










文章目录
微服务可用性设计
隔离
隔离,本质上是对系统或资源进行分割,从而实现当系统发生故障时能限定传播范围和影响范围,即发生故障后只有出问题的服务不可用,保证其他服务仍然可用。
服务隔离
- 动静分离、读写分离
轻重隔离 - 核心、快慢、热点
物理隔离 - 线程、进程、集群、机房
读写分离:
主从、Replicaset、CQRS。
核心隔离
业务按照 Level 进行资源池划分(L0/L1/L2)。
- 核心/非核心的故障域的差异隔离(机器资源、依赖资源)。
- 多集群,通过冗余资源来提升吞吐和容灾能力。
快慢隔离
我们可以把服务的吞吐想象为一个池,当突然洪流进来时,池子需要一定时间才能排放完,这时候其他支流在池子里待的时间取决于前面的排放能力,耗时就会增高,对小请求产生影响。
日志传输体系的架构设计中,整个流都会投放到一个 kafka topic 中(早期设计目的: 更好的顺序IO),流内会区分不同的 logid,logid 会有不同的 sink 端,它们之前会出现差速,比如 HDFS 抖动吞吐下降,ES 正常水位,全局数据就会整体反压。
按照各种纬度隔离:sink、部门、业务、logid、重要性(S/A/B/C)。
业务日志也属于某个 logid,日志等级就可以作为隔离通道。
热点隔离
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行缓存。比如:
- 小表广播(被动预热): 从 remotecache 提升为 localcache,app 定时更新,甚至可以让运营平台支持广播刷新 localcache。atomic.Value
- 主动预热: 比如直播房间页高在线情况下bypass 监控主动防御。
线程隔离
主要通过线程池进行隔离,也是实现服务隔离的基础。把业务进行分类并交给不同的线程池进行处理,当某个线程池处理一种业务请求发生问题时,不会讲故障扩散和影响到其他线程池,保证服务可用。
对于 Go 来说,所有 IO 都是 Nonblocking,且托管给了 Runtime,只会阻塞Goroutine,不阻塞 M(netpoll),我们只需要考虑 Goroutine 总量的控制,不需要线程模型语言的线程隔离。
golang 网络层如何封装的epoll
golang 网络层封装epoll核心文件在系统文件src/runtime/netpoll.go, 这个文件中调用了不同平台封装的多路复用api,linux环境下epoll封装的文件在src/runtime/netpoll_epoll.go中,windows环境下多路复用模型实现在src/runtime/netpoll_windows.go。
golang的思想意在将epoll操作放在runtime包里,而runtime是负责协程调度的功能模块,程序启动后runtime运行时是在单独的线程里,个人认为是MPG模型中M模型,epoll模型管理放在这个单独M中调度,M其实是运行在内核态的,在这个内核态线程不断轮询检测就绪事件,将读写就绪事件抛出,从而触发用户态协程读写调度。
而我们常用的read,write,accept等操作其实是在用户态操作的,也就是MPG模型中的G,举个例子当read阻塞时,将该协程挂起,当epoll读就绪事件触发后查找阻塞的协程列表,将该协程激活,用户态G激活后继续读,这样在用户态操作是阻塞的,在内核态其实一直是轮询的,这就是golang将epoll和协程调度结合的原理。
进程隔离
容器化(docker),容器编排引擎(k8s)。我们15年在 KVM 上部署服务;16年使用 Docker Swarm;17年迁移到 Kubernetes,到年底在线应用就全托管了,之后很快在线应用弹性公有云上线;20年离线 Yarn 和 在线 K8s 做了在离线混部(错峰使用),之后计划弹性公有云配合自建 IDC 做到离线的混合云架构。
集群隔离
回顾 gRPC,我们介绍过多集群方案,即逻辑上是一个应用,物理上部署多套应用,通过 cluster 区分。
多活建设完毕后,我们应用可以划分:region.zone.cluster.appid
- 早期转码集群被超大视频攻击,导致转码大量延迟。
入口Nginx(SLB)故障,影响全机房流量入口故障。 - 缩略图服务,被大图实时缩略吃完所有 CPU,导致正常的小图缩略被丢弃,大量503。
- 数据库实例 cgroup 未隔离,导致大 SQL 引起的集体故障。
- INFO 日志量过大,导致异常 ERROR 日志采集延迟。
主动防御:redis 变为 localcache sync.map
webp h265->png
head-of-line blocking ,http2.0 tcp保证可靠传递、顺序传递(只解决了应用层对头阻塞),假如一个包丢了,
拆表会有join,一般是查两次
Docker隔离 linuxCPU隔离基于CFS算法,会导致多个Docker CPU Throttleing
cpu thermal throttling指的是:CPU 自动保护功能设置,一般包括下面几项内容 cpu thermal-throttling(cpu 过热降频保护功能) 此项可以设置当cpu 温度过高时,为了保护cpu,可以降低cpu 频率以达到保护cpu 的目的

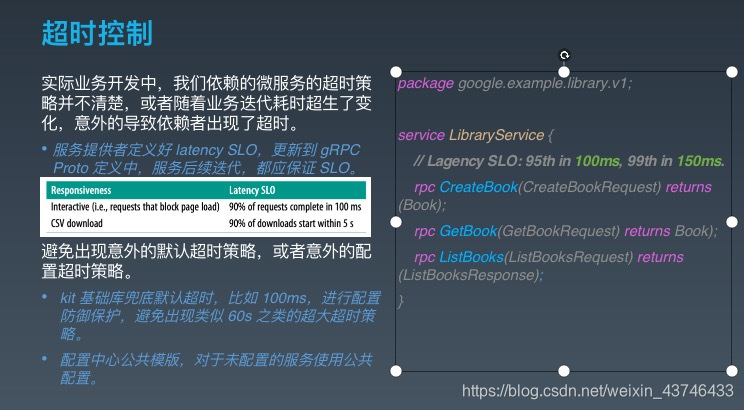
超时控制
超时控制,我们的组件能够快速失效(fail fast),因为我们不希望等到断开的实例直到超时。没有什么比挂起的请求和无响应的界面更令人失望。这不仅浪费资源,而且还会让用户体验变得更差。我们的服务是互相调用的,所以在这些延迟叠加前,应该特别注意防止那些超时的操作
- 网路传递具有不确定性。
- 客户端和服务端不一致的超时策略导致资源浪费。
- “默认值”策略。
- 高延迟服务导致 client 浪费资源等待,使用超时传递: 进程间传递 + 跨进程传递。
当未设置 Deadlines 时,将采用默认的 DEADLINE_EXCEEDED(这个时间非常大)
如果产生了阻塞等待,就会造成大量正在进行的请求都会被保留,并且所有请求都有可能达到最大超时
这会使服务面临资源耗尽的风险,例如内存,这会增加服务的延迟,或者在最坏的情况下可能导致整个进程崩溃
超时控制是微服务可用性的第一道关,良好的超时策略,可以尽可能让服务不堆积请求,尽快清空高延迟的请求,释放 Goroutine。
- A gRPC 请求 B,1s超时。
- B 使用了300ms 处理请求,再转发请求 C。
- C 配置了600ms 超时,但是实际只用了500ms。
- 到其他的下游,发现余量不足,取消传递。
在需要强制执行时,下游的服务可以覆盖上游的超时传递和配额。
在 gRPC 框架中,会依赖 gRPC Metadata Exchange,基于 HTTP2 的 Headers 传递 grpc-timeout 字段,自动传递到下游,构建带 timeout 的 context。
95线 表示至少有95%的数字是小于或者等于这个值
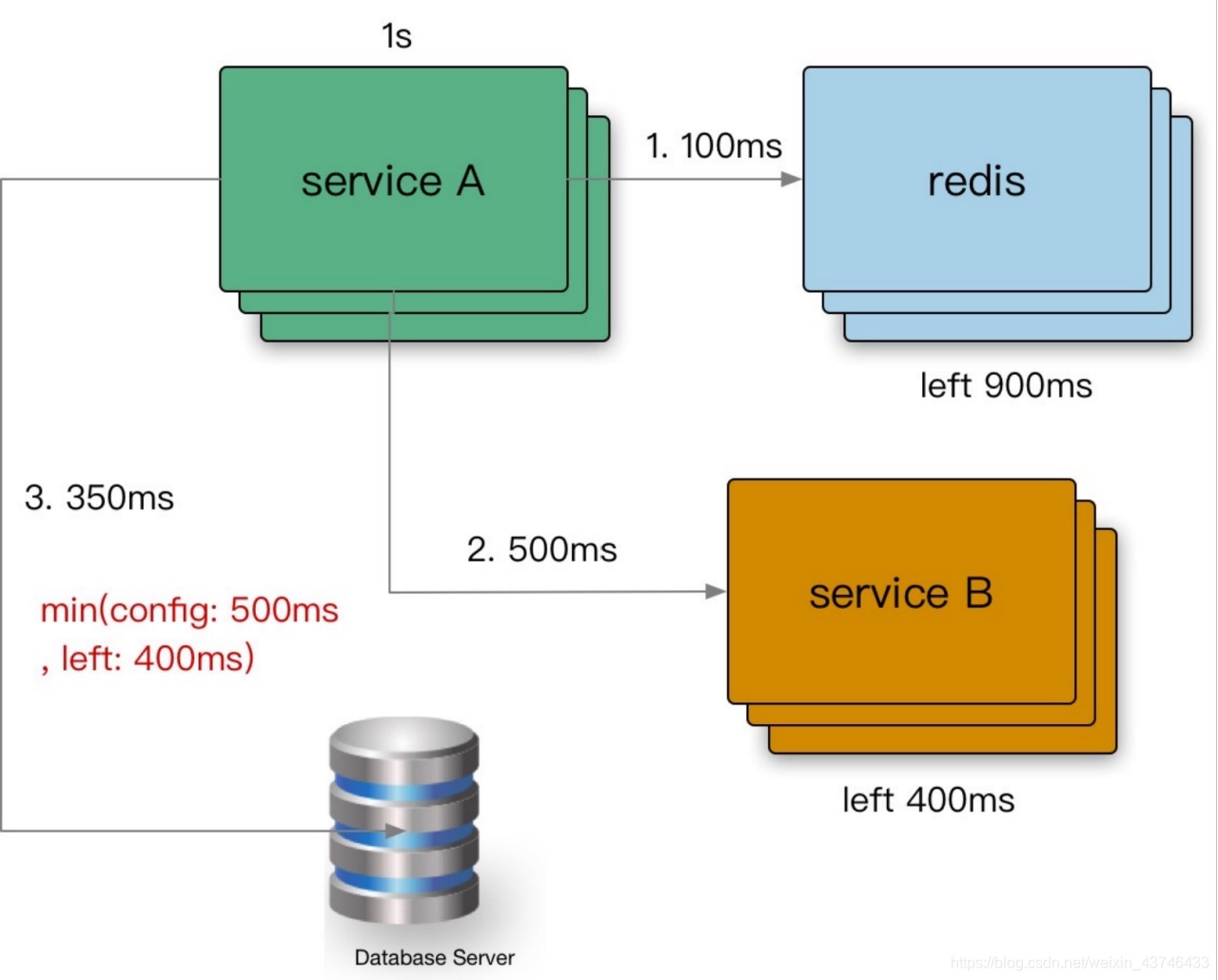
超时传递: 当上游服务已经超时返回 504,但下游服务仍然在执行,会导致浪费资源做无用功。超时传递指的是把当前服务的剩余 Quota 传递到下游服务中,继承超时策略,控制请求级别的全局超时控制。
- 进程内超时控制
一个请求在每个阶段(网络请求)开始前,就要检查是否还有足够的剩余来处理请求,以及继承他的超时策略,使用 Go 标准库的 context.WithTimeout。
func (c *asiiConn) Get(ctx context.Context, key string) (result *Item, err error) {
c.conn.SetWriteDeadline(shrinkDeadline(ctx, c.writeTimeout))
if _, err = fmt.Fprintf(c.rw, "gets %s\r\n", key); err != nil {
双峰分布
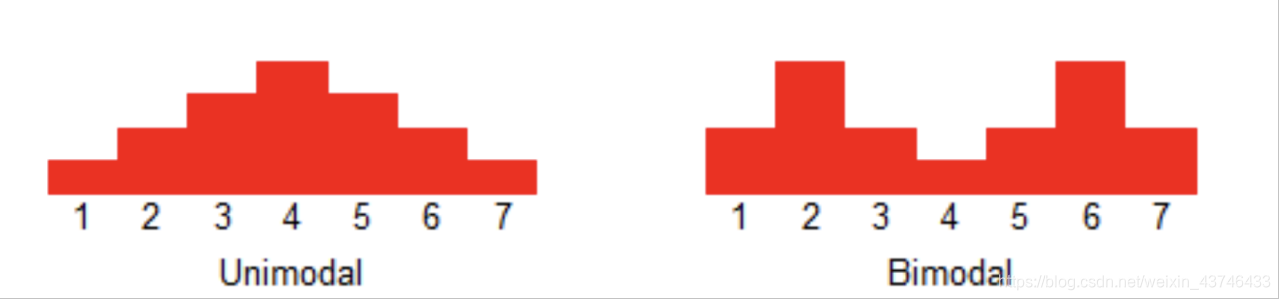
双峰分布: 95%的请求耗时在100ms内,5%的请求可能永远不会完成(长超时)。
对于监控不要只看mean,可以看看耗时分布统计,比如 95th,99th。
设置合理的超时,拒绝超长请求,或者当Server 不可用要主动失败。
超时决定着服务线程耗尽。
超时原因
- SLB 入口 Nginx 没配置超时导致连锁故障。
- 服务依赖的 DB 连接池漏配超时,导致请求阻塞,最终服务集体 OOM。
- 下游服务发版耗时增加,而上游服务配置超时过短,导致上游请求失败。
超时控制中间件
package middleware
import (
"context"
"net/http"
"time"
"github.com/gin-gonic/gin"
)
func TimeoutMiddleware(timeout time.Duration) func(c *gin.Context) {
return func(c *gin.Context) {
// wrap the request context with a timeout
ctx, cancel := context.WithTimeout(c.Request.Context(), timeout)
defer func() {
// check if context timeout was reached
if ctx.Err() == context.DeadlineExceeded {
// write response and abort the request
c.Writer.WriteHeader(http.StatusGatewayTimeout)
c.Abort()
}
//cancel to clear resources after finished
cancel()
}()
// replace request with context wrapped request
c.Request = c.Request.WithContext(ctx)
c.Next()
}
}
过载保护
常见限流的缺点
令牌桶算法
是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌。
桶中最多存放 b 个令牌,当桶满时,新添加的令牌被丢弃或拒绝。
当一个 n 个字节大小的数据包到达,将从桶中删除n 个令牌,接着数据包被发送到网络上。
如果桶中的令牌不足 n 个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。
token-bucket rate limit algorithm: /x/time/rate
漏斗桶/令牌桶确实能够保护系统不被拖垮, 但不管漏斗桶还是令牌桶, 其防护思路都是设定一个指标, 当超过该指标后就阻止或减少流量的继续进入,当系统负载降低到某一水平后则恢复流量的进入。但其通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情。
- 集群增加机器或者减少机器限流阈值是否要重新设置?
- 设置限流阈值的依据是什么?
- 人力运维成本是否过高?
- 当调用方反馈429时, 这个时候重新设置限流, 其实流量高峰已经过了重新评估限流是否有意义?
这些其实都是采用漏斗桶/令牌桶的缺点, 总体来说就是太被动, 不能快速适应流量变化。
因此我们需要一种自适应的限流算法,即: 过载保护,根据系统当前的负载自动丢弃流量。
过载保护策略
计算系统临近过载时的峰值吞吐作为限流的阈值来进行流量控制,达到系统保护。
- 服务器临近过载时,主动抛弃一定量的负载,目标是自保。
- 在系统稳定的前提下,保持系统的吞吐量。
常见做法:利特尔法则
- CPU、内存作为信号量进行节流。
- 队列管理: 队列长度、LIFO。
- 可控延迟算法: CoDel。
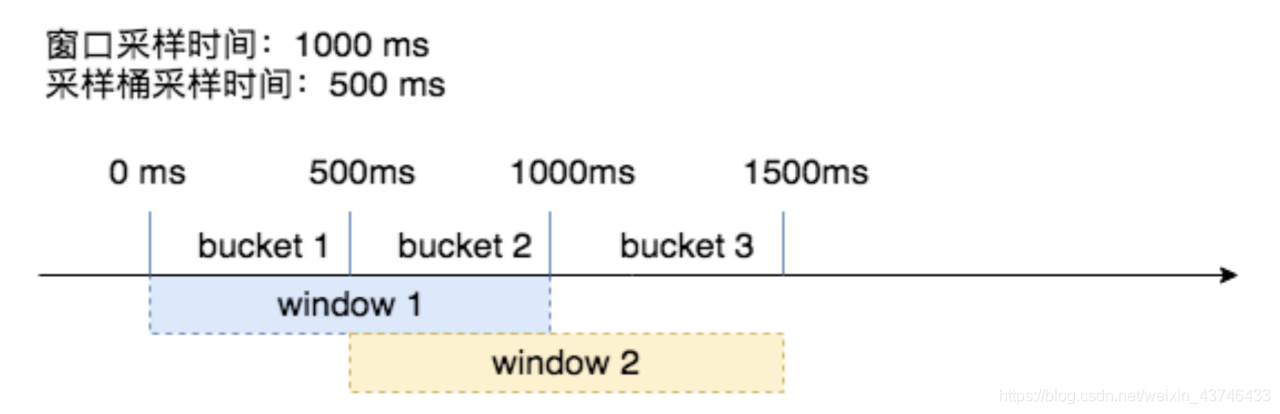
如何计算接近峰值时的系统吞吐?
CPU: 使用一个独立的线程采样,每隔 250ms 触发一次。在计算均值时,使用了简单滑动平均去除峰值的影响。
Inflight: 当前服务中正在进行的请求的数量。
Pass&RT: 最近5s,pass 为每100ms采样窗口内成功请求的数量,rt 为单个采样窗口中平均响应时间
限流
限流的目的就是为了防止恶意请求(如刷站)、恶意攻击,或者防止流量超出系统的峰值。
处理的原则就是限制流量穿透到后端的资源,保障资源的可用性。
举个例子:比如图13的QPS异常现象,请求流量超出平时晚高峰的好几倍,严重影响了服务的稳定性和后端DB的承载能力,为了保障DB资源的可用性,经排查是属于通过user_timeline接口的恶意刷站行为,此时,我们要做的就是封杀该接口,限制流量穿透到DB层。
- 对于恶意IP:可以使用Nginx deny进行屏蔽或采用iptables进行限制。
- 对于穿透到后端DB的请求流量:可以考虑用Nginx的limit模块处理或者Redis Lua脚本实现或者启用下面的过载保护策略。
- 对于恶意请求流量:只访问到Cache层或直接封杀。
限流是指在一段时间内,定义某个客户或应用可以接收或处理多少个请求的技术。例如,通过限流,你可以过滤掉产生流量峰值的客户和微服务,或者可以确保你的应用程序在自动扩展(Auto Scaling)失效前都不会出现过载的情况。
当自保护扛不住的时候,就需要分布式限流来处理
- 令牌桶、漏桶 针对单个节点,无法分布式限流。
- QPS 限流
不同的请求可能需要数量迥异的资源来处理。
某种静态 QPS 限流不是特别准。 - 给每个用户设置限制
全局过载发生时候,针对某些“异常”进行控制。
一定程度的“超卖”配额。 - 按照优先级丢弃。
- 拒绝请求也需要成本。
限流 - Case Study
- 二层缓存穿透、大量回源导致的核心服务故障。
- 异常客户端引起的服务故障(query of death)
- 请求放大。
- 资源数放大。
- 用户重试导致的大面积故障。
redis限流的问题
分布式限流,是为了控制某个应用全局的流量,而非真对单个节点纬度。
- 单个大流量的接口,使用 redis 容易产生热点。(并发扛不住)
- pre-request 模式对性能有一定影响,高频的网络往返。
思考: - 从获取单个 quota 升级成批量 quota。quota: 表示速率,获取后使用令牌桶算法来限制。

熔断
断路器(Circuit Breakers): 为了限制操作的持续时间,我们可以使用超时,超时可以防止挂起操作并保证系统可以响应。因为我们处于高度动态的环境中,几乎不可能确定在每种情况下都能正常工作的准确的时间限制。断路器以现实世界的电子元件命名,因为它们的行为是都是相同的。断路器在分布式系统中非常有用,因为重复的故障可能会导致雪球效应,并使整个系统崩溃。
一般是某个服务故障或者是异常引起的,类似现实世界中的‘保险丝’,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时,为了防止防止整个系统的故障,而采用了一些保护措施
熔断保证了下游服务在出错率达到阈值时,上游调用切换到降级方法,提供有损服务,避免服务的级联失败,影响整个系统的稳定性。
熔断的时机,取决于业务的实际场景和流量大小,不要过高,也不要过低;恢复的策略,其核心是恢复的速率,不要过快也不要过慢。一句废话,看需求。
- 服务依赖的资源出现大量错误。
- 某个用户超过资源配额时,后端任务会快速拒绝请求,返回“配额不足”的错误,但是拒绝回复仍然会消耗一定资源。有可能后端忙着不停发送拒绝请求,导致过载。
降级
服务器当压力剧增的时候,根据当前业务情况及流量,对一些服务和页面进行有策略的降级。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应。
抛弃高耦合逻辑,避免依赖服务性能下降导致雪崩。
降级本质为: 提供有损服务。
- UI 模块化,非核心模块降级。
- BFF 层聚合 API,模块降级。
- 页面上一次缓存副本。
- 默认值、热门推荐等。
- 流量拦截 + 定期数据缓存(过期副本策略)。
处理策略
- 页面降级、延迟服务、写/读降级、缓存降级
- 抛异常、返回约定协议、Mock 数据、Fallback 处理
通过降级回复来减少工作量,或者丢弃不重要的请求。而且需要了解哪些流量可以降级,并且有能力区分不同的请求。我们通常提供降低回复的质量来答复减少所需的计算量或者时间。我们自动降级通常需要考虑几个点:
- 确定具体采用哪个指标作为流量评估和优雅降级的决定性指标(如,CPU、延迟、队列长度、线程数量、错误等)。
- 当服务进入降级模式时,需要执行什么动作?
- 流量抛弃或者优雅降级应该在服务的哪一层实现?是否需要在整个服务的每一层都实现,还是可以选择某个高层面的关键节点来实现?
同时我们要考虑一下几点:
- 优雅降级不应该被经常触发 - 通常触发条件现实了容量规划的失误,或者是意外的负载。
- 演练,代码平时不会触发和使用,需要定期针对一小部分的流量进行演练,保证模式的正常。
应该足够简单。
服务熔断和服务降级比较
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
- 实现方式不太一样
重试
当请求返回错误(例: 配额不足、超时、内部错误等),对于 backend 部分节点过载的情况下,倾向于立刻重试,但是需要留意重试带来的流量放大:
- 限制重试次数和基于重试分布的策略(全局重试比率: 10%)。
- 随机化、指数型递增的重试周期: exponential ackoff + jitter。
- client 测记录重试次数直方图,传递到 server,进行分布判定,交由 server 判定拒绝。
- 只应该在失败的这层进行重试,当重试仍然失败,全局约定错误码“过载,无须重试”,避免级联重试。
重试 - Case Study
- Nginx upstream retry 过大,导致服务雪崩。
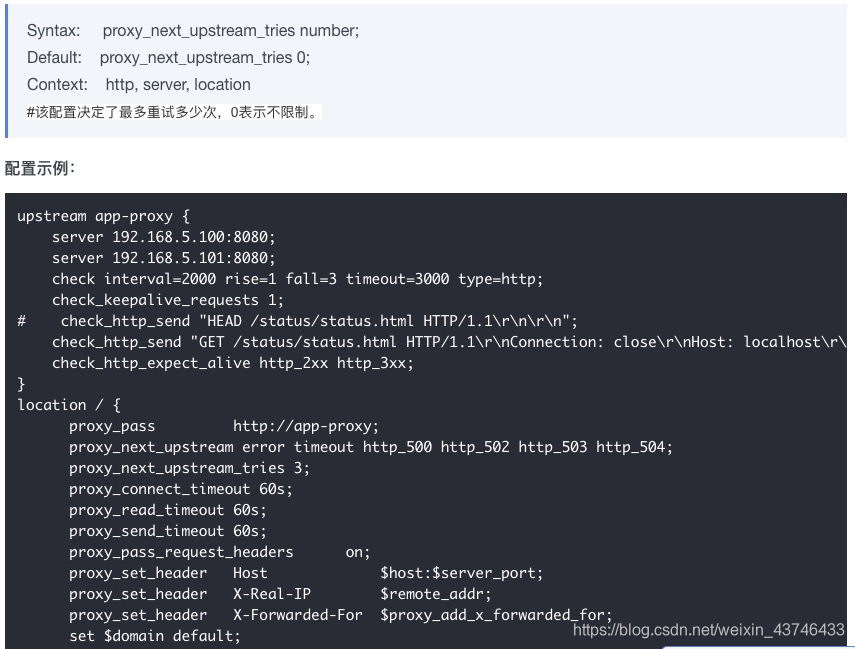
- 业务不幂等,导致的重试,数据重复。
- 唯一 ID: 根据业务生成一个全局唯一 ID,在调用接口时会传入该 ID,接口提供方会从相应的存储系统比如 redis 中去检索这个全局 ID 是否存在,如果存在则说明该操作已经执行过了,将拒绝本次服务请求;否则将相应该服务请求并将全局 ID 存入存储系统中,之后包含相同业务 ID 参数的请求将被拒绝。
- 去重表: 这种方法适用于在业务中有唯一标识的插入场景。比如在支付场景中,一个订单只会支付一次,可以建立一张去重表,将订单 ID 作为唯一索引。把支付并且写入支付单据到去重表放入一个事务中了,这样当出现重复支付时,数据库就会抛出唯一约束异常,操作就会回滚。这样保证了订单只会被支付一次。
- 多版本并发控制: 适合对更新请求作幂等性控制,比如要更新商品的名字,这是就可以在更新的接口中增加一个版本号来做幂等性控制。
- 多层级重试传递,放大流量引起雪崩。
负载均衡
数据中心内部的负载均衡
在理想情况下,某个服务的负载会完全均匀地分发给所有的后端任务。在任何时刻,最忙和最不忙的节点永远消耗同样数量的CPU。
目标:
- 均衡的流量分发。
- 可靠的识别异常节点。
- scale-out,增加同质节点扩容。
- 减少错误,提高可用性。
服务不可用 在使用etcd等注册中心不是会被摘掉吗?
有可能在调用服务时出错,而此服务于ETCD心跳保持正常
upstream circle_server {
...
server 192.168.0.88:8080 max_fails=1 fail_timeout=10;
...
}
原理解析:
max_fails=3 fail_timeout=30s代表在30秒内请求某一应用失败3次,认为该应用宕机,后等待30秒,这期间内不会再把新请求发送到宕机应用,而是直接发到正常的那一台,时间到后再有请求进来继续尝试连接宕机应用且仅尝试1次,如果还是失败,则继续等待30秒…以此循环,直到恢复。
最佳实践
- 变更管理:
70%的问题是由变更引起的,恢复可用代码并不总是坏事。 - 避免过载:
过载保护、流量调度等。 - 依赖管理:
任何依赖都可能故障,做 chaos monkey testing,注入故障测试。 - 优雅降级:
有损服务,避免核心链路依赖故障。 - 重试退避:
退让算法,冻结时间,API retry detail 控制策略。 - 超时控制:
进程内 + 服务间 超时控制。 - 极限压测 + 故障演练。
扩容 + 重启 + 消除有害流量。
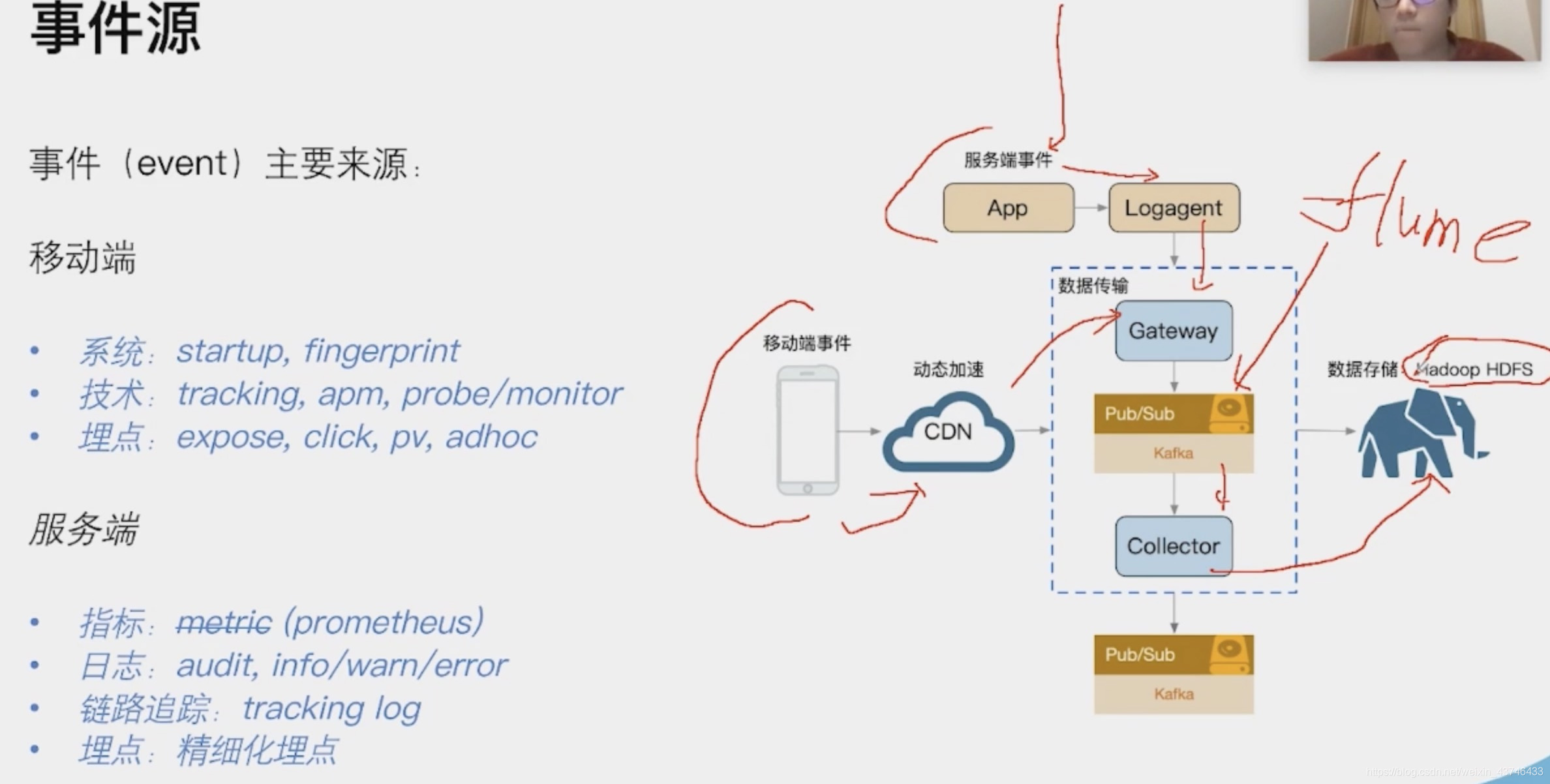
7. 播放历史架构设计
事件源 log
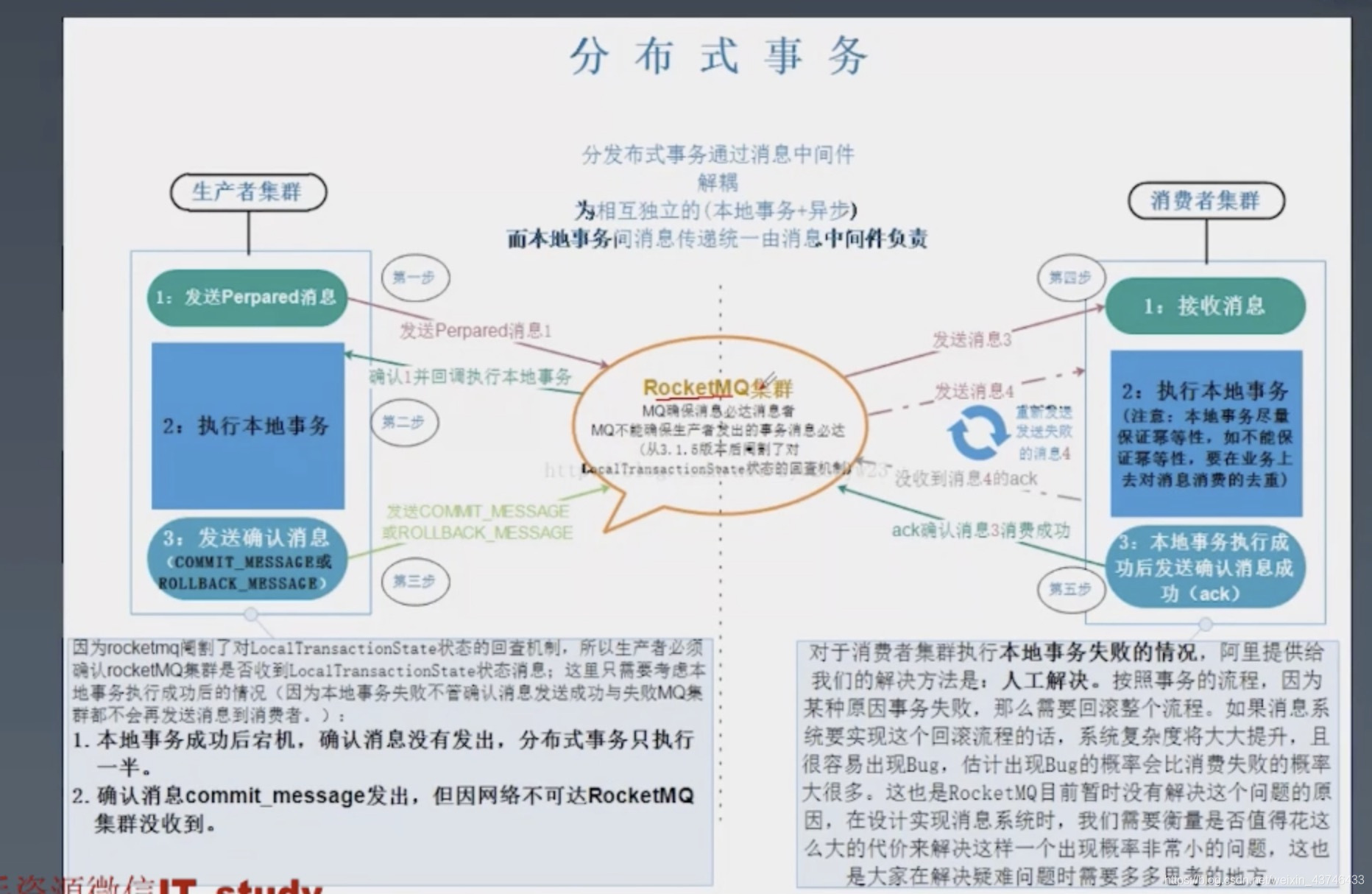
分布式事务
分布式事务顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合而成。
https://zhuanlan.zhihu.com/p/183753774
Best Effor 最大努力通知
其实我觉得本地消息表也可以算最大努力,事务消息也可以算最大努力。
就本地消息表来说会有后台任务定时去查看未完成的消息,然后去调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃。这其实算是最大努力了。
事务消息也是一样,当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者消费不了则会一直重试,到最后进入死信队列。其实这也算最大努力。
所以最大努力通知其实只是表明了一种柔性事务的思想:我已经尽力我最大的努力想达成事务的最终一致了。
适用于对时间不敏感的业务,例如短信通知。
支付场景

消息幂等性
在消费端一定要做幂等性处理

分布式事务实现
消息事务
RocketMQ 就很好的支持了消息事务,让我们来看一下如何通过消息实现事务。
第一步先给 Broker 发送事务消息即半消息,半消息不是说一半消息,而是这个消息对消费者来说不可见,然后发送成功后发送方再执行本地事务。
再根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令。
并且 RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功,然后执行 Commit 或者 RollBack 命令。
如果是 Commit 那么订阅方就能收到这条消息,然后再做对应的操作,做完了之后再消费这条消息即可。
如果是 RollBack 那么订阅方收不到这条消息,等于事务就没执行过。
可以看到通过 RocketMQ 还是比较容易实现的,RocketMQ 提供了事务消息的功能,我们只需要定义好事务反查接口即可。
2PC两阶段提交
在分布式系统中,为了让每个节点都能够感知到其他节点的事务执行状况,需要引入一个中心节点来统一处理所有节点的执行逻辑,这个中心节点叫做协调者(coordinator),被中心节点调度的其他业务节点叫做参与者(participant)。
2PC 是一种尽量保证强一致性的分布式事务,因此它是同步阻塞的,而同步阻塞就导致长久的资源锁定问题,总体而言效率低,并且存在单点故障问题,在极端条件下存在数据不一致的风险。
2PC将分布式事务分成了两个阶段,两个阶段分别为提交请求(投票)和提交(执行)。协调者根据参与者的响应来决定是否需要真正地执行事务,具体流程如下。
提交请求(投票)阶段
协调者向所有参与者发送prepare请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
参与者执行事务中包含的操作,并记录undo日志(用于回滚)和redo日志(用于重放),但不真正提交。
参与者向协调者返回事务操作的执行结果,执行成功返回yes,否则返回no。
提交(执行)阶段
分为成功与失败两种情况。
若所有参与者都返回yes,说明事务可以提交:
- 协调者向所有参与者发送commit请求。
- 参与者收到commit请求后,将事务真正地提交上去,并释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务成功完成。
若有参与者返回no或者超时未返回,说明事务中断,需要回滚:
- 协调者向所有参与者发送rollback请求。
- 参与者收到rollback请求后,根据undo日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务回滚完成。
MySQL想要准备事务的时候会先写redolog、binlog分成两个阶段。
-
两阶段提交的第一阶段 (prepare阶段):写rodo-log 并将其标记为prepare状态。
-
两阶段提交的第二阶段(commit阶段):写bin-log 并将其标记为commit状态。
第一阶段:中间件告诉各数据库节点,让它们开启XA事务,然后判断所有数据库节点是否已经处于prepare状态
第二阶段:中间件判断事务提交还是回滚的阶段。如果所有节点都prepare那就统一提交。但凡出现一个失败的节点,统一回滚。
2PC的缺点
1、协调者存在单点问题。如果协调者挂了,整个2PC逻辑就彻底不能运行。
2、执行过程是完全同步的。各参与者在等待其他参与者响应的过程中都处于阻塞状态,大并发下有性能问题。
3、仍然存在不一致风险。如果由于网络异常等意外导致只有部分参与者收到了commit请求,就会造成部分参与者提交了事务而其他参与者未提交的情况。

















 5678
5678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









