






在当今人工智能技术飞速发展的背景下,大模型训练和推理所需资源成为行业关注的焦点。本文将从四个方面介绍大模型相关资源情况:
- 训练资源概述:分析了大模型训练过程中所需的GPU计算资源
- 推理资源的计算方法:为读者提供了一套实用的计算框架
- GPU服务器概述:英伟达服务器及海光服务器配置简介
- 推理集群配置建议:为读者在大模型推理环境搭建过程中提供参考
通过本文的阅读,希望读者能够对大模型所需的GPU计算资源有一个全面、深入的了解,为人工智能领域的研究和实践提供有力支持。
一、训练资源概述
要训练一个 100B 规模的 LLM,通常需要庞大的数据资源和计算资源,例如拥有万卡 GPU 的集群,TB级的数据。
- 计算资源:大模型训练需要大量的计算资源,包括GPU和分布式计算系统。Meta 在训练其 LLaMA3 系列模型时使用了 15T 的 Token,这一过程是在 2 个 24K H100 集群上完成的。LLaMA 2 70B 训练需要 1.7M GPU hours(A100),要是用 1 个 GPU,那得算 200 年。要在一个月这种比较能接受的时间周期内训练出来,就得至少有 2400 块 A100。OpenAI在GPT-4的训练中动用了大约25000个A100 GPU,历时近100天,并采用分布式计算以加速模型的训练过程。此外,对于GPT-3的微调,使用1个节点(8xA100)在1亿令牌上训练1.3亿参数模型需要7.1小时,而使用16个节点(128xA100)只需要0.5小时,显示了分布式并行训练在加速大模型训练中的重要性。
- 数据资源:大模型训练需要海量的数据来学习语言的深层次规律和语义信息。例如,GPT-3的训练数据据说就达到了45 TB,GPT-4 的训练数据集包含约 130B个 token。数据集的质量、规模和多样性直接影响到模型的性能和泛化能力。高质量的数据集可以提供丰富的语言知识和语义信息,使得模型能够学习到更准确的语言规律。
此外,大模型训练的算力需求可以通过公式 6∗N∗D来计算,其中 N是模型的参数量, D是你要用的训练token的数量。例如,一个82B参数的GPT-3,用150B的token来训练,如果拥有1024个A100 GPU,可以计算出所需的算力。由于作者未参与过模型训练,以上只是理论数据。本篇主要详细介绍一下推理所需的计算资源(不涉及训练数据资源,相对简单)。
二、推理资源计算明细
在系统的介绍GPU资源使用情况前,我们有必要先了解一下GPU的算力具体是怎么衡量的。下图是一个简单算力表格对比:
| 型号 | 显存 | FP32 | FP16 | INT8 | INT4 |
|---|---|---|---|---|---|
| 海光Z100L 深算一号(MI50) | 32GB | 12TF | 25TF | ||
| 海光K100 深算二号 | 64GB | 25TF | 100TF | 200TF | |
| 英伟达A100 PCIe | 80GB | 312TF | 624TF | ||
| 英伟达4090 | 24GB | 83TF | 330TF | ||
| 英伟达A30 | 24GB | 10TF | 165TF | 330TF | 661TF |
| 英伟达V100 | 32GB | 125TF | |||
| 英伟达K80 | 12GB | 8.73TF | |||
| 昇腾910B | 64GB | 256TF | 512TF |
根据显存大小计算所需卡数计算公式:
以FP16为基准:参数大小nB * 2/单卡显存 = 需要的卡数量
以INT4为基准:参数大小nB /2/单卡显存 = 需要的卡数量
以上计算时还需要考虑冗余显存,加载KV Cache、Prompt Cache等,一般40 GB KV Cache即可,Prompt Cache根据大模型支持情况而定,一般32K(较大)。
| 型号 | Qwen1.5-14B-FP16 | Qwen1.5-32B-FP16 | Qwen1.5-32B-INT4 | Qwen1.5-72B-INT4 | Qwen1.5-110B-INT4 |
|---|---|---|---|---|---|
| 海光Z100L 深算一号(MI50) | Y *2 | ||||
| 海光K100 深算二号 | |||||
| 英伟达A100 PCIe | Y*1 | Y*1 | Y*1 | Y*1 | Y*1 |
| 英伟达4090 | Y *2 | Y*4 | Y*2 | Y*4 | Y*4 |
| 英伟达A30 | Y*4 | N | |||
| 英伟达V100 | |||||
| 英伟达K80 | N | N | N | N | N |
| 昇腾910B |
以上有标注Y/N的是作者实践过的场景,Y*2代表可以运行推理,需要2张卡,N代表不能运行。其余空白读者可以自行计算。
三、GPU服务器概述
HGX 是 NVIDIA 出的高性能服务器,通常一台机器包含 8 个或 4 个 GPU,搭配 Intel 或 AMD CPU,并且使用 NVLink 和 NVSwitch 实现全互联(8 个 GPU 通常也是除 NVL 和 SuperPod 之外的 NVLink 全互联的上限),而且一般会采用风冷散热。
- 从 HGX A100 -> HGX H100 和 HGX H200,其 FP16 稠密算力增加到 3.3 倍,而功耗不到原来的 2 倍。
- 从 HGX H100 和 HGX H200 -> HGX B100 和 HGX B200,其 FP16 稠密算力增加到 2 倍左右,而功耗相当,最多不到 50%。
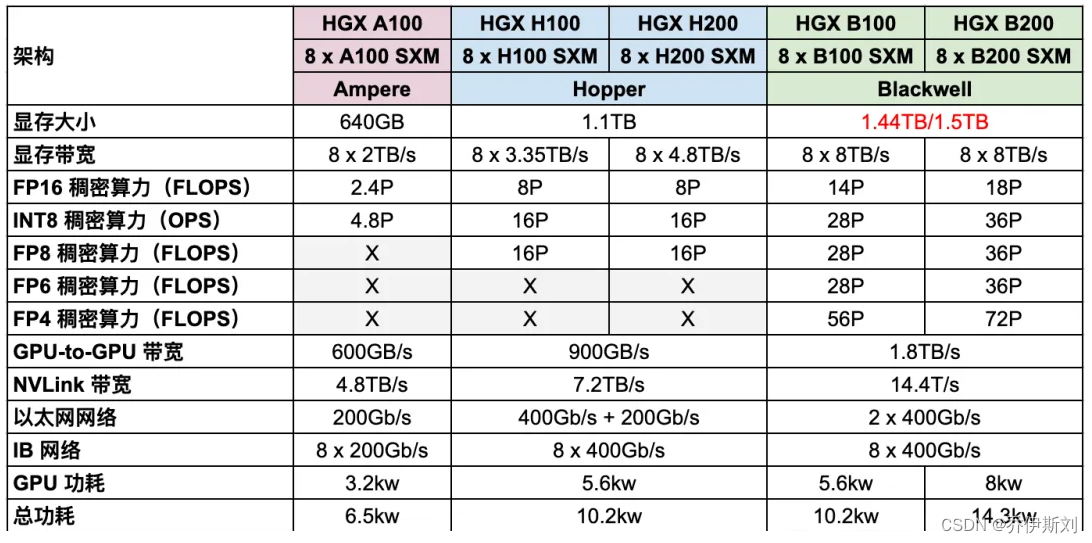
NVIDIA DGX 和 HGX 是两种高性能解决方案,它们都是针对深度学习、人工智能和大规模计算需求的,但是设计和目标应用有所不同:
- DGX:主要面向普通消费者,提供即插即用的高性能解决方案,配套全面的软件支持,包括 NVIDIA 的深度学习软件栈、驱动程序和工具等,通常是预构建的、封闭的系统。
- HGX:主要面向云服务提供商和大规模数据中心运营商,适合用于构建自定义的高性能解决方案。
国产化方面,了解到的海光DCU服务器Hygon /380配置如下(单机4卡):
| DDR4 3200 32G*16 |
|---|
| 1.2TB 2.5吋10K12Gb SAS硬盘*3 |
| 480G 2.5 SATA 6GD R SSD^2 |
| 8口RAID卡(9540) |
| 横插04盘12G SAS 硬盘背板*2 |
| 双口10G 含模块光纤网卡*2 |
| HG DCU K100 -E4x16 64GB 300W 双宽 GPU卡*4 |
| 42000W电源模块4/托轨 /150cm 国标电源线*4 |
四、推理集群配置建议
1) 推荐配置
| 大模型 | 系统版本 | CPU | 内存 | 磁盘 | GPU | GPU显存 |
|---|---|---|---|---|---|---|
| Qwen14B | Centos7.9 | Intel x8632C | 64G | 1T | 1 * NVIDIA A100 | 80G |
| Qwen72B | Centos7.9 | Intel x8632C | 64G | 1T | 4 * NVIDIA A100 | 80G |
| Qwen110B | Centos7.9 | Intel x8632C | 64G | 1T | 6 * NVIDIA A100 | 80G |
2) 国产化配置
| 大模型 | 系统版本 | CPU | 内存 | 磁盘 | GPU | GPU显存 |
|---|---|---|---|---|---|---|
| Qwen14B | Centos7.9 | x86 32C | 64G | 1T | 4 * HG DCU | 64G |
| Qwen72B | Centos7.9 | x86 32C | 64G | 1T | 8 * HG DCU K100 | 64G |
| Qwen110B | – | – | – | – | – | – |
3) 高性价比配置
| 大模型 | 系统版本 | CPU | 内存 | 磁盘 | GPU | GPU显存 |
|---|---|---|---|---|---|---|
| Qwen14B | Centos7.9 | Intel x8632C | 64G | 1T | 2 * NVIDIA | 24G |
| Qwen72B | Centos7.9 | Intel x8632C | 64G | 1T | 4 * NVIDIA | 24G |
| Qwen110B | – | – | – | – | – | – |

















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









