










集成学习介绍
文章目录
1 基本概念
1.1 定义
基本定义
集成学习(ensemble learning):通过构建并结合多个学习器来完成学习任务。
个体学习器:通过由一个现有的学习算法从训练数据产生,如决策树算法,BP神经网络算法。
弱学习器:通常指泛化性能略优于随机猜测的学习器,例如在二分类问题上精度略高于50%的分类器。
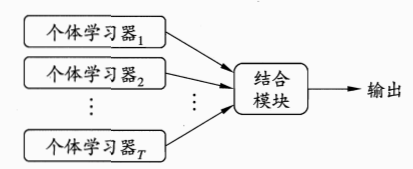
如图所示,集成学习的一般结构:先产生一组 “ 个体学习器”,再由某种策略将它们结合起来。常可以获得比单一学习器显著优越的泛化性能。
要获得好的集成,个体学习器应**“好而不同”**,如下图。hi表示不同的学习器。

事实上,个体学习器的“准确性”和“多样性”本身就存在冲突。集成学习的研究核心:如何产生并结合“好而不同”的个体学习器。
集成学习类别
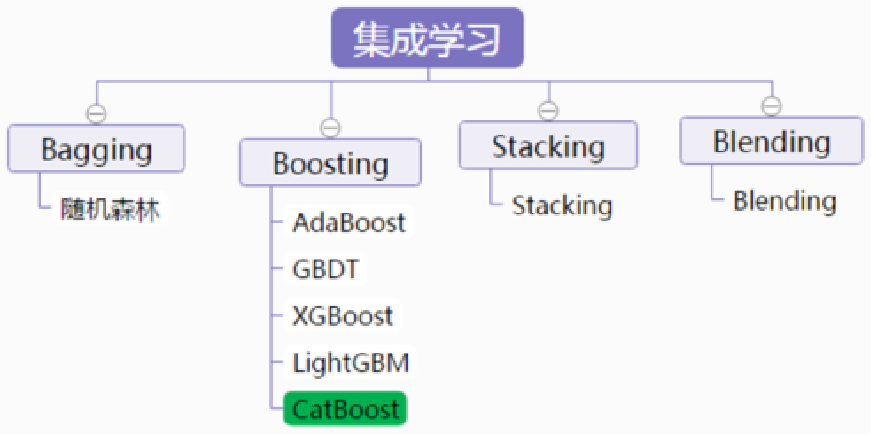
- Boosting类:个体学习器之间存在强依赖关系,必须串行生成的序列化方法。包括AdaBoost/GBDT/XGBoost等;
- Bagging类:个体学习器之间不存在强依赖关系,可同时生成的并行化方法,如RF随机森林等。
后两种 stacking和Blending,严格意义上来说,应该是模型融合。模型融合有许多方法,简单的有平均融合,加权融合,投票融合等方法;较为复杂的就是Blending和Stacking了 。
- stacking:是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
- Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
下面将主要介绍Bagging和Boosting。
参考链接
常用的模型集成方法介绍:bagging、boosting 、stacking
1.2 基学习器(CART)
介绍
机器学习中的集成学习的基学习器多为CART( Classification and Regression Tree ),即分类回归树,是一个二叉树。
- CART既能是分类树,又能是分类树;
- 当CART是分类树时,采用GINI值作为节点分裂的依据;当CART是回归树时,采用样本的最小方差作为节点分裂的依据;
- CART是一棵二叉树。
如下图,为二叉决策树。
公式介绍
无论是分类树还是回归树,CART都要选择使子节点的GINI值或者回归方差最小的属性作为分裂的方案 。下面这些公式可能不太好理解,下面会给出具体例子讲解。
- 分类
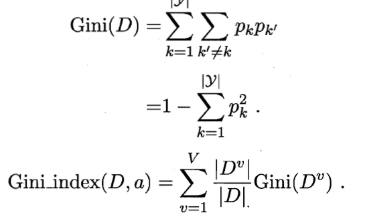
- 回归
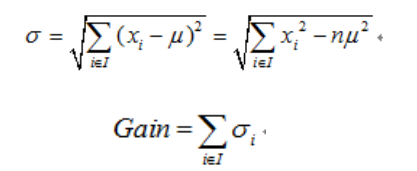
例子讲解
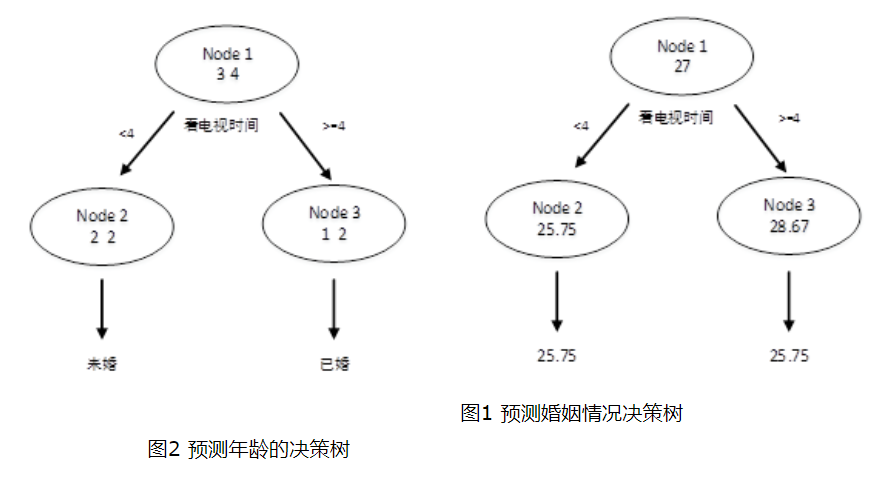
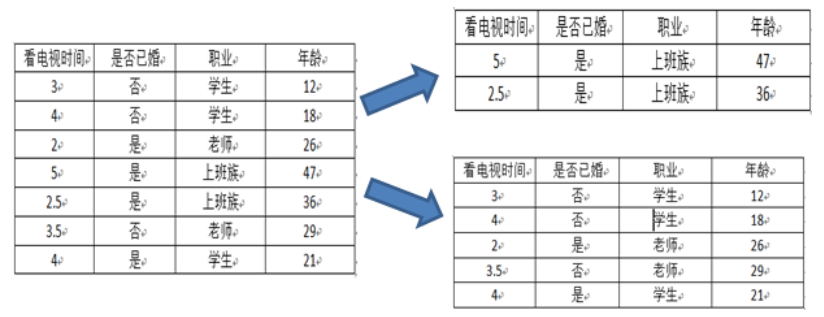
- 选择按照职业 {“学生”} ,{“老师”,“上班族”} 分为两个节点
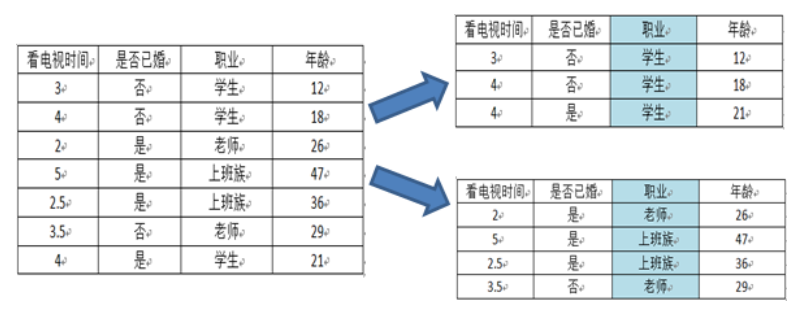
默认右上图为左节点,右下图为右节点。其中左节点的有3个样本,其中2个未婚,1个已婚。因此该左节点的Gini系数为:
G i n i ( 左 节 点 ) = 1 − ( 2 / 3 ) 2 − ( 1 / 3 ) 2 G i n i ( 右 节 点 ) = 1 − ( 3 / 4 ) 2 − ( 1 / 4 ) 2 Gini(左节点) = 1- (2/3)^2-(1/3)^2\\ Gini(右节点) = 1- (3/4)^2-(1/4)^2 Gini(左节点)=1−(2/3)2−(1/3)2Gini(右节点)=1−(3/4)2−(1/4)2
再根据Gini_index(Gain) 的计算公式可,左节点样本数目为3,总样本数为7,对应的 P(左) = 3/7。即有如下计算公式。下同。
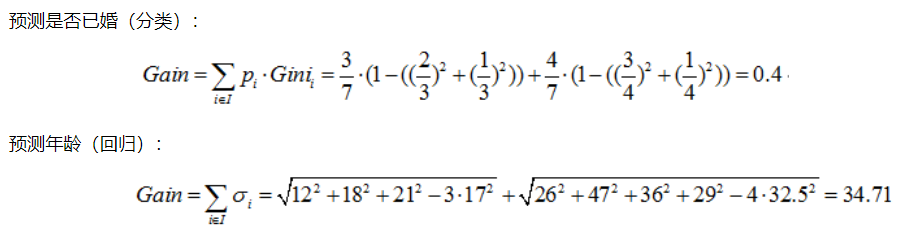
- 选择按照职业 {“老师”} ,{“学生”,“上班族”} 分为两个节点
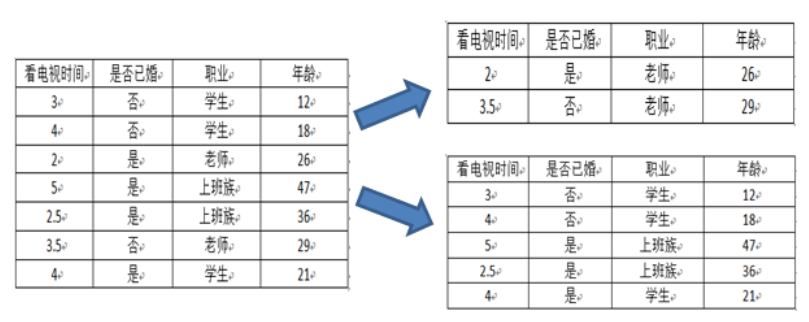
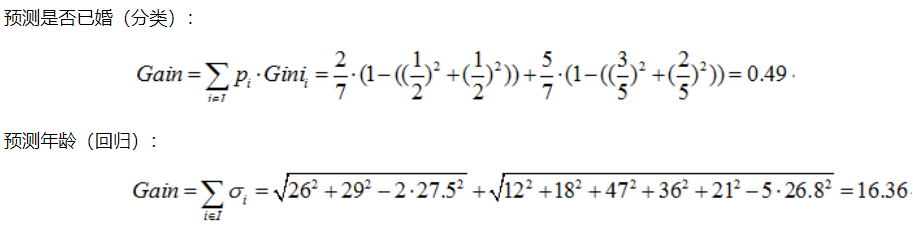
- 选择按照职业 {“上班族”} ,{“学生”,“老师”} 分为两个节点
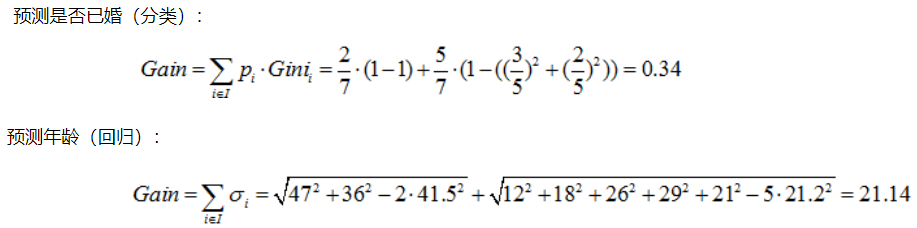
综上,如果想预测是否已婚,则选择{“上班族”}、{“学生”、“老师”}的划分方法,如果想预测年龄,则选择{“老师”}、{“学生”、“上班族”}的划分方法。
代码实践
from sklearn.tree import DecisionTreeRegressor
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
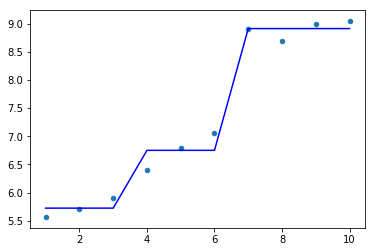
X = np.array(list(range(1, 11))).reshape(-1,1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05]).ravel()
#默认使用Gini为分类判据
model = DecisionTreeRegressor(max_depth=1,max_leaf_nodes=3)
model.fit(X,y)
plt.scatter(X, y, s=20)
plt.plot(X,model.predict(X),color='blue')
参考链接
周志华-《机器学习》第4章
1.3 偏差(bias)和方差(var)
对学习算法除了通过实验估计其泛化性能,人们往往还希望了解它“为什 么”具有这样的性能.“偏差-方差分解"(bias-variance decomposition)是解 释学习算法泛化性能的一种重要工具。
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力;
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
公式推导
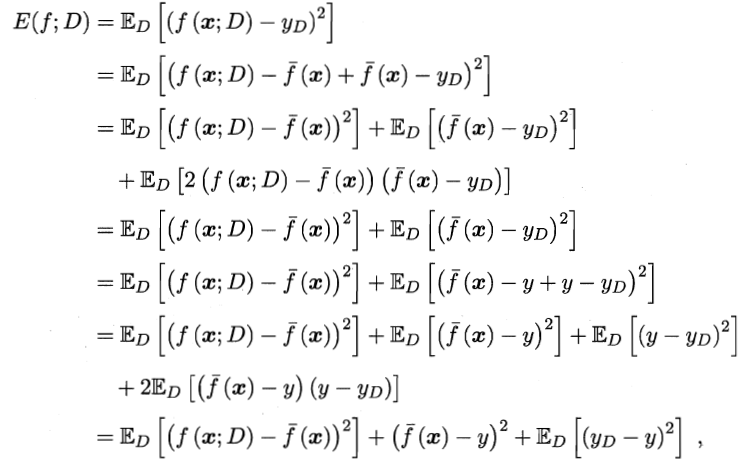
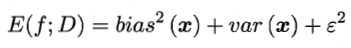
也就是说,泛化误差 = 偏差 + 方差 + 噪声
图解
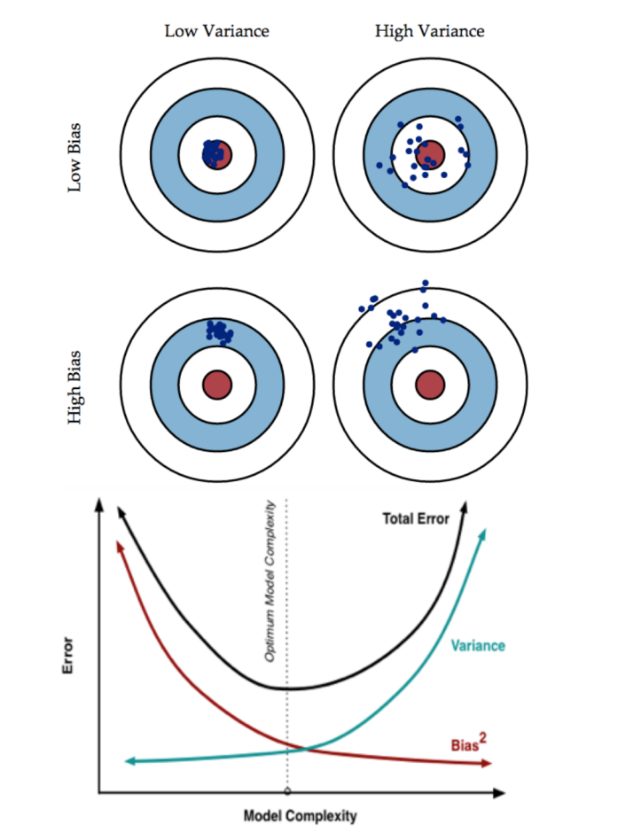
- 一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境。
- 给定学习任务,假定我们能控制学习算法 的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足 以使学习器产生显著变化,此时偏差主导了泛化错误率;
- 随着训练程度的加深, 学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差, 逐渐主导了泛化错误率;
- 在训练程度充足后,学习器的拟合能力已非常强,训练 数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全 局的特性被学习器学到了,则将发生过拟合。
高方差是模型过于复杂,即过拟合,记住太多细节(包括噪声),受离群点和噪声影响很大;高偏差是欠拟合,模型过于简单,模型什么都没有学到。
- Bagging是Bootstrap Aggregating 的简称,即再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的 方差(variance)。Bagging 比如Random Forest 这种先天并行的算法都有这个效果;
- Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 偏差(bias) 会不断降低。例子比如Adaptive Boosting.
参考链接
周志华-《机器学习》第2章
如何理解bagging是减少variance,而boosting是减少bias?
Understanding the Bias-Variance Tradeoff
机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
2 Boosting类
2.1 原理
Boosting是一族可将弱学习器提升为强学习器的算法。这族算法的工作机制类似。
- 先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注;
- 然后基于调整后的样本分布来训练下一个基学习器;
- 如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
下面将介绍几种较为知名的Boosting机器学习方法。
2.2 AdaBoost
AdaBoost ( Adaptive Boosting )具体原理如下图:
2.2.2 公式推导
- step1: 训练数据集
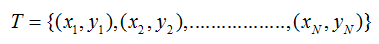
- step2: 初始化训练数据的权重
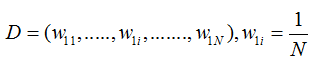
- step3: 计算第m个分类器的分类错误率
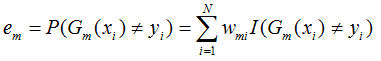
- step4: 计算得到第m个分类器的权重系数
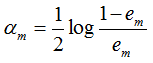
- step5: 计算第m+1个分类器的训练数据权重分布Wm+1
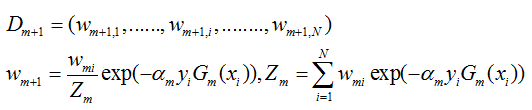
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
- step6: 计算基分类器的线性组合
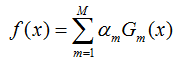
- step7: 最终的分类器
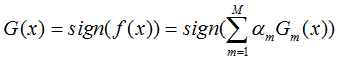
AdaBoost 本质就是,每次迭代更新样本分布,然后对新的分布下的样本学习一个弱分类器,和它对应的权重。更新样本分布的规则是:减小之前弱分类器分类效果较好的数据的概率,增大之前弱分类器分类效果较差的数据的概率。最终的分类器是弱分类器线性组合。
其模型是加法模型;损失函数为指数函数;学习算法为前向分步算法的二类分类学习方法 ,具有自适应性。
2.2.3 优点与不足
优点
- 很好的利用了弱分类器进行级联;
- 可以将不同的分类算法作为弱分类器;
- AdaBoost具有很高的精度;
- 相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
- AdaBoost的训练误差是以指数速率下降的;
- AdaBoost算法不需要事先知道下界γ,具有自适应性,它能适应弱分类器各自的训练误差率 ;
- 不容易发生过拟合。
不足
- AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定;
- 数据不平衡时,会导致分类精度下降。
- 训练比较耗时,每次重新选择当前分类器最好切分点。
- 执行效果依赖于弱分类器的选择。
- 对样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
应用
模式识别、计算机视觉领域,用于二分类和多分类场景。可同时用于回归和分类。
2.2.4 代码实践
集成在sklearn这个库中。
pip install scikit-learn #直接安装sklearn库
具体使用可以参考 sklearn 官方教程。下面给出一些展示个例展示。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
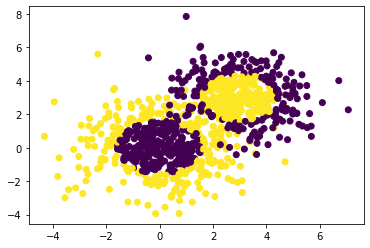
#生成二维正态分布,生成的数据分为两类,500个样本,2个样本特征,协方差系数为2
X1,y1=make_gaussian_quantiles(cov=2.0,n_samples=500,
n_features=2,n_classes=2,
random_state=1)
#生成二维正态分布,生成的数据分为两类,500个样本,2个样本特征,协方差系数为1.5
X2,y2=make_gaussian_quantiles(mean=(3,3),cov=1.5,
n_samples=400,n_features=2,
n_classes=2,random_state=1)
#将两组数据合为一组
X=np.concatenate((X1,X2))
y=np.concatenate((y1,-y2+1))
#绘画生成的数据点
plt.figure()
plt.scatter(X[:,0],X[:,1],marker='o',c=y)
plt.show()
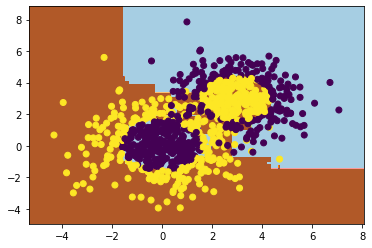
# 训练数据
clf=AdaBoostClassifier(DecisionTreeClassifier(
max_depth=2,min_samples_split=20,
min_samples_leaf=5),algorithm="SAMME",
n_estimators=200,learning_rate=0.8)
clf.fit(X,y)
#将训练结果绘画出来
plt.figure()
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
#训练模型的得分
print(clf.score(X,y))
#0.913333333333
2.2.5 参考链接
《机器学习》第8章 周志华
Adaboost入门教程——最通俗易懂的原理介绍(图文实例)
2.3 GBDT
原理介绍
GBDT是以决策树(CART)为基学习器的GB算法。
GBDT的核心是:每一棵树学习的是之前所有树结论和的残差。这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学习。
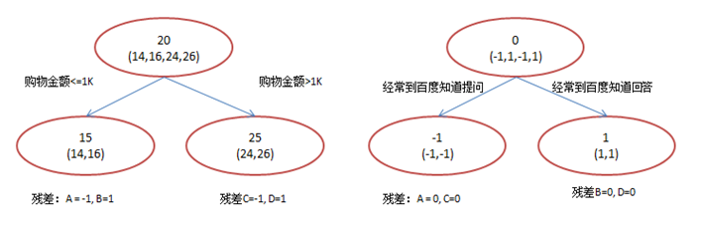
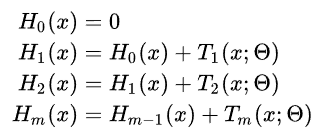
-
优点:它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
-
缺点:Boost是一个串行过程,不好并行化,而且计算复杂度高,同时不太适合高维稀疏特征。
详细使用请见 sklearn官方教程。

代码实践
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,max_depth=1, random_state=0).fit(X_train, y_train)
score = clf.score(X_test, y_test)
print('score:',score)
'''
output:
score: 0.913
'''
参考链接
2.4 XGBoost
2.4.1 原理
XGBoost(陈天奇,2014)是Exterme Gradient Boosting(极限梯度提升)的缩写,它是基于决策树的集成机器学习算法,它以梯度提升(Gradient Boost)为框架。XGBoost是由GBDT发展而来,同样是利用加法模型与前向分步算法实现学习的优化过程,但与GBDT是有区别的。主要区别包括以下几点:
- 目标函数:XGBoost的损失函数添加了正则化项,使用正则用以控制模型的复杂度,正则项里包含了树的叶子节点个数、每个叶子节点权重(叶结点的socre值)的平方和。
- 优化方法:GBDT在优化时只使用了一阶导数信息,XGBoost在优化时使用了一、二介导数信息。
- 缺失值处理:XBGoost对缺失值进行了处理,通过学习模型自动选择最优的缺失值默认切分方向。
- 防止过拟合: XGBoost除了增加了正则项来防止过拟合,还支持行列采样(样本采样和特征采样)的方式来防止过拟合。
- 结果:它可以在最短时间内用更少的计算资源得到更好的结果。
XGBoost被大量运用于竞赛中,比如Kaggle竞赛,在Kaggle2015年公布的29个获胜者中有17个使用了XGBoost,同样在KDDCup2015的竞赛中XGBoost也被大量使用。
2.4.2 XGBoost的基学习器
XGBoost的可以使用Regression Tree(CART)作为基学习器,也可以使用线性分类器作为基学习器。以CART作为基学习器时,其决策规则和决策树是一样的,但CART的每一个叶节点具有一个权重,也就是叶节点的得分或者说是叶节点的预测值。CART的示例如下图:
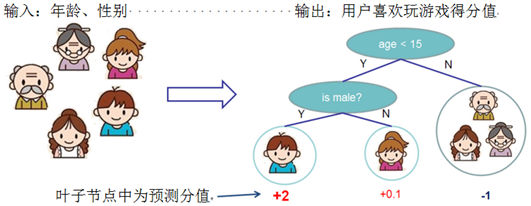
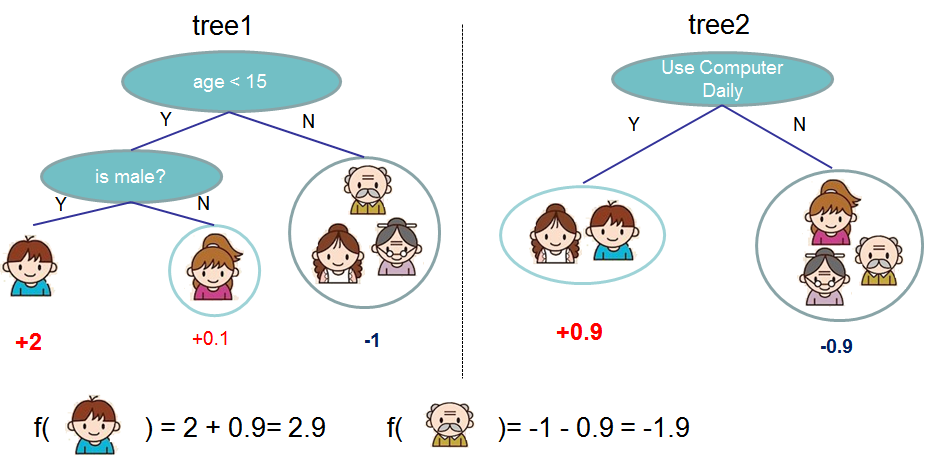
图中为两颗回归树(左右两个),其中树下方的输出值即为叶节点的权重(得分),当输出一个样本进行预测时,根据每个内部节点的决策条件进行划分节点,最终被划分到的叶节点的权重即为该样本的预测输出值。
2.4.3 优化过程
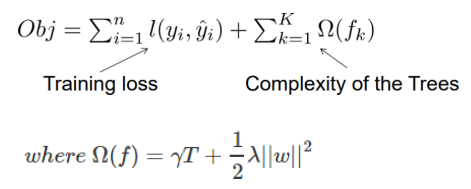
目标函数由 训练损失(模型预测值与真值的差异) + 树的复杂度约束 组成。是为了避免模型训练过程中,树的结构变得过于复杂,而在新的数据集上不具有泛化性。
step1:训练损失

将 训练损失部分为,只有ft(xi)是未知的,是我们要学习的残差,相比真值 yi 和 y(t-1) 为小量,因此可以将训练损失部分,泰勒展开到二阶。
step2:树的复杂度约束
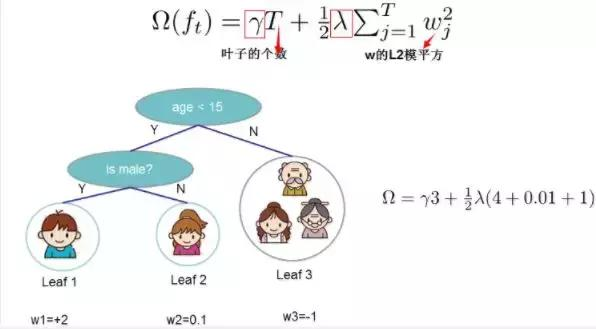
树的复杂度约束包括 叶子节点的个数,和每个叶子节点对应的输出值wi的L2模。
step3: 最终目标函数
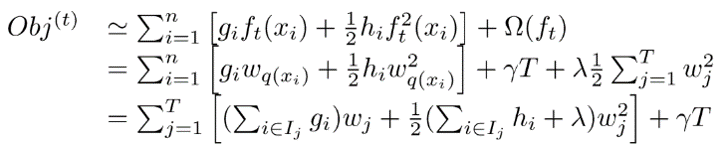
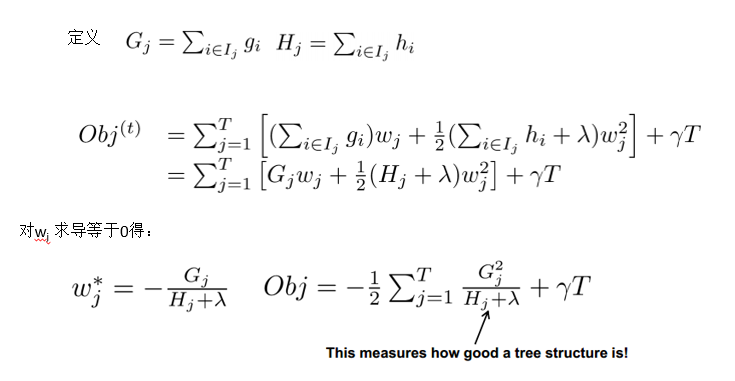
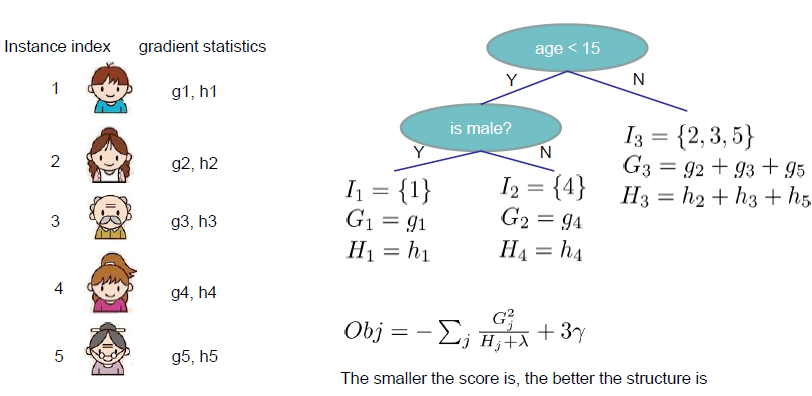
目标损失函数越小,表明该树结构越好。那怎么能使得该目标函数值足够小呢?下面一步就是寻找最优分裂点。
step4:寻找最优分裂点

怎么设计一颗结构漂亮(损失最小)的树呢,如上图所示:
- 遍历所有特征;
- 面对每一个特征,将样本按照该特征数值大小排序;
- 在该排序好的特征上,从左到右依次滑动分裂点,计算分裂点左右两边的损失,并比较与不分裂的整体损失的数值大小,λ为分裂惩罚系数(分裂节点使得整体损失减小的数值 如果不能抵偿 由于分裂使得树结构变深带来的过拟合风险λ,则不接受该在该分裂点进行节点分裂);
- 在所有特征中选择最合适的分裂点(损失最小)进行节点分裂;
- 依次在 分裂的节点中重复上述流程,继续分裂。直到满足不了Gain判据;
- 便可以找到 使得损失最小的 树结构。
2.4.3 其他优化方法及其优点
tricks设计
- 稀疏值处理
- 分块并行
- 缓存访问
- "核外"块计算
- 块压缩
- 块分区
- early-stop,学习率设置;
- 列、行采样
优点
- 正则化。 用于控制模型的复杂度,降低了模型的variance,使学习出来的模型更加简单,防止过拟合;
- 支持并行。 XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量;
- 灵活。支持用户自定义目标函数和评价函数, 前提是目标函数二阶可导;
- 缺失值处理。 对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向;
- 剪枝。 XGBoost先从顶到底建立所有可以建立的子树,再从底到顶反向进行剪枝。比起GBM,这样不容易陷入局部最优解。
- 内置交叉验证。 XGBoost允许在每一轮boosting迭代中使用交叉验证。因此,可以方便地获得最优boosting迭代次数。而GBM使用网格搜索,只能检测有限个值。
缺点
- 在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。
- 虽然使用了预排序方法,首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
2.4.4 代码实践
安装
pip install xgboost
具体可以查看官方文档安装教程,其中包括windows/linux/Mac的安装方法。
支持数据格式
- libsvm格式的文本数据
- Numpy的二维数组
- XGBoost的二进制的缓存文件
加载的数据存储在对象 DMatrix 中。
个例测试
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# read in the iris data
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565)
params = {
'booster': 'gbtree',
'objective': 'multi:softmax',
'num_class': 3,
'gamma': 0.1,
'max_depth': 6,
'lambda': 2,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
plst = params.items()
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 500
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 计算准确率
cnt1 = 0
cnt2 = 0
for i in range(len(y_test)):
if ans[i] == y_test[i]:
cnt1 += 1
else:
cnt2 += 1
print("Accuracy: %.2f %% " % (100 * cnt1 / (cnt1 + cnt2)))
# 显示重要特征
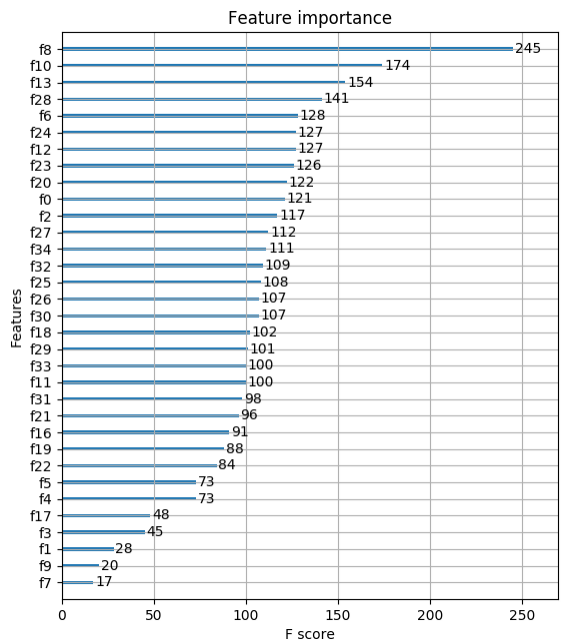
plot_importance(model)
plt.show()

xgboost参数及其实践详细教程见参考链接1和2.
2.4.5 参考链接
[1] 官方文档
[5] XGBoost使用教程
[6] xgboost原始论文
[7] xgboost作者讲座PPT
[8] 对xgboost的理解
[9] xgboost数学推导
[10] [机器学习–boosting家族之XGBoost算法
[11] 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost总结
2.5 LightGBM
2.5.1 原理
LightGBM (微软,2017)是一个梯度 boosting 框架,使用基于学习算法的决策树。它可以说是分布式的,高效的。
- 传统的boosting算法(如GBDT和XGBoost)已经有相当好的效率,但是在如今的大样本和高维度的环境下,传统的boosting似乎在效率和可扩展性上不能满足现在的需求了,主要的原因就是传统的boosting算法需要对每一个特征都要扫描所有的样本点来选择最好的切分点,这是非常的耗时。
- 为了解决这种在大样本高纬度数据的环境下耗时的问题,Lightgbm使用了如下几种解决办法:
- GOSS(Gradient-based One-Side Sampling, 基于梯度的单边采样),不是使用所用的样本点来计算梯度,而是对样本进行采样来计算梯度;
- EFB(Exclusive Feature Bundling, 互斥特征捆绑),这里不是使用所有的特征来进行扫描获得最佳的切分点,而是将某些特征进行捆绑在一起来降低特征的维度,使寻找最佳切分点的消耗减少。这样大大的降低的处理样本的时间复杂度,但在精度上,通过大量的实验证明,在某些数据集上使用Lightgbm并不损失精度,甚至有时还会提升精度。
- 它采用最优的leaf-wise策略分裂叶子节点,然而其它的提升算法分裂树一般采用的是depth-wise或者
level-wise而不是leaf-wise。因此,在LightGBM算法中,当增长到相同的叶子节点,leaf-wise算法比
level-wise算法减少更多的loss。因此导致更高的精度,而其他的任何已存在的提升算法都不能够达。
与此同时,它的速度也让人感到震惊,这就是该算法名字 Light 的原因。
2.5.2 优化与优点
优化
- 基于Histogram的决策树算法;
- 带深度限制的Leaf-wise的叶子生长策略
- 直方图做差加速
- 直接支持类别特征(Categorical Feature)
- Cache命中率优化
- 基于直方图的稀疏特征优化
- 多线程优化
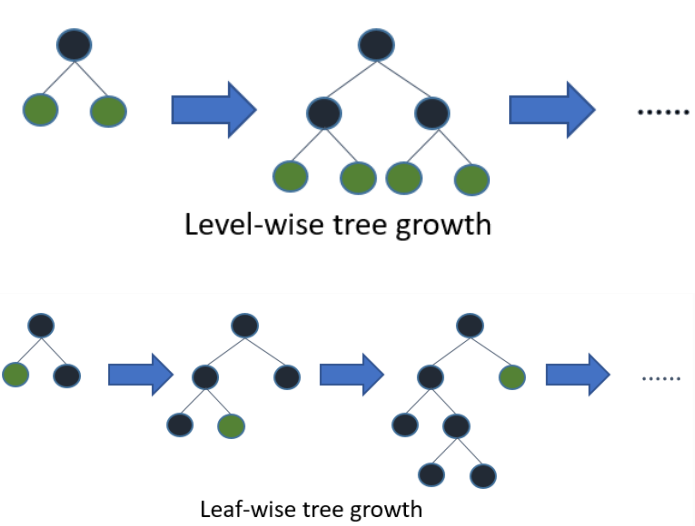
究竟什么是 leaf-wise,什么是level-wise呢?通俗解释一下:
-
XGBoost 和 LightGBM的基学习器都是CART二叉树,二叉树是每个父节点最多有两个子节点。
-
上面介绍过XGBoost 的树结构构造规律,即为 level-wise。这里再补充一下,如上图,根节点分裂后,得到两个子节点,依次对每个子节点都使用Gain标准,选取最合适的特征和划分点(如果某个子节点纯度为100%,则不需要进行分裂),进行分裂,以此类推。这样很容易得到一个 满二叉树。 际上很多叶子的分裂增益较低没必要进行分裂,带来了没必要的开销
-
leaf-wise的增长规则为:从跟节点分裂出两个子节点A和B后,选取A,B两个节点中 分裂增益最大的节点进行再次分裂为 两个子节点C,D,再选取C,D两个子节点中分裂增益最大的节点进行分裂。以此类推进行循环,直至满足一定树停止生长规则(如树深度max_depth)后,此时树停止生长。
-
因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise 可能会造成过拟合。
优点
因此相比前面提到过的系列的GB算法,LightGBM拥有如下优点:
- 速度和内存使用的优化
- 减少分割增益的计算量
- 通过直方图的相减来进行进一步的加速
- 减少内存的使用 减少并行学习的通信代价
- 稀疏优化
- 准确率的优化
- Leaf-wise (Best-first) 的决策树生长策略
- 类别特征值的最优分割
- 网络通信的优化
- 并行学习的优化
- 特征并行
- 数据并行
- 投票并行
- GPU 支持可处理大规模数据
比较
下面给出XGBoost和LightGBM的比较
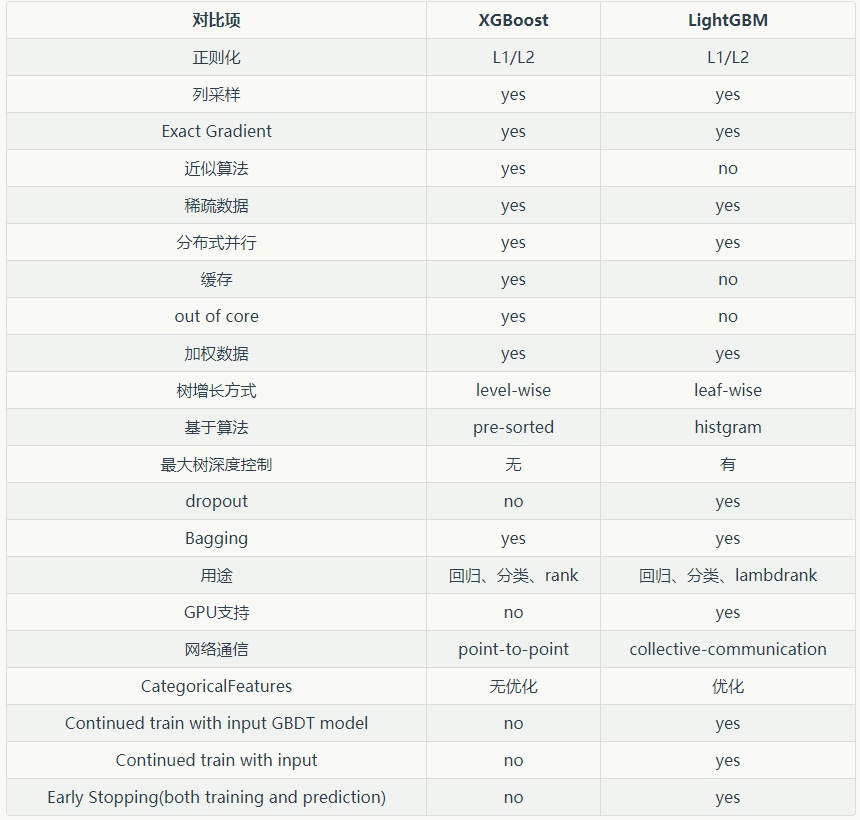
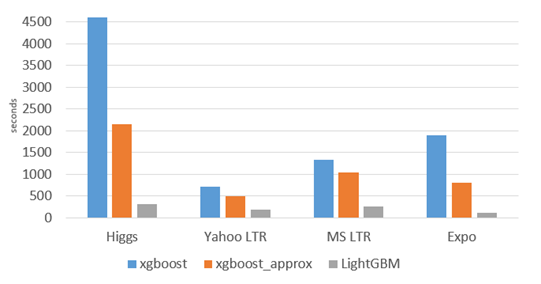
可以看到,在所有数据集上,LightGBM的运行时间上都远远低于XGBoost类,效率提高了一个数量级。
2.5.3 代码实践
安装
具体可见LightGBM安装指南。
#win下
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake -DCMAKE_GENERATOR_PLATFORM=x64 ..
cmake --build . --target ALL_BUILD --config Release
#linux下
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake ..
make -j
#MacOS下
brew install cmake
brew install gcc --without-multilib
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake ..
make -j
应用示例
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(feature_df, label_df, test_size=0.33, random_state=42)
#将数据读入
train_data = lgb.Dataset(data=x_train,label=y_train)
test_data = lgb.Dataset(data=x_test,label=y_test)
param = {'max_depth':10, 'objective':'binary','num_threads':8,
'learning_rate':0.1,'bagging':0.7,'feature_fraction':0.7,
'lambda_l1':0.1,'lambda_l2':0.2,'seed':123454}
param['metric'] = ['auc']
#训练模型
bst = lgb.train(param, train_data,num_boost_round=150,early_stopping_rounds=100, valid_sets=[test_data])
#保存模型
bst.save_model("lgb.model")
y_train_binary = bst.predict(x_train, num_iteration=bst.best_iteration) # type:np.numarray
y_pred_binary = bst.predict(x_test, num_iteration=bst.best_iteration) # type:np.numarray
参考链接
开源|LightGBM:三天内收获GitHub 1000+ 星
2.6 Catboost
2.6.1 原理
Catboost (Category and Boosting) () 是一种能够很好地处理类别型特征的梯度提升算法库。该库中的学习算法基于GPU实现,打分算法基于CPU实现。
-
它自动采用特殊的方式处理类别型特征(categorical features)。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。
-
catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合。
-
**克服梯度偏差。**CatBoost,和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点中计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度[8]或牛顿步长的近似值来计算。CatBoost第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。
-
**快速评分。**catboost的基模型采用的是对称树( symmetric or oblivious trees ),这种树是平衡的,不太容易过拟合。oblivious树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。CatBoost首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
-
基于GPU的实现快速学习。
- **密集的数值特征。**CatBoost利用oblivious决策树作为基础模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
- 类别型特征。 CatBoost使用完美哈希来存储类别特征的值,以减少内存使用。
- 多GPU支持。 CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算分类特征的统计数据。
2.6.2 优点
-
性能卓越:在性能方面可以匹敌任何先进的机器学习算法
-
鲁棒性/强健性:它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性
-
易于使用:提供与scikit集成的Python接口,以及R和命令行界面
-
实用:可以处理类别型、数值型特征
-
可扩展:支持自定义损失函数
上面的比较显示了测试数据的对数损失(log-loss)值,在CatBoost的大多数情况下,它是最低的。图中清楚地表明了CatBoost对调优和默认模型的性能都更好。

在运行速度上,CatBoost也是非常出色。
2.6.3 代码实践
具体了解和调参使用可以参考官网链接
# 用pip
pip install catboost
# 或者用conda
conda install -c conda-forge catboost
# 安装jupyter notebook中的交互组件,用于交互绘图
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
具体示例:
from catboost.datasets import titanic
import numpy as np
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier, Pool, cv
from sklearn.metrics import accuracy_score
# 导入数据
train_df, test_df = titanic()
# 查看缺测数据:
null_value_stats = train_df.isnull().sum(axis=0)
null_value_stats[null_value_stats != 0]
# 填充缺失值:
train_df.fillna(-999, inplace=True)
test_df.fillna(-999, inplace=True)
# 拆分features和label
X = train_df.drop('Survived', axis=1)
y = train_df.Survived
# train test split
X_train, X_validation, y_train, y_validation = train_test_split(X, y, train_size=0.75, random_state=42)
X_test = test_df
# indices of categorical features
categorical_features_indices = np.where(X.dtypes != np.float)[0]
model = CatBoostClassifier(
custom_metric=['Accuracy'],
random_seed=666,
logging_level='Silent'
)
# custom_metric <==> custom_loss
在model.fit中,设置Plot = True,还可以可视化训练过程
model = CatBoostClassifier(
custom_metric=['Accuracy'],
random_seed=666,
logging_level='Silent'
)
# custom_metric <==> custom_loss
model.fit(
X_train, y_train,
cat_features=categorical_features_indices,
eval_set=(X_validation, y_validation),
logging_level='Verbose', # you can comment this for no text output
plot=True
);
# OUTPUT:
"""
...
...
...
bestTest = 0.3792389991
bestIteration = 342
Shrink model to first 343 iterations.
"""
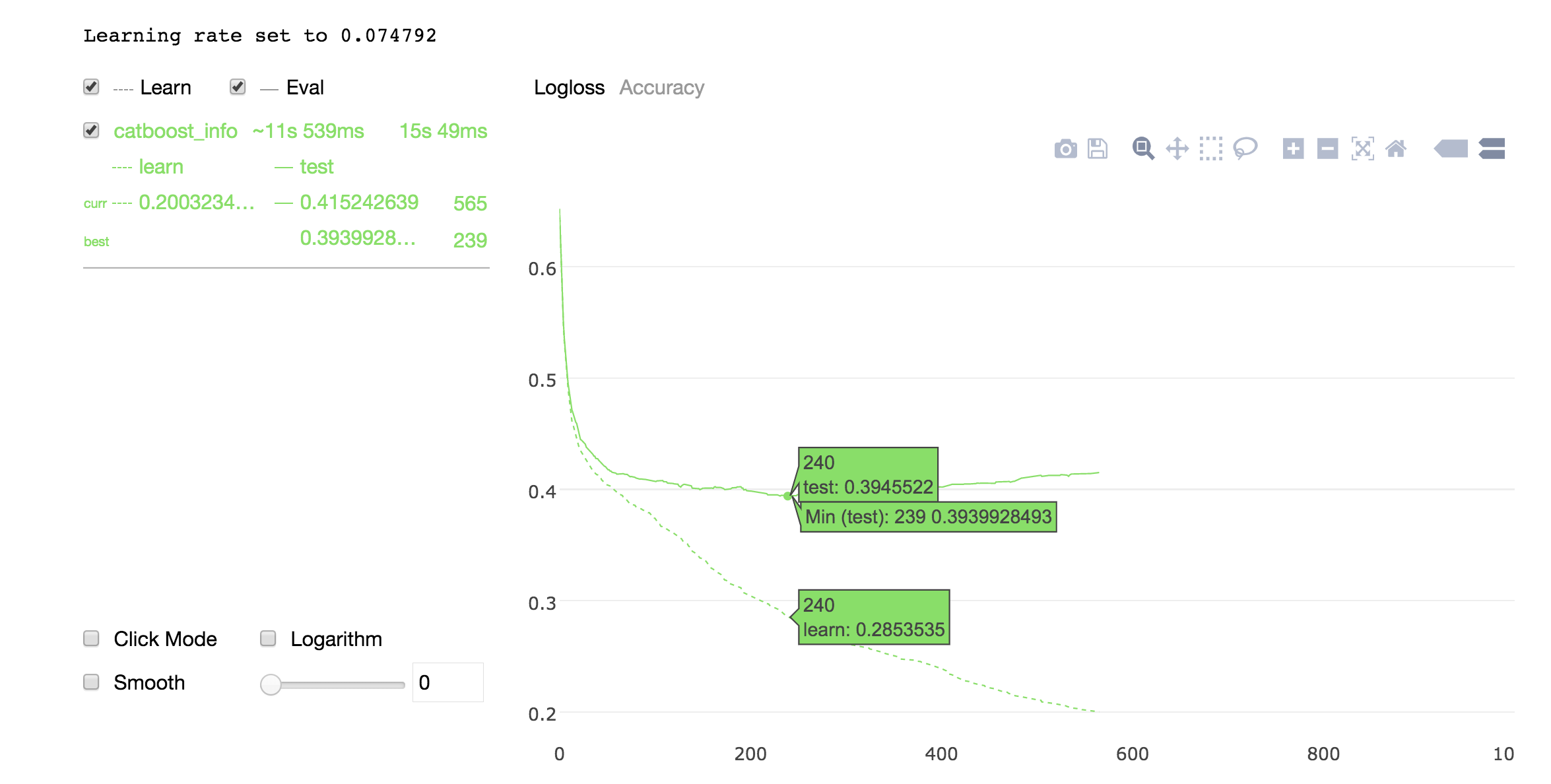
2.6.4 参考链接
3 Bagging类别
3.1 Bagging介绍
关键词
自主采样 样本扰动 降低方差
基本流程
Bagging [Breiman, 1996a]是并行式集成学习方法最著名的代表。
- 从名字即可看出,它直接基于自助釆样(bootstrap sampling)。
- 给定包含m个样本的数据集,我们先随机取出一个样本放入釆样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中。
- 这样,经过m次随机采样操作,我们得到含m个样本的釆样集。
- 初始训练集中有的样本在采样集里多次出现,有的则从未出现,这样初始训练集中约有63.2%的样本出现在采样集中。
- 照这样,我们可采样出T个含m个训练样本的釆样集,然后基于每个采样集训练出一个基学习器。
- 再将这些基学习器进行结合。

结合策略
在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法.若分类预测时出现两个类收到同样票数的情形,则最简单的做法是随机选择一个,也可进一步考察学习器投票的置信度来确定最终胜者。
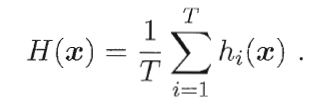
- 加权平均法
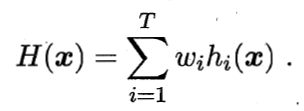
一般在而言,在个体学习器性能相差较大时,宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。

- 相对多数投票法
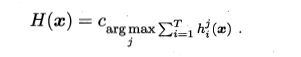
即预测为得票最多的标记,若同时有多个标记获得高票,则从中随机选取一个。
- 加权投票法
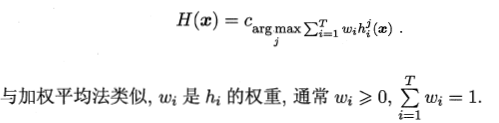
代码实践
from sklearn.metrics import accuracy_score
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
#选择决策树作为基学习器
bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, n_jobs=-1 )
#训练模型
bag_clf.fit( X_train, y_train )
#预测并输出得分
y_pred = bag_clf.predict(X_test)
pred_score = accuracy_score( y_pred, y_test )
print( pred_score )
具体参数和原理介绍参考sklearn官网链接
参考链接
周志华 《机器学习》第8章
常用的模型集成方法介绍:bagging、boosting 、stacking
3.2 Bagging扩展变体—随机森林
关键词
样本扰动 属性扰动 决策树集成 泛化能力强
基本介绍
随机森林(Random Forest,简称 RF) 是 Bagging 的一个扩展变体。RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
- 具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;
- 在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分;
- 一般情况下,推荐值k = log2d
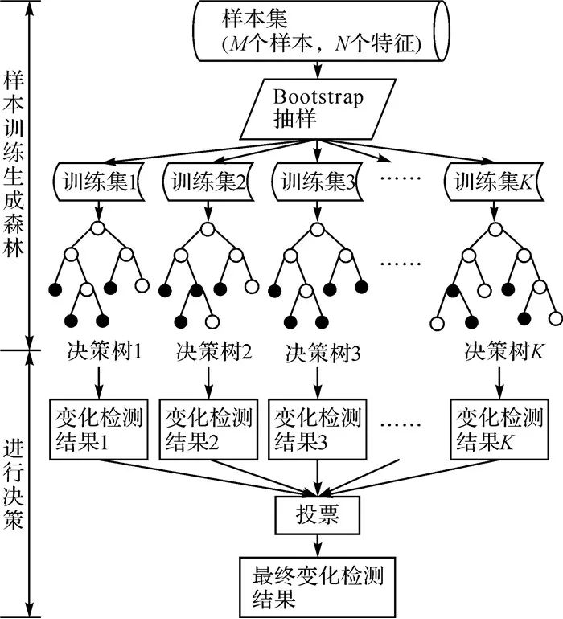
优点与不足
- 随机森林简单、容易实现、计算开销小,速度快(能并行),泛化能力强;
- 在某些噪音较大的分类或回归问题上会过拟和 ;
与Bagging比较
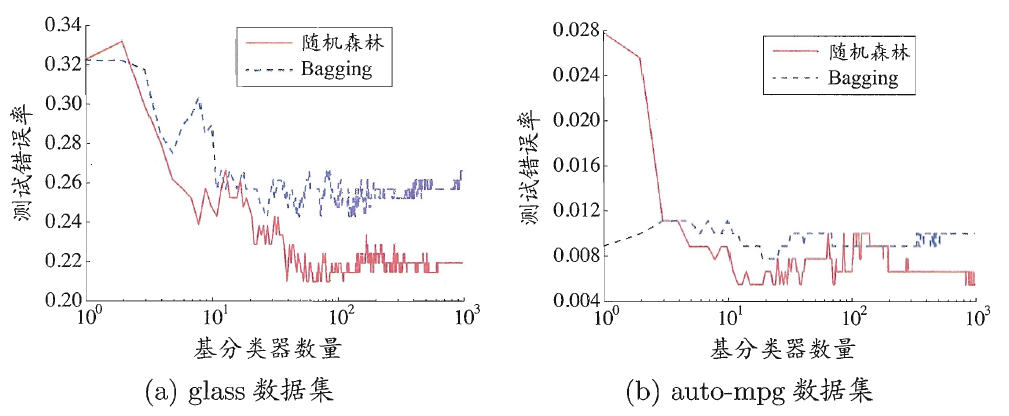
由图可知,在基分类器较少时,Bagging错误率较低(由于使用全部属性进行节点的分裂判断),而在基分类器数量较多时(>10个),随机森林错误率显著低于Bagging。
代码实践
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_blobs(n_samples=10000, n_features=10, centers=100,random_state=0)
#使用决策树
clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
print('DecisionTreeClassifier scores mean:',scores.mean())
#使用随机森林;随机选择 k个属性进行树的划分;
clf = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
print('RandomForestClassifier scores mean:',scores.mean())
#使用随机森林变种ExtraTreesClassifier,也是Bagging集成方法;会随机的选择一个特征值/属性来划分决策树。
clf = ExtraTreesClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
print('ExtraTreeClassifier scores mean:',scores.mean())
'''
output:
DecisionTreeClassifier scores mean: 0.982300000000000
RandomForestClassifier scores mean: 0.9997
ExtraTreeClassifier scores mean: 1.0
'''
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_blobs(n_samples=10000, n_features=10, centers=100,random_state=0)
#使用决策树
clf = DecisionTreeClassifier(max_depth=None, min_samples_split=2,random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
print('DecisionTreeClassifier scores mean:',scores.mean())
#使用随机森林;随机选择 k个属性进行树的划分;
clf = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
print('RandomForestClassifier scores mean:',scores.mean())
'''
DecisionTreeClassifier scores mean: 0.982300000000000
RandomForestClassifier scores mean: 0.9997
'''
具体使用请参考sklearn官网。
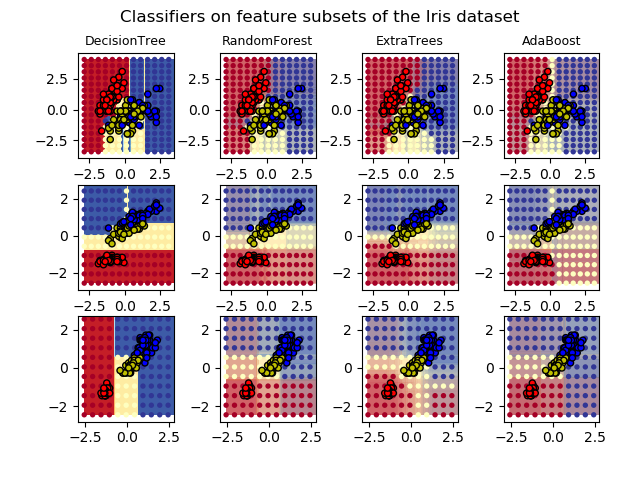
下面给出了决策树、随机森林、极端树和AdaBoost等方法在 鸢尾花数据上的分类结果,可以清楚看到,合成方法分类效果显著高于单个基学习器,分类边界较为平滑,其中又以随机森林效果为最优。
参考链接
周志华 《机器学习》第8章
4 总结
- Bagging类中,随机森林最为出色;
- Boosting类中,XGBoost和LightGBM都能满足一般要求,Catboost速度和效果更佳,强烈推荐。
- 除了面向具体任务进行分类或者回归,这些集成类方法都能给出 feature_importance,用户可以很清晰看到哪些特征最为重要,方便解释。
感谢前人的工作和总结分享,这里只是一个简单的拼凑。如果有更深一步的需求,可以多浏览官方文档。以上!















 5910
5910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









