






一、数据处理
1.1 数据格式说明
数据集分为10类,每一类下有10000张手绘图像数据(28*28大小),每类数据存放在一个.npy文件中。
.npy文件是NumPy库中用于存储多维数组数据的文件格式。NumPy是Python中用于科学计算的强大库,提供了高效的数组操作和数值计算功能。
它以二进制格式保存,可以保存多维数组数据,包括整数、浮点数和其他数据类型。.npy文件保存了数组的维度、数据类型和实际的数组数据。可以使用numpy.save()函数将数组保存为.npy文件,使用numpy.load()函数从.npy文件加载数组数据。
# 查看数据
path = "data/cat/cat.npy"
data_all = np.load(path) # 所有数据
data = data_all[i, :] # i为第几个数据
data = data.reshape(28, 28) # 将数据转为(28,28)维度
img = Image.fromarray(data) # 转为图片
img.show()

1.2 Dataset类
在PyTorch中,Dataset类是一个抽象类,用于表示数据集的抽象接口。它提供了一种统一的方式来访问和操作数据,可以用于训练、验证和测试深度学习模型。通过继承它可以创建自定义的数据集类。自定义的数据集类需要实现两个主要的方法:__len__()和__getitem__():
__len__()方法返回数据集的长度,即数据集中样本的数量。__getitem__()方法根据给定的索引返回对应索引的数据样本。它通常会在该方法中读取数据、进行预处理和返回数据样本及其对应的标签等信息。
# 数据读取,继承dataset类
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.utils.data import Dataset, ConcatDataset
from torchvision import transforms
# label为0-10,分别代表了下列标签:
label_names=['ambulance','apple','bear','bicycle','bird','bus','cat','foot','owl','pig']
# 数据转换器
data_transforms = transforms.Compose([
transforms.ToTensor(),
# 单通道归一化
transforms.Normalize((0.5,),(0.5,))])
# dataset类,方便datasetloader读取并输入网络中
class MyDataset(Dataset):
def __init__(self, label_index, transform = data_transforms):
path = "data/quick_draw_data/"+label_names[label_index]+"/"+label_names[label_index]+".npy"
self.data = np.load(path)
self.labels = [label_index]*len(self.data)
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data = self.data[idx]
image = Image.fromarray(data.reshape(28,28)) #将数据转为(28,28)维度
image = self.transform(image)
label = self.labels[idx]
return image, label
# 批量读取数据并整合为一个数据集
datasets = [MyDataset(label_index) for label_index in range(10)]
combined_dataset = ConcatDataset(datasets) # 整的数据集
由于我有10个.npy文件,故需要将数据集进行整合,如何划分为训练集、验证集和测试集:
# 数据划分,得到train_set, val_set, test_set
from torch.utils.data import random_split
lengths = [int(len(combined_dataset)*0.6), int(len(combined_dataset)*0.3), int(len(combined_dataset)*0.1)]
train_set, val_set, test_set = random_split(combined_dataset, lengths)
1.3 DataLoader
torch.utils.data.DataLoader是PyTorch中的一个数据加载器,用于批量加载数据并提供数据的迭代器。它是在训练深度学习模型时用于数据输入的常用工具之一。
DataLoader接受一个Dataset对象作为输入,并根据指定的批次大小batch_size、是否随机打乱数据shuffle等参数,将数据划分为小批量进行加载。每个小批量数据可以被用于模型的训练、验证或测试。
二、网络构建
2.1 网络结构:
# 构建CNN作为10-分类模型
from torch import nn
from torch.nn import Sequential, Conv2d, ReLU, MaxPool2d, Linear
class Net(nn.Module):
def __init__(self,num_classes=10):
super(Net, self).__init__()
self.conv1 = Sequential(
Conv2d(1, 10, kernel_size=5),
MaxPool2d(2),
ReLU()
)
self.conv2 = Sequential(
Conv2d(10, 20, kernel_size=5),
MaxPool2d(2),
ReLU()
)
self.fc = Linear(320, num_classes)
# 前向过程
def forward(self,x):
batch_size = x.size(0)
x = self.conv1(x)
x = self.conv2(x)
x = x.view(batch_size, -1) # Flatten
x = self.fc(x)
return x
2.2 训练方法
# 训练模型(单次,epoch_num为当前批次)
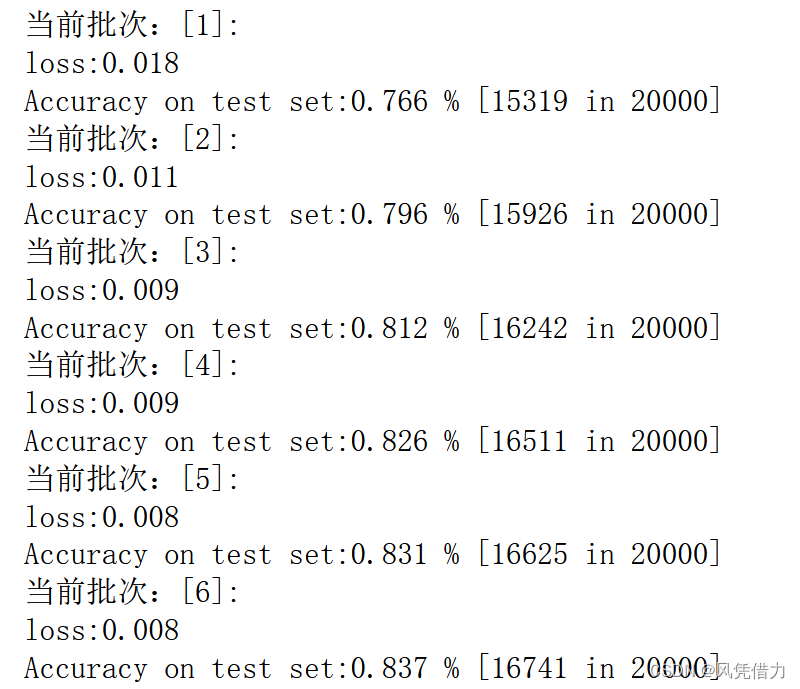
def train(epoch_num):
print("当前批次:[%d]:" % (epoch_num+1))
running_loss = 0.0
loss_sum = 0.0
for j,(batch_data,batch_label) in enumerate(train_loader):
batch_data,batch_label=batch_data.to(device),batch_label.to(device)
optimizer.zero_grad()
output = model(batch_data)
loss = loss_func(output, batch_label)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 每1000次打印一次loss
if (j+1) % 1000 == 0:
print('loss:%.3f' % (running_loss / (1000*64))) # batch——size = 64
loss_sum += running_loss
running_loss = 0.0
torch.save(model, "models/model_{}.pth".format(epoch_num))
return loss_sum/len(train_set)
# 测试模型
def test():
correct=0
total=0
with torch.no_grad():
for batch_data,batch_label in test_loader:
batch_data,batch_label=batch_data.to(device),batch_label.to(device)
output = model(batch_data)
_,predicted=torch.max(output.data,dim=1)
total+=batch_label.size(0)
correct+=(predicted==batch_label).sum().item()
print('Accuracy on test set:%.3f %% [%d in %d]' %(correct/total,correct,total))
return correct/total
2.3 模型训练
from torch import optim
from torch.utils.data import DataLoader
model = Net() # 创建模型
device = torch.device("cpu")
model.to(device)
batch_size = 64 # 批量训练大小
epoch_num = 10
learn_rate = 0.01
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learn_rate, momentum=0.5)
# 数据加载器
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set,batch_size, shuffle=True)
loss_set = []
acc_set = []
for epoch in range(10):
loss = train(epoch)
acc = test()
loss_set.append(loss)
acc_set.append(acc)
2.4 验证
# 验证模型
label_names=['ambulance','apple','bear','bicycle','bird','bus','cat','foot','owl','pig']
val_loader = DataLoader(val_set,10, shuffle=True)
# 数据均为十个一组
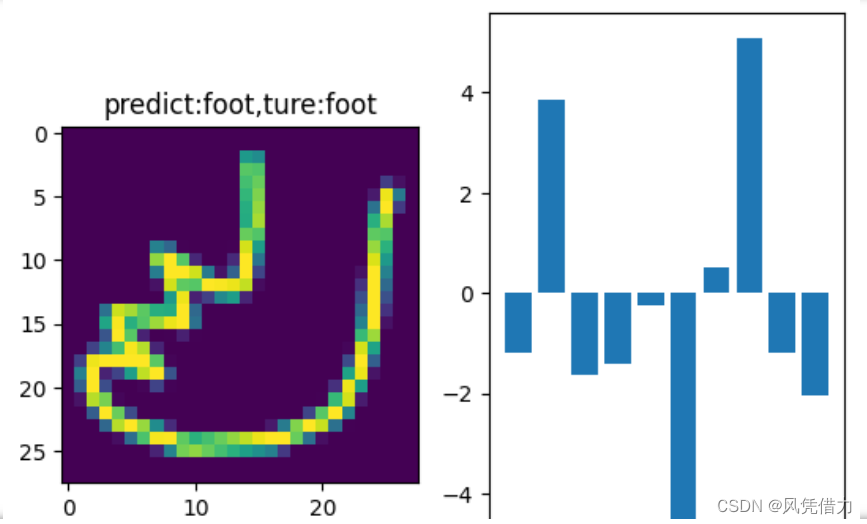
def result_show(data,label,prediction):
for i in range(10):
plt.figure()
plt.subplot(1,2,1)
img = data[i].reshape(28,28)
_,index = torch.max(prediction[i].data,dim=0)
# print(index.data)
plt.title("predict:{},ture:{}".format(label_names[index],label_names[label[i]]))
plt.imshow(img)
plt.subplot(1,2,2)
plt.bar(range(len(prediction[i].data)), prediction[i].data)
plt.show()
for i,(data,label) in enumerate(val_loader):
if (i == 2):
break
prediction = model(data)
result_show(data,label,prediction)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









