







为什么要用字典树
字典树有比较多的功能,我目前了解的有:
1)统计一堆字符串中每个字符串出现的次数,嗯,是不是想到了如何生成词云呢,个人认为词云就是用字典树为核心算法生成的。
2)处理一些字符串,删除重复出现的字符串(看起来没什么难的,但是如果字符串的数量高达1e7呢?)
3)字符串匹配问题
字典树对于这些问题有很好的效果。是一种用空间换时间的方法。
PS:当我第一次看见这个名字的时候,一点也没看出是什么,人家树链剖分听名字都可以猜个三成,这字典树倒是一点也没看出是啥。
字典树的结构
字典树也是树形结构的,而我们在构建字典树的时候将按照如下的规则:
1)树中的每条边代表一个字符
2)根结点到某一结点路径上的边组成的字符串,为这一结点所表示的字符串
3)某一结点的深度就是其代表的字符串的长度
如何实现
我们构建字典树一般采用数组储存或者动态开点储存,能用数组储存的一般是数据量比较小的,当数据量偏大的时候就需要动态开的了(其实如果完全利用,空间是一样的,不过特殊情况下动态开点更有效,比如我们下面的那一道例题)
在这里我就介绍一下数组储存的方法吧,一般我们开一个二维数组来维护: tree[i][j] ,i 表示结点的编号,我们会为每个新的结点唯一标识一个编号,j 表示从这个结点借助一条边权为 j 的边到达子节点,tree[i][j] 表示一个编号为 i 的结点,借助一条边权为 j 的边到达的子节点编号。
当我们建图的时候,需要考虑能不能利用已经存在的边,也就是有没有相应的字符,如果存在可用边,那就利用这个边到达下一个结点,然后寻找下一个字符是否出现,如果没有可用边,那我们就新建一个权值为这个字符的边,得到一个新的结点,我们以字符串win , warm ,watch 为例,先构建出了一条链,如图:
构建win,全部都是构建新边

构建warm,权值为w的边可以利用,得到如下图:
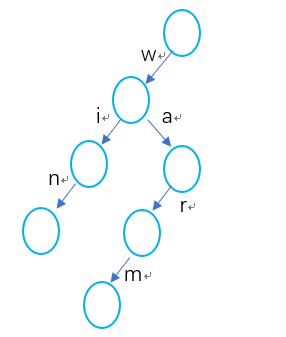
然后,构建watch,此时边权为w和a的边都可以利用,得到下图:

此时我们就得到了由win,warm,watch构建的字典树了,现在,我们来进行一下字符串匹配问题,两个字符串,wat 和 winter ,我们的匹配过程和建图过程是相似的。
以wat为例,从根结点开始,存在边权为w的边,然后,我们的结点移动到这条边的终点,从这个点开始,存在边权为a的边,继续转移到这条边的终点,从这个点开始,存在边权为t的边,我们继续将结点移动到这条边的终点,此时wat已近匹配完了,这说明wat是win,warm,watch三个字符串中某个字符串的子串。
对于watch,当我们匹配的过程中,发现watch没有匹配完,但是字典树中已经没有可转移的边了,此时说明watch不是三个字符串中人一个的子串。
可能讲的不是很好,没看懂的话建议去这里看点击进入(QAQ,没讲好,我也很伤心,但是不能让看我博客的人搞不懂)
例题(链接:https://csustacm.fun/problem/1006)

题目分析
这个题目如果开二维数组存的话,空间为 sizeof(int) * 2e5 * 1e3 == MLE ,因此,我们将数组的第二维度换位了map,这一一来我们的空间就只需要 sizeof(int)*2e5 了
还有就是这个题目的一种优化法,因为我们构建的节点数为m的那个树,如果他的极大链(从根结点到叶子结点的链)是匹配的,那么这条链的子链必然也是匹配的,所以我们不需要每条链都进行一次匹配,虽然我没试过每条链都匹配,但是超时还是很可能的。
代码区(可提取字典树模板)
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<queue>
#include<string>
#include<cmath>
#include<fstream>
#include<vector>
#include<stack>
#include <map>
#include <iomanip>
#define bug cout << "**********" << endl
#define out cout<<"---------------"<<endl
#define show(x, y) "["<<x<<","<<y<<"] "
//#define LOCAL = 1;
using namespace std;
typedef long long ll;
const int inf = 0x3f3f3f3f;
const int mod = 1e8;
const int Max = 2e5 + 10;
struct Edge
{
int to, next;
}edge[Max << 1];
struct Node
{
map<int, int>maps; //这个地方无法像常规的
}node[Max];
int n, m;
int head[Max], tot;
int id;
int val[Max]; //记录各个结点的值
int a[Max], len; //a[i]记录插入值第i位的数(从左到右数),以及插入的数长度
void init() //初始化操作
{
memset(head, -1, sizeof(head));tot = 0;
for (int i = 0;i < Max; i++)
node[i].maps.clear();
id = 0;
}
void add(int u, int v)
{
edge[tot].to = v;
edge[tot].next = head[u];
head[u] = tot++;
}
void insert()
{
int root = 0;
for (int i = 1;i <= len;i++)
{
if (node[root].maps[a[i]] == 0) node[root].maps[a[i]] = ++id; //如果不存在,那就整一个新的出来
root = node[root].maps[a[i]];
}
}
bool find()
{
int root = 0;
for (int i = 1;i <= len;i++)
{
if (node[root].maps[a[i]])
{
root = node[root].maps[a[i]];
continue;
}
return false; //只要出现了一个位置的不匹配,那不匹配
}
return true;
}
bool dfs(int now, int pre, int depth) //当前结点编号和深度,深度代表字符串长度
{
a[depth] = val[now]; //记录当前结点所代表的字符串
bool ok = true;
bool vis = false;
for (int i = head[now]; i != -1 && ok; i = edge[i].next) //分最长字符串无需进行匹配,纯粹浪费时间
{
int v = edge[i].to;
if (v == pre) continue;
ok = dfs(v, now, depth + 1);
vis = true; //代表不是叶子结点
}
if (!vis) //为了节省时间,我们只需要用根结点到叶子节点的这条链去匹配就可以了
{
len = depth;
return find();
}
return ok;
}
int main()
{
#ifdef LOCAL
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
#endif
while (scanf("%d%d", &n, &m) != EOF)
{
init();
for (int i = 1;i <= n;i++)
{
scanf("%d", &len);
for (int j = 1;j <= len;j++)
scanf("%d", a + j);
insert();
}
for (int i = 1; i <= m;i++)
scanf("%d", val + i);
for (int i = 1, u, v;i < m;i++)
{
scanf("%d%d", &u, &v);
add(u, v);add(v, u);
}
if (dfs(1, 0, 1))
printf("YES\n");
else
printf("NO\n");
}
return 0;
}















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









