







点对点通信
tag的使用
- tag使用是满足发送和接收完全匹配
如果B先到达Q,如果没有tag匹配,则会放到X中.

- 标签的使用
使用Any_Tag可以都接收,然后用Status.Tag来确定是哪一个发送方.

- 特殊的Tag

#include<stdio.h>
#include<mpi.h>
int main(int argc, char* argv[]){
int myrank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (myrank == 0){
//指定0号进程发送数据
int send_num = 99;
int send_num1 = 100;
int tag = 0;
int tag1 = 1;
MPI_Send(&send_num, 1, MPI_INT, 1, tag, MPI_COMM_WORLD);
MPI_Send(&send_num1, 1, MPI_INT, 1, tag1, MPI_COMM_WORLD);
}
else{
//指定1号进程接收数据
int recv_num = 0;
int recv_num1 = 0;
int tag = MPI_ANY_TAG;
MPI_Status status;
printf("before recv, recv_num = %d\n", recv_num);
MPI_Recv(&recv_num, 1, MPI_INT, MPI_ANY_SOURCE, tag, MPI_COMM_WORLD, &status);
// 两者组合任意消息都可以接收
// 实际上99和100不一定谁先到达
MPI_Recv(&recv_num1, 1, MPI_INT, 0, tag, MPI_COMM_WORLD, &status);
printf("after recv, recv_num = %d\n", recv_num);
printf("after recv, recv_num = %d\n", recv_num1);
}
MPI_Finalize();
return 0;
- 存在的问题
- 阻塞式,同时都在等recv,永远不会结束,死锁问题
- 能选择非阻塞则要选择非阻塞,对通信过程要有了解

练习1:Jacobi迭代
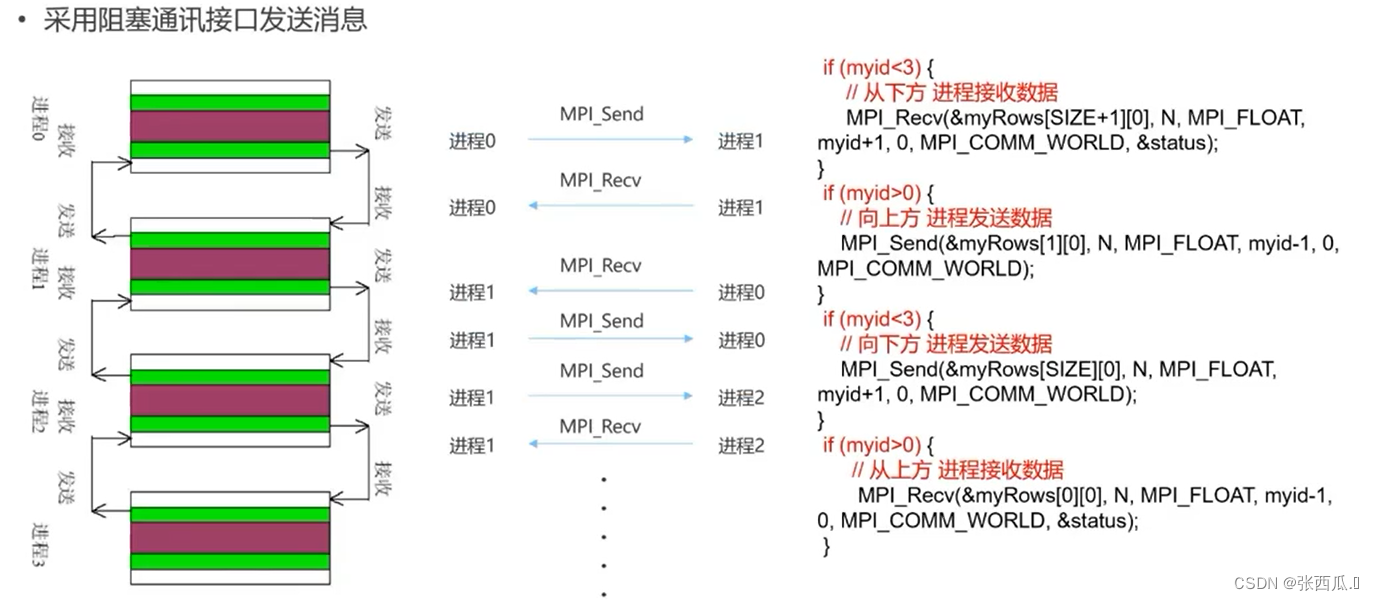
- 采用阻塞式通讯接口
#include<stdio.h>
#include<mpi.h>
#inlcude<stdlib.h>
#include<unistd.h>
#define N 8
#define SIZE N / 4
#define T 2
void print_myRows(int, float [][N]);
int main(int argc, char* argv[]){
int myid, size;
float myRows[SIZE + 2][N], myRows2[SIZE+2][N], tmp[2][N], c[N][N];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status status;
// 初始化数据
int i, j;
for (i = 0; i < SIZE + 2; i ++){
for (j = 0; j < N; j ++){
myRows[i][j] = myRows2[i][j] = 0;
}
}
if (myid == 0){
for (j = 0; j < N; j ++)
myRows[1][j] = 8.0;
}
if (myid == 3){
for (j = 0; j < N; j ++)
myRows[2][j] = 8.0;
}
for (i = 1; i < SIZE + 1; i ++){
myRows[i][0] = 8.0;
myRows[i][N - 1] = 8.0;
}
// 实际迭代过程 0->1->2->3 3->2->1->0
int step;
int tag_down = 0, tag_up = 1;
for (step = 0; step < T; step ++){
// 数据传输
if (myid < 3){
MPI_Send(&myRows[SIZE][0], N, MPI_FLOAT, myid + 1, tag_down, MPI_COMM_WORLD);
}
if (myid > 0){
MPI_Recv(&myRows[0][0], N, MPI_FLOAT, myid - 1, tag_down, MPI_COMM_WORLD, &status);
}
if (myid > 0){
MPI_Send(&myRows[1][0], N, MPI_FLOAT, myid - 1, tag_up, MPI_COMM_WORLD);
}
if (myid < 3){
MPI_Recv(&myRows[SIZE + 1][0], N, MPI_FLOAT, myid + 1, tag_up, MPI_COMM_WORLD, &status);
}
// 数据迭代
// 第一个和最后一个进程取值
int begin_row = (0 == myid) ? 2 : 1;
int end_row = (3 == myid)? 1 : 2;
for (i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows2[i][j] = 0.25 * (myRows[i - 1][j] + myRows[i + 1][j] + myRows[i][j + 1] + myRows[i][j - 1]);
}
}
for (i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows[i][j] = myRows2[i][j];
}
}
}
sleep(myid);
print_myRows(myid, myRows);
// if (myid == 1) sleep(1);
for (int i = 1; i < SIZE + 1; i ++){
for (int j = 0; j < N; j ++){
tmp[i - 1][j] = myRows[i][j];
}
}
// MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, 16, MPI_FLOAT, c, 16, MPI_FLOAT, 0, MPI_COMM_WORLD);
// 输出结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < N; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][N]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE + 2;i ++){
for (j = 0; j < N; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
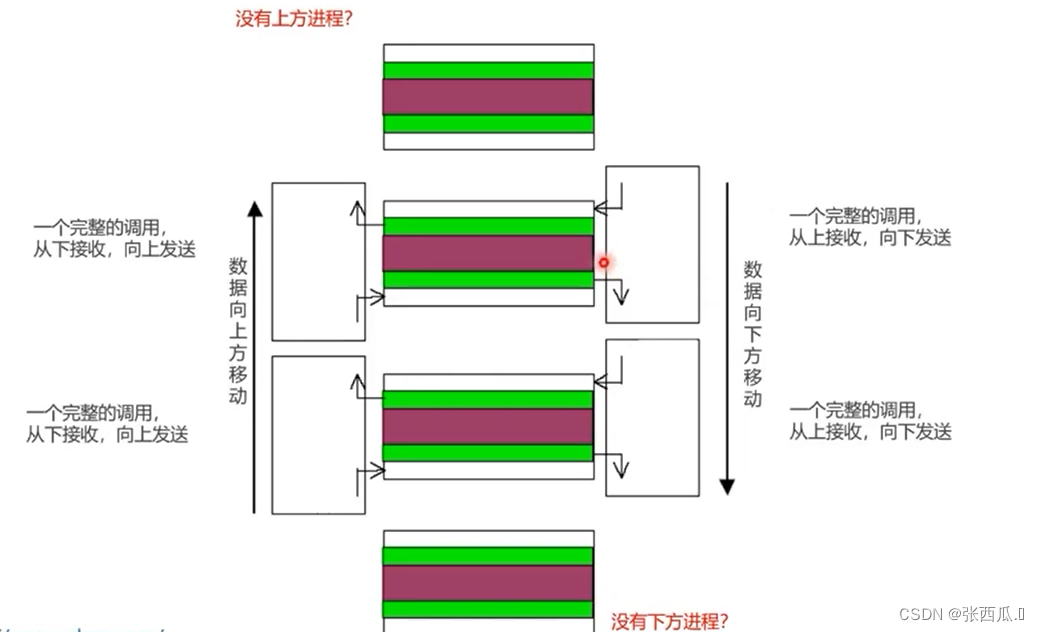
- MPI_Sendrecv捆绑发送接收



由于第一个进程无上方进程,最后一个进程无下方进程,所以引入了虚拟进程.

可以完成接收操作,不会改变之前接受的数据.
#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#define N 8
#define SIZE N / 4
#define T 2
void print_myRows(int, float [][N]);
int main(int argc, char* argv[]){
int myid, size;
float myRows[SIZE + 2][N], myRows2[SIZE+2][N], tmp[2][N], c[N][N];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status status;
// 初始化数据
int i, j;
for (i = 0; i < SIZE + 2; i ++){
for (j = 0; j < N; j ++){
myRows[i][j] = myRows2[i][j] = 0;
}
}
if (myid == 0){
for (j = 0; j < N; j ++)
myRows[1][j] = 8.0;
}
if (myid == 3){
for (j = 0; j < N; j ++)
myRows[2][j] = 8.0;
}
for (i = 1; i < SIZE + 1; i ++){
myRows[i][0] = 8.0;
myRows[i][N - 1] = 8.0;
}
// 实际迭代过程 0->1->2->3 3->2->1->0
int step;
int tag_down = 0, tag_up = 1;
int up_proc_id = (0 == myid) ? MPI_PROC_NULL:(myid - 1);
int down_proc_id = (3 == myid) ? MPI_PROC_NULL:(myid + 1);
for (step = 0; step < T; step ++){
// 数据传输
// 数据向下方移动
MPI_Sendrecv(&myRows[SIZE][0], 8, MPI_FLOAT, down_proc_id, tag_down, &myRows[0][0], 8, MPI_FLOAT, up_proc_id, tag_down, MPI_COMM_WORLD, &status);
// 数据向上方移动
MPI_Sendrecv(&myRows[1][0], 8, MPI_FLOAT, up_proc_id, tag_up, &myRows[SIZE + 1][0], 8, MPI_FLOAT, down_proc_id, tag_up, MPI_COMM_WORLD, &status);
// 数据迭代
// 第一个和最后一个进程取值
int begin_row = (0 == myid) ? 2 : 1;
int end_row = (3 == myid)? 1 : 2;
for (i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows2[i][j] = 0.25 * (myRows[i - 1][j] + myRows[i + 1][j] + myRows[i][j + 1] + myRows[i][j - 1]);
}
}
for (i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows[i][j] = myRows2[i][j];
}
}
}
sleep(myid);
print_myRows(myid, myRows);
// if (myid == 1) sleep(1);
for (int i = 1; i < SIZE + 1; i ++){
for (int j = 0; j < N; j ++){
tmp[i - 1][j] = myRows[i][j];
}
}
// MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp, 16, MPI_FLOAT, c, 16, MPI_FLOAT, 0, MPI_COMM_WORLD);
// 输出结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < N; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][N]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE + 2;i ++){
for (j = 0; j < N; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
MPI_Barrier(MPI_COMM_WORLD);
}
- 主从模式
0进程:负责初始化数组,然后发送给1234进程.最后接收结果
其他进程:负责接收初始化数组,并且进行与其他进程通信计算,结果再返回0号进程

#include<stdio.h>
#include<mpi.h>
#include<stdlib.h>
#include<unistd.h>
#include<string.h>
#define N 8
#define SIZE N / 4
#define T 2
MPI_Status status;
float oriA[N][N], myRows[SIZE + 2][N], myRows2[SIZE+2][N],c[N][N];
void print_myRows(int, float [][N]);
// 主进程,分发和收集
void master(){
memset(&oriA[0][0], 0, sizeof(float) * N * N);
for (int i = 0; i < N; i ++){
oriA[0][i] = 8.0;
oriA[N - 1][i] = 8.0;
oriA[i][0] = 8.0;
oriA[i][N - 1] = 8.0;
}
for (int i = 0; i < 4; i ++){
MPI_Send(&oriA[i * 2][0], N * 2, MPI_FLOAT, i + 1, i + 1, MPI_COMM_WORLD);
}
for (int i = 0; i < 4; i ++){
MPI_Recv(&c[i * 2][0], N * 2, MPI_FLOAT, i + 1, i + 1, MPI_COMM_WORLD, &status);
}
}
void slave(int myid){
memset(&myRows[0][0], 0, sizeof(float) * N * (SIZE + 2));
MPI_Recv(&myRows[1][0], N * 2, MPI_FLOAT, 0, myid, MPI_COMM_WORLD, &status);
// 实际迭代过程 0->1->2->3 3->2->1->0
int step;
int tag_down = 0, tag_up = 1;
int up_proc_id = (1 == myid) ? MPI_PROC_NULL:(myid - 1);
int down_proc_id = (4 == myid) ? MPI_PROC_NULL:(myid + 1);
for (step = 0; step < T; step ++){
// 数据传输
// 数据向下方移动
MPI_Sendrecv(&myRows[SIZE][0], 8, MPI_FLOAT, down_proc_id, tag_down, &myRows[0][0], 8, MPI_FLOAT, up_proc_id, tag_down, MPI_COMM_WORLD, &status);
// 数据向上方移动
MPI_Sendrecv(&myRows[1][0], 8, MPI_FLOAT, up_proc_id, tag_up, &myRows[SIZE + 1][0], 8, MPI_FLOAT, down_proc_id, tag_up, MPI_COMM_WORLD, &status);
// 数据迭代
// 第一个和最后一个进程取值
int begin_row = (1 == myid) ? 2 : 1;
int end_row = (4 == myid)? 1 : 2;
for (int i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows2[i][j] = 0.25 * (myRows[i - 1][j] + myRows[i + 1][j] + myRows[i][j + 1] + myRows[i][j - 1]);
}
}
for (int i = begin_row; i <= end_row; i ++){
for (int j = 1; j < N - 1; j ++){
myRows[i][j] = myRows2[i][j];
}
}
}
sleep(myid);
print_myRows(myid, myRows);
MPI_Send(&myRows[1][0], 2 * N, MPI_FLOAT, 0, myid, MPI_COMM_WORLD);
}
int main(int argc, char* argv[]){
int myid, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 5){
printf("Use 5 processes to run Master slave mode!\n");
MPI_Abort(MPI_COMM_WORLD, 1); // 终止程序,给一个信后
}
if (0 == myid){
master();
}else{
slave(myid);
}
// 输出结果
if (0 == myid){
fprintf(stderr, "\n收集后结果\n");
for (int i = 0; i < N; i ++){
for (int j = 0; j < N; j ++){
fprintf(stderr, "%.3f\t", c[i][j]);
}
fprintf(stderr, "\n");
}
fprintf(stderr, "\n");
}
MPI_Finalize();
return 0;
}
void print_myRows(int myid, float myRows[][N]){
int i, j;
printf("Result in process %d:\n", myid);
for (i = 0; i < SIZE + 2;i ++){
for (j = 0; j < N; j ++){
printf("%1.3f\t", myRows[i][j]);
}
printf("\n");
}
// MPI_Barrier(MPI_COMM_WORLD);
}
任务1
任务描述
编写MPI程序,求和1+2+3+……+100。
要求:
1、使用两个进程
2、进程0计算1+2+…+20,进程1计算21+22+…+100
3、调用计时函数,分别输出两个进程的计算时间。
4、输出两个进程的计算结果,要求结果加起来等于5050
代码
```cpp
#include<stdio.h>
#include<mpi.h>
#include<sys/time.h>
#include<iostream>
int main(int argc, char* argv[]){
int myrank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
//struct timeval time_start, time_end;
double pStart, pEnd;
if (myrank == 0){
int a = 0;
int b = 0;
int sum = 0;
int tag = 0;
MPI_Status status;
pStart = MPI_Wtime();
//gettimeofday(&time_start, NULL);
for (int i = 1; i <= 20; i ++) a += i;
//gettimeofday(&time_end, NULL);
pEnd = MPI_Wtime();
MPI_Recv(&b, 1, MPI_INT, 1, tag, MPI_COMM_WORLD, &status);
//printf("rank 0 used time %ld us \n", time_end.tv_usec - time_start.tv_usec);
printf("rank 0 耗时 %lf 秒", pEnd - pStart);
//std::cout << "rank 0 耗时" << pEnd - pStart << "秒" << std::endl;
printf("rank 0 result is %d, rank 1 result is %d, sum is %d \n", a, b, a + b);
}else{
int b = 0;
int tag = 0;
pStart = MPI_Wtime();
for (int i = 21; i <= 100; i ++) b += i;
//gettimeofday(&time_end, NULL);
pEnd = MPI_Wtime();
MPI_Send(&b, 1, MPI_INT, 0, tag, MPI_COMM_WORLD);
//printf("rank 1 used time %ld us \n", time_end.tv_usec - time_start.tv_usec);
printf("rank 1 耗时 %lf 秒", pEnd - pStart);
//std::cout << "rank 1 耗时"<< pEnd - pStart << "秒" << std::endl;
}
MPI_Finalize();
return 0;
}














 3325
3325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









