









目录
C++基础
- 全局与局部都定义一个静态变量会有什么样的结果
静态变量生存期为整个程序期间,但只能在函数内部被使用,当在函数内部使用全局已有的同名变量时,此时使用的局部静态变量。当在函数外部使用,使用的是外部的全局变量。
可以理解为全局静态变量a为a1,局部静态变量为a2,这两个是互相不会影响对方的值的。
继承
- 继承类型
当一个类派生自基类,该基类可以被继承为 public、protected 或 private 几种类型。继承类型是通过上面讲解的访问修饰符 access-specifier 来指定的。
我们几乎不使用 protected 或 private 继承,通常使用 public 继承。当使用不同类型的继承时,遵循以下几个规则:
- 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基类的公有和保护成员来访问。
- 保护继承(protected): 当一个类派生自保护基类时,基类的公有和保护成员将成为派生类的保护成员。
- 私有继承(private):当一个类派生自私有基类时,基类的公有和保护成员将成为派生类的私有成员。
- 子类继承父类时,构造函数和析构函数的顺序是什么样的?
先调用父类的构造函数,如果成员变量中有类再调用该成员的构造函数,最后调用自己的构造函数。(先父母后客人最后自己)
析构函数的调用顺序与构造函数相反
- 执行自身的析构函数
- 执行成员变量的析构函数
- 执行父类的析构函数
- 菱形继承的问题?

会存在二义性的问题,子类的两个父类会对公共基类的成员都继承,那子类调用公共基类的成员则会有二义性。
解决方法,子类的两个父类继承时采用virtual修饰,这样就只会创造一份公共基类的实例,不会造成二义性。
举例:
解决方法:


- 移动构造函数(考的很少,可忽略)
(150条消息) C++ 移动构造函数详解_a只如初见的博客-CSDN博客_移动构造函数
移动构造是C++11标准中提供的一种新的构造方法。
移动构造可以减少不必要的复制,带来性能上的提升。
有些复制构造是必要的,我们确实需要另外一个副本;而有些复制构造是不必要的,我们可能只是希望这个对象换个地方,移动一下而已。
在C++11之前,如果要将源对象的状态转移到目标对象只能通过复制。
而现在在某些情况下,我们没有必要复制对象——只需要移动它们。
如果临时对象即将消亡,并且它里面的资源是需要被再利用的,这个时候就没有必要去复制它产生一个副本,然后析构这个临时对象。可以将临时对象它的原本的资源直接转给构造的对象即可了。
移动构造是这样的:
就是让这个临时对象它原本控制的内存的空间转移给构造出来的对象,这样就相当于把它移动过去了。
从下图中可以看到,原本由临时对象申请的堆内存,由新建对象a接管,临时对象不再指向该堆内存。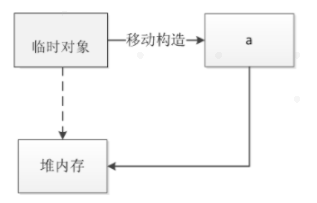
具体到代码上的实现如下:
移动构造函数接收的参数必须是自身返回类型的右值引用,这样保证使用右值进行构造时会调用移动构造函数而不是别的拷贝构造函数。
如下图用getNum()这个函数返回的即将消亡的变量去构造,此时getNum()就是个右值。在调用时就会使用移动构造函数。
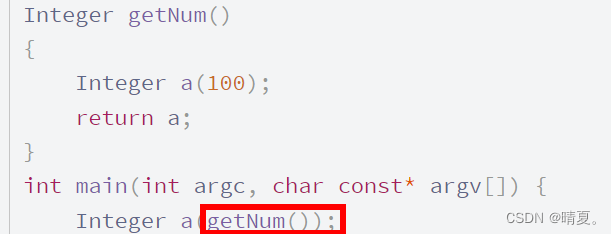
然后将参数的内存地址空间由自己接管。
并将原参数的内存空间地址置空(防止该参数消亡时去释放它所指向的空间,即防止此时自己所指向的空间也被释放,事实上这就是浅拷贝构造函数存在的问题)

例子完整代码如下:
#include <iostream>
#include <string>
using namespace std;
class Integer {
private:
int* m_ptr;
public:
Integer(int value)
: m_ptr(new int(value)) {
cout << "Call Integer(int value)有参" << endl;
}
Integer(const Integer& source)
: m_ptr(new int(*source.m_ptr)) {
cout << "Call Integer(const Integer& source)拷贝" << endl;
}
Integer(Integer&& source)
: m_ptr(source.m_ptr) {
source.m_ptr= nullptr;
cout << "Call Integer(Integer&& source)移动" << endl;
}
~Integer() {
cout << "Call ~Integer()析构" << endl;
delete m_ptr;
}
int GetValue(void) { return *m_ptr; }
};
Integer getNum()
{
Integer a(100);
return a;
}
int main(int argc, char const* argv[]) {
Integer a(getNum());
cout << "a=" << a.GetValue() << endl;
cout << "-----------------" << endl;
Integer temp(10000);
Integer b(temp);
cout << "b=" << b.GetValue() << endl;
cout << "-----------------" << endl;
return 0;
}
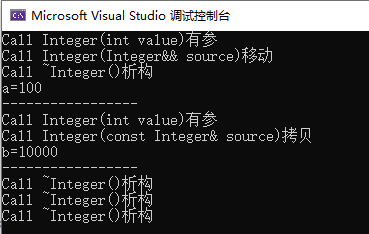
可以看到上图如果使用右值去构造时,调用的则是移动构造函数,使用左值构造时,调用的是拷贝构造函数。
子类父类指针问题
在语法上,父类指针可以指向子类,子类通过强制类型转换(不安全)也能指向父类。通过指针操作时,判断指针访问了谁的成员,就是看原型指针的类型是什么,访问的就是该类型的成员。需要特别注意的是:
(1)定义父类类型的指针p,指向子类类型(地址值为子类类型指针):这种做法是安全的,因为指针p是父类类型,只能访问父类中定义的成员,而子类继承了父类所有的成员,所以指针p不会出现非法访问。如果此时,p想访问子类特有函数,在语法上不被允许,因为p是父类类型指针,但可以在父类中声明虚函数,然后在子类重写,那么此时p在调用虚函数时,即可访问到子类重写的函数。
(2)定义子类类型的指针t,指向父类类型(地址值为父类类型指针):这种做法语法上不允许,但能通过强制类型转换(非常不安全)让语法正确。因为t是子类类型指针,能访问子类定义的所有成员,但其原型却是一个父类指针,若访问的刚好是父类成员,可能不会有问题,倘若访问的是子类特有成员,则会出现非法访问,这种指向是非常不推荐的。
class Base
{
void BaseFunc() {}
virtual void ChildSpecial() {}
};
class Child : public Base
{
void ChildFunc() {}
void ChildSpecial() override { std::cout << "Call Child Special Func."; }
};
Child* pChild = new Child();
// 安全,pBase只能访问Base内定义的成员,而pChild继承了Base的所有成员,故不会出现非法访问
Base* pBase = pChild;
// 想用pBase访问Child特有函数,可在Base中定义虚函数,然后在子类重写,即实现了父类指针调用子类特有函数
pBase->ChildSpecial(); // 打印 Call Child Special Func.
Base* tBase = new Base();
Child* tChild = tBase; // 语法错误,不允许的转化
// 语法上允许,但不安全,tChild访问的是Base中不存在的函数时,会出现非法访问,不推荐这么做
Child* tChild = static_cast<Child*>(tBase);- 子类的指针指向父类,它的内存会发生改变吗?
重载、重写(覆盖)、隐藏(重定义)
首先这三种,函数名都必须相同。
重载:参数必须不同,返回值可以不同。都在类内。调用时根据参数不的同,调用不同的同名函数。
重写(覆盖):又称覆盖override,在c++中必须给基类的函数添加virtual,然后子类重写该虚函数。一般用于实现,使用父类指针去指向不同的子类对象时,可以通过父类指针调用子类中重写的函数,以实现多态。
(返回值、参数必须完全相同,否则会变成隐藏。)
具体:
隐藏(重定义):
子类存在和父类一样的同名函数或者变量,此时子类会屏蔽父类的同名变量/函数。
析构函数
析构函数(destructor)是成员函数的一种,它的名字与类名相同,但前面要加~,没有参数和返回值。
析构函数在对象消亡时即自动被调用。可以定义析构函数在对象消亡前做善后工作。
如果没有使用指针类型的变量,则使用默认的析构函数也没什么问题。
因为,堆上分配的空间必须由用户自己来管理,如果不释放,就会造成内存泄漏。而栈上分配的空间是由编译器来管理的,具有函数作用域,出了函数作用域后系统会自动回收,不由用户管理,所以不用用户显式释放空间。也就是会自动调用析构函数。而使用new声明的需要我们手动用delete去释放它。
例如:
#include<iostream>
using namespace std;
class CDemo {
public:
~CDemo() { //析构函数
cout << "Destructor called"<<endl;
}
};
int main() {
CDemo* pTest = new CDemo; //构造函数调用
delete pTest; //析构函数调用
}调用delete会导致该对象消亡,而对象消亡时会自动调用析构函数。
如果对象的成员变量中含有指针类型的变量,需要在析构函数里也调用delete,这样才能保证该对象运行期间申请的空间能够得到释放:
class String{
private:
char* p;
public:
String(int n);
~String();
};
String::~String(){
delete[] p;
}
String::String(int n){
p = new char[n];
}- A a和A *a = new A()有什么区别?什么时候会析构?
A a的a是在栈上申请的空间,A a 在其函数作用域结束时,会自动释放内存。
new是在堆上分配内存,它需要用delete释放,否则会造成内存泄漏。
- 析构函数和继承的关系
创建一个子类对象时,先调用父类的构造函数,再调用子类的构造函数。而析构的顺序与之相反,先调用子类的析构函数,再调用父类的析构函数。
- 虚析构函数
具体代码示例看此处:(291条消息) 虚析构函数详解_-CSDN博客_虚析构函数
当基类指针指向子类对象时候,虚函数能实现运行时多态(多态指:同一个接口的不同实现方式)
虚析构函数:当基类指针指向子类对象的时候,需要把基类的析构函数设置成虚析构,防止内存泄露。
原因:因为,如果基类析构函数不定义为虚析构,当我们用基类指针指向子类对象的时候,只会调用基类析构函数,而不会调用子类的析构函数了。这样的话,如果我们用多态的特性,调用了子类中重写父类虚函数的函数,假如里面有new出来的变量,则会导致无法正常释放申请的内存。
- 为什么要自己定义拷贝构造函数?什么是深拷贝和浅拷贝?
(1)拷贝构造函数的作用就是定义了当我们用同类型的另外一个对象初始化本对象的时候做了什么,在某些情况下,如果我们不自己定义拷贝构造函数,使用默认的拷贝构造函数,就会出错。比如一个类里面有一个指针,如果使用默认的拷贝构造函数,会将指针拷贝过去,即两个指针指向同个对象,那么其中一个类对象析构之后,这个指针也会被delete掉,那么另一个类里面的指针就会变成野指针(悬浮指针);
(2)这也正是深拷贝和浅拷贝的区别,浅拷贝只是简单直接地复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。 但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
- 如果想将某个类用作基类,为什么该类必须定义而非声明?
如果想将某个类用作基类,该类必须被定义而非仅仅声明。这是因为在 C++ 中,派生类需要知道其基类的成员变量和成员函数,以便正确地访问它们和使用它们。
如果只有类的声明而没有定义,则编译器无法确定基类中的成员变量和成员函数的具体实现细节。在派生类中访问基类的成员时,编译器就会发生错误或者警告。
例如,下面的代码会编译失败:
// 声明一个名为 Base 的类
class Base;
// 派生一个名为 Derived 的类,并将 Base 作为其基类
class Derived : public Base {
public:
void print() {
cout << "Derived" << endl;
}
};
int main() {
Derived d; // 编译失败:Base 未定义
d.print();
return 0;
}多态、虚函数(⭐⭐⭐)
- 什么是多态?C++的多态是如何实现的?
答:所谓多态,就是同一个函数名具有多种状态,或者说一个接口具有不同的行为。
C++的多态分为编译时多态和运行时多态:
- 编译时多态也称为为静态联编,通过重载和模板来实现,在编译时确定。
- 运行时多态称为动态联编,通过继承和虚函数来实现,在运行时才确定。
- 多态、虚函数的实现机制是什么?
虚函数是通过虚函数表来实现的,虚函数表包含了一个类(所有)的虚函数的地址,在有虚函数的对象中,它内存空间的头部会有一个虚函数表指针(虚表指针),用来指向这个对象对应的类的虚表。当子类对象对父类虚函数进行重写的时候,虚函数表中的相应虚函数地址会发生改变,改写成这个虚函数的地址。
当我们用一个父类的指针来指向子类对象,然后用该指针去调用子类的虚函数时,然后会去该子类对应的虚函数表,然后找到对应的虚函数,即可实现多态的功能。
- 虚函数表原理的详解
每个类会含有一个虚函数表,而虚表是一个指针数组,其元素是虚函数的指针,每个元素对应一个虚函数的函数指针。虚表是属于类的,同一个类的所有对象都使用同一个虚表。
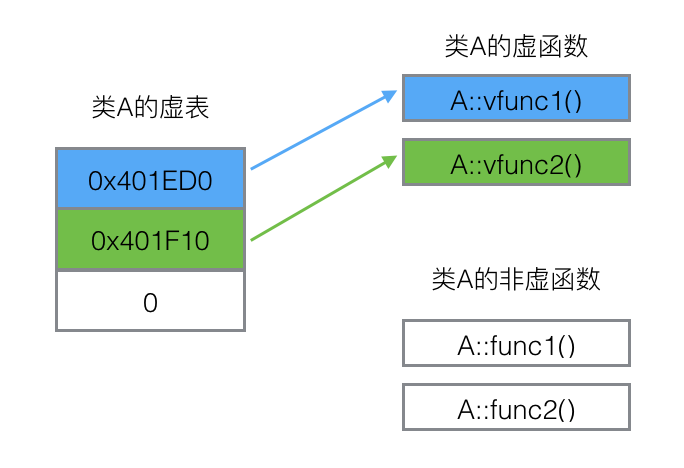
而每个对象会有一个虚表指针,对象内部包含一个虚表的指针,来指向自己所使用的虚表。
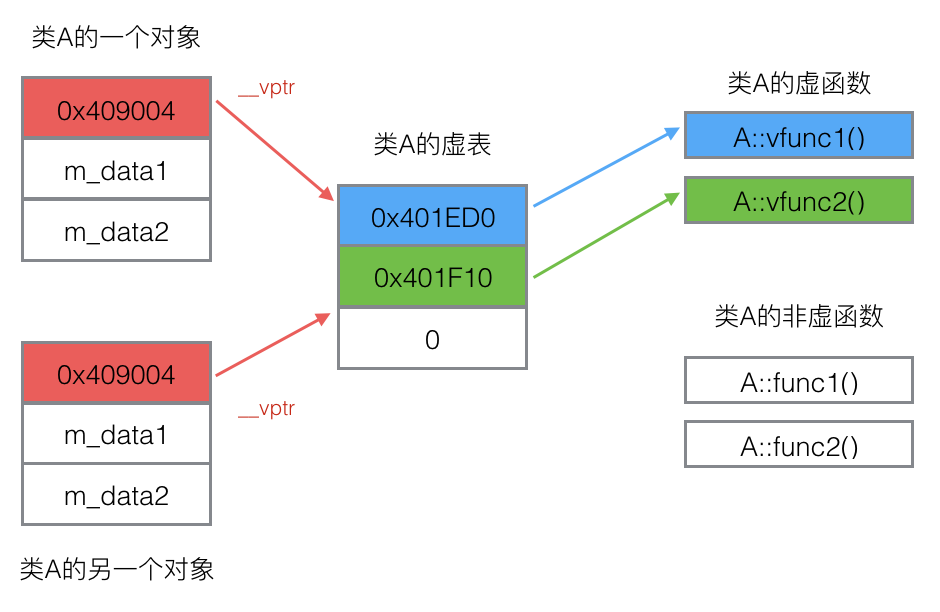
下面给一个具体的继承的虚函数及其虚表的实例:
class A {
public:
virtual void vfunc1();
virtual void vfunc2();
void func1();
void func2();
private:
int m_data1, m_data2;
};
class B : public A {
public:
virtual void vfunc1();
void func1();
private:
int m_data3;
};
class C: public B {
public:
virtual void vfunc2();
void func2();
private:
int m_data1, m_data4;
};类A是基类,类B继承类A,类C又继承类B。类A,类B,类C,其对象模型如下图3所示。
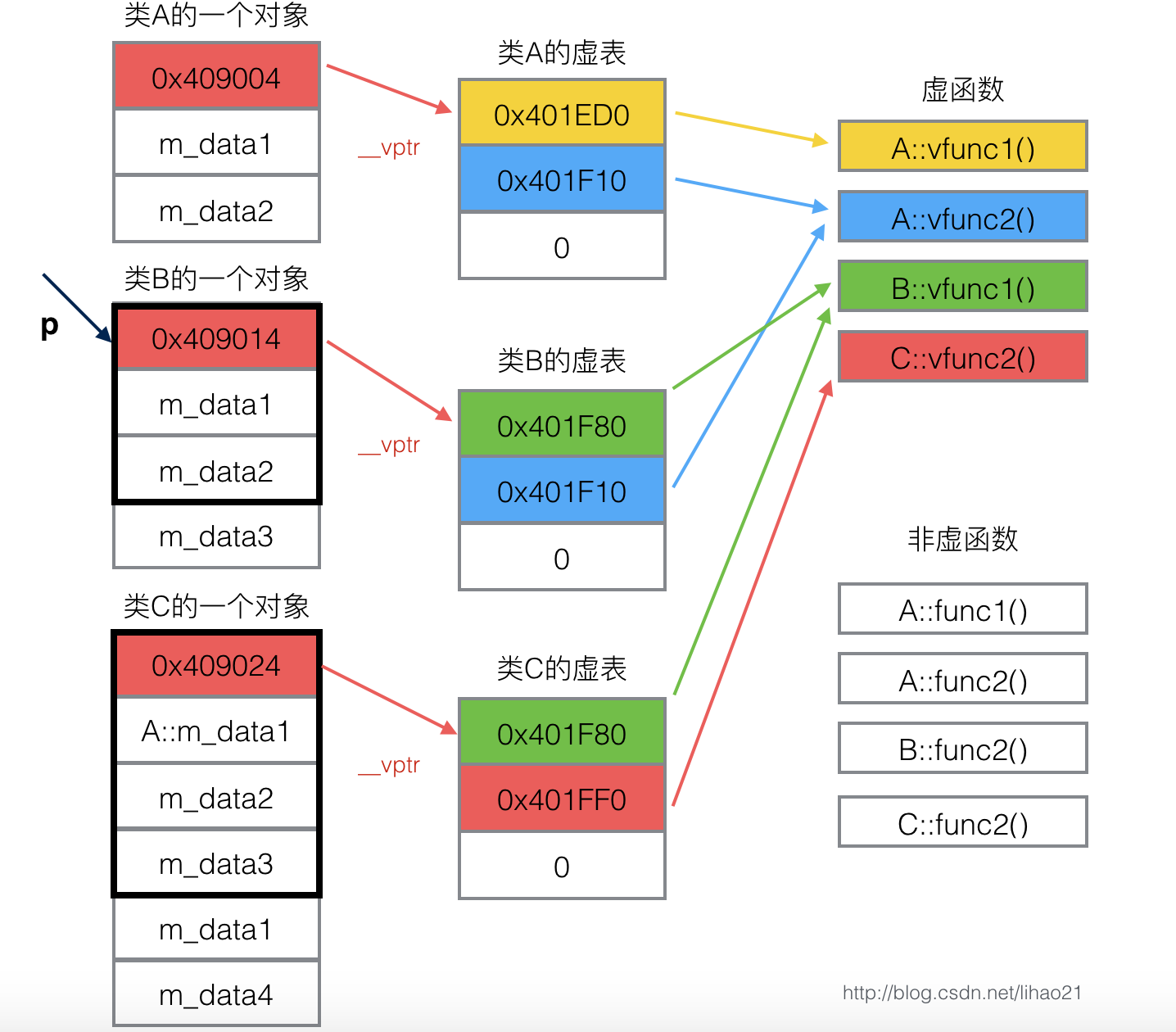
动态绑定过程:具体可以看上面那篇博客。
下面这里代码中,类B继承了类A并重写了A的虚函数。然后用基类的指针指向子类并调用子类的函数。
int main()
{
B bObject;
A *p = & bObject;
p->vfunc1();
}程序在执行p->vfunc1()时,会发现p是个指针,且调用的函数是虚函数,接下来便会进行以下的步骤。
首先,根据虚表指针p->__vptr来访问对象bObject对应的虚表。(虽然指针p是基类A*类型,但是*__vptr也是基类的一部分,所以可以通过p->__vptr可以访问到对象对应的虚表。)
然后,在虚表中查找所调用的函数对应的条目。(由于虚表在编译阶段就可以构造出来了,所以可以根据所调用的函数定位到虚表中的对应条目。对于 p->vfunc1()的调用,B vtbl的第一项即是vfunc1对应的条目。 )
最后,根据虚表中找到的函数指针,调用函数。从图3可以看到,B vtbl的第一项指向B::vfunc1(),所以 p->vfunc1()实质会调用B::vfunc1()函数。
- 虚函数调用是在编译时确定还是运行时确定的?如何确定调用哪个函数?
答:运行时确定,通过查找虚函数表中的函数地址确定。
更正:此处说法不严谨,应该是只有通过指针或者引用的方式调用虚函数是运行时确定,通过值调用的虚函数是编译期就可以确定的,参考这篇文章,虚函数一定是运行期才绑定么? - 知乎 (zhihu.com)
- 虚函数是存在类中还是类对象中(即是否共享虚表)?
答:存在类中,不同的类对象共享一张虚函数表(为了节省内存空间)。
- 什么是动态绑定?
是指与给定的过程调用相关联的代码,只有在运行期才可知的一种绑定,他是多态实现的具体形式。
在c++中就是指使用父类的指针或者引用调用虚函数时,这个调用可能在运行时,绑定到不同的子类中,产生不同的行为。
- 纯虚函数?

- 构造函数和析构函数能否使用虚函数?
构造函数不能是虚函数,而构造函数是在创建对象时自动调用的,不可能通过父类的指针或者引用去调用,因此规定构造函数不能是虚函数。
如果成员变量中包含指针变量,析构函数就必须使用虚函数。
在多态的时候,比如基类的指针指向派生类的对象,如果删除该指针delete []p,就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。
如果析构函数不被声明成虚函数,此时则只会调用基类的析构函数,这时候就会导致只清理了派生类从基类继承过来的资源,而派生类自己独有的资源却没有被清理。
- 有虚函数的类的大小是多大?
包含虚函数的类的大小会额外多出一个虚表指针的大小,这个指针在32位系统是4字节,在64位的系统下是8字节。
- 那虚函数表的大小会算在类中吗?
虚函数表的大小不会算在类的大小中。虚函数表是一个指针数组,这个数组在编译阶段就已经确定了,存储在只读数据段,而不是对象实例中。
- C++和C分别使用什么函数来做内存的分配和释放?有什么区别?
总结new/delete和malloc/free的区别和联系:
1. 它们都是动态管理内存的入口。
2. malloc/free是C/C++标准库的函数,new/delete是C++操作符。
3. malloc/free只是动态分配内存空间/释放空间。而new/delete除了分配空间还会调用构造
析构函数进行初始化与清理(清理成员)。
4. malloc/free需要手动计算类型大小且返回值为void*,new/delete可自己计算类型的大小
对应类型的指针。
5.new/delete的底层调用了malloc/free。
6.malloc/free申请空间后得判空,new/delete则不需要。
7.new直接跟类型,malloc跟字节数个数。
类型转换(⭐⭐)
数据类型转换:
隐式转换:
高精度和低精度的数据相加会发生转换,结果为高精度:

强制转换:
下面这种情况导致精度丢失

下面这种情况导致数据截断:

- 四种类型转换
(1)const_cast: 把const属性去掉,即将const转换为非const(也可以反过来),const_cast只能用于指针或引用,并且只能改变对象的底层const(顶层const,本身是const,底层const,指向对象const);
(2)static_cast: 隐式类型转换,可以实现C++中内置基本数据类型之间的相互转换,enum、struct、 int、char、float等,能进行类层次间的向上类型转换(子类转父类)和向下类型转换(向下不安全,因为没有进行动态类型检查)。它不能进行无关类型(如非基类和子类)指针之间的转换,也不能作用包含底层const的对象;
(3)dynamic_cast:动态类型转换,用于将基类的指针或引用安全地转换成派生类的指针或引用(也可以向上转换),若指针转换失败返回NULL,dynamic_cast是在运行时进行安全性检查;使用dynamic_cast父类一定要有虚函数,否则编译不通过;
(4)reinterpret_cast:reinterpret是重新解释的意思,此标识符的意思即为将数据的二进制形式重新解释,但是不改变其值,有着和C风格的强制转换同样的能力。它可以转化任何内置的数据类型为其他任何的数据类型,也可以转化任何指针类型为其他的类型。它甚至可以转化内置的数据类型为指针,无须考虑类型安全或者常量的情形。不到万不得已绝对不用(比较不安全)
第二第三点的举例:
class Base { public: int _i; virtual void foo() {}; //基类必须有虚函数。保持多态特性才能使用dynamic_cast }; class Sub : public Base { public: char *_name[100]; void Bar() {}; }; int main() { Base* pb = new Sub(); Sub* ps1 = static_cast<Sub*>(pb); //子类->父类,静态类型转换,正确但不推荐 Sub* ps2 = dynamic_cast<Sub*>(pb); //子类->父类,动态类型转换,正确 Base* pb2 = new Base(); Sub* ps21 = static_cast<Sub*>(pb2); //父类->子类,静态类型转换,危险!访问子类_name成员越界 Sub* ps22 = dynamic_cast<Sub*>(pb2);//父类->子类,动态类型转换,安全,但结果为NULL return 0; }
总结:
去const属性用const_cast
基本类型转换用static_cast,可以用于子类转父类但不推荐
多态类之间的类型转换用dynamic_cast,将基类的指针或引用安全地转换成派生类的指针或引用
不同类型的指针类型转换用reinterpret_cast
- static_cast和dynamic_cast的异同点?
答:二者都会做类型安全检查,只是static_cast在编译期进行类型检查,dynamic_cast在运行期进行类型检查。后者需要父类具备虚函数,而前者不需要。
智能指针(⭐)
详细可以见这篇文章:
(203条消息) 智能指针用法及其代码详解_晴夏。的博客-CSDN博客![]() https://blog.csdn.net/weixin_43757333/article/details/124449079
https://blog.csdn.net/weixin_43757333/article/details/124449079
智能指针主要解决一个内存泄露的问题,解决对象重复释放的问题。,它可以自动地释放内存空间,比如说new完之后忘记delete了。智能指针分为共享指针(shared_ptr), 独占指针(unique_ptr)和弱指针(weak_ptr)。
(因为它本身是一个类,当函数结束的时候会调用析构函数,并由析构函数释放内存空间。)
- shared_ptr的实现原理是什么?构造函数、拷贝构造函数和赋值运算符怎么写?shared_ptr是不是线程安全的?
(1)shared_ptr是通过引用计数机制实现的,引用计数存储着有几个shared_ptr指向相同的对象,当引用计数下降至0时就会自动销毁这个对象;
(2)具体实现:
1)构造函数:将指针指向该对象,引用计数置为1;
2)拷贝构造函数:将指针指向该对象,引用计数++;
3)赋值运算符:=号左边的shared_ptr的引用计数-1,右边的shared_ptr的引用计数+1,如果左边的引用技术降为0,还要销毁shared_ptr指向对象,释放内存空间。
(3)shared_ptr的引用计数本身是安全且无锁的,但是它指向的对象的读写则不是,因此可以说shared_ptr不是线程安全的
unique_ptr:
保证每时每刻只有一个指针指向
weak_ptr:
weak_ptr是用来解决shared_ptr相互引用时的死锁问题,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
各种关键字
- const作用?
const修饰符用来定义常量,具有不可变性。在类中,被const修饰的成员函数,不能修改类中的数据成员;
- 指针常量和常量指针?
补充一点:
const int* p;
int const* p;
int* const p;
前两个中const形容的是int,代表指针类型是const int的,意思是指向的对象是const int的,意味着指向的对象是常量,而指针p自身可以改变。即常量指针
第三个,const形容的是指针p,代表指针不能变。指针类型是int,代表指向的对象就是可变的int型变量。即指针常量。
- static的作用?static变量什么时候初始化?
static即静态的意思,可以对变量和函数进行修饰。分三种情况:
(1)当用于文件作用域的时候(即在.h/.cpp文件中直接修饰变量和函数),static意味着这些变量和函数只在本文件可见,其他文件是看不到也无法使用的,可以避免重定义的问题。
(2)当用于函数作用域时,即作为局部静态变量时,意味着这个变量是全局的,只会进行一次初始化,不会在每次调用时进行重置,但只在这个函数内可见。
(3)当用于类的声明时,即静态数据成员和静态成员函数,static表示这些数据和函数是所有类对象共享的一种属性,而非每个类对象独有。
(4)static变量在类的声明中不占用内存,定义时要分配空间,不能在类声明中初始化,必须在类定义体外部初始化。
- extern的作用?
答:当它与"C"一起连用时,如: extern "C" void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的;当它作为一个对函数或者全局变量的外部声明,提示编译器遇到此变量或函数时,在其它模块中寻找其定义。
- auto和deltype的作用和区别?
答:用于实现类型自动推导,让编译器来操心变量的类型;auto不能用于函数传参和推导数组类型,但deltype可以解决这个问题。
- typedef的作用
定义一种类型的别名,而不只是简单的宏替换。可以用作同时声明指针型的多个对象。
比如:
char* pa, pb; // 这多数不符合我们的意图,它只声明了一个指向字符变量的指针, 和一个字符变量;以下则可行:
typedef char* PCHAR; // 一般用大写 PCHAR pa, pb; // 可行,同时声明了两个指向字符变量的指针虽然:
char *pa, *pb;也可行,但相对来说没有用typedef的形式直观,尤其在需要大量指针的地方,typedef的方式更省事。
左值右值,右值引用(就没问过)
- 左值右值是什么?
可以取地址的,有名字的,非临时的就是左值;
不能取地址的,没有名字的,临时的就是右值;
- 右值引用的作用?
参考文章:c++ 左值引用与右值引用 - 知乎 (zhihu.com)
举例:
先看一下传统的左值引用。
int a = 10; int &b = a; // 定义一个左值引用变量 b = 20; // 通过左值引用修改引用内存的值左值引用在汇编层面其实和普通的指针是一样的;定义引用变量必须初始化,因为引用其实就是一个别名,需要告诉编译器定义的是谁的引用。
int &var = 10;上述代码是无法编译通过的,因为10无法进行取地址操作,无法对一个立即数取地址,因为立即数并没有在内存中存储,而是存储在寄存器中,可以通过下述方法解决:
const int &var = 10;使用常引用来引用常量数字10,因为此刻内存上产生了临时变量保存了10,这个临时变量是可以进行取地址操作的,因此var引用的其实是这个临时变量,相当于下面的操作:
const int temp = 10; const int &var = temp;根据上述分析,得出如下结论:
- 左值引用要求右边的值必须能够取地址,如果无法取地址,可以用常引用;
但使用常引用后,我们只能通过引用来读取数据,无法去修改数据,因为其被const修饰成常量引用了。那么C++11 引入了右值引用的概念,使用右值引用能够很好的解决这个问题。
右值引用可以进行读写操作,而常引用只能进行读操作。
定义右值引用的格式如下:
类型 && 引用名 = 右值表达式;右值引用是C++ 11新增的特性,所以C++ 98的引用为左值引用。右值引用用来绑定到右值,绑定到右值以后本来会被销毁的右值的生存期会延长至与绑定到它的右值引用的生存期。
int &&var = 10;右值引用的存在并不是为了取代左值引用,而是充分利用右值(特别是临时对象)的构造来减少对象构造和析构操作以达到提高效率的目的。
使用右值引用的移动操作可以避免无谓的拷贝,充分利用右值(特别是临时对象)的构造来减少对象构造和析构操作以达到提高效率的目的。,提高性能。
右值引用用来绑定到右值,绑定到右值以后本来会被销毁的右值的生存期会延长至与绑定到它的右值引用的生存期。
- 右值引用只能对右值进行引用吗?能不能对左值引用?
右值引用独立于左值和右值。意思是右值引用类型的变量可能是左值也可能是右值。比如:
内联函数与宏
- 内联函数有什么作用?存不存在什么缺点?
(1)作用是使编译器在函数调用点上展开函数,可以避免函数调用的开销;
(2)内联函数的缺点是可能造成代码膨胀,尤其是递归的函数,会造成大量内存开销,exe太大,占用CPU资源。此外,内联函数不方便调试,每次修改会重新编译头文件,增加编译时间。
- 为什么不能把所有的函数写成内联函数?
内联函数以代码复杂为代价,它以省去函数调用的开销来提高执行效率。所以一方面如果内联函数体内代码执行时间相比函数调用开销较大,则没有太大的意义;另一方面每一处内联函数的调用都要复制代码,消耗更多的内存空间,因此以下情况不宜使用内联函数:
-
函数体内的代码比较长,将导致内存消耗代价
-
函数体内有循环,函数执行时间要比函数调用开销大
- 宏是什么,有什么用法?
宏在预处理阶段,对标识符进行文本替换。
不带参数的宏定义:
// 不带参数的宏定义
#define MAX 10带参数的宏定义
带参数的宏定义的一般形式如下:
#define <宏名>(<参数表>) <宏体>
其中, <宏名>是一个标识符,<参数表>中的参数可以是一个,也可以是多个,视具体情况而定,当有多个参数的时候,每个参数之间用逗号分隔。<宏体>是被替换用的字符串,宏体中的字符串是由参数表中的各个参数组成的表达式。例如:
#define SUB(a,b) a-b
如果在程序中出现如下语句:
result=SUB(2, 3);
则被替换为:
result=2-3;
(注意,宏仅仅是会进行替换,不会改变运算时的相对顺序)
宏的一个不容易被替换的特性是:宏函数中的 # 和 ##
在宏函数里,当#加在一个参数的前面,它会被自动转换为那个给予的参数名的字符串
#define PRINTOUT_VALUE(var) std::cout<<"The value of "<<#var<<" is: "<<var<<std::endl;(void(0))
在宏函数里,当#加在一个参数的前面,它会被自动转换为那个给予的参数名的字符串
这个时候如果我们有
int a = 3;
PRINTOUT_VALUE(a);
我们运行就能看到
The value of a is: 3 两个双井号包裹住的中间的部分会从参数的形式转换成代码。
#define CALL_FUNC(func_num) func_##func_num##()
如果我这样写
CALL_FUNC(1);
这个时候编译器会把它解析成
func_1(); - 宏的好处是什么?
- 程序会更易读。
- 程序会更易于修改。
- define和const定义常量的区别
宏(macro)和const都是C++中常用的常量定义方式,但它们有一些区别。
-
宏定义是在预处理阶段进行替换,而const定义是在编译阶段处理的。宏定义的替换是在编译前进行的,可以将宏定义展开成任意的代码,而const变量在编译阶段会被编译器处理成实际的内存地址,因此const变量是有类型的。
-
宏定义没有作用域,而const变量有作用域。宏定义在定义后,直到文件结束都是可用的,而const变量只在定义的作用域内可见。
-
宏定义没有类型检查,而const变量有类型检查。宏定义只是简单地进行字符串替换,编译器不会对替换后的代码进行任何类型检查。而const变量在定义时必须指定类型,编译器会对类型进行检查。
-
宏定义可以被修改,而const变量是只读的。宏定义只是简单的文本替换,可以通过再次定义来修改宏的值,而const变量是不可修改的。
综上所述,const定义的常量更加安全、可读性更高,并且具有类型检查等优点。而宏定义的常量更加灵活,可以用于宏定义、条件编译等场景。在编程中,我们应该根据具体情况选择合适的常量定义方式。
- 内联函数和宏有什么区别,有了宏为什么还需要内联函数?
(1)define宏命令是在预处理阶段对命令进行替换,inline是在编译阶段在函数调用点处直接展开函数,节省了函数调用的开销;
(2)define的话是不会对参数的类型进行检查的,因此会出现类型安全的问题,比如定义一个max命令,但是传递的时候可能会传递一个整数和一个字符串,就会出错,但是内联函数在编译阶段会进行类型检查;
- define的用法?define和const有什么区别?
define就是用一个表达式去替换另外一个表达式,但是不做类型检查。当对源程序作编译时,将先由预处理程序进行宏代换,即用表达式去置换所有的宏名M,然后再进行编译。
而const是定义一个常量,在运行时产生的变量,系统会为它分配内存。
其他杂项
- 指针和引用的区别?
1.指针:指针是一个变量,该变量存储的是一个地址,指向内存的一个存储单元。
引用:与原来的变量实质是同一个东西,只不过是变量的另一个别名
- 模板的优点和缺点

- 当程序中有函数重载时,函数的匹配原则和顺序是什么?
-
名字查找
-
确定候选函数
-
寻找最佳匹配
- struct和class的区别
C中的struct仅仅是用来存储数据的,是值类型不能用于定义成员函数,而C++为了保持对C的兼容性,所以需要有struct的功能。在此之上,C++中给strcut添加了可以定义成员函数和继承的功能。
struct的访问权限默认是public,class的默认访问权限是private。
在继承上,struct默认是public式的继承,而class是private式的继承。
class可以用来定义模板,实现模板类,但是struct不行。
struct更适合看成是一个数据结构的实现体,class更适合看成是一个对象的实现体。
- 值类型和引用类型的区别?
复制方面:
引用类型的变量在复制时,只复制对象的引用而不复制对象本身。将一个值类型变量复制给另一个值类型变量时,会把值复制过去。
载体方面:
值类型在内存管理方面有更高的效率,且不支持多态,适合做数据存储的载体。
引用类型支持多态,适合用于定义应用程序的行为。
内存分配方面:

- 函数指针
- this指针
每一个对象都能通过 this 指针来访问自己的地址。this 指针是所有成员函数的隐含参数。因此,在成员函数内部,它可以用来指向调用对象。
this是一个指针,它指向你这个实例本身。
this指针不能再静态函数中使用
静态函数如同静态变量一样,他不属于具体的哪一个对象,静态函数表示了整个类范围意义上的信息,而this指针却实实在在的对应一个对象,所以this指针不能被静态函数使用。
- 野指针的定义?什么情况会出现野指针?
野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)指针变量在定义时如果未初始化,其值是随机的,指针变量的值是别的变量的地址,意味着指针指向了一个地址是不确定的变量,此时使用这个指针会访问了一个不确定的地址,所以结果是不可知的。
1、指针变量未初始化,任何指针变量刚被创建时不会自动成为 NULL 指针,它的缺省值是随机的。
所以,指针变量在创建的同时应当被初始化,要么将指针设置为 NULL ,要么让它指向合法的内存。
2、指针释放后之后未置空。
指针在 free 或 delete 后未赋值 NULL ,它们只是把指针所指的内存给释放掉,但并没有处理指针本身。此时指针指向不可知的(随机的、不正确的、没有明确限制的)。

- 怎样避免野指针?
初始化时置 NULL.
- C++11的新特性
(1)auto关键字,可以自动推断出变量的类型;
(2)nullptr来代替NULL,nullptr 的类型是 std::nullptr_t,能转换成任意的指针类型。使用nullptr表示空指针。
可以避免重载时出现的问题(一个是int,一个是void*);
为什么建议使用nullptr代替NULL呢?
这是因为在C++中,NULL是被定义为0的常量,当遇到函数重载时,就会出现问题。
比如有下面两个函数时:
- void foo(int n)
- void foo(char* s)
函数重载:C++允许在同一作用域中声明多个类似的同名函数,这些同名函数的形参列表(参数个数,类型,顺序)必须不同。
#include <iostream> using namespace std; void foo(int n) { cout << "foo(int n)" << endl; } void foo(char* s) { cout << "foo(char* s)" << endl; } int main() { foo(NULL); return 0; }编译上述代码,结果如下图所示,编译器提示有两个函数都可能匹配,产生二义性。
(3)智能指针,那三个智能指针,对内存进行管理;
(4)右值引用,基于右值引用可以实现移动语义和完美转发,消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率;
(5)lambda表达式,可以理解为一个匿名的函数,有些函数我们只关心它的功能不需要有它的名字,甚至可以是临时的,这时候可以使用匿名函数。
另一方面,lambda表达式可以使得代码更加简洁易懂。
参考:C++中的Lambda表达式 - 简书 (jianshu.com)
例如:
bool cmp(int &a, int &b); int main() { vector<int> data; for (int i = 0; i < 10; ++i) data.push_back(i); sort(data.begin(), data.end(), cmp); for (int i = 0; i < data.size(); ++i) cout << data[i] << endl; return 0; } bool cmp(int &a, int &b) { return a > b; }在定义了函数bool cmp(int &a, int &b)后,相同的函数签名变得不可用,我不能再用bool cmp(int &a, int &b)这个签名定义一个别的比较函数:
问题是排序这件事通常不会反复做,那么用cmp比较大小是个一次性的临时需求,排序之后它的任务就已经完成了。所以给它特意起个名字污染命名空间似乎有点不太合算,可不可以不给它起cmp这个名字,又能使用比较大小的功能呢?答案当然是可以的,通过与cmp等价的匿名函数:
int main() { vector<int> data; for (int i = 0; i < 10; ++i) data.push_back(i); sort(data.begin(), data.end(), [](int &a, int &b)->bool { return a > b; }); for (int i = 0; i < data.size(); ++i) cout << data[i] << endl; return 0; }即
[](int &a, int &b)->bool { return a > b; }就是传说中的Lambda表达式了,先不管[]部分,(int &a, int &b)->bool表示接受两个int引用类型的参数,返回值是bool类型,{}里是函数体,是不是很简单?
[ capture-list ] ( params ) -> ret { body }其中( params ) -> ret定义了这个匿名函数的参数和返回类型, { body }定义了这个匿名函数的功能,捕捉列表[ capture-list ]是做什么的呢?概括地讲,它使这个匿名函数可以访问外部(父作用域)变量。
- c++是如何进行垃圾回收的?
在 C++ 中,垃圾回收不是由语言本身提供的特性,而是需要程序员负责手动管理内存。也就是说,C++ 程序员需要自己分配和释放内存,以确保没有内存泄漏或者非法内存访问。
手动管理堆内存可能会变得非常复杂和容易出错。因此,一些第三方库和框架提供了自动化的内存管理实现,例如智能指针、引用计数等技术。
- 为什么要进行垃圾回收?
使开发人员不必手动释放内存。
回收不再使用的对象,清除它们的内存,并使内存可用于将来的分配。
- 补充:C#如何进行垃圾回收
在 C# 中,垃圾回收是由 .NET Framework 或 .NET Core 运行时环境提供的自动化机制。这种机制称为垃圾回收器(Garbage Collector,简称 GC),可以自动地跟踪和回收不再被程序使用的内存资源,从而减少内存泄漏和非法内存访问等问题。
C# 中的垃圾回收器通过对内存堆进行扫描来检测哪些对象已经不再被程序所引用。如果一个对象没有任何引用指向它,那么就可以认为它是「无用的」,并且可以被垃圾回收器清理掉。
垃圾回收器通常会将内存堆分成多个区域,并按照对象的生命周期将对象存储到不同的区域中。例如,在新生代区域中存储生命周期较短的对象,而在老年代区域中存储生命周期较长的对象。垃圾回收器会定期启动垃圾回收过程,扫描整个堆空间并清理无用对象所占用的内存。
在 C# 中,程序员不需要显式地释放内存,因为垃圾回收器会自动回收无用的内存资源。
- 垃圾回收算法
(217条消息) C++中垃圾回收机制中的几种经典算法_一名12岁的C++爱好者的博客-CSDN博客_c++垃圾回收机制

- C和C++有什么区别?
C是C是面向过程的结构化编程语言,不具有面向对象的功能,而C++具有面向对象的功能,具有封装,继承,多态三种特征。这些都是C没有的。
C++是对C的拓展,C++可以向下兼容C的代码。
C++中的结构体可以声明函数,但是C中的结构体只能声明变量。
函数库不同
1、C语言:C语言有标准的函数库,它们比较松散,只是把功能相同的函数放在一个头文件中。
2、C++:C++对于大多数的函数都是有集成的,很紧密,是一个集体
- 面向过程和面向对象的区别?
面向对象在涉及较为复杂的业务时,具有耦合度低,可拓展力强的优点。
面向过程是一种 以过程为中心 的编程思想。
面向过程:主要关注点是:实现的具体过程,因果关系。
优点:对于业务逻辑比较简单的程序,可以达到快速的开发,前期成本投入较低。
缺点:很难解决非常复杂的业务逻辑。另外面向过程的方式,导致软件元素之间的“耦合度”非常的高,只要其中一环出问题,整个系统受到影响,导致最终软件扩展能力差,另外由于没有独立体的概念,所以无法达到组间复用。
面向对象: 主要关注的点是:主要关注各个对象【独立体】完成的功能
优点:耦合度低扩展力强,更容易解决,现实世界中更复杂的业务逻辑
缺点:前期投入成本较高,需要进行独立体的设计
- C++和C#有什么区别?
1、编译区别
C#代码首先会被编译为CLR(公共语言运行库),然后由.NET框架解析。
C ++代码将会直接被编译为机器代码。
2、内存管理的不同
C#有自动垃圾收集机制,防止内存泄露,,会自动进行内存管理。而,C ++需要手动组织管理内存。
3、指针使用的区别
C#不支持使用指针,;而,C ++允许使用指针,这会带来一些安全隐患,比如内存泄漏。而c#出于软件安全性和易用性的考虑没有使用指针。
4、继承上的区别
C#不支持多重继承,
5、面向的区别
C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计。而c#是完全面向对象的语言。
6、速度上的区别
C ++代码更快,因为它不使用重型库;而,C#较慢,因为它会产生开销并使用了类似于java这样的重型库
开发项目来说,C#适合企业各应用程序,C++适合底层开发(游戏等)
- C 广泛应用于底层开发,主要用于嵌入式领域,驱动开发等与硬件直接打交道的领域,因为 C 会自动翻译成为汇编。
- C++ 可应用于应用层开发、用户界面开发等于操作系统打交道的领域,如数据库、编译器、解析器、游戏、大型网站后台、大型桌面应用程序等,小到嵌入式,大到分布式服务器,到处可以见到 C++ 的身影。
- C# 适合程序开发和编程爱好者,对硬件的控制功能比 C++ 差很多,虽然写起来很优雅但性能不好优化。
C/C++里,static关键字的作用有: ()
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定为 static。
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员
STL
容器的底层实现(⭐⭐⭐)
(1)vector,底层是一块具有连续内存的数组,vector的核心在于其长度自动可变。
vector的数据结构主要由三个迭代器(指针)来完成:指向首元素的start,指向尾元素的finish和指向内存末端的end_of_storage。
vector的扩容机制是:当目前可用的空间不足时,分配目前空间的两倍或者目前空间加上所需的新空间大小(取较大值),容量的扩张必须经过“重新配置、元素移动、释放原空间”等过程。

- vector扩容机制
当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,再插入新增的元素。
1.5倍或2倍(增长倍数太大会导致产生的堆空间浪费)
由于重新分配内存和元素复制会带来额外的开销,因此在使用vector时应尽量避免频繁进行扩容操作。所以如果初始就能确定大小就很好。
(2)list,底层是一个双向链表(在某些stl版本中用的是双向循环链表),每个结点包含pre、next指针和data数据。
优点:插入删除快
缺点:访问特定数据慢,时间复杂度O(n)
(list有一个重要性质:插入操作(insert)和接合操作(splice)都不会造成原有的list迭代器失效。这在vector是不成立的。因为vector的插入操作可能造成记忆体重新配置,导致原有的迭代器全部失效。甚至list的元素删除操作(erase)也只有“指向被删除元素”的那个迭代器失效,其他迭代器不受影响。
(**有难度)(3)deque(double-ended queue),双向队列,
双向队列的特点就是可以在两端进行插入和删除,不过它是动态扩容,但是不像vector使用的是连续空间,也不像list那样是离散的空间。deque实际上是由一段一段定量的连续空间构成。
当在队列的头和尾增加元素需要新的空间的时候,就会分配一段新的定量的空间,串在deque的头和尾上,因此deque的最大的任务就是在这些分段定量的连续空间上,维持整体连续假象的状态。
既然是分段连续空间,因此肯定需要一个控制器来将这些分段连续的空间组织起来,才能维持空间连续的假象。它用一小段连续的空间作为控制器,里面的结点指向不同的连续空间。

然后deque还需要一个迭代器,迭代器具有这几点功能:
1.指出当前缓冲区的位置
2.知道自己是否在当前缓冲区的边缘,当迭代器进行++或者–时发生缓冲区跳跃,到上一个或者下一个缓冲区
3.知道当前元素的位置,访问和操作该元素
例如:当我们设置一个缓冲区的大小时32个byte,需要存储20个int型的元素时,一个缓冲区可以存储8个元素,因此需要3个缓冲区来存储,也需要三个节点来将这三个空间链家起来,其中的迭代器如下图所示:

(4)stack和queue,栈和队列。它们都是由由deque作为底层容器实现的,他们是一种容器配接器,修改了deque的接口,具有自己独特的性质(此二者也可以用list作为底层实现);stack是deque封住了头端的开口,先进后出,queue是deque封住了尾端的开口,先进先出。
(5)priority_queue,优先队列。是由以vector作为底层容器,以heap(大顶堆、小顶堆)堆的规则作为处理规则,heap的本质是一个完全二叉树。
(6)set和map。底层都是由红黑树实现的。set是一种基于红黑树实现的有序集合,map是一种基于红黑树实现的有序映射。
红黑树是一种二叉搜索树,但是它多了一个颜色的属性。红黑树的性质如下:1)每个结点非红即黑;2)根节点是黑的;3)如果一个结点是红色的,那么它的子节点就是黑色的;4)任一结点到树尾端(NULL)的路径上含有的黑色结点个数必须相同。通过以上定义的限制,红黑树确保没有一条路径会比其他路径多出两倍以上;
为什么map不用平衡二叉树?
因此,红黑树是一种弱平衡二叉树,相对于严格要求平衡的平衡二叉树来说,它的旋转次数少,所以对于插入、删除操作较多的情况下,通常使用红黑树。
补充:平衡二叉树(AVL)和红黑树的区别:AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance(旋转操作),导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
(7)unordered_set和unordered_map底层是用哈希表实现的,
增删改查的时间复杂度(⭐⭐)
【参考资料】:C++STL各种容器的性能比较、【C++】STL各容器的实现,时间复杂度,适用情况分析_Y先森0.0-CSDN博客
(1)vector,vector支持随机访问(通过下标),时间复杂度是O(1);如果是无序vector查找的时间复杂度是O(n),如果是有序vector,采用二分查找则是O(log n);对于插入操作,在尾部插入最快,中部次之,头部最慢,删除同理。vector占用的内存较大,由于二倍扩容机制可能会导致内存的浪费,内存不足时扩容的拷贝也会造成较大性能开销;
(2)list由于底层是链表,不支持随机访问,只能通过扫描的方式查找,复杂度为O(n),但是插入和删除的速度快,只需要调整指针的指向。(有一种说法是链表每次插入和删除都需要分配和释放内存,会造成较大的性能开销,所以如果频繁地插入和删除,list性能并不好,但很多地方都说list插入删除性能好,这点我还没有验证,希望有人能指出);list不会造成内存的浪费,占用内存较小;
(3)deque支持随机访问,但性能比vector要低;支持双端扩容,因此在头部和尾部插入和删除元素很快,为O(1),但是在中间插入和删除元素很慢;
(4)set和map,底层基于红黑树实现,增删查改的时间复杂度近似O(log n),红黑树又是基于链表实现,因此占用内存较小;
(5)unordered_set和unordered_map,底层是基于哈希表实现的,是无序的。理论上增删查改的时间复杂度是O(1)(最差时间复杂度O(n)),实际上数据的分布是否均匀会极大影响容器的性能。
STL的排序用到了哪种算法,具体如何执行?
答:快速排序、插入排序和堆排序;当数据量很大的时候用快排,划分区段比较小的时候用插入排序,当划分有导致最坏情况的倾向的时候使用堆排序。
- 使用map和vector的迭代器删除数据时需要注意什么?
先来看一段错误的用法:
#include<map>
#include<iostream>
using namespace std;
int main() {
map<int, string> mp;
mp[1] = "aaa";
mp[2] = "bbb";
mp[3] = "ccc";
mp[4] = "ddd";
for (auto iter = mp.begin(); iter != mp.end(); iter++) {
if (iter->second == "bbb") mp.erase(iter);
}
}看上去好像没什么问题,可是运行后会报错,这是因为,erase会删除这个迭代器,那么此时将无法再获取这个迭代器了。
解决办法:
1.在删除这个迭代器之前先让这个迭代器后移一位:
for (auto iter = mp.begin(); iter != mp.end(); /*iter++*/) {
if (iter->second == "bbb")mp.erase(iter++);
else iter++;
}2.利用erase这个函数会返回被删除的迭代器的下一个迭代器的性质,将其赋值
for (auto iter = mp.begin(); iter != mp.end(); /*iter++*/) {
if (iter->second == "bbb")iter=mp.erase(iter);
else iter++;
}数据结构
排序算法
数据结构与算法系列--十大排序(附动态图解) - 知乎 (zhihu.com)

- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
(1)快速排序:一轮划分,选择一个基准值,小于该基准值的元素放到左边,大于的放在右边,此时该基准值在整个序列中的位置就确定了,接着递归地对左边子序列和右边子序列进行划分。时间复杂度o(nlogn),最坏的时间复杂度是o(n2);

(2)堆排序:参考:(177条消息) 堆排序_guanlovean的博客-CSDN博客_堆排序
分为大顶堆和小顶堆,大顶堆就是根节点必须要大于左右子树的结点。
使用堆排序排序一个完整的无序数组分为两步骤,
第一步是建堆:
构造方法:以大顶堆为例,先按顺序将其用树的形式存放,然后从最后一个非叶子结点开始(从左至右,从下至上),看其是否满足其值大于左右子树,如果不满足则说明其值小于左右子树,则将子树中更大的元素和它交换,一直交换直到它满足上述性质。
(也就是每次使得一个结点,移动它的位置,直到它满足他的两个子树比它小(让它的子树变成它的小弟))(这样即可实现大的元素上浮,小的元素下沉)。
这样就构造完堆了,也就是此时满足根节点大于左右子树了。
备注,初始建堆时,我们是对第一个非叶子结点,对该结点进行,下沉的操作,当它沉到最底部,例如:
若构造大顶堆,此时4会下沉,而6上去。
而有结点上浮时,此时6比根结点大,那它需要上浮吗?答案是不用,因为此时我们 其实是把原来的6当作父结点的,因此此时4已经走到了终点。
第二步:排序:
前面做完之后,最大的数将会位于最顶端,然后将该元素与最后一个元素做交换即可实现最大的元素位于最后。
然后接下来调整堆,使得换上来的这个结点,也最终满足其左右小于它的条件。(在下沉时如果左右结点都比它大,则让其和更大的那一个交换。)
接下来按照上面的步骤循环直到使整个序列有序。
具体例子看上面的博客。
时间复杂度O(nlogn);
视频演示:
1//声明全局变量,用于记录数组array的长度;
2static int len;
3/**
4* 堆排序算法
5*
6* @param array
7* @return
8*/
9public static int[] HeapSort(int[] array) {
10 len = array.length;
11 if (len < 1) return array;
12 //1.构建一个最大堆
13 buildMaxHeap(array);
14 //2.循环将堆首位(最大值)与末位交换,然后在重新调整最大堆
15 while (len > 0) {
16 swap(array, 0, len - 1);
17 len--;
18 adjustHeap(array, 0);
19 }
20 return array;
21}
22/**
23* 建立最大堆
24*
25* @param array
26*/
27public static void buildMaxHeap(int[] array) {
28 //从最后一个非叶子节点开始向上构造最大堆
29 for (int i = (len - 1) / 2; i >= 0; i--) {
30 adjustHeap(array, i);
31 }
32}
33/**
34* 调整使之成为最大堆
35*
36* @param array
37* @param i
38*/
39public static void adjustHeap(int[] array, int i) {
40 int maxIndex = i;
41 //如果有左子树,且左子树大于父节点,则将最大指针指向左子树
42 if (i * 2 < len && array[i * 2] > array[maxIndex])
43 maxIndex = i * 2;
44 //如果有右子树,且右子树大于父节点,则将最大指针指向右子树
45 if (i * 2 + 1 < len && array[i * 2 + 1] > array[maxIndex])
46 maxIndex = i * 2 + 1;
47 //如果父节点不是最大值,则将父节点与最大值交换,并且递归调整与父节点交换的位置。
48 if (maxIndex != i) {
49 swap(array, maxIndex, i);
50 adjustHeap(array, maxIndex);
51 }
52}(3)冒泡排序:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
时间复杂度O(n²),最好情况O(n);
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。

优化:比如 8 1 2 3 5 7,进行一次排序之后,结果就变成了 1 2 3 5 7 8,那我们还有必要再像上面代码里那样继续循环下去吗?肯定没有必要了,因为这已经是最终结果了。
若在某一趟排序中未发现数据位置的交换,则说明整个数组已经有序。那么就没有必要再次排序下去了。
代码:
void BubbleSort(vector<int> &array){
for(int i=0;i<array.size();i++){
bool flag=true;
for(int j=0;j<array.size()-1-i;i++){
if(array[j]>array[j+1]){
flag=false;
swap(array[j],array[j+1]);
}
}
if(flag==true) break;
}
}(4)插入排序,类似打牌,从第二个元素开始,把每个元素插入前面有序的序列中;时间复杂度O(n2),最好情况O(n);

6public static int[] insertionSort(int[] array) {
7 if (array.length == 0)
8 return array;
9 int current;
10 for (int i = 0; i < array.length - 1; i++) {
11 current = array[i + 1];
12 int preIndex = i;
13 while (preIndex >= 0 && current < array[preIndex]) {
14 array[preIndex + 1] = array[preIndex];
15 preIndex--;
16 }
17 array[preIndex + 1] = current;
18 }
19 return array;
20}(5)选择排序,每次选择待排序列中的最小值和未排序列中的首元素交换;时间复杂度O(n2);

(6)希尔排序是把序列按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量的逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个序列恰好被分为一组,算法便终止。增量一般是从len/2开始,时间复杂度O(n1.3),最好O(n),最坏O(n2);希尔排序时间复杂度是 O(n^(1.3-2))
7public static int[] ShellSort(int[] array) {
8 int len = array.length;
9 int temp, gap = len / 2;
10 while (gap > 0) {
11 for (int i = gap; i < len; i++) {
12 temp = array[i];
13 int preIndex = i - gap;
14 while (preIndex >= 0 && array[preIndex] > temp) {
15 array[preIndex + gap] = array[preIndex];
16 preIndex -= gap;
17 }
18 array[preIndex + gap] = temp;
19 }
20 gap /= 2;
21 }
22 return array;
23}- 为什么希尔排序的时间复杂度比插入排序要好?
首先插入排序具有这两种性质:
1. 当原序列的长度很小时,即便它的所有元素都是无序的,此时进行的元素比较和移动的次数还是很少。
2. 当待排序的原序列中大多数元素都已有序的情况下,此时进行的元素比较和移动的次数较少;
而希尔排序首先会将元素分为短的几个子数组,此时数组内排序时,移动的次数会少很多。(利用性质1)。
希尔排序进行了多趟后,会对序列进行大体的有序,这样真正在直接插入排序的时候就会少了很多移动的次数。(利用性质2)
(7)
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。


1/**
2* 归并排序
3*
4* @param array
5* @return
6*/
7public static int[] MergeSort(int[] array) {
8 if (array.length < 2) return array;
9 int mid = array.length / 2;
10 int[] left = Arrays.copyOfRange(array, 0, mid);
11 int[] right = Arrays.copyOfRange(array, mid, array.length);
12 return merge(MergeSort(left), MergeSort(right));
13}
14/**
15* 归并排序——将两段排序好的数组结合成一个排序数组
16*
17* @param left
18* @param right
19* @return
20*/
21public static int[] merge(int[] left, int[] right) {
22 int[] result = new int[left.length + right.length];
23 for (int index = 0, i = 0, j = 0; index < result.length; index++) {
24 if (i >= left.length)//假如左指针已经走到尽头,则接下来继续拷贝右指针即可
25 result[index] = right[j++];
26 else if (j >= right.length)
27 result[index] = left[i++];
28 else if (left[i] > right[j])
29 result[index] = right[j++];//比较左右两个数组,将小的赋值给新开辟的数组
30 else
31 result[index] = left[i++];
32 }
33 return result;
34}(8)计数排序
输出待排序序列中,每个数字有多少个,然后新生成一个数组,根据每种数字有多少个,然后填入新开辟的数组。

注意到下面的代码中有一个bias,其是用来实现一个节约空间的操作的。比如数的范围是100~200,我们可以直接开辟0~200的数组,但是那样比较浪费,我们可以开辟一个0~100的数组,对于数字101,我们将其存储到数字的位置1中,数字153,存储在53位,中。bias就是这个偏移量。
7public static int[] CountingSort(int[] array) {
8 if (array.length == 0) return array;
9 int bias, min = array[0], max = array[0];
10 for (int i = 1; i < array.length; i++) {
11 if (array[i] > max)
12 max = array[i];
13 if (array[i] < min)
14 min = array[i];
15 }
16 bias = 0 - min;//节省空间的偏移量
17 int[] bucket = new int[max - min + 1];
18 Arrays.fill(bucket, 0);
19 for (int i = 0; i < array.length; i++) {
20 bucket[array[i] + bias]++;
21 }
22 int index = 0, i = 0;
23 while (index < array.length) {
24 if (bucket[i] != 0) {
25 array[index] = i - bias;
26 bucket[i]--;
27 index++;
28 } else
29 i++;
30 }
31 return array;
32}(9)桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。
桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
每个桶分别排序完后再取出来即可
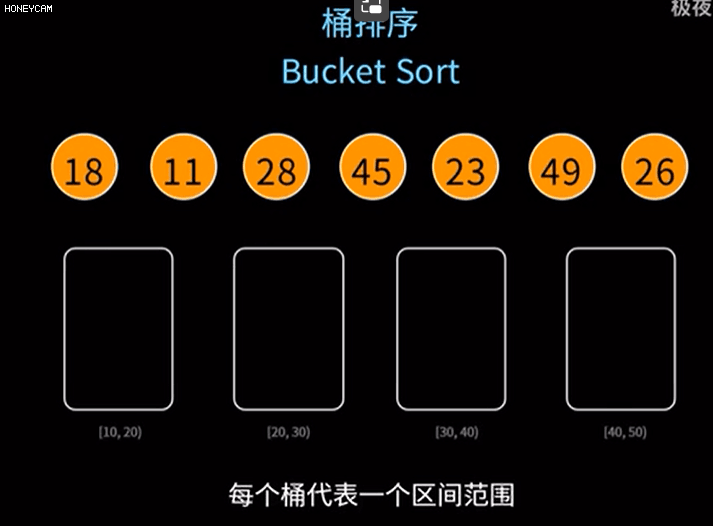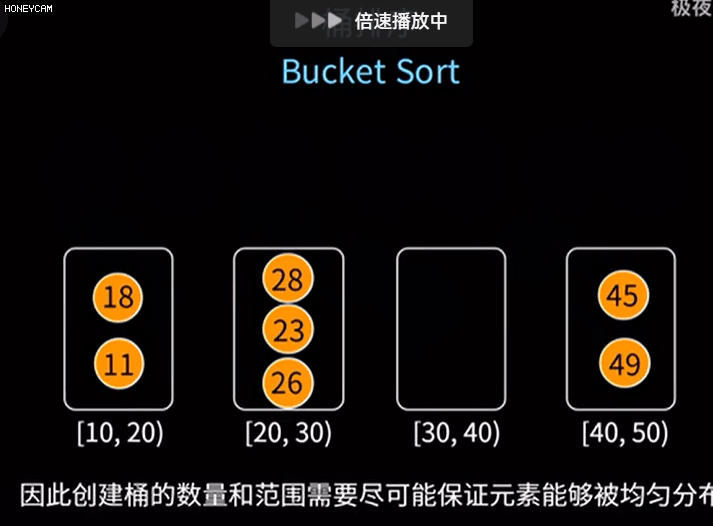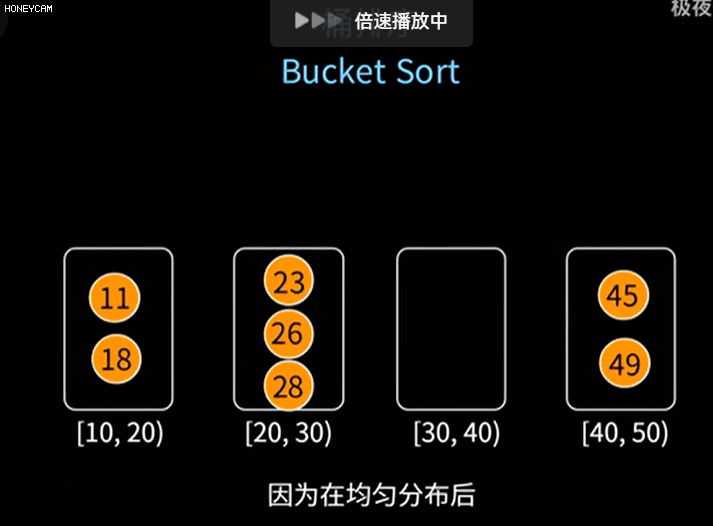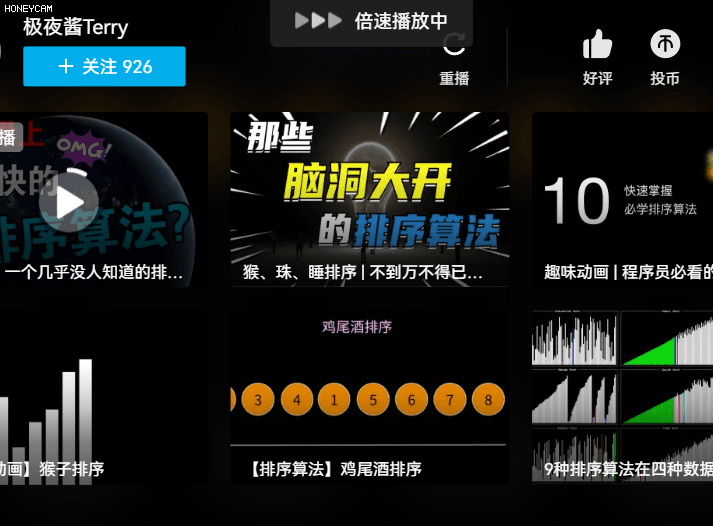
(10)基数排序
基数排序也是非比较的排序算法,对每一位进行排序,从最低位开始排序,复杂度为O(kn),为数组长度,k为数组中的数的最大的位数;
基数排序是按照低位先排序,然后收集,此时的数组,在最低位上是有序的。如下图

接下来再按照高位排序,然后再收集,收集完后,高位中,小的肯定放在前面,毫无疑问。但是高位的数相同的,其最低位一定是按顺序的,因为,最低位由于上一轮排序完成后,是按照顺序收集的,所以最低位肯定是有序的,如下图:
按最高位排序后如下:
对这次排序的结果收集后如下:


就这样依次类推,直到最高位。

有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。
最佳情况与 最差情况都是:T(n) = O(n * k) 平均情况:T(n) = O(n * k)
基数排序有两种方法:
MSD 从高位开始进行排序 LSD 从低位开始进行排序
- 基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
- 排序算法的稳定性是怎么样的?为什么?
选择、快速、希尔、堆(选希快堆)不是稳定的排序算法,其他的都是稳定的排序算法。
冒泡排序比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,此时不需要交换。
插入排序是在已经有序的部分序列中插入一个元素,插入元素的过程中如果元素相同,则将这个元素插入在相等的元素之后即可保证有序。
选择排序是给每个位置选择当前元素最小的,比如5 8 5 2 9, 我们知道第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了。
快速排序的思想是选取一个基准值,然后用双指针的方法,将大于基准值的放右边,小于基准值的放左边。在这样的过程中无法保证稳定性。
归并排序是将序列划分为多个小的子序列,在子序列内部进行排序,然后将排序好的子序列在合并。不论是在子序列内部排序,还是将序列合并时,都不会破坏相等元素的先后顺序。
希尔排序是在插入排序的基础上优化,进行多次不同步长的插入排序。插入排序是稳定的,不会改变相同元 素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的。
堆排序不是稳定的,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;
如何在一个序列中求前k个最大或者最小的数?(TOP K问题)
思想:将全局排序优化为局部排序,非TopK的元素是不需要排序的。除此之外,只需要找出前K个,对这K个内部也不需要排序。
(1)基于快排,每轮划分选择一个基准值,把比它小的数放在左边,大的放在右边,函数返回基准值的位置,如果该位置恰好是K,就说明了这是第K小的数,所以从0-基准值位置的数是序列中的前K小数。若返回基准值的位置小于或者大于K,再进行相应调整:如果返回的基准值大于k,在基准值左边序列查找,如果大于,在基准值右边进行查找。递归地进行快排,直到返回的结果=K;时间复杂度为O(n)。
举例:
算法必学:经典的 Top K 问题 - 简书 (jianshu.com)

(2)基于堆排序,求前K个最小的数用最大顶堆,求前K个最大的数用最小顶堆。以最大顶堆为例,要维护一个大小为K的顶堆,就是先将K个数插入堆中,随后,对每一个数,与堆顶的最大元素比较,若该数比堆顶元素小,则替换掉堆顶元素,然后调整堆,若大于堆顶元素,则不管,那么将所有元素比较和插入后,该堆维护的就是最小的K个数。求前k小的数用最大顶堆的目的(原理):这是一种局部淘汰的思想,尽量的把小的数都放在堆中,最后使得即使堆中最大的数,也比外界的所有数都小,就达到了目的。
(大顶堆的顶部是最大的元素,我们要找最小的几个数,那么大顶堆的顶部元素是最容易被淘汰的那个。)
- 怎样判断单链表是否存在回环
最简单的方法, 用一个指针遍历链表,
每遇到一个节点就把他的内存地址做为key放在一个map中.
这样当map中出现重复key的时候说明此链表上有环. 这个方法的时间复杂度为O(n), 空间同样为O(n).
判断单链表是否存在回环原理很简单,即假设有两个指针p1,p2。在每次循环的时候,p1先走一步,p2走两步,直到p2碰到空指针或两者相等时循环结束,如果两个指针相等则说明存在回环。
- 均摊时间复杂度是什么?
均摊时间复杂度是一种平均时间复杂度的计算方法,它考虑了算法在最坏情况下的时间复杂度,以及算法实际执行过程中的平均时间消耗,用于描述算法的总体性能。与普通的时间复杂度相比,均摊时间复杂度能更准确地反映算法的实际执行情况,尤其适用于涉及到分摊操作成本的算法。
均摊时间复杂度通常基于摊还分析(Amortized Analysis)实现。摊还分析是一种平衡分析方法,它通过将操作成本分摊到多次执行中,从而得到操作的平均成本。例如,在动态数组的扩容过程中,每次扩容的时间复杂度为O(n),但是扩容操作并不是每次都执行,而是随着元素数量的增加而逐渐减少,因此可以将扩容成本均摊到每个元素上,得到每个元素的插入时间复杂度为O(1),即均摊时间复杂度。
它能够避免过于乐观或悲观的时间复杂度估计。
计算机组成
内存对齐、区域、布局、泄漏相关问题
- 类的对象存储空间?
-
非静态成员的数据类型大小之和。
-
编译器加入的额外成员变量(如指向虚函数表的指针)。
-
为了边缘对齐优化加入的padding。
空类(无非静态数据成员)的对象的size为1, 当作为基类时, size为0.
(291条消息) c++内存对齐原则_hi_baymax的博客-CSDN博客
C++中的内存对齐规则可以概括为以下三点:
-
对于任意数据类型,其起始地址必须是对齐值的整数倍。
-
数据类型的大小必须是对齐值的整数倍。如果数据类型的大小不是对齐值的整数倍,则编译器会在其末尾填充额外的空间,以达到对齐要求。
-
结构体的对齐值等于其中包含的最大基本类型的对齐值。也就是说,结构体成员的偏移量必须是它的类型大小的整数倍,并且结构体大小必须是成员大小的整数倍。
下面给出几个例子以便于理解:见这里:
- c++内存区域是什么样的?
堆 heap :
堆,用于存储动态分配的内存。堆内存的大小可以在程序运行时动态地分配和释放。使用new、delete动态分配和释放空间,能分配较大的内存;
如果程序员没有释放掉,在程序结束时OS会自动回收。涉及的问题:“缓冲区溢出”、“内存泄露”
栈 stack :
存放局部变量、函数参数、函数调用的返回地址
是那些编译器在需要时分配,在不需要时自动清除的存储区。
存放在栈中的数据只在当前函数及下一层函数中有效,一旦函数返回了,这些数据也就自动释放了。
全局/静态存储区
存储全局和静态变量
常量存储区
存放常量
代码区
存放代码。代码区的大小在程序编译时就已经确定,并且它的内容在整个程序的运行期间都存在。
- c++中类对象的内存模型(布局)是怎么样的?
在C++中,类对象的内存模型(布局)通常包括以下几个部分:
-
对象头部(object header):用于存储虚函数表指针和其他元数据。对象头部的大小通常为4字节或8字节(取决于CPU架构)。
-
成员变量(member variables):用于存储类的数据成员。成员变量的大小和数据类型有关,可以是任意的基本类型、指针类型或自定义类型。
-
对齐填充(padding):用于对齐成员变量,保证其在内存中的地址是按照对齐规则对齐的。对齐填充的大小通常是根据成员变量的大小和对齐规则计算得出的。
需要注意的是,类对象的内存模型可能会受到编译器和CPU架构的影响,因此具体的实现方式可能会有所不同。在编写代码时,应该避免对类对象的内存布局做出任何假设,以免出现不可预料的问题。
- C++中空类的大小应该是多大?如果一个类里只有两个函数,那么大小是多大?
如果其中一个函数是虚函数呢?
在C++中,空类的大小(即不包含任何成员变量和成员函数的类)通常为1字节。
这是因为C++标准规定,任何非0大小的对象在内存中都必须有一个独特的地址,即使是空类也不例外。因此,空类的大小至少为1字节。
如果一个类里只有两个函数且都不是虚函数,那么该类的大小也是为1字节,它在内存中不占用实际的空间,而只是占用了一个地址。
如果一个类里有一个虚函数,那么该类的大小通常会比没有虚函数的类要大,因为C++编译器会在对象头中分配一个指向虚函数表的指针,用于实现虚函数的动态绑定。虚函数表的大小通常是4字节或8字节,取决于CPU架构。因此,包含虚函数的类的大小至少是4字节或8字节,再加上其他成员变量的大小。
- C++中类对象的内存布局是如何分布的呢?
【参考资料】:C++内存模型 - MrYun - 博客园 (cnblogs.com)、C++内存布局(上)_qinm的专栏-CSDN博客
没有继承的情况:
- 无虚函数 = 各字段的大小之和+字节对齐
- 有虚函数 = sizeof(vfptr)+各字段大小之和+内存对齐(虚函数表的指针始终存放在内存空间的头部,并且虚函数表会占用四个字节)
单一继承
在单一继承中,子类只继承自一个父类,这又可以分为简单直接继承、父类或子类中有虚函数、虚继承等几种情况。
1)简单直接继承(父类、子类都没有虚函数):父类各字段大小之和+子类各字段大小之和+字节对齐
2)有虚函数(父类或子类中有虚函数)
当父类有虚函数表时,则父类中会有一个vfptr指针指向父类虚函数对应的虚表。
当一个子类继承自含有虚函数的父类时,就会继承父类的虚函数,因此子类中也会有vfptr指针指向虚函数表。当子类重写了虚函数时,虚表中对应的虚函数就会被子类重写的函数覆盖。此时
子类大小就为:sizeof(vfptr) + 父类各字段大小之和 + 子类各字段大小之和+字节对齐
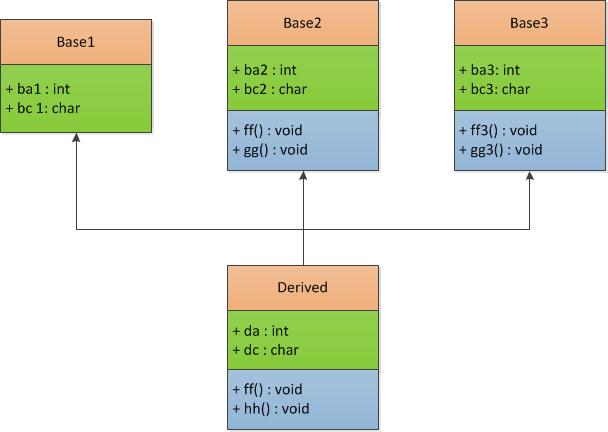
eg : 父子类图如下所示:
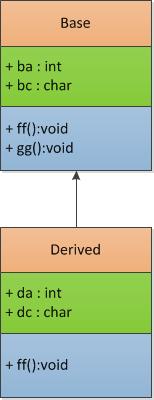
则Derived类在内存中的存储结构为:
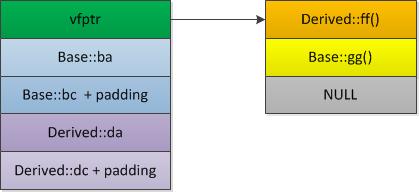
则sizeof(Derived) = 4 + (4 + 1 + 3) + (4 + 1 + 3)=20,且子类的虚函数表覆盖了父类的ff()方法。
成员变量根据其继承和声明顺序依次放在后面,先父类后子类。
(3)多继承
如果是多个层次的单一继承,则分析和上所示思想一样。
如果是多继承,如果没有虚函数,则也与上面一样。
如果有虚函数,则子类会有多个虚表指针,(其中子类自己独有的虚函数在第一个虚表指针中)。具体如下:
则Derived类在内存中的存储结构示意图为
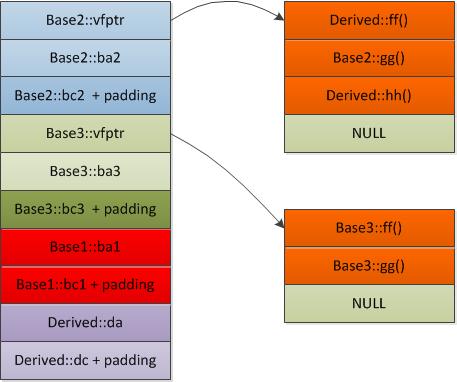
sizeof(Derived) = 40字节
可以发现:
1)Base2、Base3 中定义了虚函数,因此出现在Base1的前面
2)子类Derived重写了父类Base2的ff()方法,因此Base2的虚函数表被覆盖了
3)子类新增的虚函数hh()增加到了第一个虚函数表,也就是Base2的虚函数表中
(4)如果有钻石继承,并采用了虚继承,则内存空间排列顺序为:各个父类(包含虚表)、子类、公共基类(最上方的父类,包含虚表),并且各个父类不再拷贝公共基类中的数据成员。
- 堆和栈的内存有什么区别?
(1)堆中的内存需要手动申请和手动释放,栈中内存是由OS自动申请和自动释放;
(2)堆能分配的内存较大(4G(32位机器)),栈能分配的内存较小(1M);
(3)在堆中分配和释放内存会产生内存碎片,栈不会产生内存碎片;
(4)堆的分配效率低,栈的分配效率高;
(5)堆地址从低向上,栈由高向下。
(6)使用new和malloc申请到的空间是在堆上的,声明的局部变量是在栈中的。
- 内存泄漏是什么?
C/C++ 内存泄漏-原因、避免以及定位_北极熊~~的博客-CSDN博客_c++ 内存泄漏
C++ 中,内存泄漏指的是程序中分配的堆内存没有被正确释放或回收,从而导致程序持续占用更多的内存资源。当程序运行时频繁出现内存泄漏问题时,可能会导致程序崩溃或性能下降等问题。
- 程序中使用了
new运算符分配堆内存,但是忘记使用delete或delete[]运算符释放这些内存。 - 程序中使用了
malloc()或calloc()函数分配堆内存,但是忘记使用free()函数释放这些内存。 - 程序中存在循环引用,导致部分对象无法被垃圾回收器清理,从而占用更多的内存资源。
为避免内存泄漏,程序员需要负责手动管理堆内存的分配和释放过程,确保在不再需要某个内存块时及时进行释放。同时,也可以考虑使用智能指针(如 std::shared_ptr 和 std::unique_ptr)等 RAII 技术来自动化管理堆内存的分配和释放过程。
编译链接原理,从C++源文件到可执行文件的过程?(⭐⭐)
答:包括四个阶段:预处理阶段、编译阶段、汇编阶段、连接阶段。
(1)预处理阶段处理头文件包含关系,对预编译命令进行替换,生成预编译文件;
(2)编译阶段将预编译文件编译,生成汇编文件(编译的过程就是把预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码);
(3)汇编阶段将汇编文件转换成机器码,生成可重定位目标文件(.obj文件)(汇编器是将汇编代码转变成机器可以执行的命令,每一个汇编语句几乎都对应一条机器指令。汇编相对于编译过程比较简单,根据汇编指令和机器指令的对照表一一翻译即可);
(4)链接阶段,将多个目标文件和所需要的库连接成可执行文件(.exe文件)。
- ifdef endif代表着什么?
-
一般情况下,源程序中所有的行都参加编译。但是有时希望对其中一部分内容只在满足一定条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”。有时,希望当满足某条件时对一组语句进行编译,而当条件不满足时则编译另一组语句。
-
条件编译命令最常见的形式为:
#ifdef 标识符
程序段1
#else
程序段2
#endif- 什么是缓存(Cache)?为什么需要缓存?(⭐⭐)
(1)Cache即CPU的高速缓冲存储器,是一种是用于减少处理器访问内存所需平均时间的部件;
解决了cpu与内存之间速度不匹配问题。
由于CPU的计算速度远远大于从CPU向内存取数据的速度。
当CPU直接从内存中存取数据时要等待一定周期,而Cache则可以保存CPU刚用过或循环使用的一部分数据,如果CPU需要再次使用该部分数据时可从Cache中直接调用,这样就避免了重复存取数据,减少了CPU的等待时间,从而大大提升了计算机系统的处理速度。
- 如何提高缓存的命中率?缓存是不是最快的?
注意程序的局部性原理,在遍历数组时按照内存顺序访问;充分利用CPU分支预测功能,将预测的指令放到缓存中执行;此外缓存的容量和块长是影响缓存效率的重要因素。如何提升CPU的缓存命中率? - 知乎 (zhihu.com)
缓存不是最快的,寄存器更快。
- 栈溢出,StackOverflow是什么?
是指程序在调用函数时,使用的栈空间超过了栈的容量,导致数据写入栈的非法区域,进而导致程序崩溃的现象。栈是一种数据结构,用于存储程序执行时的函数调用、局部变量和参数等信息,栈空间是有限的,一旦超出了这个范围,就会出现栈溢出。
通常情况下,栈溢出是由于递归调用函数时出现了无限循环导致栈空间不断增大,超出了栈的容量,引起栈溢出错误。此外,如果函数内部声明了过多的局部变量或者参数,也可能导致栈空间不足而引起栈溢出。
- 大端小端是什么,有什么区别?
大端(Big-endian)和小端(Little-endian)是指在计算机系统中存储多字节数据类型(如整数、浮点数等)时,字节序(即字节的排列顺序)的不同表示方法。
在大端存储中,数值的高位字节存储在较低的内存地址中,而低位字节存储在较高的内存地址中。换句话说,大端法是将数据的高位字节放在内存地址的低位(起始地址)。
例如,一个 32 位(4 字节)整数 0x12345678 在大端存储中将按以下顺序存储:
低地址 -> 0x12 | 0x34 | 0x56 | 0x78 <- 高地址
在小端存储中,数值的低位字节存储在较低的内存地址中,而高位字节存储在较高的内存地址中。换句话说,小端法是将数据的低位字节放在内存地址的低位(起始地址)。
同样的 32 位整数 0x12345678 在小端存储中将按以下顺序存储:
低地址 -> 0x78 | 0x56 | 0x34 | 0x12 <- 高地址
(高位字节指的是权重高的,如123,最高权重位是100)
(低地址则是指0x100和0x200,100是低地址,在内存中是从左到右)
- 原码、补码、反码、无符号整数,有符号整数都是什么,有什么关系?
无符号整数:表示正整数,没有符号位,最高位用来表示数值大小,一般采用二进制表示。例如,8位二进制无符号整数的范围是0-255。
以8位二进制数为例,对于有符号整数而言:
原码:最高位表示符号位,0表示正数,1表示负数,其余位表示数值部分。
例如,+25的原码为00011001,-25的原码为10011001。
反码:正数的反码与原码相同,负数的反码为将原码中数值部分按位取反。
补码:正数的补码与原码相同,负数的补码为将原码中数值部分按位取反,再加1。
补码是计算机中用来表示有符号整数的一种编码方式。
-
补码表示法将正数和负数统一到一个表示范围内,简化了计算机中的数据表示。在补码表示法中,正数的补码与其原码相同,负数的补码是其绝对值的原码求反(按位取反)后加1。
总之,补码和加法的关系主要表现在补码表示法简化了计算机硬件设计,使得加法和减法运算可以通过相同的硬件进行,并将减法运算转换为加法运算。
- C++函数调用机制?(函数运行)
局部变量占用的内存是在程序执行过程中“动态”地建立和释放的。这种“动态”是通过栈由系统自动管理进行的。当任何一个函数调用发生时,系统都要作以下工作:
(1)建立栈空间;
(2)保护现场:原函数运行状态和返回地址入栈;
(3)为被调函数中的局部变量分配空间,完成参数传递;
(4)执行被调函数的函数体;
(5)释放被调函数中局部变量占用的栈空间;
(6)恢复现场:取主调函数运行状态及返回地址,释放栈空间;
(7)继续主调函数后续语句。
举例:
◆ 函数调用过程中的内存使用:通过下面例子来看函数调用时内存的变化情况。
void fun1(int, int); void fun2(float); int main() { int x=1;y=2; fun1(x, y); return 0; } void fun1(int a,int b) { float x=3; fun2(x); } void fun2(float y) { int x; … }

内存管理(内存分配、内存对齐)(⭐⭐⭐)
- C++是如何做内存管理的(有哪些内存区域)?
- 大端小端模式?
小端模式(Little-endian),是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
- CPU寻址方式?
直接寻址,直接给出数据的地址
寄存器间接寻址,数据的地址在寄存器中
寄存器相对寻址方式,数据的地址是寄存器的值再加上一个偏移量
基址变址寻址方式,数据的地址是两个寄存器的值相加
相对基址变址寻址方式 ,有点像以上两种的综合,数据的地址是两个寄存器的值相加,再加上一个偏移量
设计模式
设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
设计原则
完整文章:写文章-CSDN创作中心
这里介绍几个常用的设计原则
-
单一职责原则 (Single Responsibility Principle, SRP):一个类或者一个模块只负责完成一个功能或者任务。
-
开闭原则 (Open/Closed Principle, OCP):软件实体应该对扩展开放,对修改关闭。
-
里氏替换原则 (Liskov Substitution Principle, LSP):子类应该可以替换掉父类并且程序能够正确的执行。子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
-
依赖倒置原则 (Dependency Inversion Principle, DIP):程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,
-
接口隔离原则 (Interface Segregation Principle, ISP):一个类不应该依赖它不需要的接口,这要求我们将大接口拆分成多个小接口,从而避免客户端代码依赖于它不需要使用的接口,
-
迪米特法则 (Law of Demeter, LoD):一个对象应该对其他对象有尽可能少的了解,只与其直接的朋友(成员变量、方法参数、方法返回值等)通信,而不与陌生的对象发生直接的联系。
-
合成/聚合复用原则 (Composite/Aggregation Reuse Principle, CARP):应该尽量使用合成/聚合关系来实现对象之间的复用关系,而不是使用继承关系来实现。
工厂模式
有关工厂模式的具体例子详解可以看我写的另外一篇文章:
该模式用来封装和管理类的创建,终极目的是为了解耦,实现创建者和调用者的分离。
工厂模式解决的问题是:
Factroy要解决的问题是:希望能够创建一个对象,但创建过程比较复杂,希望对外隐藏这些细节。
工厂模式分为三种:
1)简单工厂模式相比传统模式,将创建对象的方法交给工厂去创建,实现了创建者和调用者的分离。
传统模式类图如下:
此时让调用者直接去创建披萨的对象。
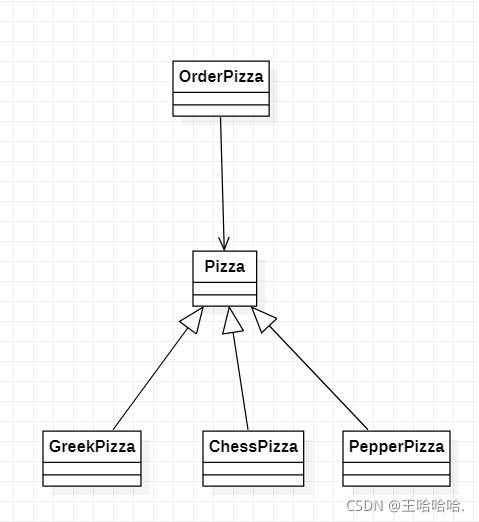
而简单工厂模式的代码:
public class SimpleFactory {
public static Pizza createPizza(String pizzaType){
Pizza pizza = null;
System.out.println("使用了简单工厂模式");
if (pizzaType.equals("greek")) {
pizza = new GreekPizza();
pizza.setName("greek");
} else if (pizzaType.equals("chess")) {
pizza = new ChessPizza();
pizza.setName("chess");
} else if (pizzaType.equals("pepper")) {//新增PepperPizza的时候 修改了源代码 违反了ocp原则 如果新增10000个?
//那就很麻烦了
pizza = new PepperPizza();
pizza.setName("pepper");
}
return pizza;
}
}
此时简单工厂的类图如下:
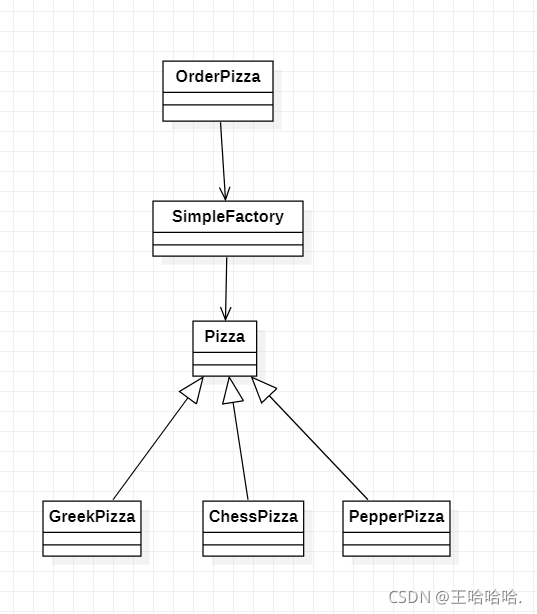
对比传统模式和简单工厂模式的类图可以看出来,在OrderPizza和Pizza中间又加了一层,原来是OrderPizza依赖Pizza,后来让SampleFactory依赖Pizza。
通过封装SimpleFactory这个类,我们将OrderPizza和Pizza进行了解耦合。
但是简单工厂模式存在一个问题,当我们有新的产品需要增加时,就需要直接在工厂类里去添加新的产品,而这违背了OCP原则,即开闭原则Open-Closed Principle,
对扩展开放,对修改关闭。

2)普通工厂,将产品生产分配给多个工厂,但是每个工厂只生产一种产品;
我们让工厂这个类抽象化,让具体的子类去执行实例化对象的操作,类图如下:
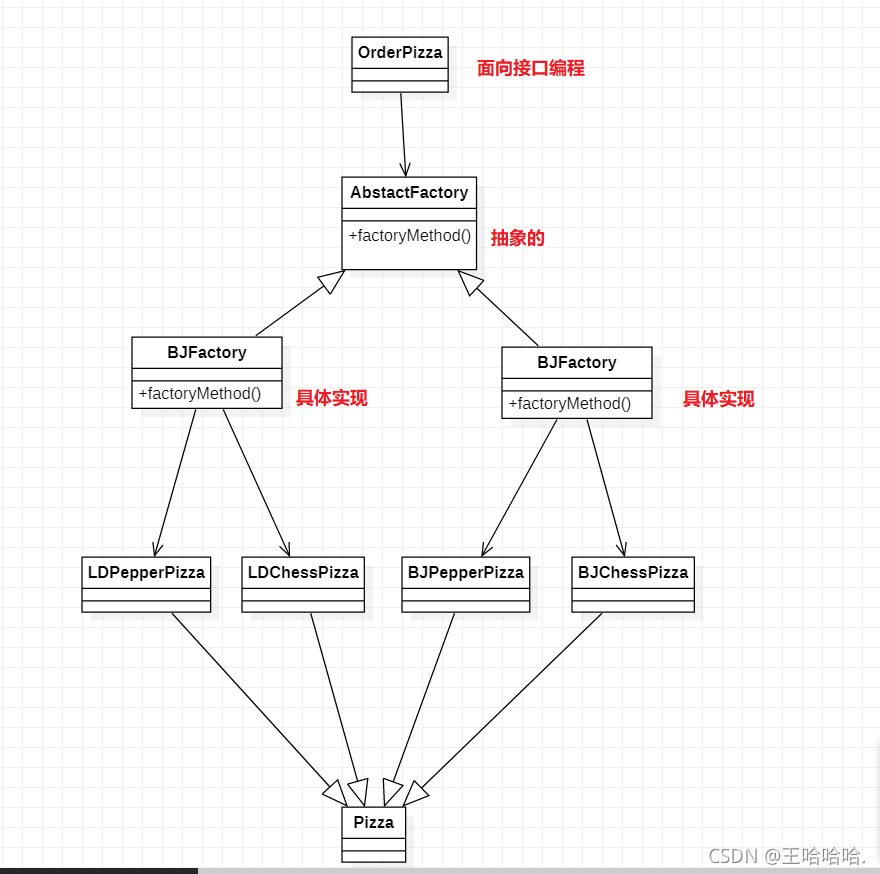
抽象工厂:
定义一个抽象的接口,让子类决定实例化哪个类。
public abstract class AbstractFactory {
//具体实现在子类,应用到了多态的特性
abstract Pizza createPizza(String orderType);
}
具体工厂:
public class BJFactory extends AbstractFactory {
@Override
Pizza createPizza(String orderType) {
Pizza pizza = null;
if (orderType.equals("chess")){
pizza = new BJChessPizza();
}else if (orderType.equals("pepper")){
pizza = new BJPepperPizza();
}
return pizza;
}
}
3)抽象工厂
抽象工厂模式可以使得具体工厂类可以创建多个大类(不同产品)的对象,不过还是需要修改抽象工厂和具体工厂的代码,违反开闭原则。
怎么修改原有的代码呢?
很简单,只需要在抽象工厂类中新增创建该产品的抽象方法,然后在具体工厂子类中实现它即可。
public interface AbstractFactory {
Pizza createPizza(String orderType);
···········
Sauce createSauce(String orderType);
········
//创建蔬菜的方法
Vegetable createVegetable(String orderType);
········
}
public class BJFactory implements AbstractFactory {
@Override
public Pizza createPizza(String orderType) {
System.out.println("~~~使用的是抽象工厂模式~~~");
Pizza pizza = null;
if (orderType.equals("chess")){
pizza = new BJChessPizza();
}else if (orderType.equals("pepper")){
pizza = new BJPepperPizza();
}
return pizza;
}
//实现其他产品的方法
public Vegetable createVegetable (String orderType) {
System.out.println("~~~使用的是抽象工厂模式~~~");
Vegetable vegetable = null;
if (orderType.equals("Shengcai")){
Vegetable = new BJShengcaiVegetable ();
}else if (orderType.equals("Youmaicai")){
Vegetable = new BJYoumaicaiVegetable();
}
return Vegetable ;
}
}
可以看到,抽象工厂仅仅是在工厂方法模式下新增了一些接口,只是工厂模式的一个拓展,当抽象工厂模式只有一个产品体系的话就会退化成工厂模式。
单例模式
(178条消息) Unity单例模式较为简单的理解_晴夏。的博客-CSDN博客_unity单例模式是干什么用的
含义:单例模式是指在内存中只会创建一次对象的设计模式,并且确保一个类只有实例,而且会自行实例化,并向整个系统提供这个实例。
作用:在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象。
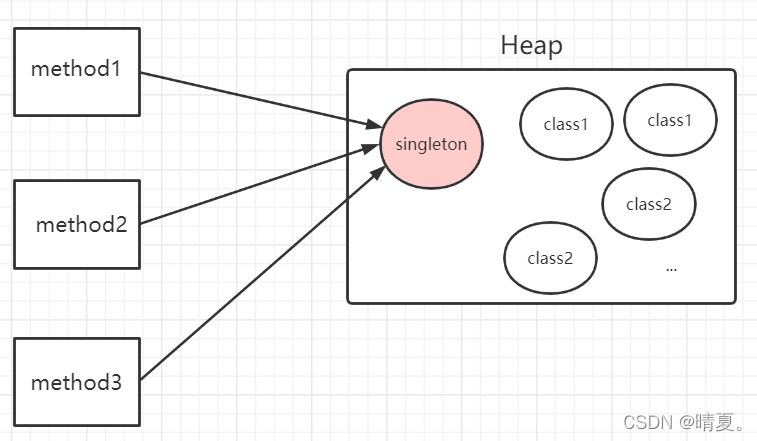
代码书写的要求:
- 因为不能被外界实例化,所以构造方法一定是private的
- 单例模式只能有一个实例,且这个实例属于当前类,也就是说这个实例是当前类的成员变量,还得是静态变量。
- 它要求向整个系统提供这个实例,即我们要再提供一个静态的方法,向外界提供当前类的实例
注意下面的代码,创建实例时放在第一次使用类时进行实例化。
(这种为懒汉式的单例模式,另外一种是饿汉式的单例模式,在加载类的时候就进行实例化(即一开始))

随后即可在其他地方直接对其直接调用类名.Instance.类里的方法即可。
懒汉式与饿汉式
懒汉式:在第一次使用的时候才进行初始化,

饿汉式:在类加载的时候就对实例进行初始化,没有线程安全问题;如果该实例从始至终都没被使用过,则会造成内存浪费。
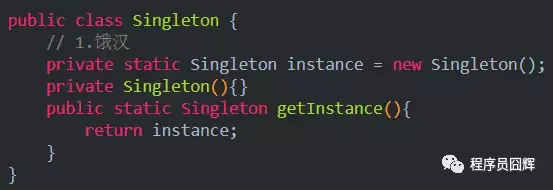
观察者模式
(229条消息) 设计模式——观察者模式_晴夏。的博客-CSDN博客
意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
通俗理解:其中一个对象的行为发生改变可能会导致一个或者多个其他对象的行为也发生改变。例如,某种商品的物价上涨时会导致部分商家高兴,而消费者伤心;
抽象理解:当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。可以降低对象之间的耦合度。
使用场景:一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,
- 一个对象必须通知其他对象,而并不知道这些对象是谁。
代码实现,简单来说,就是一个被观察者会有一个列表,列表记录着所有观察者。当被观察者某件事触发后,就让观察者去notifyAllObservers,去提醒所有的观察者。然后观察者就会执行对应的response函数。 为了让代码复用性更强,还会使用抽象的被观察者和观察者的基类,然后让想成为观察者和被观察者的对象继承该类即可。
1. 模式的结构
观察者模式的主要角色如下。
- 抽象主题(Subject)角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。
- 具体主题(Concrete Subject)角色:也叫具体目标类,它实现抽象目标中的通知方法,当具体主题的内部状态发生改变时,通知所有注册过的观察者对象。
- 抽象观察者(Observer)角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方法,当接到具体主题的更改通知时被调用。
- 具体观察者(Concrete Observer)角色:实现抽象观察者中定义的抽象方法,以便在得到目标的更改通知时更新自身的状态。
观察者模式的结构图如图 1 所示。

package net.biancheng.c.observer;
import java.util.*;
public class ObserverPattern {
public static void main(String[] args) {
Subject subject = new ConcreteSubject();
Observer obs1 = new ConcreteObserver1();
Observer obs2 = new ConcreteObserver2();
subject.add(obs1);
subject.add(obs2);
subject.notifyObserver();
}
}
//抽象目标
abstract class Subject {
protected List<Observer> observers = new ArrayList<Observer>();
//增加观察者方法
public void add(Observer observer) {
observers.add(observer);
}
//删除观察者方法
public void remove(Observer observer) {
observers.remove(observer);
}
public abstract void notifyObserver(); //通知观察者方法
}
//具体目标
class ConcreteSubject extends Subject {
public void notifyObserver() {
System.out.println("具体目标发生改变...");
System.out.println("--------------");
for (Object obs : observers) {
((Observer) obs).response();
}
}
}
//抽象观察者
interface Observer {
void response(); //反应
}
//具体观察者1
class ConcreteObserver1 implements Observer {
public void response() {
System.out.println("具体观察者1作出反应!");
}
}
//具体观察者1
class ConcreteObserver2 implements Observer {
public void response() {
System.out.println("具体观察者2作出反应!");
}
}操作系统
进程、线程相关
先上最常考的两个:
- 进程和线程的区别?
(1)进程是运行时的程序,是系统进行资源分配和调度的基本单位,它实现了系统的并发;
(2)线程是进程的子单位,也称为轻量级进程,它是CPU进行分配和调度的基本单位,也是独立运行的基本单位,它实现了进程内部的并发;
(3)一个程序至少拥有一个进程,一个进程至少拥有一个线程,线程依赖于进程而存在;
(4)进程拥有独立的内存空间,而线程是共享进程的内存空间的,自己不占用资源;
(5)线程的优势:线程之间的信息共享和通讯比较方便,不需要资源的切换等.
- 进程间通信的方法?
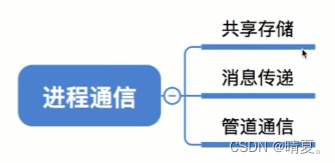

共享存储
设置一个两个进程都能共享存储的区域


往往配合信号量机制进行使用。
因为,当使用共享内存的通信方式,如果有多个进程同时往共享内存写入数据,有可能先写的进程的内容被其他进程覆盖了。因此需要一种保护机制。
信号量本质上是一个整型的计数器,用于实现进程间的互斥和同步。
信号量代表着资源的数量,操作信号量的方式有两种:
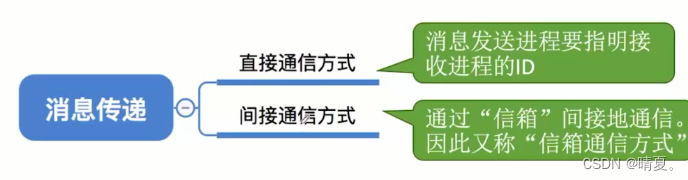
消息传递

分为直接通信方式和间接通信方式:
间接通信方式:
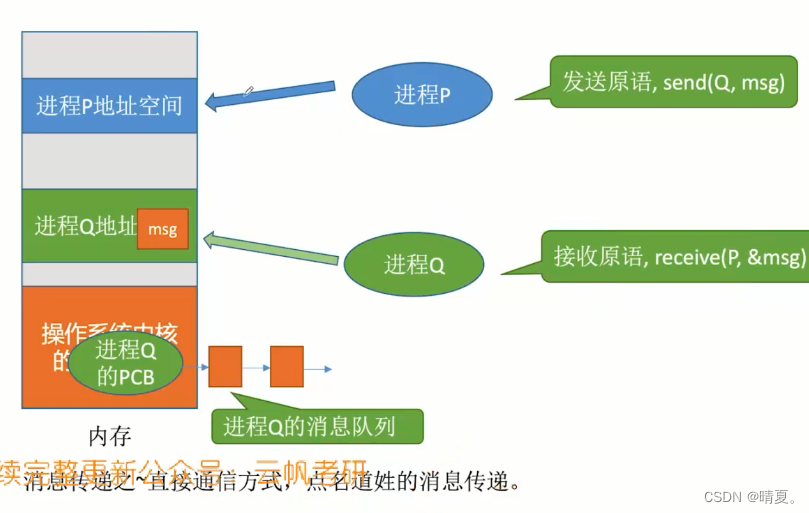
一个进程发消息给信箱,另外的进程从信息中接受消息

管道通信
管道是特殊的共享文件,在内存中开辟一个大小固定的内存缓冲区。
管道的特性是先进先出。并且是半双工通信,单向的传输。

信号
(233条消息) 六种进程间通信方式_modi000的博客-CSDN博客_进程间通信
对于异常情况下的工作模式,就需要用「信号」的方式来通知进程。
信号是进程间通信机制中唯一的异步通信机制,因为可以在任何时候发送信号给某一进程,一旦有信号产生,用户进程就会对信号做出处理。
在 Linux 操作系统中, 为了响应各种各样的事件,提供了几十种信号,分别代表不同的意义。
socket
前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
socket是一个套接字,通过四元组(在tcp中为四元组,即源ip地址,目的ip地址,源端口号,目的端口号,在udp中只需要源ip地址和源端口号即可)来唯一标识接收和发送数据的两方,用于这两方之间的通信。
- 进程有什么状态?状态间是如何互相转换的?
进程有着「运行 - 暂停 - 运行」的活动规律。一般说来,一个进程并不是自始至终连续不停地运行的,它与并发执行中的其他进程的执行是相互制约的。
它有时处于运行状态,有时又由于某种原因而暂停运行处于等待状态,当使它暂停的原因消失后,它又进入准备运行状态。
所以,在一个进程的活动期间至少具备三种基本状态,即运行状态、就绪状态、阻塞状态。

上图中各个状态的意义:
-
运行状态(Runing):该时刻进程占用 CPU;
-
就绪状态(Ready):可运行,但因为其他进程正在运行而暂停停止;
-
阻塞状态(Blocked):该进程正在等待某一事件发生(如等待输入/输出操作的完成)而暂时停止运行,这时,即使给它CPU控制权,它也无法运行;
当然,进程另外两个基本状态:
-
创建状态(new):进程正在被创建时的状态;
-
结束状态(Exit):进程正在从系统中消失时的状态;
于是,一个完整的进程状态的变迁如下图:

进程五种状态的变迁
-
NULL -> 创建状态:一个新进程被创建时的第一个状态;
-
创建状态 -> 就绪状态:当进程被创建完成并初始化后,一切就绪准备运行时,变为就绪状态,这个过程是很快的;
-
就绪态 -> 运行状态:处于就绪状态的进程被操作系统的进程调度器选中后,就分配给 CPU 正式运行该进程;
-
运行状态 -> 结束状态:当进程已经运行完成或出错时,会被操作系统作结束状态处理;
-
运行状态 -> 就绪状态:处于运行状态的进程在运行过程中,由于分配给它的运行时间片用完,操作系统会把该进程变为就绪态,接着从就绪态选中另外一个进程运行;
-
运行状态 -> 阻塞状态:当进程请求某个事件且必须等待时,例如请求 I/O 事件;
-
阻塞状态 -> 就绪状态:当进程要等待的事件完成时,它从阻塞状态变到就绪状态;
另外,还有一个状态叫挂起状态,它表示进程没有占有物理内存空间。这跟阻塞状态是不一样,阻塞状态是等待某个事件的返回。
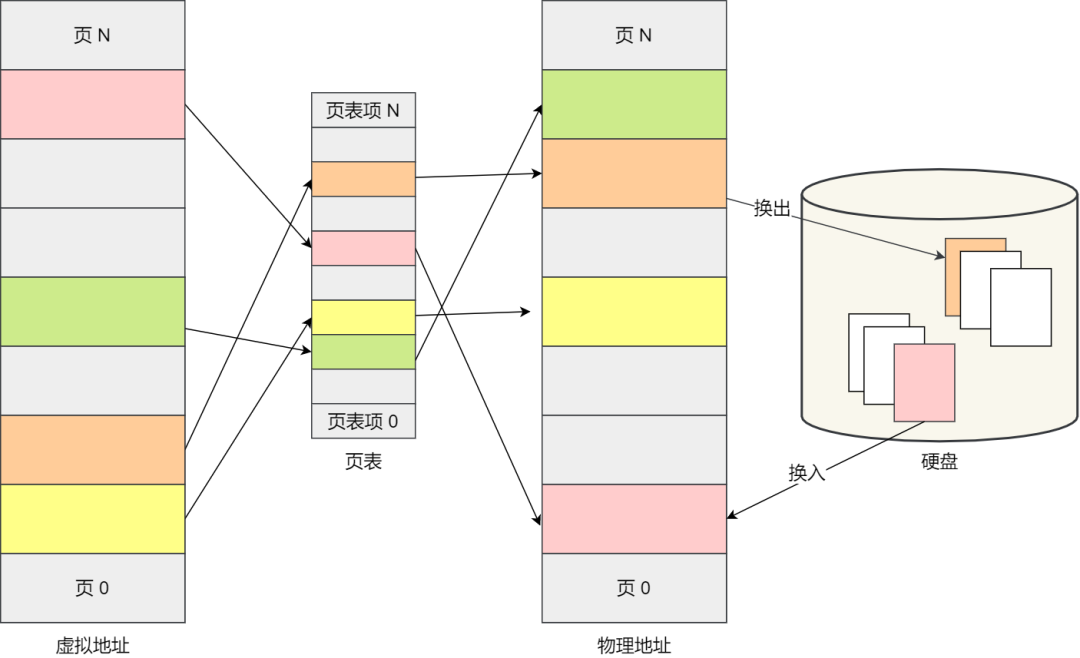
↑虚拟内存管理-换入换出
挂起状态可以分为两种:
-
阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现;
-
就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立刻运行;
这两种挂起状态加上前面的五种状态,就变成了七种状态变迁(留给我的颜色不多了),见如下图:

七种状态变迁
- 进程同步、异步是什么意思?
(187条消息) 进程同步/异步的区别_木石_m的博客-CSDN博客_异步进程
同步:在多道程序环境下,进程是并发执行的,不同进程之间存在着不同的相互制约关系。这些进程需要协调他们间的工作次序,这种制约关系叫做同步。
异步性:各并发执行的进程以各自独立的、不可预知的速度向前推进。
同步是指两个进程的运行是相关的,其中一个进程要阻塞等待另外一个进程的运行。异步的意思是两个进程毫无相关,自己运行自己的。
- 进程互斥是什么意思?
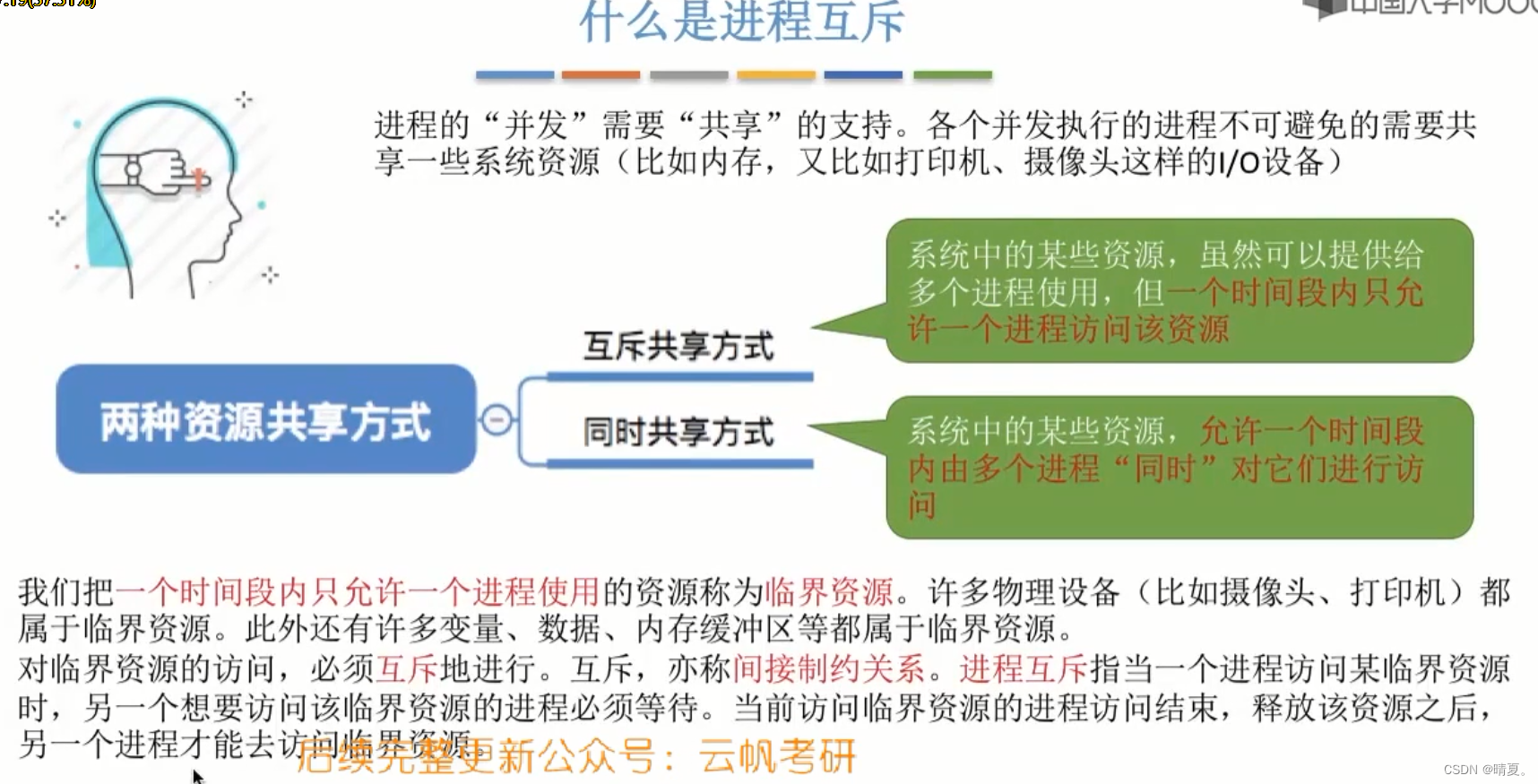
信号量机制

对记录型信号量进行总结:

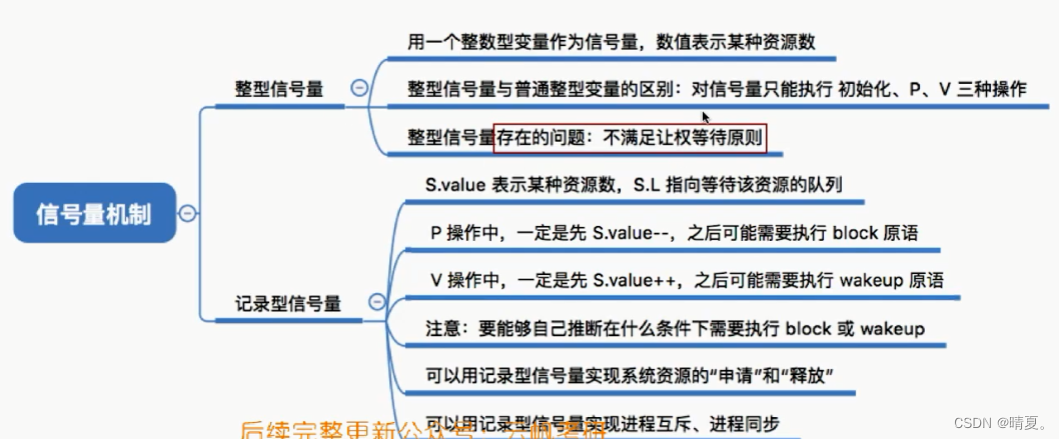
用信号量实现进程互斥、同步、前驱

- 信号量机制实现进程互斥

- 信号量机制实现进程同步

为了保证代码12在代码4之前执行,加入下面的操作:


- 用信号量实现进程前驱关系


进程调度算法
-
先来先服务(FCFS)调度算法:按照进程到达的顺序依次分配 CPU 时间片,优点是简单易实现,但是容易导致平均等待时间长。
-
短作业优先(SJF)调度算法:按照进程需要的 CPU 时间长度进行排序,优先分配 CPU 时间片给需要时间短的进程,可减少平均等待时间,但是容易出现饥饿现象。
-
优先级调度算法:为每个进程赋予一个优先级,优先级高的进程优先获得 CPU 时间片,可根据实际需求对不同进程设置不同的优先级,但是容易出现优先级反转问题。
-
时间片轮转调度算法:将 CPU 时间片分为固定长度,按照进程到达的顺序依次分配 CPU 时间片,但是当一个进程的时间片用完后,会将其挂起并放到队列末尾,下一个进程继续执行,可保证所有进程都能获得一定的 CPU 时间,但是当时间片长度过短时,容易出现过多的进程切换,影响性能。
-
多级反馈队列调度算法:将就绪队列分成多个队列,每个队列有不同的时间片长度和优先级,进程从最高优先级队列开始执行,如果用完时间片还未完成,则将进程降到下一个优先级队列,并重新分配时间片,直到进程执行完毕或者降到最低优先级队列,可兼顾长短作业和响应时间的要求,但是实现较为复杂。
页式存储系统与虚拟内存
- 内存与外存的区别
内存是计算机的工作场所,cpu可以直接访问,外存,比如硬盘这种用来存储暂时不用读取的数据。
内存和主存的区别?(主存是内存里的一部分,内存还包括其他东西)
- 操作系统如何管理内存,什么是虚拟内存?
通过一种分页管理机制来进行内存管理。分页管理机制将程序的逻辑地址划分为固定大小的页,而物理内存划分为同样大小的块,程序加载时,可以将任意一页放入内存中任意一个块,这些块不必连续,从而实现了离散分离。(如果不是离散型的,那容易产生内存碎片)
虚拟内存是基于分页存储管理机制的,它使得应用程序认为它拥有连续可用的内存,但实际上,操作系统只是将一部分页映射到内存中,另一部分页放在外存上(如磁盘、软盘、USB),当引用到不在内存中的页时,系统产生缺页中断,并从外存中调入该部分页进来,从而产生一种逻辑上内存得到扩充的感觉,实际上内存并没有增大。
- 虚拟内存?为什么要使用虚拟内存?
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
原来程序指令所访问的内存地址就是物理内存地址.,也就是不得不把程序的全部装进内存当中,然后运行。
这样会导致一些问题,:
- 内存空间利用率的问题
各个进程对内存的使用会导致内存碎片化,当要用malloc分配一块很大的内存空间时,可能会出现虽然有足够多的空闲物理内存,却没有足够大的连续空闲内存这种情况,东一块西一块的内存碎片就被浪费掉了。
2. 内存读写的效率问题
当多个进程同时运行,需要分配给进程的内存总和大于实际可用的物理内存时,需要将其他程序暂时拷贝到硬盘当中,然后将新的程序装入内存运行。由于大量的数据频繁装入装出,内存的使用效率会非常低
每个进程创建加载的时候,会被分配一个大小为4G的连续的虚拟地址空间,虚拟的意思就是,其实这个地址空间时不存在的,仅仅是每个进程“认为”自己拥有4G的内存,而实际上,它用了多少空间,操作系统就在磁盘上划出多少空间给它,等到进程真正运行的时候,需要某些数据并且数据不在物理内存中,才会触发缺页异常,进行数据拷贝。
操作系统向进程描述了一个完整的连续的虚拟地址空间供进程使用,但是在物理内存中进程数据的存储采用离散式存储(提高内存利用率),但是其实虚拟内存和物理内存之间的关系并不像上图中那样直接,其中还需要使用页表映射虚拟地址与物理地址的映射关系,并且通过页表实现内存访问控制。这个页表又是何方神圣?
- 什么是页表?
核心功能就是记录每个逻辑页面放在哪个主存块中,实现一个逻辑地址到物理地址的映射。
页表是一种特殊的数据结构,存放着各个虚拟页的状态,是否映射,是否缓存.。进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,这就需要用页表来记录。页表的每一个表项分为两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)。当进程访问某个虚拟地址,就会先去看页表,如果发现对应的数据不在物理内存中,则发生缺页异常。
- 这里补充一下页式存储
页式存储系统:一个进程在逻辑上被分为若干个大小相等的页面。
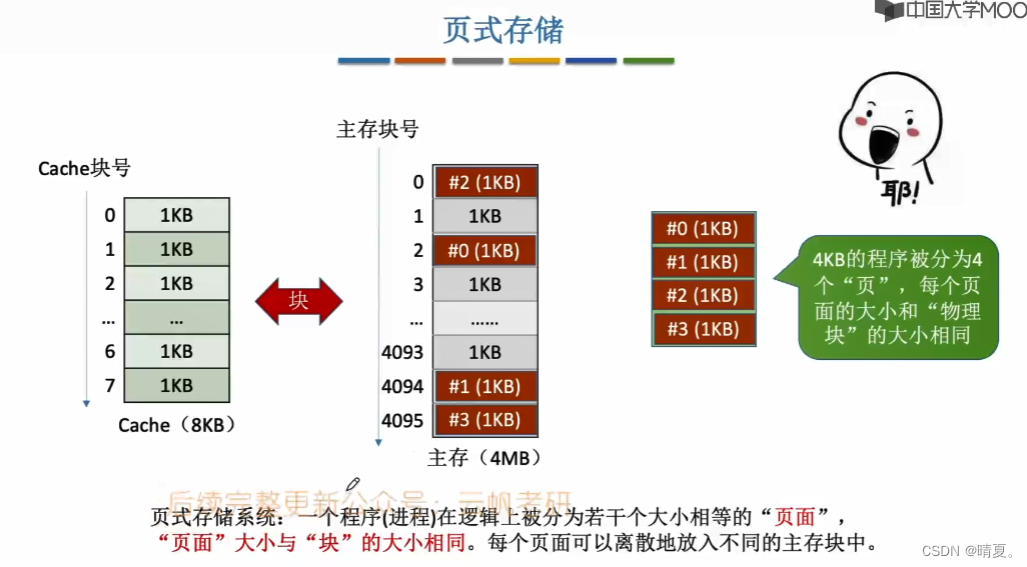
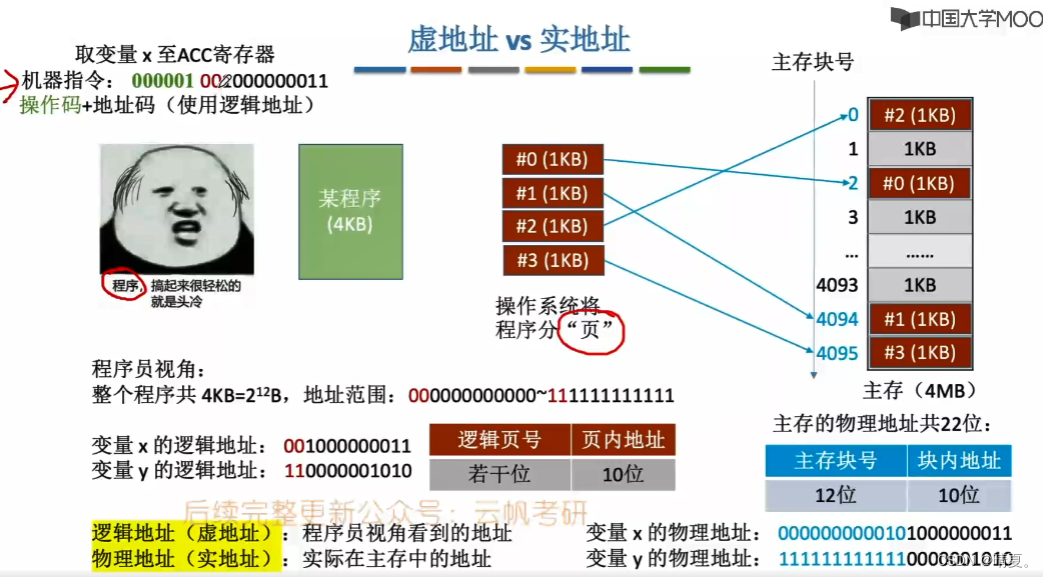
每个页面都在主存块中有所对应,逻辑地址由两部分组成,逻辑页号和页内地址。而实现逻辑地址到物理地址映射的就是通过页表。

每个逻辑页号会对应一个主存块号。
接下来,通过页表获取了对应的物理地址后,就先去Cache中看数据是否存在,如果Cache没找到,cpu才会去主存里面寻找资源。

而类似会将一部分内存放入cache中,页表也存在这样的机制。
例如上面访问了逻辑页号0,那么根据局部性原理,在接下来一段时间内可能都会访问该页面,而页表是存储在主存中的,访问速度较慢,因此为了加快访问速度,按照类似Cache一样的机制建立一个叫做快表的东西。
引入快表后地址变换过程如下:

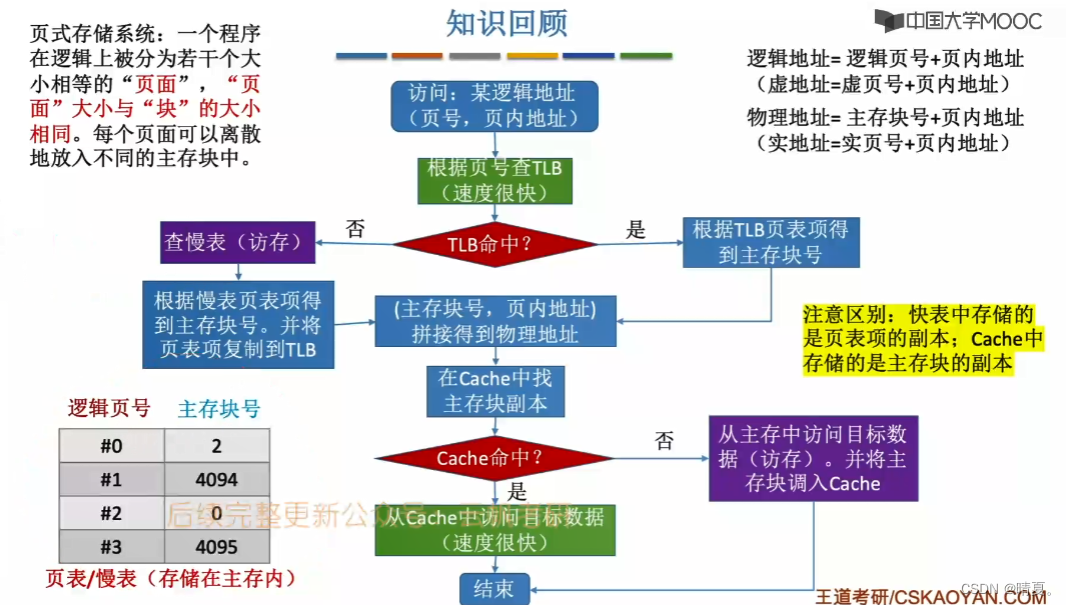
虚拟内存会先将暂时需要用到的程序内存放在主存中,而暂时用不上的则不会调入。
在之前的页表中只是实现了逻辑地址到主存地址的实现,但如果该页面不在主存而在外存中,这时候我们给页表拓展功能:
加入两个,外存块号和有效位,对应的是该页面在外存块的哪个地方,访问位为1说明在主存中。
如果此时在主存中没有该页面,那么就可以根据外存块号到对应的块去获取页面了。
而这个访问位就是用于进行页面替换算法的:



- 段式存储器和页式存储器有什么区别?
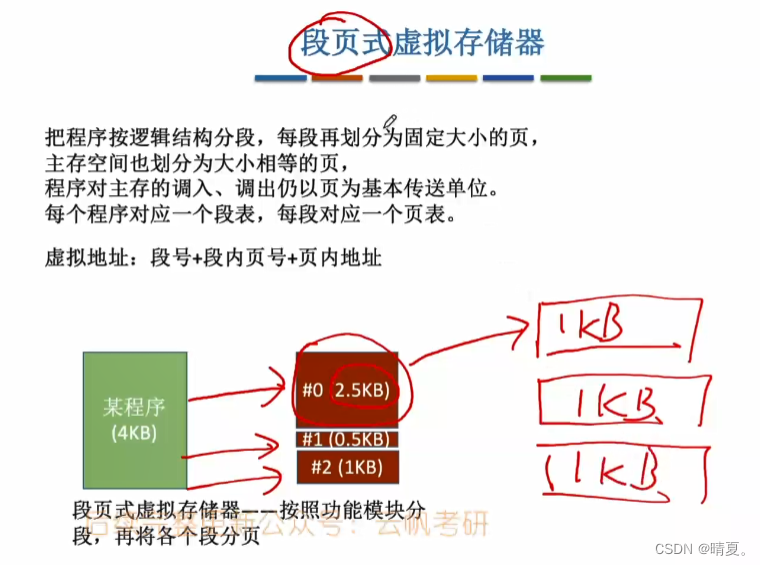
段式虚拟存储器和页式虚拟存储器的区别就是在于拆分页面时的逻辑不同:

虚拟内存的工作原理
当一个进程试图访问虚拟地址空间中的某个数据时,会经历下面两种情况的过程:
- CPU想访问某个虚拟内存地址,找到进程对应的页表中的条目,判断有效位, 如果有效位为1,说明在页表条目中的物理内存地址不为空,根据物理内存地址,访问物理内存中的内容,返回
- CPU想访问某个虚拟内存地址,找到进程对应的页表中的条目,判断有效位,如果有效位为0,但页表条目中还有地址,这个地址是磁盘空间的地址,这时触发缺页异常,系统把物理内存中的一些数据拷贝到磁盘上,腾出所需的空间,并且更新页表。此时重新执行访问之前虚拟内存的指令,就会发现变成了情况1.
- 什么是内存碎片,内存碎片是在虚拟内存还是物理内存?
采用分区式存储管理的系统,在储存分配过程中产生的、不能供用户作业使用的主存里的小分区称成“内存碎片”。内存碎片分为内部碎片和外部碎片。内存碎片只存在于虚拟内存上。
- 什么是死锁,死锁的条件以及如何防止?
(1)死锁就是多个进程并发执行,在各自占有一定资源的情况下,希望获得其他进程占有的资源以推进执行,但是其他资源同样也期待获得另外进程的资源,大家都不愿意释放自己的资源,从而导致了相互阻塞、循环等待,进程无法推进的情况。
(2)死锁条件:1)互斥条件(一个资源每次只能被一个进程使用);2)请求并保持条件(因请求资源而阻塞时,对已获得的资源保持不放);3)不剥夺条件(在未使用完之前,不能剥夺,只能自己释放);4)循环等待(若干进程之间形成一种头尾相接的循环等待资源关系)。
(3)死锁防止:1)死锁预防,打破四个死锁条件;2)死锁避免,使用算法来进行资源分配,防止系统进入不安全状态,如银行家算法;3)死锁检测和解除,抢占资源或者终止进程;
什么是银行家算法?(⭐⭐)
(4)银行家算法是一种最有代表性的避免死锁的算法。在避免死锁方法中允许进程动态地申请资源,但系统在进行资源分配之前,应先计算此次分配资源的安全性,若分配不会导致系统进入不安全状态,则分配,否则等待。为实现银行家算法,系统必须设置若干数据结构。安全的状态指的是一个进程序列{P1,P2,...Pn},对于每一个进程Pi,它以后尚需要的资源不大于当前资源剩余量和其余进程所占有的资源量之和。
计算机网络
待解决的问题:
- ping返回来的结果有什么特点
- ping命令执行后,数据包是怎么过去的
HTPP1.X与HTTP2.0的区别
tcp与udp,tcp的滑动窗口为0会断开连接吗
http2.0的分帧,多路复用等内容
tcp的三次握手与四次分手问的比较细(三次为什么不能两次,四次分手的第二次与第三次为什么不能合为一次,发送端为什么要等待两个MSL)
11.http2,http3,http1.1
12.http2有多路复用
6. 数据库的主键约束和外键约束
7. 什么是事务?
8. 事务的原子性是什么?
9. MySQL中,select是怎么查询到数据的?具体执行过程是什么
设计模式
登录注册的前后端整体流程。
TCP理论基础
- TCP和UDP的区别?
(1)TCP是传输控制协议,UDP是用户数据报协议;
(2)TCP是面向连接的,可靠的数据传输协议,它要通过三次握手来建立连接,UDP是无连接的,不可靠的数据传输协议,采取尽力而为的策略,不保证接收方一定能收到正确的数据;
(3)TCP面向的是字节流,UDP面向的是数据报;
(4)TCP只支持点对点,UDP支持一对一,一对多和多对多;
(5)TCP有拥塞控制机制,UDP没有。
- 什么是面向连接,什么是无连接服务?有什么区别?
面向连接是一种网络协议,网络系统需要在两台计算机之间发送数据之前先建立连接,当数据传输完毕需要释放的一种特性。
面向无连接是通信技术之一。是指通信双方不需要事先建立一条通信线路,而是把每个带有目的地址的包(报文分组)送到线路上,由系统自主选定路线进行传输。
面向连接的通信可以保证数据的有序性,面向无连接的不能保证收发数据的顺序一致。
- TCP的字节流和数据报有什么区别?
“TCP是一种流模式的协议,UDP是一种数据报模式的协议”
TCP连接给另一端发送数据,调用一次write发送一次数据,对方可以分多次接受完,一次接受一部分数据。
UDP不同,对于UDP来说,发送端调用几次write,接收端必须使用相同次数的read读完。每次读取一个报文。
- TCP如何保证可靠传输?
有以下六种:校验和、序列号和确认应答、超时重传、连接管理、流量控制、拥塞控制




流量控制的细节见下方:


当拥塞窗口未达到阈值时,使用慢开始

达到阈值时使用拥塞避免,每次窗口大小增加一:

接下来,当重传计时器超时时,我们认为发生了拥塞情况,执行以下操作:

接下来继续使用慢启动算法,直到达到阈值,此时继续执行拥塞避免算法:

完整过程如图所示:
慢开始不是指增长速度慢,而是一开始的数量少。

但是将拥塞窗口重新设置为1,效率比较低下:

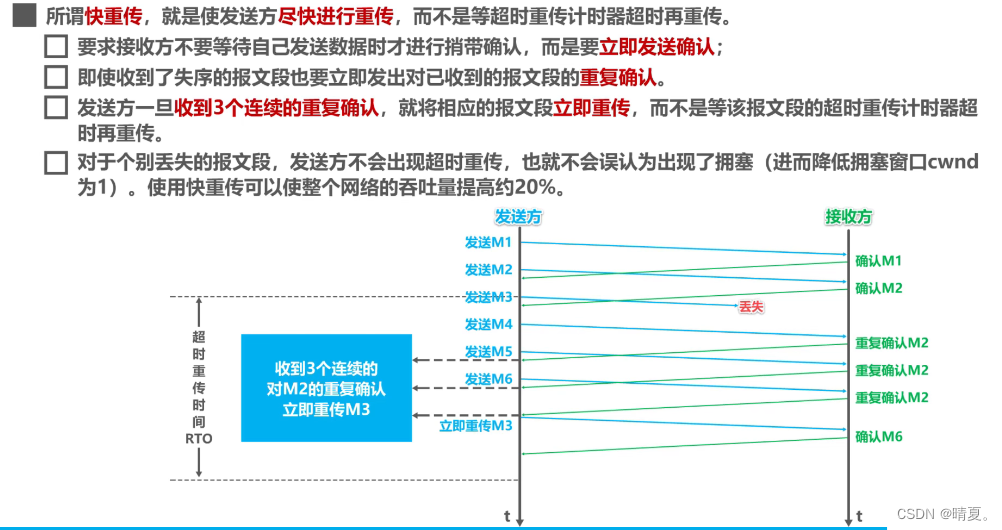
- 快重传算法
如下方右图所示,丢失了发送的M3,即使后面发送方一直发送新的,接收方回的确认号也是旧的未接收的报文序号。当发送方受到三个连续的重复确认时,立即重新发丢失的报文。
随后接收方回复确认收到了刚才那个丢失的,接下来回到之前的状态。
于是回到之前的那个出现拥塞避免的情况,我们不再是把发送拥塞后,把窗口设置为1,而是执行快恢复算法。
- 快恢复

如图所示:

流量控制与滑动窗口
流量控制与拥塞控制的区别:
主要区别:流量控制解决的是发送方和接收方速率不匹配的问题;拥塞控制解决的是避免网络资源被耗尽的问题。流量控制是通过滑动窗口来实现的;拥塞控制是通过拥塞窗口来实现的。



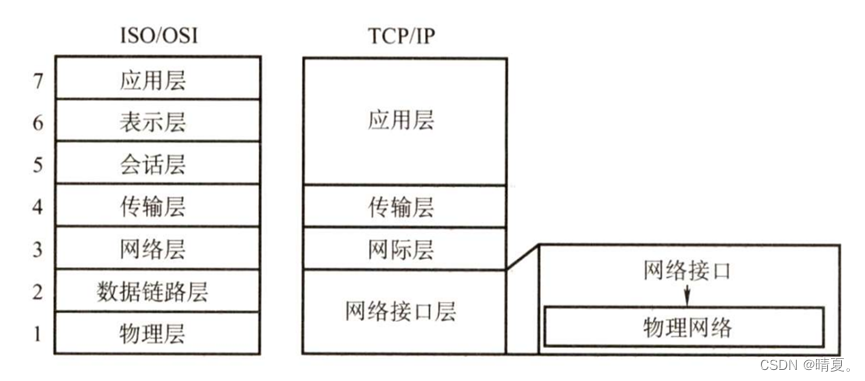
OSI七层模型和TCP/IP五层模型
- OSI七层模型和TCP/IP五层网络模型
(物联网淑慧试用)
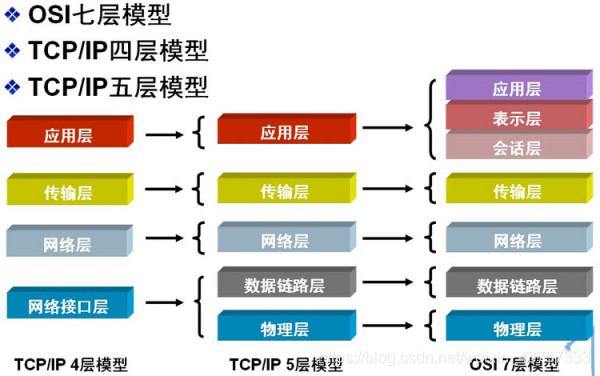
这些层分别是什么功能?

第一层是物理层,也是最低层
应用层:应用层,顾名思义,它就是为应用程序提供网络服务的,它是网络服务与最终用户的一个接口。
典型应用层服务:

表示层:它会对数据进行编码,对信息进行加密解密等,是用来处理不同通信系统交换信息时需要转换表示方式。
发送数据时,将应用层的数据格式转换为适合传输的数据格式(如01编码),在接收数据时,表示层再将通用的数据格式转化成应用层能够理解的数据(如jpg和mp4)。

会话层:会话层允许不同主机上的各个进程之间进行会话。
建立两个app之间的会话,用于建立、维护、终止连接
用于建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
如下图所示·:
传输层:负责不同主机进程间的通信连接建立,保证传输可靠。即端到端的通信(端指的是端口),端到端的通信是指运行在不同主机内的两个进程之间的 通信,一个进程由一个端口来标识,所以称为端到端通信
通过TCP或UDP连接建立。
传输单位是报文段或用户数据报。
网络层:基于ip地址进行路由转发
对于每个包根据ip地址发送来选择发送到哪里
网络层会在数据段上添加发送方和接收方的ip地址
协议有:ICMP IGMP IP(IPV4 IPV6) ARP



数据链路层:将网络层传过来的的数据报组装成帧。并且还会进行差错控制,此时传输单位是帧,封装成帧后可以保证数据帧在物理层上传输。
数据链路层提供的是点到点的通信,传输层提供的是端到端的通信,两者不同。
通俗地说, 点到点可以理解为主机到主机之间的通信,端到端则是端口到端口的通信。
物理层会把数据帧转化成比特,然后通过物理设备和媒介(例如光纤)在网络中传播。
然后比特数据会被另外的电脑在物理层接收,然后物理层将比特数据转化成链路层需要的数据帧。数据帧再被链路层准确无误的传到网络层,然后转化成数据报格式,然后传送到传输层、会话层、表示层、最后到应用层。
七层模型传输数据过程:

TCP/IP模型
模型从低到高依次为网络接口层(对应OSI参考模型中的物理层和数据链路层)、网际层、传输层和应用层(对应OSI参考模型中的会话层、 表示层和应用层)。TCP/IP由于得到广泛应用而成为事实上的国际标准
MAC地址、IP地址都是什么?为什么要有MAC和IP地址?区别是什么?
MAC地址在数据链路层工作,是绑定物理网卡,出厂时决定,是独一无二的。
IP地址在互联网的逻辑上代表一个设备,在ip地址使用到期后,ip地址会被重新分配,然后再次绑定到其他设备上。
- DHCP协议是用来干嘛的?
当离开局域网,需要去到互联网进行通信时,我们需要使用IP地址来进行通信,如果我们没有去配置IP地址,此时DHCP协议会自动为我们配置IP地址。
- ARP协议是干嘛的?与互联网内的另外一台主机进行通信时,我们不能直接通信,需要获取对方的MAC地址后才能进行通信,但是我们只知道IP地址。
而通过ARP协议,我们可以将IP地址转化为MAC地址。
Arp协议Address Resolution Protocol 意思是解决地址问题的协议
(方式是通过广播的形式:发送ARP广播,询问是否有人的IP地址是这个,如果有人的IP地址是这个,那么请告诉我MAC地址是多少)

然后IP地址符合的则会将自己的MAC地址返回给请求的客户端。
- 接下来客户端会将这个IP地址对应的MAC地址缓存起来以便于下次使用。
- 子网和子网掩码是什么?
网络中有很多的IP地址,我们希望对其进行分类,以便于管理,所以我们将网络划分为不同的子网。而IP地址也是由网络号和主机号所组成。
例如下面这个,前面的24位就是网络号,后面8位则是主机号。
这就有点类似A班同学的1号,A班同学的2号,3号这样的形式。

如果给定了一个IP地址,也给定了它的子网掩码,我们就可以确定它是属于哪一个子网,在这个子网中它是几号。

假如上面这个IP地址的子网掩码是24,那么其子网掩码是这样的:

换成16进制就是255.255.255.0
如果一个ip的子网掩码是24位,就代表这个ip地址的前24位是网络号,而剩下的位数就是主机号,如下所示

不同的子网掩码及其对应的主机数:
下面的那些从32、31、30…,ip地址的前面这些位数就是网络号,而剩下的部分则是主机号,主机数就代表这个长度的网络号的子网下,能有多少台主机,
主机数其实就是2^(32-CIDR)

- 五类IP地址


一般有两种特殊的ip地址不会用来分配:
当主机号全部取0时,代表的是网络号,
而子网号全为1时,代表的是则是这个子网的广播地址,例如下面这个ip地址,其子网掩码是24位,最后的8位就是主机号,也就是下图紫色部分,代表的是0:

而下图中最后的8位全为1,代表的则是广播地址:

- 路由是什么?
根据目标ip判断如何发送的方式就是路由

- NAT协议是什么?
NAT协议通常用于公网和内网的IP地址转换,内网的设备想访问公网时,就需要将IP地址转化为公网的IP地址,这就是通过NAT协议来进行的。
并且NAT协议还可以让多个内网的设备使用同一个公网IP地址,这样可以节省公网IP地址的使用,也可以增强网络安全性。
- SNAT和DNAT是什么?
SNAT 和 DNAT 是 NAT 协议中的两种转换方式,分别用于实现源地址转换和目的地址转换。具体来说:
-
SNAT:SNAT(Source Network Address Translation,源地址转换)是一种 NAT 技术,用于将源 IP 地址转换为另一个 IP 地址。SNAT 主要用于将私有 IP 地址转换为公共 IP 地址,从而允许内部网络上的计算机访问互联网或外部网络。
-
DNAT:DNAT(Destination Network Address Translation,目的地址转换)是一种 NAT 技术,用于将目标 IP 地址转换为另一个 IP 地址。DNAT 主要用于将公共 IP 地址转换为内部网络中的私有 IP 地址,从而允许外部网络访问内部网络上的计算机。在 DNAT 转换过程中,目标 IP 地址会被替换成内部网络中的私有 IP 地址。(端口映射是DNAT技术的一种具体实现方式)
TCP
- 为什么需要TCP?TCP 工作在哪一层?
IP 层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。
如果需要保障网络数据包的可靠性,那么就需要由上层(传输层)的 TCP 协议来负责。
因为 TCP 是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
- 什么是 TCP ?
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
-
面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
-
可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
-
字节流:用户消息通过 TCP 协议传输时,消息可能会被操作系统「分组」成多个的 TCP 报文,如果接收方的程序如果不知道「消息的边界」,是无法读出一个有效的用户消息的。并且 TCP 报文是「有序的」,当「前一个」TCP 报文没有收到的时候,即使它先收到了后面的 TCP 报文,那么也不能扔给应用层去处理,同时对「重复」的 TCP 报文会自动丢弃。
- TCP三次握手?四次挥手?
具体可以见我写的另外一篇:
(253条消息) 详解三次握手与四次挥手及相关面试题回答_晴夏。的博客-CSDN博客
面试回答:TCP/IP是传输层面向连接的可靠协议,三次握手的机制是为了保证安全可靠的连接。
三次握手其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。
具体过程如下:
SYN:同步序列编号(Synchronize Sequence Numbers)
ack(acknowledge)
第一次由客户端向服务器发送报文,这个报文的SYN位置一,代表请求建立连接,并包含seq报文序列号。
第二次:服务器收到报文后会知道客户端请求建立连接,于是向客户端发送确认消息报,SYN置1表示建立连接,ACK置一,并且ack设置为第一次握手中的seq+1。
第三次:在服务器发送报文后,服务器方不知道自己的报文是否发送成功,因此此时需要第三次握手,客户端发送报文,并且ACK位置1,表示客户端已经收到服务器端的确认报文了。
在三次握手结束后,双方都知道了可以发送和接受到对方的消息,此时连接成功建立,接下来双方就可以进行数据的发送了。
四次挥手:
(1)首先由客户端发起,表示请求断开连接,此时客户端发送请求断开连接的报文,FIN置一。
(2)服务器端接收到从客户端发出的TCP报文之后,确认了客户端想要释放连接,于是返回一段TCP报文告知服务器自己知道了。随后服务器端结束ESTABLISHED阶段,进入CLOSE-WAIT阶段(半关闭状态)
前"两次挥手"既让服务器端知道了客户端想要释放连接,也让客户端知道了服务器端了解了自己想要释放连接的请求。于是,可以确认关闭客户端到服务器端方向上的连接了。
(3)当服务器端收到报文后,此时可能还没准备好断开连接,此时可能还有需要继续发送的报文。当服务器准备好的时候,服务器向客户端发送请求断开连接的报文,FIN置1.
(4)服务器并不知道自己是否发送成功,于是最后还需要一次挥手,就是让客户端向服务器发送收到断开信息的报文。
http和https
- http和https是什么,有什么区别?
具体可以查看这篇文章:
HTTP
HTTP (HyperText Transfer Protocol),即超文本传输协议,是实现网络通信的一种规范。
HTTP是一个传输协议,即将数据由A传到B或将B传输到A,并且 A 与 B 之间能够存放很多第三方,如:A<=>X<=>Y<=>Z<=>B。
HTTP传递信息是以明文的形式发送内容,这并不安全。而HTTPS出现正是为了解决HTTP不安全的特性。
为了保证这些隐私数据能加密传输,让HTTP运行安全的SSL/TLS协议上,即 HTTPS = HTTP + SSL/TLS,通过 SSL证书来验证服务器的身份,并为浏览器和服务器之间的通信进行加密。
HTTP 和 HTTPS 使用连接方式不同,默认端口也不一样,HTTP是80,HTTPS是443。HTTPS 由于需要设计加密以及多次握手,性能方面不如 HTTP。
- https是怎么实现保密性的?https,SSL,TLS都是什么
https的核心本质还是使用高效的对称通信方式来进行传输,但是想使用这种方式就得对这个对称的密钥通过各种手段保证双方拿到的是可靠。
在TLS的四次握手中,通过非对称传输密钥的方式,互相传输三个随机数,用这三个随机数生成对称加密的会话密钥,然后最后双方使用这个对称的密钥通信。
在握手过程中,关键在于第三个随机数是可靠的,这个随机数是客户端生成传给服务器的,为了保证可靠,客户端会使用服务器传来的公钥进行加密,然后服务器用只有自己有的私钥进行解密。
但是如何保证服务器给出去的公钥可靠呢?服务器就让第三方担保。
为了保证服务器给客户端的公钥是可靠的,服务器向第三方认证的机构CA申请证书,然后服务器再将公钥附在证书上传给客户端。客户端收到证书后,首先判断域名是否为目标域名,然后比对数字签名(这个数字签名就是证书的摘要,是经过加密的)和使用摘要算法得出的信息是否正确(即验签)。这样即可保证最后客户端传给服务器的随机数可靠。
- 数字签名是怎么加密的?它为什么可靠?
数字签名,它经过CA上的私钥加密过,只有客户端用一开始就存在于客户端的操作系统内部存储的公钥才可以解密,这个公钥别人没有。
- socket编程?
socket是用于不同主机通信的api
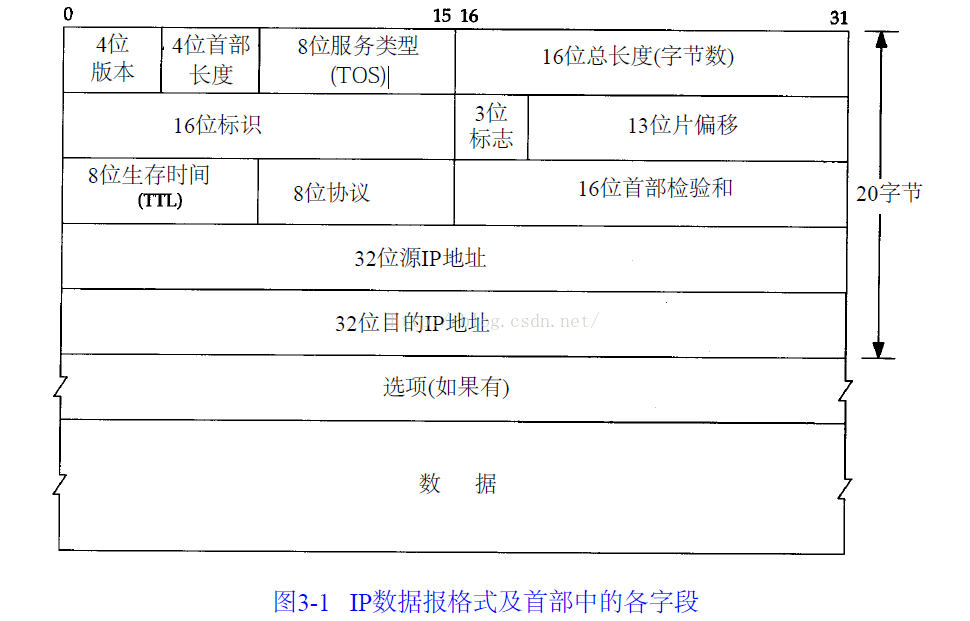
- IP协议的首部结构
首部协议一共是20个字节(固定)
第一个4字节: 版本号;首部长度; 服务类型;总长度;
第二个4字节:标识;标志;片偏移;
第三个4字节:生存时间;协议;校验和;
第四个4字节:源ip地址;
第五个4字节:目的ip地址;
- TCP/IP协议簇是什么?
TCP/IP协议族是一组协议的集合,也叫互联网协议族,用来实现互联网上主机之间的相互通信。TCP和IP只是其中的2个协议,也是很重要的2个协议,所以用TCP/IP来命名这个互联网协议族,实际上,它还包括其他协议,比如UDP、ICMP、IGMP、ARP/RARP等
互联网协议族TCP/IP按粗粒度的四层划分,两种划分的对照图让彼此关系一目了然。

当键入网址后,到网页显示,其间发生了什么?
(12条消息) 当键入网址后,到网页显示,其间发生了什么?_小林coding的博客-CSDN博客
浏览器做的第一步工作是解析 URL,对URL进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了。
需要委托操作系统将消息发送给 web 服务器。但在发送之前,还得查询服务器域名对于的 IP 地址,因为委托操作系统发送消息时,必须提供通信对象的 IP 地址。
然后使用 DNS 服务器,查询Web 服务器域名与 IP 的对应关系。
获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。(协议栈的内部分为几个部分,分别承担不同的工作。上下关系是有一定的规则的,上面的部分会向下面的部分委托工作,下面的部分收到委托的工作并执行。)
应用程序(浏览器)通过调用 Socket 库,来委托协议栈工作。协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,它们两会接受应用层的委托执行收发数据的操作。
协议栈的下面一半是用 IP 协议控制网络包收发操作,在互联网上传数据时,数据块被切分成一块块的网络包,而将网络包发送给对方的操作就是由 IP 负责的。
此外 IP 中还包括 ICMP 协议和 ARP 协议。
ICMP用于告知网络包传送过程中产生的错误以及各种控制信息。ARP用于根据 IP 地址查询相应的以太网 MAC 地址。
IP 下面的网卡驱动程序负责控制网卡硬件,然后由物理网卡硬件则负责完成实际的收发操作,也就是对网线中的信号执行发送和接收操作。
HTTP 是基于 TCP 协议传输的,因此需要建立TCP连接,那么就需要三次握手。
建立连接后,如果 HTTP 请求消息比较长,超过了 MSS 的长度,这时 TCP 就需要把 HTTP 的数据拆解一块块的数据发送,而不是一次性发送所有数据。
数据会被以 MSS 的长度为单位进行拆分,拆分出来的每一块数据都会被放进单独的网络包中。也就是在每个被拆分的数据加上 TCP 头信息,然后交给 IP 模块来发送数据。
TCP 报文生成
在双方建立了连接后,TCP 报文中的数据部分就是存放 HTTP 头部 + 数据,组装好 TCP 报文之后,就需交给下面的网络层处理。
至此,网络包的报文如下图。
- 从输入URL到页面展示发生了什么?
总的来说,分为以下几个过程:
1、DNS 解析
2、TCP 连接
3、发送 HTTP 请求
4、服务器处理请求并返回 HTTP 报文
5、浏览器解析渲染页面
1.DNS解析
当你在浏览器中输入一个域名时,会先通过DNS解析找到域名对应的IP地址。
先进行本地 DNS 服务器解析,递归解析:

如果本地解析不到,则根据本地 DNS 服务器设置的转发器进行查询,若未用转发模式,再去域名服务器解析,迭代解析:

结合起来的过程,可以用一个图表示:

补充一下:
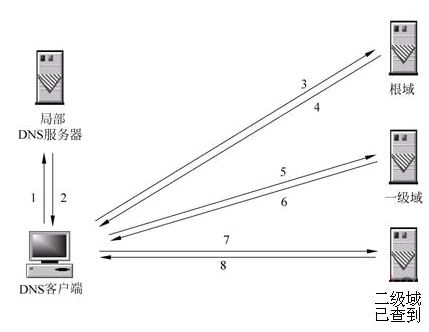
- DNS查询的两种方式:递归查询和迭代查询
1、递归解析
当局部DNS服务器自己不能回答客户机的DNS查询时,它就需要向其他DNS服务器进行查询。
如图所示递归方式:局部DNS服务器自己负责向其他DNS服务器进行查询,一般是先向该域名的根域服务器查询,再由根域名服务器一级级向下查询。最后得到的查询结果返回给局部DNS服务器,再由局部DNS服务器返回给客户端。

2、迭代解析
如图所示迭代解析:局部DNS服务器不是自己向其他DNS服务器进行查询,而是把能解析该域名的其他DNS服务器的IP地址返回给客户端DNS程序,客户端DNS程序再继续向这些DNS服务器进行查询,直到得到查询结果为止。
也就是说,迭代解析只是帮你找到相关的服务器而已,而不会帮你去查。比如说:baidu.com的服务器ip地址在192.168.4.5这里,你自己去查吧,本人比较忙,只能帮你到这里了。
续接上面的,
2.建立 TCP 连接
三次握手
拿到 IP 地址之后,我们就可以建立 TCP 连接了,要进行三次握手:
建立 TLS 连接
建立 TCP/IP 连接后,如果发现请求协议是 HTTPS,还需要建立 TLS 连接。 这个“握手过程”与 TCP 类似,是 HTTPS 和 TLS 协议里最重要、最核心的部分。
3.发送 HTTP 请求
现在TCP连接建立完毕,浏览器可以和服务器开始通信,即开始发送 HTTP 请求。浏览器发 HTTP 请求要携带三样东西:请求行、请求头和请求体。
4.网络响应
HTTP 请求到达服务器,服务器进行对应的处理。最后要把数据传给浏览器,也就是返回网络响应。
跟请求部分类似,网络响应具有三个部分:响应行、响应头和响应体。
响应完成之后可能会看是否需要持续连接,如果不需要就会断开,断开 TCP 连接需要经历四次挥手过程。
5.浏览器解析渲染页面

- http的几个版本及其区别?
HTTP0.9
1991年发布, 没有header,功能非常简单,只支持GET。
HTTP1.0
1996年发布,明文传输安全性差,header特别大。它相对0.9有以下增强:
- 增加了header(使用元数据与数据解耦)
- 增加了status code,用于声明请求的结果。
- content-type可以传输其它文件。
- 请求头增加了http/1.0版本号。
缺点:每请求一次资源就新建一次tcp连接
HTTP1.1
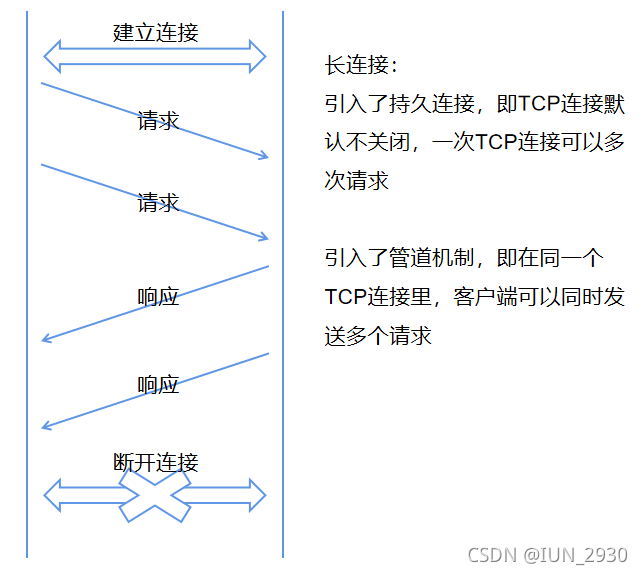
1997发布,是现在使用最广泛的版本。它相对1.0有以下增强:
- 引入了持久连接,即TCP连接默认不关闭,可以被多个请求复用,默认Connection: keep-alive
- 支持pipeline传输,请求发出后可以继续发送请求。即在同一个TCP连接里,客户端可以同时发送多个请求(大多数浏览器允许同时建立6个持久连接引入了管道机制),进一步改进了HTTP协议的效率。
- 增加了HOST头,让服务端知道用户请求的是哪个域名
- 增加了type、language、encoding等header
2014年更新了内容:
- 增加了TLS支持,即https传输
- 支持四种模型:短连接,可重用tcp的长链接,服务端push模型(服务端主动将数据推送到客户端cache中),websocket模型
缺点:还是文本协议,客户端服务端都需要利用cpu解压缩
HTTP2
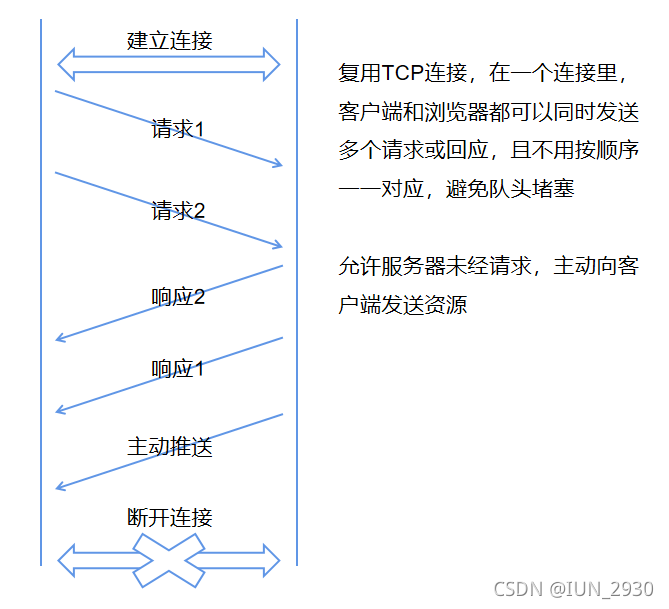
2015年发布,主要是提升安全性与性能。它相对1.1的增强有:
- 头部压缩(合并同时发出请求的相同部分)
- 二进制分帧传输,更方便头部只传输差异部分
- 流多路复用,同一服务下只需要用一个连接,节省了连接
- 服务器推送,一次客户端请求服务端可以多次响应。
- 可以在一个tcp连接中并发发送请求
缺点:基于tcp传输,会有队头阻塞问题(丢包停止窗口滑动),tcp会丢包重传。tcp握手延时长,协议僵化问题。
HTTP3
2018年发布,基于谷歌的QUIC,底层使用udp代码tcp协议,
这样解决了队头阻塞问题,同样无需握手,性能大大地提升,默认使用tls加密。
图形学
渲染基础
什么是图形渲染管线,分为哪些阶段?(⭐⭐⭐)
图形渲染管线实际上指的是一堆原始图形数据途经一个输送管道,期间经过各种变化处理最终出现在屏幕的过程,在概念上可以将图形渲染管线分为四个阶段:应用程序阶段、几何阶段、光栅化阶段和像素处理阶段。

图形渲染管线
(1)应用程序阶段
大体逻辑是:进行一些软件层面上的工作,碰撞检测、动画物理模拟等,查询出可能需要绘制的图元并生成渲染数据,设置渲染状态和绑定各种Shader参数,调用DrawCall,进入到下一个阶段,GPU渲染管线。
(注:应用程序阶段在CPU端完成,后面的所有阶段都是在GPU端完成)
(2)几何阶段主要负责大部分多边形操作和顶点操作,将三维空间的数据转换为二维空间的数据,可以分为顶点着色、投影变换、裁剪和屏幕映射阶段。
(3)光栅化阶段是将图元离散化成片段的过程,其任务是找到需要绘制出的所有片段,包括三角形设定(图元装配)和三角形遍历阶段;
(4)像素处理阶段,给每一个像素正确配色,最后绘制出整幅图像,包括像素着色和合并阶段。
- 请详细描述图形渲染管线每个阶段的具体任务?(⭐⭐⭐)
(1)应用阶段
这是一个由CPU主要负责的阶段,且完全由开发人员掌控。在这个阶段,CPU将决定递给GPU什么样的数据(譬如渲染目标场景中的灯光、场景的模型、摄像机的位置),有时候还会对这些数据进行处理(譬如只递给GPU可以被摄像机看见的元素,其他不可见的元素被剔除(culling)出去),并且告诉GPU这些数据的渲染状态(譬如纹理、材质、着色器等)。还有进行一些例如碰撞检测、动画模拟等的工作。
(2)几何阶段,包含顶点处理阶段、裁剪和屏幕映射阶段。
a.顶点处理阶段:
这个阶段会执行顶点变换和顶点着色的工作。通过模型矩阵、观察矩阵和投影矩阵(也就是MVP矩阵)计算出顶点在裁剪空间下的位置(clip space),以便后续阶段转化为标准化设备坐标系(NDC)下的位置。也可能会计算出顶点的法线(需要有法线变换矩阵)和纹理坐标等。
b. 裁剪阶段:对部分不在视体内部的图元进行裁剪。

c. 屏幕映射阶段:主要目的是将之前步骤得到的坐标映射到对应的屏幕坐标系上。

尽管GPU已经得到了顶点的x、y坐标,但他们处于[-1,1]区间中的,GPU还需要进行一定的计算才能把他们映射到我们的1920*1080甚至2560*1440的屏幕。得到的新坐标系称为窗口坐标系,虽然只需要两个坐标把顶点投射到屏幕上,但它仍然是三维的,这个多出来的z值就是在上面算出来的深度。
(3)光栅化阶段
a. 三角形设置(图元装配),这个过程做的工作就是把顶点数据收集并组装为简单的基本体(线、点或三角形),通俗的说就是把相关的两个顶点“连连看”,看能否构成面、线。
b. 三角形遍历,找到哪些像素被三角形所覆盖,并对这些像素的属性值进行插值。
通过判断像素的中心采样点是否被三角形覆盖来决定该像素是否要生成片段。
通过三角形三个顶点的属性数据,插值得到每个像素的属性值。
这两个阶段是完全硬件控制的,不可进行任何操作。
(4)像素处理阶段,包括像素着色和测试合并。
a. 像素着色,进行光照计算和阴影处理,决定屏幕像素的最终颜色。各种复杂的着色模型、光照计算都是在这个阶段完成。(由片元着色器完成)
b. 测试合并:
从两个名字中我们大致可以推测出GPU在这个阶段要做的事情:对每个片元进行操作,将它们的颜色以某种形式合并,得到最终在屏幕上像素显示的颜色。主要的工作有两个:对片元进行测试(Test)并进行合并
包括各种测试和混合操作,如裁剪测试、透明测试、深度测试以及色彩混合等。经过了测试合并阶段,并存到帧缓冲的像素值,才是最终呈现在屏幕上的图像。
- 各种测试(缓冲)的含义,相对顺序?
顺序:裁剪->透明度->模板->深度。
裁剪测试:只有在裁剪框内的片元才会被显示出来,在裁剪框外的片元皆被剔除。
透明度绘制:仅仅允许透明度值达到设置的阈值后才可以会绘制。
模板测试:
模板测试就是用片段指定的参考值与模板缓冲中的模板值进行比较,如果达到预设的比较结果,模板测试就通过了,然后用这个参考值更新模板缓冲中的模板值;如果没有达到预设的比较结果,就是没有通过测试,就不更新模板缓冲。
当启动模板测试时,通过模板测试的片段像素点会被替换到颜色缓冲区中,从而显示出来,未通过的则不会保存到颜色缓冲区中,从而达到了过滤的功能。

深度测试:
我们在观察物体的时候,位于前面的物体会把后面的物体挡住,所以在渲染的时候,图形管线会先对每一个位置的像素存储一个深度值,称为深度缓冲,代表了该像素点在3D世界中离相机最近物体的深度值。于是在计算每一个物体的像素值的时候,都会将它的深度值和缓冲器当中的深度值进行比较,如果这个深度值小于缓冲器中的深度值,就更新深度缓冲和颜色缓冲的值,否则就丢弃;
这是因为,我们总想只显示出离摄像机最近的物体,而那些被其它物体遮挡的就不需要出现在屏幕上;如果这个片元没有通过这个测试,那么就会被舍弃;
简单来说,就是根据物体的深度决定是否渲染。
深度测试允许程序员设置如何渲染物体之间的遮挡关系。
- ps:补充一点,提前深度测试?
大量的被遮挡片元直到深度测试阶段才会被剔除,而在此之前它们同样地被计算,这占用了GPU大量的资源。因此有种优化技术是将深度测试提前(Early-Z)
提前深度测试允许深度测试在片段着色器之前运行。只要我们清楚一个片段永远不会是可见的(它在其他物体之后),我们就能提前丢弃这个片段。
- ps:补充一点,什么是双重缓冲?
在经过上面的层层测试后,片元颜色就会被送到颜色缓冲区。GPU会使用双重缓冲(Double Buffering)的策略,即屏幕上显示前置缓冲(Front Buffer),而渲染好的颜色先被送入后置缓冲(Back Buffer),再替换前置缓冲,以此避免在屏幕上显示正在光栅化的图元。
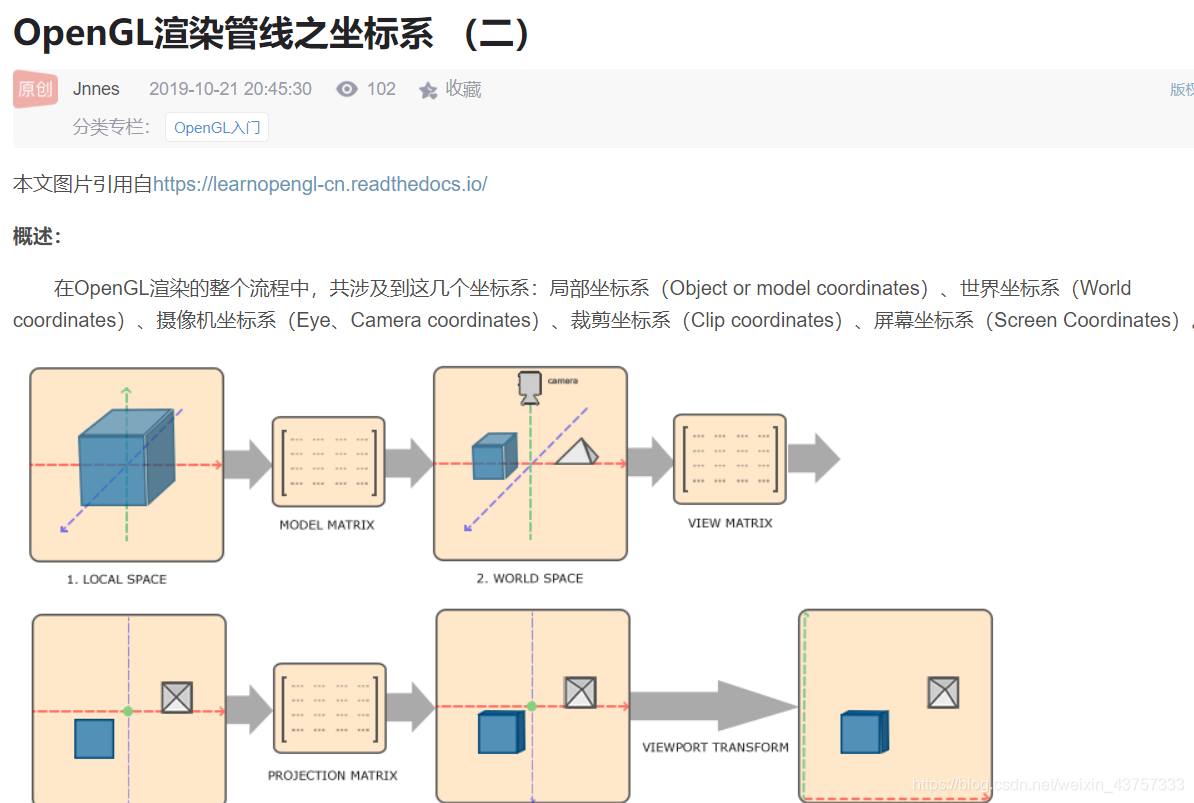
- 坐标系的转换



- 请描述OpenGL中由顶点数据输入到绘制出一幅图像的具体过程
(注:这个问题将图形渲染管线具体到了某一个图形API,因此涉及到了一些具体概念,但是大体上跟上面描述的图形渲染管线一致)
【Reference】:你好,三角形 - LearnOpenGL CN (learnopengl-cn.github.io)、【OpenGL】OpenGL渲染流程详解_Zok93-CSDN博客_opengl渲染
(1) vbo将数据存储到缓存中,vao绑定顶点属性关系,然后vbo将缓存数据传给vertex_shader;
(2) 在顶点着色器中进行坐标变换,由mvp矩阵将其转换到裁剪坐标系,以及顶点着色;
(3) 然后到了图元装配阶段,将顶点着色器的输出数据装配成指定图元的形状,之后还有一个可选的几何着色器阶段,将输入的点或线扩展成多边形;
(注意,这个地方的表述正是和平常的图形渲染管线不一致的地方,这里应该是将图形渲染管线中的三角形设定或者说图元组装阶段表述为图元装配阶段,然后下面的光栅化阶段就是三角形遍历阶段)
(4) 然后到裁剪和屏幕映射阶段;裁剪掉视体外的图元,将当前坐标映射到屏幕坐标;
(5) 然后进入光栅化阶段,找到哪些像素被三角形覆盖,以及进行插值计算;
(6) 然后进入到了fragment_shader,执行光照计算,进行着色;
(7) 最后进入到测试混合阶段,包括Alpha测试、模板测试、深度测试等,然后进行混合。
- 局部光照模型?
阴影(及公式)
纹理贴图
mimap
法线贴图
伽马校正
三维数学
- 齐次坐标
齐次坐标的意义:
1.平移变换拆解为矩阵和向量相乘需要多一个维度,齐次坐标可以解决这个问题。这样子就可以实现平移缩放旋转使用统一的矩阵乘法实现。
2.使用齐次坐标,可以表示 平行线在透视空间的无穷远处交于一点。在欧氏空间,这变得没有意义,所以欧式坐标不能表示。
即:齐次坐标可以表示无穷远处的点。例如:
如果点(1,2)移动到无限远处,在笛卡尔坐标下它变为(∞,∞),然后它的齐次坐标表示为(1,2,0),因为(1/0, 2/0) =(∞,∞),我们可以不用”∞"来表示一个无穷远处的点了。
3.另一方面,齐次坐标可以通过0和1表示是向量还是点。
- 基本矩阵的推导

我们将如下图所示的简单矩阵乘法定义为对向量的线性变换。
即对矩阵(x,y)做了变换可得。
缩放(scaling)
缩放变换是一种沿着坐标轴作用的变换,定义如下:

即除了原点保持不变之外,所有的点变为。 举两个简单例子:

旋转(rotation)
旋转可以说是又一个十分重要的变换矩阵了,如下图,我们希望用一个变换矩阵表示将向量a旋转到向量b的位置,

记为

推导见计算机图形学一:基础变换矩阵总结(缩放,旋转,位移) - 知乎 (zhihu.com)
(提示,先计算出a的xy坐标=rcosα和r=sinα,然后b的x坐标即为rcos(α+σ),y坐标同理,然后再用r=cosα替换xa)
而在三维的情况下绕xyz轴的结果如下:



其实到这里可以下一个结论,可以看到任意旋转都是正交矩阵!,因此他们的逆便是他们的转置,而一个旋转矩阵的逆所对应的几何解释便是,我反着转这么多,比如我逆时针转30°,转置便是顺时针30°
平移矩阵:


-
各种变换矩阵的作用和推导(⭐⭐⭐)
(1)基本概念
模型矩阵M(Model):将局部坐标变换到世界坐标;
观察矩阵V(View):将世界坐标转换为观察坐标,或者说,将物体的世界坐标,转换为在相机视角下的坐标;
投影矩阵P(Projection):将顶点坐标从观察空间变换到裁剪空间(clip space) ,后续的透视除法操作会将裁剪空间的坐标转换为标准化设备坐标系中(NDC)。
观察矩阵:
(190条消息) 推导相机变换矩阵_Popy007(Twinsen)的专栏-CSDN博客_相机变换矩阵
图中,红色是相机的基,而黑色是世界的基,也就是参考系。小人是世界中的一个物体。相机在移动之前,两个基是重合的。当相机在屏幕中定位时,它首先会进行朝向的确定——旋转,然后进行位置的确定——平移。图中的Rotation和Translation两步就是相机定位时所发生的变换。可以看到相机相对于小人的运动。而当进行相机变换的时候,小人应该从世界基变换到相机的基里面。这样,他应该进行一个相机定位的逆定位,先逆平移小人和相机,然后再逆旋转小人和相机,最后相机归位,小人随相机变到了相机空间。这是由Inverse Translation和Inverse Rotation两个步骤完成的,这两个步骤就是相机变换。现在我们推导这个变换。我们把关系写出来,相机本身的变换C包括两个元素
其中T是平移变换,R是旋转变换。而相机变换是相机本身变换的逆变换
这个C^-1就是我们要求出的相机变换。其中T^-1很容易求出,即
而R^-1就没有这么容易求出来了。所以,我们不求它,我们用UVN系统。什么意思?请看上面的那张相机变换的图,当相机变换进行完Inverse Translation这一步之后,相机的原点和世界原点就重合了,也就是处理完了关于平移的变换。接下来我们要做的是逆旋转,而其实逆旋转的目的,就是要得到目前世界坐标中经过逆平移的小人在相机坐标系中的坐标。是不是似曾相识?我们的坐标变换理论就派上用场了。我们回忆上面坐标变换的公式
这个坐标转换公式可以解释为:对于世界坐标系中的向量v’,它在坐标系R中的坐标是v’’。那么,我们可以套用在这里:对于世界坐标中的已经经过逆平移的坐标v’,它在相机坐标系R中的坐标是v’’。什么是相机坐标系R?就是我们的相机UVN系统!就是
则相机变换的完整公式就是
这里,v是小人在世界空间中的坐标,v’’是小人在相机空间中的坐标。则相机变换矩阵就是


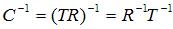





正交投影矩阵很好计算,只需要经历一个移回原点,再进行scale缩放,再进行位移回原来的地方即可实现。

透视投影
1 将原空间范围的左下角移至原点
2 放大给定倍数
3 将缩放后的空间范围移至新空间范围
这样一个general的二维例子用矩阵来表示就是这样:

三维同理。
4 视口变换(viewport transformation)
这一步就很简单了,一开始也介绍过就是两个范围空间的转换

在正交变换一节已详细解释清楚,这里直接套公式即可

- 欧拉角、矩阵、四元数表示旋转的区别和优缺点(⭐⭐⭐)
【Reference】:《游戏引擎架构》P164
(1)欧拉角:定义了绕着三个坐标轴的旋转角,来确定刚体的旋转位置的方式,包括俯仰角pitch,偏航角yaw和滚动角roll;它的优点是比较直观,而且单个维度上的角度也比较容易插值;缺点是它不能进行任意方向的插值,而且会导致万向节死锁的问题,旋转的次序对结果也有影响
(2)矩阵:优点是不受万向节死锁的影响,可以独一无二的表达任意旋转,并且可以通过矩阵乘法来对点或矢量进行旋转变换;现在多数CPU以及所有GPU都有内置的硬件加速点积和矩阵乘法;缺点是不太直观,而且需要比较大的存储空间,也不太容易进行插值计算。
(3)四元数:四元数的好处是能够串接旋转;能把旋转直接作用于点或者矢量;而且能够进行旋转插值;另外它所占用的存储空间也比矩阵小;四元数可以解决万向节死锁的问题。
- 判断一个点是否在多边形内部?
https://www.pianshen.com/article/9475339846/
下面是几个比较基本的方法:
(1)面积法:将这个点与多边形的所有顶点连线,将所形成的所有三角形面和求和,如果和多边形面积相等则点在多边形内部
(2)夹角法:将这个点与多边形的所有顶点连线,如果夹角和为360°则点在多边形内部
(3)射线法:以点P为端点,向左方作射线L,由于多边形是有界的,所以射线L的左端一定在多边形外,考虑沿着L从无穷远处开始自左向右移动,遇到和多边形的第一个交点的时候,进入到了多边形的内部,遇到第二个交点的时候,离开了多边形,……所以很容易看出当L和多边形的交点数目C是奇数的时候,P在多边形内,是偶数的话P在多边形外。
相机和view矩阵
- 项目中如何实现相机的功能?
对于相机坐标,我们本质上是将世界坐标进行平移和旋转,然后让它正确地显示出从相机视角观察的特性。
需要一个矩阵,实现世界坐标系到相机坐标系的变化。那么如何确定这个矩阵?
先来看相机坐标系需要两个参数:
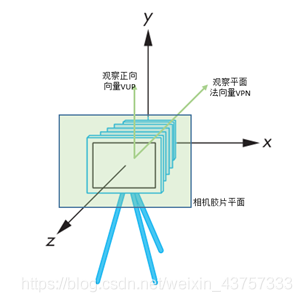

对于VPN即观察平面法向量我们是通过用目标点减去眼睛的方向向量,即eye减去at的实现的,对于vup也可以通过公式计算可得,有了这两个向量后就可以构造出矩阵。
换言之,也就是可以根据三个参数,eye,at和up,分别代表相机所在位置,被观察物体所在位置,和观察正向向量。然后就可以通过计算获得view矩阵。
那么如何实现相机的移动?这个比较简单,只要直接改变eye所在的位置即可。
而实现相机的旋转是通过这样:
由于eye是相机位置,我们对于at的设定是通过相机位置的基础上添加一个方向向量,即:
cameraPosition+cameraDirection,
那么实现相机的旋转只需要改变相机的朝向CameraDirection即可,改变cameraDirection的方法是通过使用欧拉角来实现,让方向向量设定为和俯仰角,偏航角有关的式子:
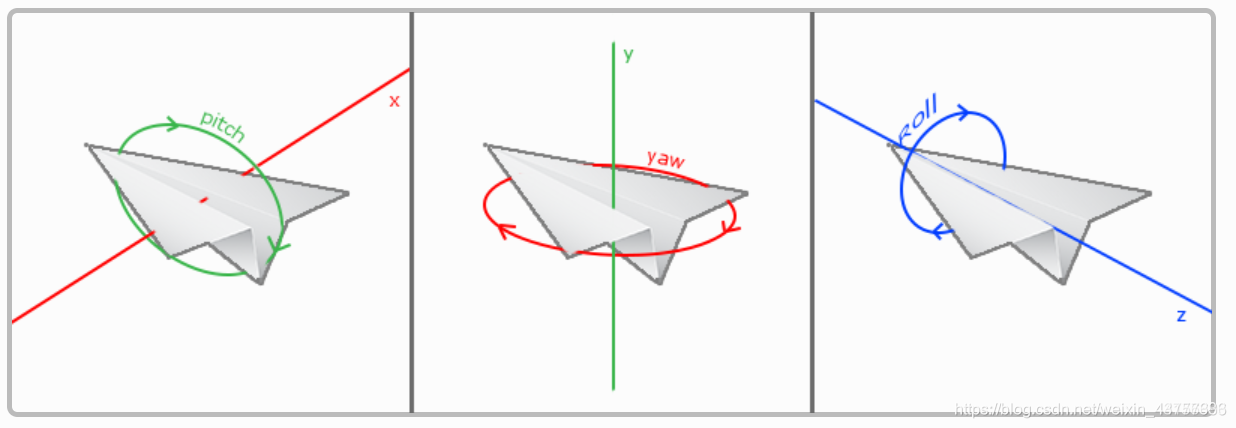
pitch 俯仰角
yaw 偏航角
roll 横滚角
// 计算欧拉角以确定相机朝向
cameraDirection.x = cos(radians(pitch)) * sin(radians(yaw));
cameraDirection.y = sin(radians(pitch));
cameraDirection.z = -cos(radians(pitch)) * cos(radians(yaw)); // 相机看向z轴负方向
然后旋转时候只需要通过改变角度即可改变direction进而实现旋转了。
阴影
- 我的项目中是如何实现阴影的?
在顶点着色器中,我们在绘制物体时需要传入model矩阵的位置,然后在对应的顶点处上色,那么绘制阴影时,我们让model矩阵乘以一个阴影矩阵,该矩阵可以得到物体上的点在地面上对应的阴影位置,然后将该矩阵再次传入顶点着色器,并且设定颜色为黑色,然后调用glDrawArray函数绘制即可。
阴影矩阵的生成是通过光源位置和阴影平面所确定,通过公式计算得到。
阴影矩阵公式求法:

投影变换
- 投影变换?正交投影和透视投影

投影变换
在经过三维物体的模-视变换后,场景中的三维物体即被放在了相机能够观察到的位置。
而投影变换的目的则是定义一个视景体(View Volume),使得视景体外多余的部分被裁减掉,最终进入到投影平面上的只是视景体内的部分。



裁剪应该可以类比为人类的视野其实也是有限的,因此在计算机中只需要将视景体内的物体保留下来即可。
正交投影
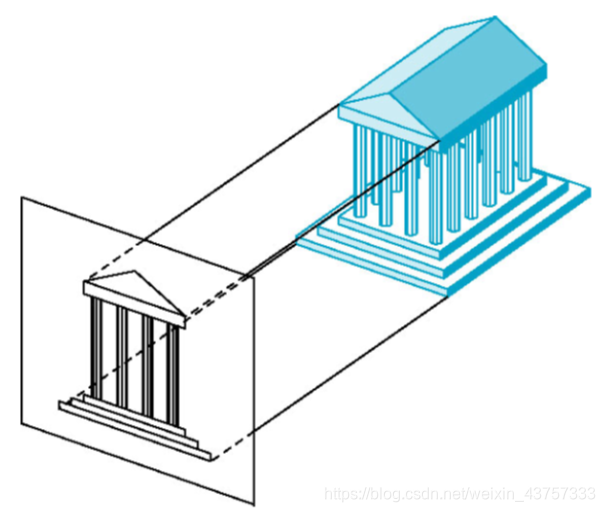
正交投影的效果现实中是不存在的,现实中都是透视投影
正交投影的视景体:
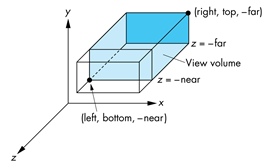
在OpenGL中,通常使用的正交投影是定义在一个平行六面体的视景体(或者说是裁剪体)中,如下图所示,该六面体由六个参数决定,分别为左右裁剪平面(left和right),上下裁剪平面(top和bottom),远近裁剪平面(near和far)。需要注意的是,这些参数的定义都是在相机坐标系下。举例来说,远近裁剪平面相当于是在z轴方向离相机的距离。
但是,在OpenGL的渲染管线中定义了一个标准视景体如下,
也就是说,在渲染的最后过程中,我们需要将上述定义的正交投影视景体变换到该标准视景体中,使用的方法是通过平移和旋转变换将相机坐标系下经过裁剪的顶点变换到默认的标准视景体下,这个处理过程称为投影规范化(ProjectionNormalization),如下图所示。
透视投影的视景体:使用棱锥

- 透视投影矩阵如何实现真实的效果的?
矩阵中使用了透视除法。
透视除法可以将深度信息保留下来,体现出近大远小的效果。
我们知道齐次坐标的最后一个信息(也就是w)如果是1则代表坐标值,此时我们可以用这个位置来储存深度信息:
所以可以构造一个投影矩阵:



光照模型
具体见我写的另外一篇文章:
(203条消息) Blinn-Phong光照模型解析及其实现_晴夏。的博客-CSDN博客
简短的概要:
光照模型包括局部光照和全局光照。局部光照指物体表面上一点的颜色只取决于表面的材质属性、表面的局部集合性质以及光源的位置和属性,而与场景中其他的表面无关。而全局光照则需要考虑场景中所有表面和光源相互作用的照射效果。


BlinnPhong和对Phong模型进行 改进,对于镜面反射的强度不再用出射方向和视点的夹角来计算,而是用半角向量和法向量的夹角来计算,有两个好处:
1. 计算反射向量的速度较慢,使用半角向量计算较快。
2. 使用Phong模型会在夹角超过90度的时候导致计算结果为负值,导致镜面反射的光出现断层。使用Blinn模型不会出现这种情况,光照效果也较为柔和。
抗锯齿算法
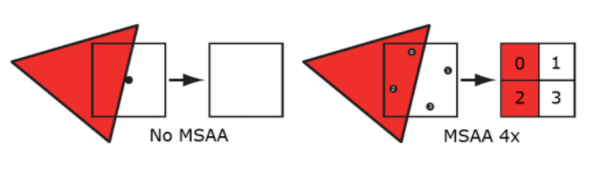
MSAA(MultiSampling AA)
原理:在光栅化阶段,判断一个三角形是否被像素覆盖的时候计算三角形对子像素的覆盖情况,但计算颜色时只用像素中心坐标计算一次颜色,然后将着色结果乘以coverage的比例
光栅化:确定每个顶点最终位于屏幕上的哪个像素,判断每个像素是否被三角形覆盖
对三角形内部的像素:pixel shader计算的颜色会存到全部4个子采样点中
对三角形边缘的像素:pixel shader计算的颜色只会存到被三角形覆盖的子采样点中
最后对4个子采样点的颜色进行插值。因为颜色是以父采样点中心计算的,所以pixel shader只计算一次颜色即可。
特点:
只支持前向渲染,不支持延迟渲染
静态画面表现好,时域上不稳定
只能消除几何走样,不能解决高光区域着色走样
计算机图形学中,透视除法和齐次坐标是两个相互关联的概念,它们都在三维图形的渲染过程中扮演着重要的角色。在这篇科普小短文中,我们将尝试以通俗易懂的方式解释这两个概念,以及它们在计算机图形学中的应用。
首先,让我们来谈谈透视除法。透视除法是计算机图形学中的一个重要步骤,用于将三维空间中的物体投影到二维平面上,从而实现透视效果。在现实生活中,我们可以观察到远离我们的物体看起来比较小,而靠近我们的物体看起来较大。透视除法正是用于实现这种现实世界中的视觉效果。
齐次坐标则是一种用于表示三维空间中点和向量的数学表示法。在传统的笛卡尔坐标系中,一个点或向量使用三个数值(x,y,z)表示。然而,在齐次坐标系中,我们使用四个数值(x,y,z,w)来表示一个点或向量。这里的w被称为齐次坐标,它为我们提供了一个灵活的方式来处理透视变换和其他图形变换。
齐次坐标在计算机图形学中具有重要的意义。它们使得透视变换和其他仿射变换可以通过矩阵乘法来实现,从而简化了计算过程。此外,齐次坐标还能够很好地处理无穷远点,这在处理透视投影时非常有用。
将齐次坐标应用于透视除法时,我们首先需要将三维空间中的点用齐次坐标表示。接下来,我们对这些点进行透视变换,将其投影到一个虚拟的二维平面上。在这个过程中,我们需要使用齐次坐标的w分量来进行透视除法,即将x、y、z坐标分别除以w。这样,我们就可以得到投影后的二维坐标(x/w,y/w),从而实现透视效果。
总之,透视除法和齐次坐标是计算机图形学中关于三维图形渲染的重要概念。它们共同协作,将三维空间中的物体投影到二维平面,实现逼真的透视效果。了解这两个概念有助于我们更好地
- 前向渲染和延迟渲染
前向渲染(Forward Rendering)和延迟渲染(Deferred Rendering)是两种常见的光照渲染技术。它们在处理场景中的光源和物体之间的光照交互时采用了不同的方法。
-
前向渲染(Forward Rendering): 前向渲染是一种传统的渲染方法。在这种方法中,场景中的每个物体都会与所有光源进行光照计算,然后将光照效果合成到最终的渲染结果中。前向渲染的主要优点是实现简单,能够很好地处理透明度和半透明度物体。然而,当场景中存在大量光源时,前向渲染的性能会受到很大的影响,因为每个物体都需要与每个光源进行光照计算。
-
延迟渲染(Deferred Rendering): 延迟渲染是一种更先进的渲染方法,它将渲染过程分为两个阶段。在第一个阶段,场景中的所有物体的几何信息(例如位置、法线、纹理坐标等)被渲染到一个称为“G缓冲区”(G-buffer)的特殊缓冲区中。在第二个阶段,所有光源根据G缓冲区的内容进行光照计算,并将光照效果合成到最终的渲染结果中。
延迟渲染的主要优点是性能更高,尤其是在场景中存在大量光源时。因为在延迟渲染中,每个物体只需要与影响它的光源进行光照计算,而不是与所有光源计算。然而,延迟渲染的一个主要缺点是处理透明度和半透明度物体较为复杂。
总之,前向渲染和延迟渲染是两种不同的光照渲染技术,各有优缺点。前向渲染适用于光源较少的场景和透明度处理较多的场景,而延迟渲染适用于光源较多的场景,尤其是需要高效处理大量光源的情况。根据实际需求和场景特点,可以选择合适的渲染方法。
- 图形渲染的性能影响因素
在图形渲染中,影响性能的因素有很多,以下是其中一些主要因素:
-
多边形数量:多边形数量越多,渲染器需要进行的计算和绘制操作也会越多,从而降低渲染性能。
-
着色器复杂度:着色器中的复杂计算会导致渲染性能下降。因此,需要避免过于复杂的着色器,尽可能地精简它们。
-
纹理数量和分辨率:纹理数量和分辨率越高,需要传输和处理的数据也会越多,从而影响渲染性能。因此,需要适当减少纹理数量和分辨率,尽可能地压缩纹理大小。
-
光照计算:光照计算是影响渲染性能的主要因素之一。需要考虑减少光源数量和使用更为简单的光照模型等优化手段来降低光照计算的复杂度。
-
渲染顺序:正确的渲染顺序可以避免不必要的计算和绘制操作,从而提高渲染性能。例如,先渲染靠前的物体,再渲染靠后的物体,可以减少后面物体的计算和绘制操作。
- 如何进行性能性能优化
针对这些影响渲染性能的因素,可以采取以下一些性能优化策略:
-
优化场景中的模型数量和多边形数量,尽可能使用简单的模型和减少不必要的细节。
-
优化着色器的复杂度,避免过多的计算和复杂的逻辑。
-
减少纹理数量和分辨率,使用纹理压缩等技术减小纹理大小。
-
采用合理的光照模型和优化光照计算,如使用简单的光照模型、减少光源数量、使用阴影优化等手段。
-
优化渲染顺序,尽可能减少不必要的绘制操作。
-
合理使用批处理技术,减少渲染调用次数,提高渲染效率。
-
优化渲染资源的加载和卸载,合理利用缓存和预加载技术,提高渲染效率。
- PBR
PBR(Physically Based Rendering),即基于物理的渲染,是一种计算机图形学渲染技术,旨在提供更真实的光照和材质模拟效果。传统的渲染技术通常是基于经验或者艺术家的感觉,而 PBR 则是通过模拟真实光学物理的行为,使得渲染结果更接近真实世界。
PBR 技术的核心思想是基于光的物理行为,将材质属性分解为反射率(Albedo)、金属度(Metallic)、粗糙度(Roughness)和法线贴图(Normal map)等物理属性。其中,反射率决定了材质表面的颜色,金属度用于描述材质表面是否具有金属性质,粗糙度用于描述表面的粗糙度程度,法线贴图用于描述表面的微观几何特征。这些属性会影响光的反射和散射行为,从而影响最终渲染结果。
- 法线贴图
法线贴图(normal map)是一种纹理贴图技术,用于增强3D模型表面的细节和几何形状。它利用红、绿、蓝三个通道的像素值表示模型表面上每个点的法线(法线表示表面的方向),进而改变模型表面的光照效果。法线贴图可以为模型表面添加微小的凹凸纹理,使得模型看起来更加真实,同时不需要增加模型的多边形数量。
制作法线贴图通常需要一个高细节模型和一个低细节模型,高细节模型可以包含更多细节和几何形状,而低细节模型可以用于实际运行的游戏或应用程序中。首先,将高细节模型和低细节模型进行UV重叠,然后在高细节模型上采样法线值,并将法线值转换为纹理空间中的RGB颜色值。最后,将生成的法线贴图应用到低细节模型上。
法线贴图广泛应用于游戏中,如增加皮肤上的细节、增加墙壁上的裂痕、增加角色服装上的皱褶等等。
- LOD
LOD(Level of Detail): LOD是一种根据物体距离观察者(相机)的远近,动态选择不同细节层次的模型和纹理进行渲染的技术。通过这种方法,可以在保持渲染质量的同时,降低场景中复杂度较高物体的渲染负担。
- 遮挡剔除
遮挡剔除是在渲染管线的前段(即几何渲染阶段)完成,它可以排除那些在摄像机视锥体范围之外或被其他物体遮挡的物体,以提高渲染性能。遮挡剔除可以使用多种技术,例如简单的面剔除和基于GPU的遮挡剔除技术(如Occlusion Query)。
- mipmap
Mipmap是一种纹理优化技术,它通过在纹理尺寸变小时使用已经缩小的纹理代替原始纹理,从而提高渲染性能和图像质量。Mipmap是由一系列不同大小的纹理组成的,其中最大的纹理大小与原始纹理大小相同,而每个后续的纹理大小都是前一个大小的一半,直到达到最小的可用纹理大小。
Mipmap可以有效地解决纹理过远或过近导致的模糊和失真问题。当纹理离相机很远时,可以使用小的Mipmap级别,从而提高渲染性能并避免过度细节。而当纹理接近相机时,可以使用更高的Mipmap级别,以保持图像的清晰度和细节。
在实现Mipmap时,需要在渲染纹理之前生成所有的Mipmap级别,然后在渲染过程中根据距离和缩放级别选择合适的Mipmap级别进行渲染。Mipmap还可以通过纹理过滤器进行控制,以进一步优化性能和图像质量。
- 纹理是什么
纹理是一种用来给3D模型表面添加细节的2D图像。在3D图形学中,通常将纹理映射到模型的表面,以模拟表面的外观和特性,例如木纹、金属光泽、皮肤等。纹理可以是简单的颜色图案、复杂的图像,甚至是动画序列。它可以用于增强渲染效果和增加游戏的视觉体验。在游戏开发中,纹理通常以图像文件的形式存储,并在游戏中被加载和使用。
- GLSL
GLSL全称为OpenGL Shading Language,是OpenGL的着色器语言,主要用于图形渲染中的计算机图形学领域。它是一种高级的着色器语言,专门为图形处理单元(GPU)而设计,旨在提供一种用于编写图形着色器的标准语言。GLSL支持的着色器类型包括顶点着色器、片元着色器、几何着色器和计算着色器等。
GLSL具有高效、可移植和可扩展性的特点,提供了丰富的内置函数和数据类型,可以实现各种复杂的图形渲染效果。在OpenGL应用程序中,GLSL被用来定义着色器程序,实现物体表面纹理贴图、光照模型、阴影、透明度和反射等各种渲染效果。
GLSL与C语言有很多相似之处,如支持函数、变量和控制结构等,但也有一些不同,如不支持指针和动态内存分配等。在使用GLSL编写着色器程序时,需要遵循一定的语法规则和编程约定,以确保代码的正确性和性能。
- 光照模型
光照模型是指在计算机图形学中,用于模拟光的物理效应的一种数学模型。通过光照模型,可以计算出给定光源下,一个物体表面上每个像素点的颜色。光照模型通常包括三个部分:环境光、漫反射光和镜面反射光。
-
环境光:指物体表面被周围环境照射的光线。环境光不会直接照到物体表面,而是经过多次反射后才到达物体表面。环境光通常是恒定的,与物体表面的法线和光源位置无关。
-
漫反射光:指从光源发出的光线,经过反射后照到物体表面上的光线。漫反射光的亮度会随着入射光线与物体表面法线之间的夹角的变化而变化,夹角越小,亮度越大。通常用兰伯特定律计算漫反射光的亮度。
-
镜面反射光:指从光源发出的光线,经过反射后与观察方向相切的光线。镜面反射光的亮度会随着反射光线与观察方向之间的夹角的变化而变化,夹角越小,亮度越大。通常用镜面反射模型计算镜面反射光的亮度。
通过这三种光线的叠加,可以计算出每个像素点的最终颜色。光照模型的实现通常使用着色器来进行计算,可以通过改变着色器的参数,调整光照模型的表现效果。光照模型的优化也是图形学中的一个重要研究方向,通过使用一些技巧,比如多重采样、延迟着色等,可以提高光照模型的计算效率和渲染效果。
Blinn-Phong光照模型
Phong模型是一种常用的光照模型,它由一个环境光照分量、漫反射分量和镜面反射分量组成。它的公式如下:
Blinn-Phong光照模型是对Phong模型的改进,它在计算镜面反射光照强度时,使用了一种更加简单的方式,使得计算速度更快。Blinn-Phong光照模型使用了一个半向量来代替 Phong 模型中的反射向量,该半向量是入射光线和视线方向的中间向量。它的公式如下:
Unity
- lua有什么特点,为什么使用lua?
Lua 是一种轻量级、高效的脚本语言,它被广泛用于游戏开发中,有以下几个优点:
-
简单易学:Lua 语法简单、灵活,易于学习和使用。它的 API 简洁、易于理解,可以快速开发游戏逻辑。
-
轻量级:Lua 的核心只有几百 K,可以轻松嵌入到游戏引擎中。它的运行速度也很快,可以在游戏中实现复杂的逻辑。
-
可扩展性:Lua 可以轻松扩展到 C 或 C++ 中,这意味着可以使用 C 或 C++ 的底层代码来提高性能和灵活性,也可以方便地调用现有的 C 或 C++ 库。
-
跨平台:Lua 代码可以在多个平台上运行,包括 Windows、macOS、Linux、Android、iOS 等等,这为跨平台开发提供了便利。
-
高度定制化:Lua 允许开发者自定义游戏逻辑,因为它允许开发者自由地编写函数、类、库等等。这种灵活性允许开发者创建自己的游戏引擎或工具,从而提高游戏的性能和可玩性。
总之,Lua 具有简单、高效、可扩展、跨平台、高度定制化等优点,使其成为游戏开发中一个非常受欢迎的脚本语言。
- UGUI
UGUI(Unity Graphical User Interface)是Unity引擎中的一个模块,用于实现游戏中的用户界面(UI)。UGUI提供了一系列UI元素,例如按钮、文本框、下拉菜单等,开发者可以通过这些元素来创建游戏的交互界面。
与旧版GUI相比,UGUI具有更好的可扩展性和性能,支持多种分辨率和屏幕尺寸的适配,并且提供了更丰富的事件系统和动画效果。UGUI还支持通过脚本来动态创建和修改UI元素,从而实现更灵活的界面设计和交互效果。
UGUI的使用非常广泛,几乎所有基于Unity引擎的游戏都会使用它来实现界面设计和交互。因此,掌握UGUI的使用对于Unity游戏开发来说非常重要。
- 骨骼蒙皮动画
骨骼蒙皮动画(Skeletal Animation)是一种计算机动画技术,也是一种基于骨骼结构的动画制作方法。它通过给3D模型添加骨骼结构,并将骨骼与模型的顶点进行绑定,使得模型的形状能够随着骨骼的移动和变形而自然变化。在骨骼蒙皮动画中,骨骼结构被用来描述动作和变形,而模型的表面则通过蒙皮技术与骨骼相连,实现模型的形状变化。
- 帧同步与状态同步
网络同步——帧同步和状态同步解析_晴夏。的博客-CSDN博客
- 怎么样体现出游戏的打击感?
1.怪物需要有明确的受击反馈(怪物的受伤动作与击退效果)
2.当武器直接攻击中怪物时,通过游戏帧冻结几帧,来凸显打击帧,以及一些闪避时的特写
3.比如屏幕的微振动,依次反映游戏中的物体发生了碰撞
4.在技能释放时根据效果会有不同的特效和音效,命中敌人时特效和音效也会有些许改变(比如只狼中的格挡与完美格挡,音效都会有所不同),通过不同攻击方式上的一些特效音效上的处理可以给人产生正反馈
5.摄像头的切换,视角的变换(动作游戏中一个角色身上会有很多不同视角的摄像头跟随,例如战双中的邦比会经常有视角变换)
6.动态的物体会有动态模糊的效果
7.论受击反馈就可以分成左边右边前后不同方向的受击反馈
技能动作的连击:设定任何状态都可以进入攻击状态,只不过攻击状态有很多种,所以可以通过设定一个连击数使其在按下同样的按键时进入不同的攻击状态
动画间状态的切换

如果处于攻击的第一段的动画中的后半段中按下攻击按键,则会让其在第一段状态结束后进入第二段攻击动画,这样就可以实现衔接。

通过设置动画间转换的transition
连招在后续会派生出很多不同的连招,我们也就可以通过动画状态机去实现各个状态间的切换
攻击时的碰撞检测:
在产生攻击动画的几个帧内激活一个碰撞盒的子物体,判断如果该子物体触碰到敌人则视为攻击生效。
- 子弹太快穿墙如何解决
根本原因就是在执行一次碰撞检测之前,移动的位移超过了碰撞本身的大小。
我们只需要在子弹飞行的途中储存前后帧的位置,然后计算他们之间的距离,最后通过射线检测是否碰撞到物体即可,。

设为continuous即可。如果有子弹和子弹间碰撞速度过快发生没碰撞的问题可以使用Continuous Dynamic。
- 对象池思想
对于那些需要频繁创建和销毁的对象,对象池的思想是,首先从对象池中寻找有没有可用的对象,如果没有,就创建对象来使用,然后当一个对象不使用的时候,不是把它删除,而是将它设置为不激活的状态并放入对象池中,等待需要使用的时候再去对象池中寻找,并把它激活。
例如:子弹思想、使用对象池实现2d跳跃的残影效果。
- 骨骼蒙皮动画
绑定蒙皮的mesh,我们称之为SkinMesh,在SkinMesh中每个mesh的顶点会受到若干个骨骼的影响,并配以一定的权重比例;
就像我们真实的人一样,首先支撑并决定位置和运动的是一组骨骼,头+身体+四肢,而身上的肌肉是受到骨骼的影响而产生运动的,每一块肌肉的运动可能会受到多个骨骼的影响;
而骨骼的运动相对于其父骨骼,并由动画关键帧数据驱动。
- 有哪些寻路算法?
dfs、bfs、迪杰斯特拉算法、A*算法。
迪杰斯特拉算法是用于求单源最短路径问题,是用于解决从一个点到其他所有顶点的最短路径。
算法思路如下:

需要为这个图建立一个表格,这个表格记录从出发点到各个点的最小距离,以及该点的前面以恶搞结点是什么:
然后检查所有节点中距离最短的结点,将其加入已确定最优路径的集合中,然后遍历该点的所有邻接结点,如果起始点到该点的距离加上该点到邻接结点的距离小于起始点到上述邻接结点的距离,则更新表格中的数值。
接下来步骤与上一样,检查所有节点中,未加入最优路径的点中,距离最短的结点,然后照上面那样做,直到所有结点都加入最优路径点的集合。

至于具体路径只需要根据表格中存储的前一个结点回溯即可。
A*算法
- A*算法是什么?
与广度优先搜索不同,A*算法会去评估代价中可能是最小的进行寻路。是一种启发式算法。
代价分为两部分。


常用的距离有欧几里得距离:



接下来在广度优先搜索的过程中优先选择预估代价最小的。

就这样循环往复直到搜索到最短路径:

在代码实现方面,整体思路和bfs差不多,区别在于使用的是优先队列,里面使用现有代价和预估代价作为评判。
UI管理
--层级管理: -- --UI被分成不同的深度层级,如普通UI层、高位界面层、新手引导层等。这保证了例如新手引导层可以覆盖在普通UI层之上,确保玩家可以看到并进行操作。 --对于界面渲染的z轴深度,我们有LayerDepthCfg来定义每个UI深度层级所对应的z轴深度区间,确保每个UI都在其应有的深度区间内。 --UI显示类型: -- --我们有不同的UI显示类型,如全覆盖类型和弹窗类型。全覆盖类型的UI会覆盖住背后的内容,而弹窗类型可能只覆盖屏幕的部分区域,允许背后的UI部分可见。 --背景遮罩: -- --当UI弹窗出现时,为了避免用户点击到背后的UI内容,我们使用了点击遮罩的机制。这是通过createClickMask函数实现的。 --除此之外,为了增强用户的体验,我们还提供了背景遮罩功能,它能为弹窗提供一个半透明或纯黑的背景,通过createBlackMask函数实现。 --UI资源预加载: -- --在UI管理中,预加载是一个重要的环节。为了减少玩家等待的时间,我们在显示某些界面之前,会先加载它们可能需要的资源,如loadPreData和addPreMapData。 --UI的动态加载和销毁: -- --通过addView、loadViewAndAssets等函数,我们可以动态地加载UI资源和对应的逻辑脚本,显示到界面上。 --同样,为了优化内存使用,我们也提供了destroyView等函数来销毁不再需要的UI。 --事件系统: -- --通过UI事件监听,我们可以方便地在Lua中处理玩家的各种操作,例如点击、滑动等。 --性能优化: -- --对于性能优化,我们有时需要知道当前Mono堆的使用情况,GetMonoHeapUseSize函数即是用于此目的。 --总体而言,ViewManager提供了一整套完整的UI管理解决方案,从UI的加载、显示、交互到销毁,都有对应的处理机制。这样的设计确保了手游中的UI能够流畅、稳定地为玩家提供良好的体验。
等待做笔记的问题
比方说点击运行提交,发送这个请求到http过程会经历一个什么样的阶段,
32位和64位的机器,运行文件上会有什么区别,
tcp/ip的五个层,http、tcp是在哪个层上的,
发送一个报文会经历什么阶段,是怎么经历这些层次的
快速排序的时间复杂度为什么是Onlogn
给main函数添加static,会有什么问题,会是哪一步有错
怎么抓一个https的包,会经历什么样的流程
什么是面向连接?是指由一条物理连接,还是通信过程固定一条路由路径?
拓扑排序
close_wait作用,如果close_wait不关闭有什么问题?
A:应该调用close()方法关闭连接
11、time_wait作用,如果不用time_wait有什么解决方法? 没想出解决方案
等待做笔记的问题:
20、接收端如何判断是否ip数据报是否完整(不会)(从网络编程角度)
进程间通信
-
有块内存,同时被一个shared_ptr和weak_ptr指向,shared_ptr析构了,weak_ptr怎么感知?我说shared_ptr析构了,reference count变为0,肯定有个机制让weak_ptr感知到,反正不会,就瞎扯嘛,但具体是啥没了解过。(了解了一下,有个lock()方法)。
红黑树详细操作 只知道大概的 为什么要用红黑树 和普通二叉搜索树以及AVL树对比
http和https的区别 https的加密方法、证书
1. Cpp的三大特性,你对他们的理解是什么
2. explicit关键字的作用是什么
3. 构造函数有哪几种
拷贝构造函数为什么输入参数一般是常量
快速排序最坏时间复杂度是多少,如何优化最坏的情况?
哈希在插入元素的时候时间复杂度是多少?
哈希函数满足哪些特性?
16. 有哪些常见的哈希函数?
2. UDP的传输内容限制多大(答得256k,应该是512k,混淆了,哭死)
5. 三次握手如果第一次握手没有收到怎么办(没答好,面试官:看来对细节了解不够深啊 哭)
7. select和epoll的区别
2. 同一个进程的线程之间共享哪些,不共享哪些
3. 线程同步有哪些方法
4. 进程调度有哪些算法
1. 游戏名重名被占用是怎么检测的
2. 给你50个红球,50个白球,两个袋子任意放球,要求我在任意一个袋子里摸球摸出红球的概率最大,怎么放
- 如何在C里面调用C++代码,反过来呢?
- 动态链接和静态链接具体说说
- 一个可执行文件如何知道哪些动态链接呢,具体这么做的?
push_back、emplace_back区别;
暂时收集到5

信号量通信
linux锁机制跟具体实现
虚拟内存
内存泄漏怎么解决(循环引用问题)
17.如何处理网络丢包问题?
18,由于卡顿,玩家购买的时候误点两次,怎么判断玩家是误点两次还是由于真的想购买两个道具
socket编程
c#gc机制,
滑动窗口
堆排序
huffman编码
unity生命周期
光照模
A*
选择做的:
7个不同的数,大顶堆有多少种情况?
1. int cnt = malloc(128); int a = cnt; 可以讲一下这步过程中发生了什么嘛?(从虚拟内存,页表的角度来谈)
问:你知道的锁有哪些?
答:读写锁互斥锁
问:互斥锁读写锁的差别,应用场景,这两个分别在什么时候使用?
答:临时照着百度念了一下
问:使用互斥锁堵塞时会对性能造成影响吗?
答:我觉得不会,但是答不上原因。
问:进程崩溃会影响其他进程吗?线程崩溃会影响其他线程吗?
答:进程崩溃不会影响其他进程,因为进程间是隔离开来的。而一个进程内的线程是共用一块内存空间的,所以可能会造成其他线程的崩溃。
进程间的通信和线程间的通信?
答:进程间的通信答了三种,(虽然我知道有6种,但是我知道详细内容的只有三种,所以没敢回答另外三种,但是他竟然没细问)
共享内存、管道、数据通信
线程间的通信有在进程内部使用全局变量、以及消息通信
问:协程和进程线程有什么区别?用来做什么?
答:协程就是个特殊的函数,是用户自定义的,进程和线程是操作系统的,我用过协程来实现异步,
问:那线程也可以实现异步为什么不用线程呢?
答:不知道
你知道、用过的设计模式有哪些?
答:单例模式、观察者模式、工厂模式。然后把功能讲了一下,单例模式和观察者模式讲了在项目里哪里用过,工厂模式我只是知道没实际用过。
问:单例模式会有什么缺点?
答:不知道
问:https加密的过程是什么样的?
答:这个答的感觉还可以,面试前有看了https的加密流程和原因,一步步理解了为什么是这么加密的,整体答得还可以,
问:http的方法?分别用来干嘛
答:get、post。
- GET - 从指定的资源请求数据。
- POST - 向指定的资源提交要被处理的数据。
问:get和post的能否实现对方的功能?
答:get能传输的数据量较小、且不安全,post传输的数据量较大,所以觉得不能。
算法题:
2[ab3[cd]]
翻译成abcdcdcdabcdcdcd
一开始让我答思路,我说用栈然后去遍历,代码挺好写,本来是一次过的,犯了两个错误
1.字符5和数字5之间还需要减去一个'0',忘记减了,后来调试出来了,
2.字符串反转这个函数记错用法了导致答案错了。
最后解出来了,调试花了一会儿时间
#include <iostream>
#include<stack>
#include<string>
#include<algorithm>
using namespace std;
int main() {
// char str[3];
// std::cin>>str;
stack<char> st;
string str;
cin>>str;
for(int i=0;i<str.length();i++){
if(str[i]==']'){
string tmp="";
while(st.top()!='['){
tmp+=st.top();
st.pop();
}
//cout<<tmp<<endl;
reverse(tmp.begin(),tmp.end());
st.pop();
int multp=st.top()-'0';
st.pop();
//cout<<multp<<endl;
string tmp0=tmp;
multp--;
while(multp--)tmp+=tmp0;
//cout<<tmp<<endl;
for(int i=0;i<tmp.length();i++){
st.push(tmp[i]);
}
}
else {
st.push(str[i]);
}
}
string res="";
while(!st.empty()){
res+=st.top();
st.pop();
}
reverse(res.begin(),res.end());
cout<<res;
return 0;
}
MVC设计模式 (以及其他的设计模式 具体问题:A界面跳转打开到了B界面,又跳转到了C界面,最后跳转到A界面,那么这个要用什么样的方式去存储去实现?)
MVM设计模式(? 其他的类似这种UI的
怎么实现极限闪避的效果
map的底层,具体哈希函数是用什么存储
是否有在unity中实现网络通信
unity navigation是怎么实现的,计算寻路的路径时,是存储什么样的信息
unity骨骼蒙皮动画要存储什么数据,相关原理
图形学中阴影的实现
UGUI
unity协程和线程
c#深拷贝
lua
同一个集合组成的二叉排序树,如果其结点顺序不同,其生成的树也会不同,平均带权路径也会不同。
unity中的粒子系统是一个对象,它包含了一个粒子发射器、粒子动画器和粒子渲染器。
二叉树遍历顺序需要中序遍历,然后前序和后序各一个。
进程是申请资源的最小单位,线程是调度的最小单位。
重载运算符obj1>obj2被翻译为:operator>(obj1,obj2)
关键路径是指事件结点网络中从源点到汇点的最长路径。
齐次坐标,透视除法
mipmap
伽马矫正
抗锯齿是什么,及其算法
骨骼蒙皮动画及其原理
建堆suanf
哈夫曼树的带权计算
二叉树的结点n0=n2+1
AABB包围盒
lamada和传统函数有什么区别
设计yuan则有哪些?















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









