







 本文深入探讨了机器学习流程,强调了预处理、特征工程和算法选择的重要性。特征工程包括数值型和类别型数据的处理,如归一化、标准化和one-hot编码。此外,介绍了模型调参、交叉验证、评估指标(如精确率、召回率和AUC)以及集成学习方法如Boosting和Bagging。同时,讨论了常见的机器学习模型,如KNN、决策树和随机森林,以及它们的优缺点。最后,提到了防止过拟合和欠拟合的策略,如正则化。
本文深入探讨了机器学习流程,强调了预处理、特征工程和算法选择的重要性。特征工程包括数值型和类别型数据的处理,如归一化、标准化和one-hot编码。此外,介绍了模型调参、交叉验证、评估指标(如精确率、召回率和AUC)以及集成学习方法如Boosting和Bagging。同时,讨论了常见的机器学习模型,如KNN、决策树和随机森林,以及它们的优缺点。最后,提到了防止过拟合和欠拟合的策略,如正则化。
- 机器学习流程:
预处理->特征工程->机器学习算法(选择合适的算法)->评估
强化学习:用人工智能去调参
数据也是一种财富 - 离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所
有这些数据全部都是整数,而且不能再细分,也不能进一步提高他
们的精确度。 - 连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续
的,如,长度、时间、质量值等,这类数据通常是非整数,含有小数
部分。 - 注:只要记住一点,离散型是区间内不可分,连续型是区间内可分
- 人工智能内部就是高阶函数,输入的数据必须是数值(离散或连续),不能输入字符串
- 图片是一大推浮点数,像素点(像素值0-255),黑白图片可以看成二维数组,彩色三维(RGB)
- 数据的结构组成

- 特征工程是什么?
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了模型对未知数据预测的准确性 - 预测问题分为两大类?、
- 分类 :预测的是一个类别
- 回归:预测的是概率,值
- 调参:
- 参数:模型自动训练的参数
- 超参数:自己调的参数
- 特征处理
- 数值型数据:标准缩放.1、归一化 2、标准化 3、缺失值
- 类别型数据:one-hot编码
- 时间类型:时间的切分
- 归一化

mx和mi可以为1和-1
- 缺点:容易受极值影响。在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
- 好处:容易更快地通过梯度下降找 到最优解
-
标准化


-
结合归一化来谈标准化
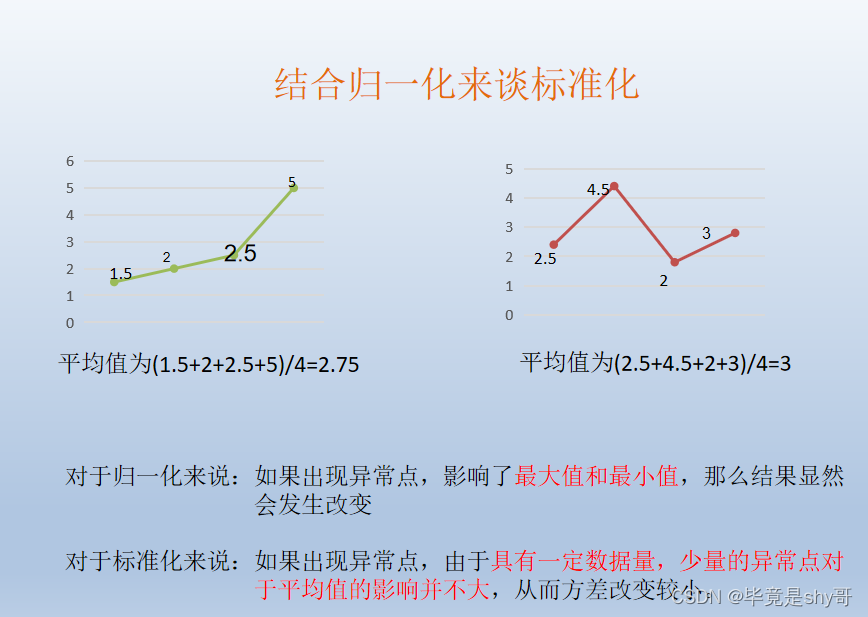
-
如何处理数据中的缺失值?

-
特征选择原因

-
特征选择是什么

方差阈值第一个,删除低方差保留高方差,就是要保留不同的特征

-
fit_trasform()
fit():计算待标准化数据的均值和方差等参数。
transform()的功能是对数据进行标准化。是将数据进行转换,比如数据的归一化和标准化,将测试数据按照训练数据同样的模型进行转换,得到特征向量。
fit_transform()的功能就是对数据先进行拟合处理,然后再将其进行标准化 -
PCA(主成分分析)是什么

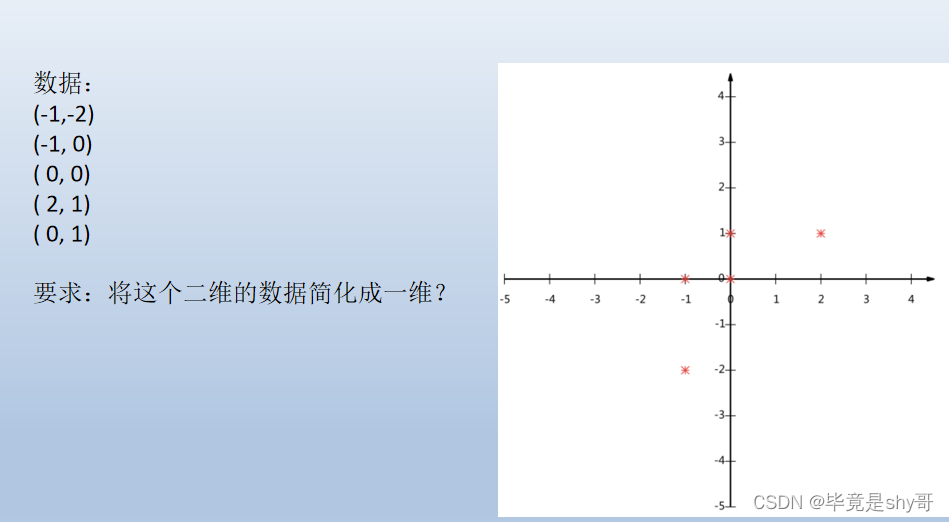
- 点到先的垂直距离和最小,这样就确定了对于的线,也确定了每个点在新的维度上的特征值

-
我们应该怎么做?
(1)算法是核心,数据和计算是基础


-
机器学习开发步骤
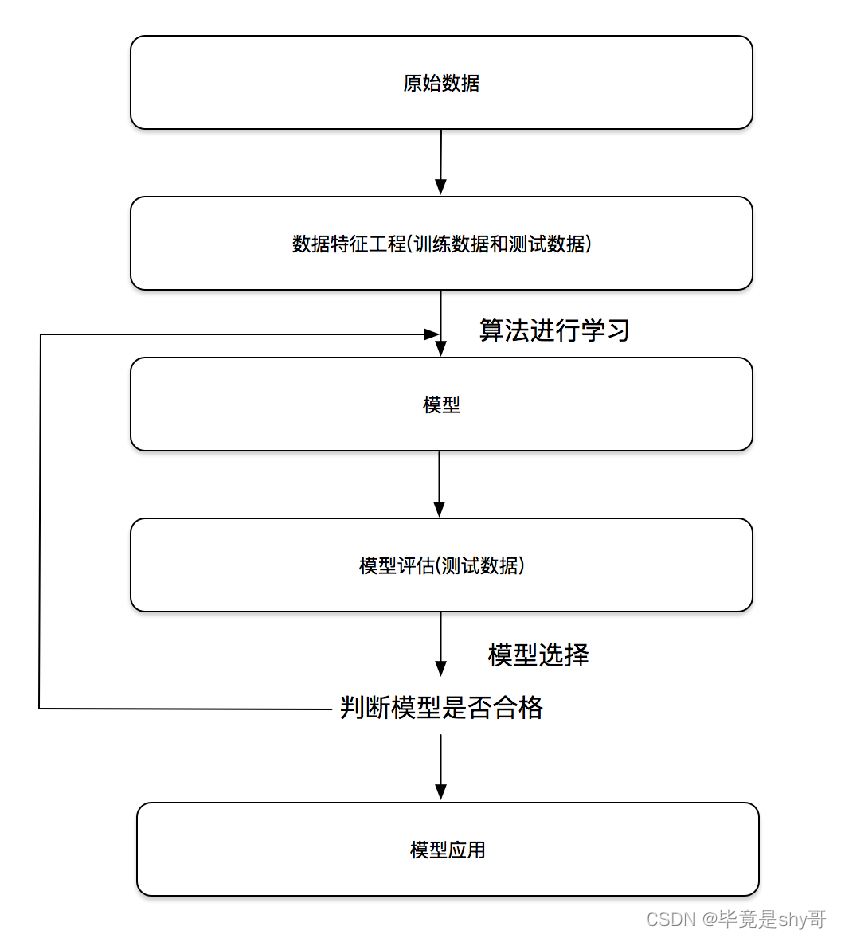
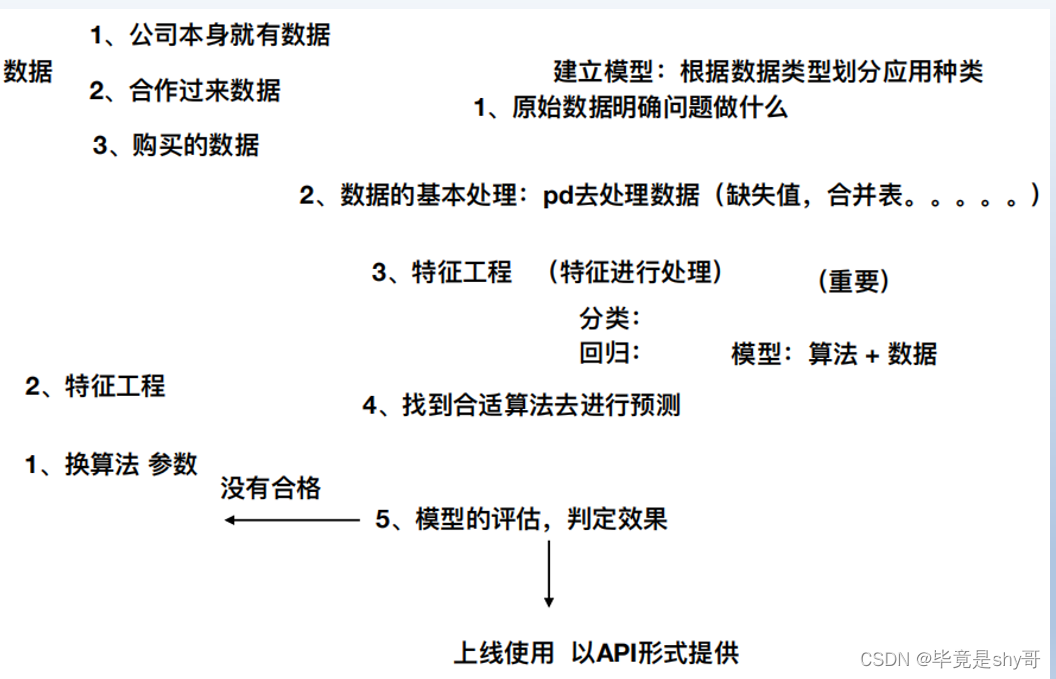
-
机器学习模型是什么
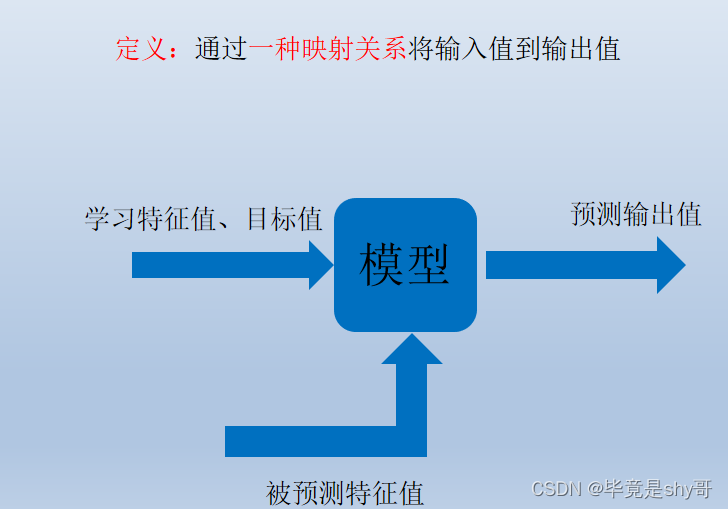
-
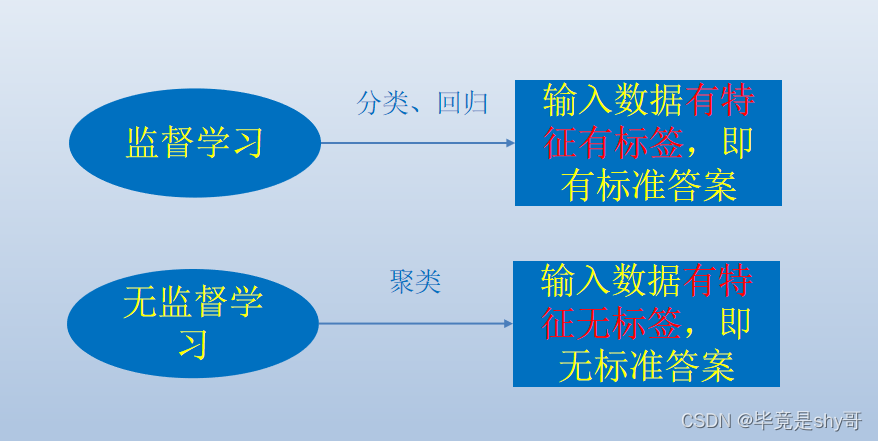
监督学习和非监督学习


- 逻辑回归是分类问题


-
分类问题

-
回归问题

-
测试集与训练集划分

-
特征工程—fit_transform转换器
1、实例化 (实例化的是一个转换器类(Transformer))(测试集用)
2、调用 fit_transform(对于文档建立分类词频矩阵,不能同时调用)(训练集用)
3、fit()计算平均值方差等,transform进行数据的转换 -
特征工程—估计器(预估器)



-
估计器的工作流程
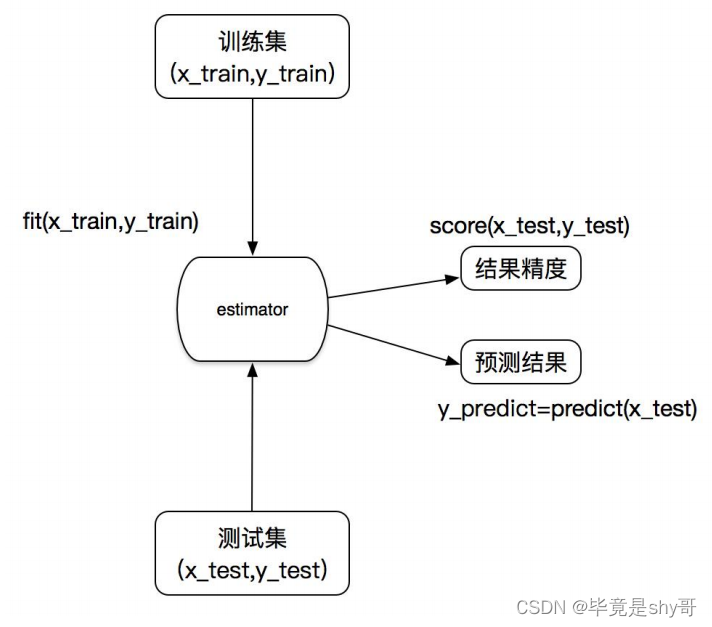
-
分类算法-k 近邻算法(KNN)
- 定义:如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属 于某一个类别,则该样本也属于这个类别。
来源:KNN 算法最早是由 Cover 和 Hart 提出的一种分类算法 - 计算距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
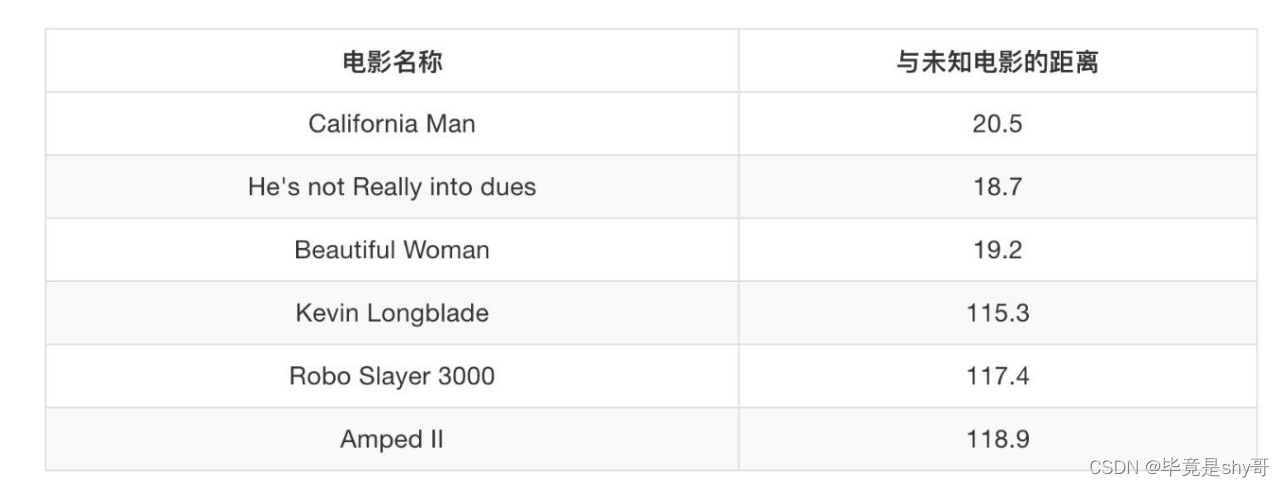

- knn中k 值取多大?有什么影响?


- k近邻算法的优缺点
-
优点:

-
缺点:



- 交叉验证:

- 网格搜索
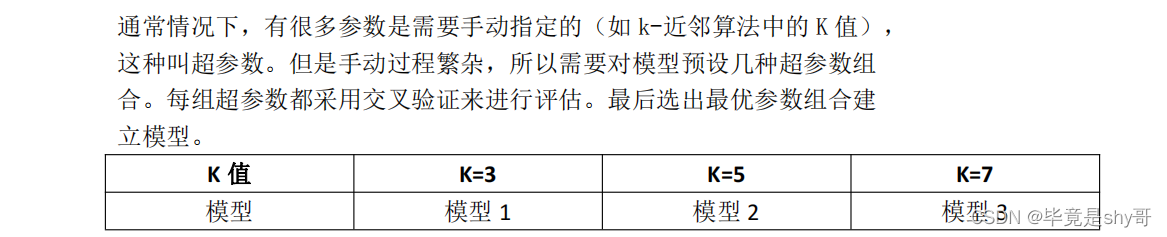
- 混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存 在四种不同的组合,构成混淆矩阵(适用于多分类)
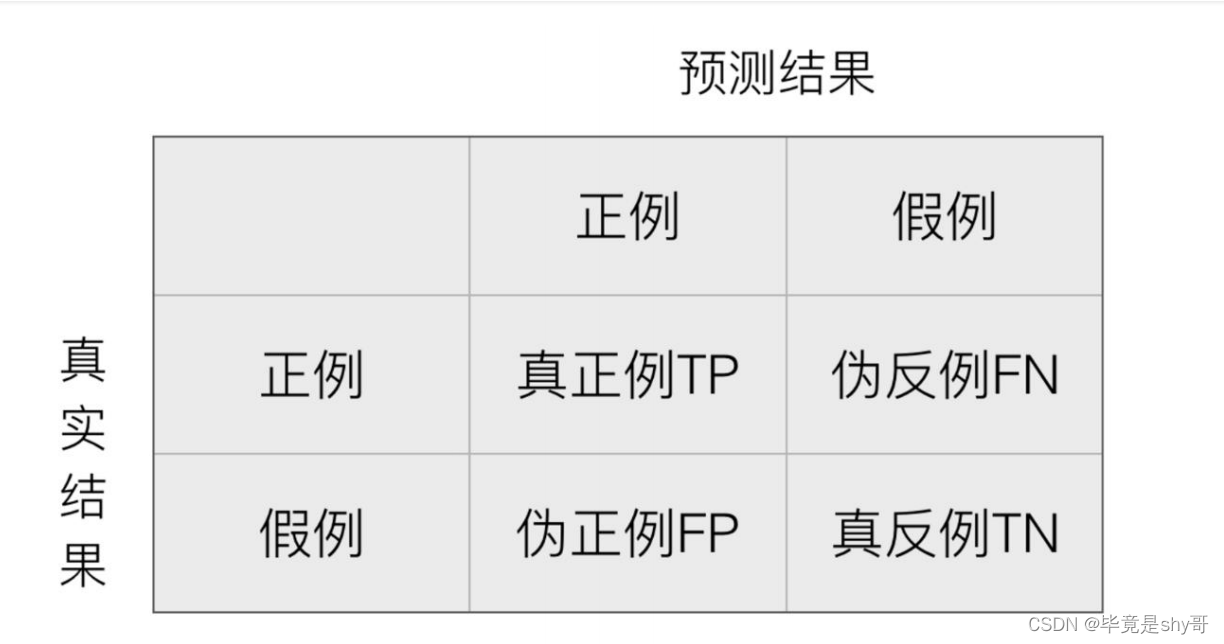
- 精确率与召回率


- TPR、FPR、ROC、AUC

- FPR越小越好
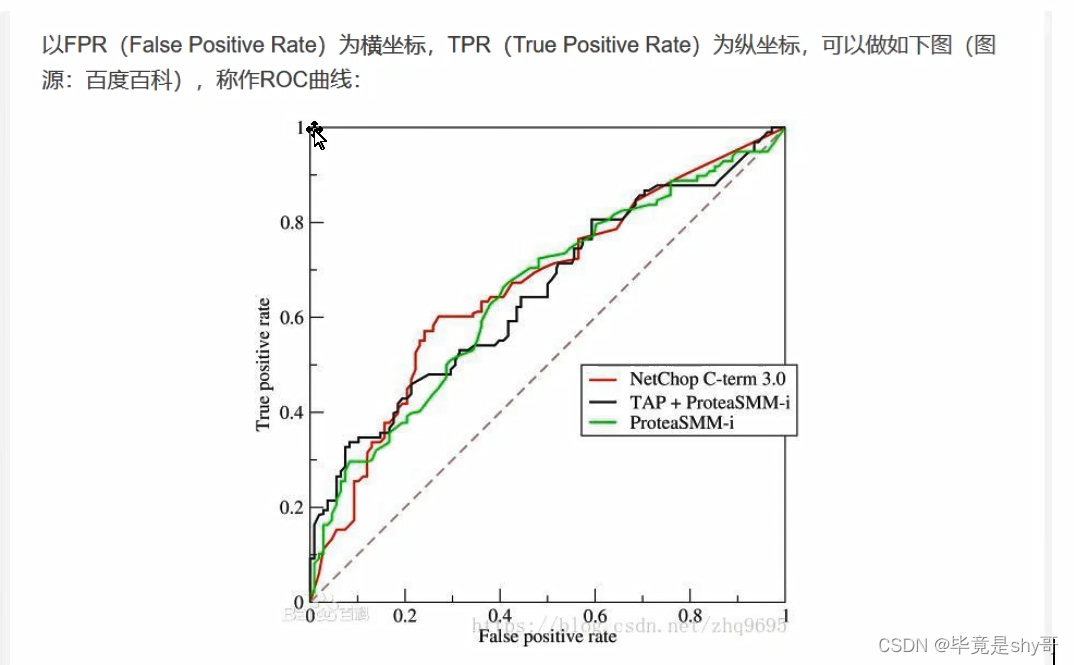
- 下面的面积越大越好
- AUC是下面的面积
- knn分类算法



- 拉普拉斯平滑系数

- 分子和分母加上一个系数,分母加alpha*特征词数目
-
朴素贝叶斯分类优缺点

-
信息熵

-
信息增益

-
信息增益的计算

-
案例
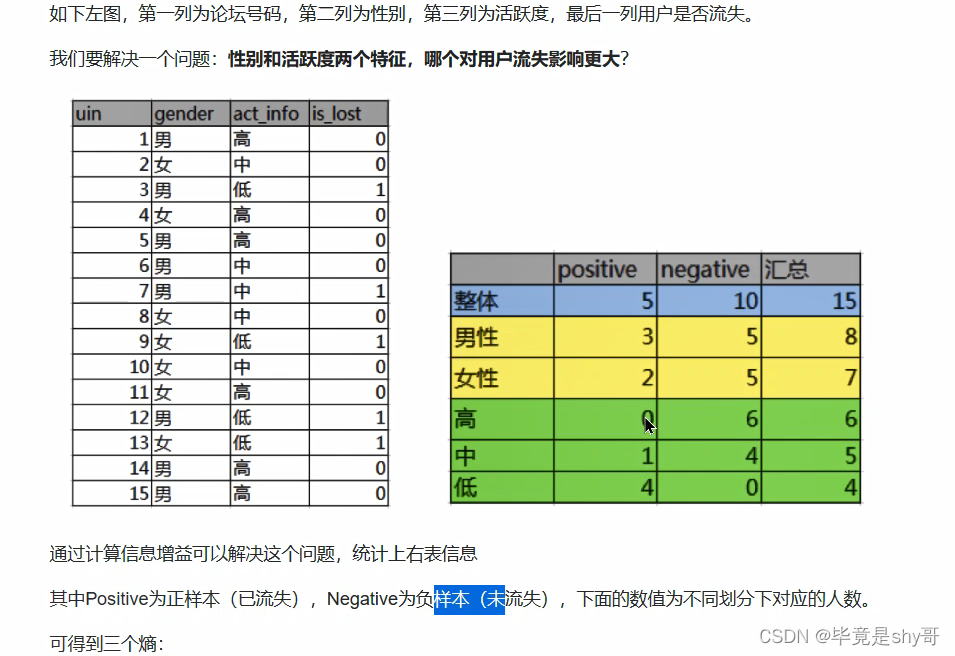


-
DictVectorizer()可以非数值转化成数值,ont-hot编码
-
决策树的划分依据
- 信息增益
- 信息增益率
- 基尼值和基尼指数

-
决策树优缺点及改进

-
集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类 器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单 分类的做出预测。
- 什么是随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由 个别树输出的类别的众数而定。 - 为什么要随机抽样训练集?

- 随机森林的优点

- 线性模型

- 线性回归

- 损失函数

- 求w
- 正规方程
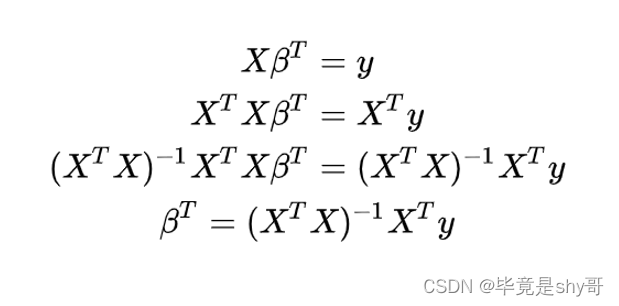

- 梯度下降

-
L1正则和L2的区别

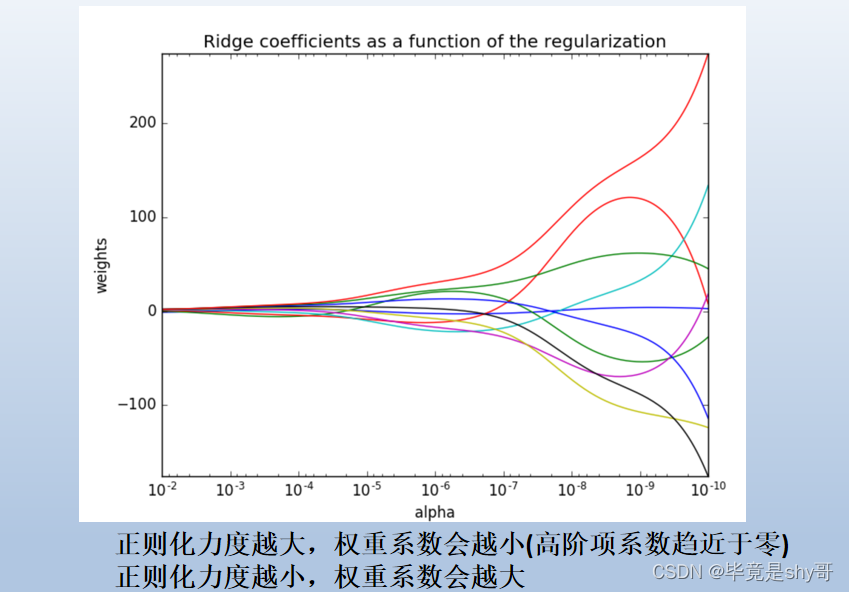
-
scikit-learn和tensorflow优缺点

-
梯度下降和正规方程的区别
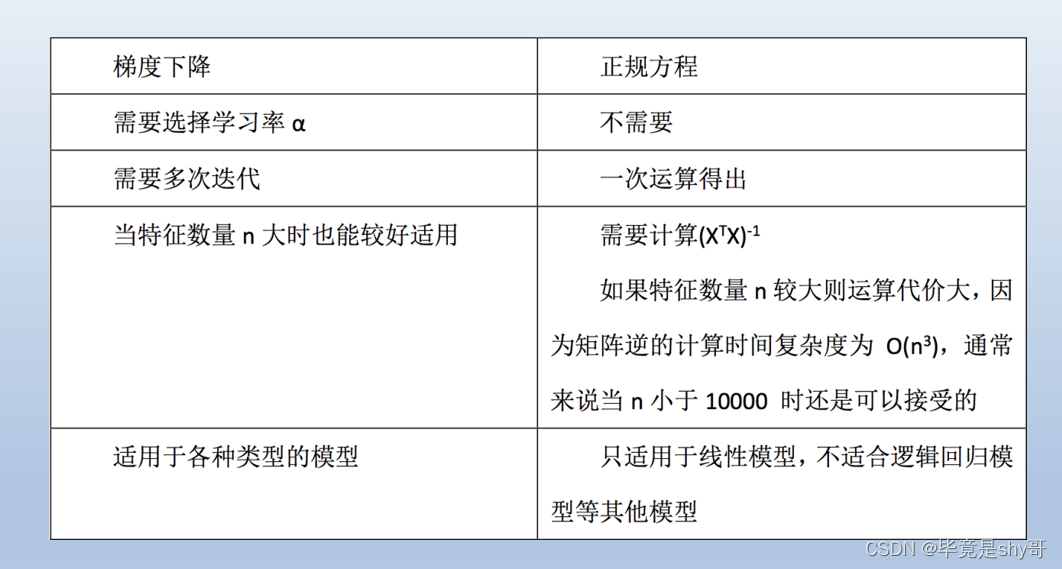

-
欠拟合原因以及解决办法

-
过拟合原因以及解决办法

-
L2正则化
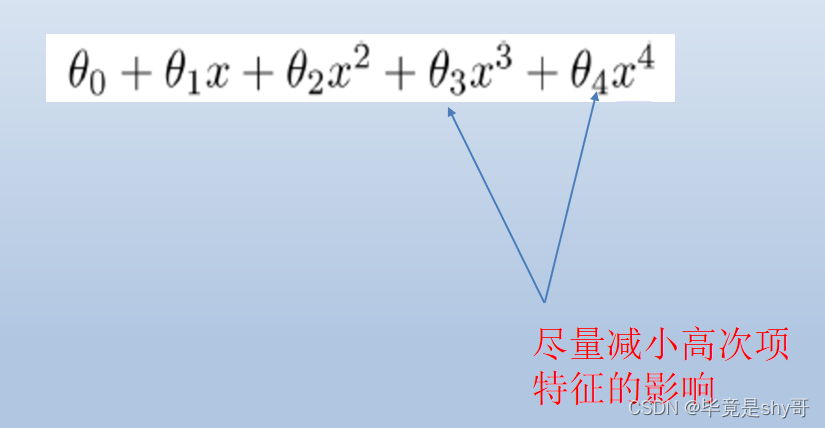

-
逻辑回归是分类算法(解决二分类)
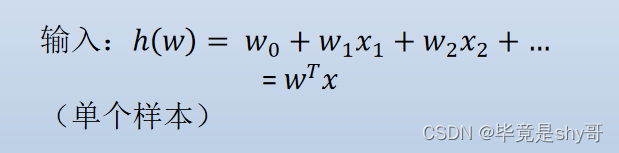
-
sigmoid函数
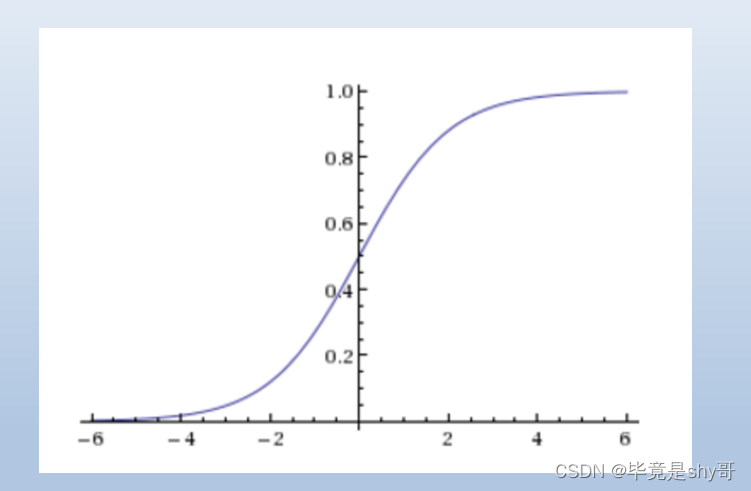
-
逻辑回归公式

-
LogisticRegression总结

-
面对一个机器学习问题,通常有两种策略
略。
一种是研发人员尝试各种模型,选择其中表 现最好的模型做重点调参优化。这种策略类似于奥运会比赛,通过强强竞争来选拔最优的运 动员,并逐步提高成绩。另一种重要的策略是集各家之长,如同贤明的君主广泛地听取众多 谋臣的建议,然后综合考虑,得到最终决策。后一种策略的核心,是将多个分类器的结果统 一成一个最终的决策。使用这 类策略的机器学习方法统称为集成学习。其中的每个单独的 分类器称为基分类器。 -
Boosting(串行)(迭代式学习)


-
Bagging(并行)


69. 集成学习的基本步骤
(1)找到误差互相独立的基分类器。
(2)训练基分类器。
(3)合并基分类器的结果。


















 6345
6345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











