheet to the dark blue background."
## [2] "Two blue fish swam in the tank."
## [3] "The colt reared and threw the tall rider."
## [4] "The wide road shimmered in the hot sun."
## [5] "See the cat glaring at the scared mouse."
## [6] "A wisp of cloud hung in the blue air."
# 提取匹配内容
matches = str_extract(has_color, color_match)
head(matches)
## [1] "blue" "blue" "red" "red" "red" "blue"
3.3 替换匹配内容
str_replace() 和str_replace_all()函数可以使用新字符串替换匹配内容,二者的区别是str_replace()函数只会替换第一次匹配到的内容,而str_replace_all()函数会替换到所有匹配到的内容。
x = 'a.a.a.a'
# 替换第一次匹配内容
str_replace(x,'\\.','-')
## [1] "a-a.a.a"
# 替换所有匹配内容
str_replace_all(x,'\\.','-')
## [1] "a-a-a-a"
3.4 定位
str_locate() 和 str_locate_all()函数可以给出每个匹配的开始位置和结束位置,然后可以结合str_sub()函数提取匹配内容。
x <- c("apple", "banana", "pear")
# 定位
str_locate(x,'(..)\\1')
## start end
## [1,] NA NA
## [2,] 2 5
## [3,] NA NA
# 根据位置提取匹配内容
all_sub = str_sub(x,str_locate(x,'(..)\\1'))
all_sub
## [1] NA "anan" NA
na_omit_sub = all_sub[!is.na(all_sub)]
na_omit_sub
## [1] "anan"
3.5 其他操作
之前介绍过dir() 函数可以列出一个目录下的所有文件和目录,此外dir() 函数的 patten参数可以是一个正则表达式,此时它只返回与这个模式相匹配的文件名。
dir(pattern = '^G')
[1] "GEO数据下载及预处理.r" "GSE31210" "GSE37745"
[4] "GSE50081"
4 正则表达式总结
| 正则表达式 | 作用 |
|---|---|
abc | 匹配字符abc |
. | 匹配除换行符\以外的任意字符 |
\ | 转义字符,将特殊字符转为字符串 |
\. | 匹配字符.本身 |
\\ | 匹配字符\本身 |
^ | 从字符串开头进行匹配 |
$ | 从字符串结尾进行匹配 |
\d | 匹配任意数字 |
\s | 匹配任意空白字符(如空格、制表符和换行符) |
[abc] | 匹配 a、b 或 c |
[^abc] | 匹配除 a、b、c 外的任意字符 |
? | 0 次或 1 次 |
+ | 1 次或多次 |
* | 0 次或多次 |
{n} | 匹配 n 次 |
{n,} | 匹配 n 次或更多次 |
{n, m} | 匹配 n 到 m 次 |
参考资料
R数据科学
本博客内容将同步更新到个人微信公众号:生信玩家。欢迎大家关注~~~
















 4007
4007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









