






1、光谱数据融合简介
光谱数据融合是一种数据处理技术,旨在结合来自不同光谱仪器的数据,以便获得比单独使用任何一种仪器更加丰富和准确的信息。光谱数据融合广泛应用于遥感、化学成分分析、医学成像等领域。以下是一些常见的光谱数据融合策略:
-
像素级融合:
- 这是最基础的融合级别,它直接在像素值上进行操作。
- 例如,通过计算不同光谱图像同一像素点的平均值或选择最大值来融合数据。
- 像素级融合适用于同时获取的多光谱和高光谱图像。
-
特征级融合:
- 特征级融合涉及到从各个光谱数据中提取特征,然后将这些特征组合在一起进行分析。
- 特征可以是统计量(如均值、方差)、纹理信息、边缘信息或是通过机器学习算法(如主成分分析PCA、线性判别分析LDA)提取的。
- 该方法更加关注数据的信息内容,而不是数据本身。
-
决策级融合:
- 在决策级融合中,各个数据源独立进行分析和解释,每个源都产生一个决策结果。
- 这些独立的决策随后通过一定的逻辑(如投票机制、贝叶斯推断、证据理论)进行综合,以得出最终决策。
- 这种策略对于集成多个独立分类器的输出特别有效。
-
基于模型的融合:
- 在这种方法中,光谱数据融合是基于对场景或对象的物理或统计模型。
- 比如,可以构建一个包含多个光谱带的辐射传递模型,然后利用该模型将不同光谱的数据结合起来。
-
多尺度融合:
- 多尺度融合涉及将不同空间分辨率的光谱图像结合在一起。
- 例如,可以将高分辨率的全色图像与低分辨率的多光谱图像结合,通过技术如波段收缩或多尺度分解来提高多光谱图像的空间分辨率。
-
基于深度学习的融合:
- 利用深度学习算法,如卷积神经网络(CNN)或生成对抗网络(GAN),来自动提取特征并进行数据融合。
- 这种策略尤其适用于大数据集,并且可以实现非线性和复杂的数据融合策略。
每种融合策略都有其适用场景和限制。选择哪种策略取决于具体应用、数据的性质、所需的输出信息以及可用的计算资源。通常,融合过程需要先对数据进行预处理,如校正、配准和归一化,以确保数据可以被有效地结合。
2、特征级融合
2.1 低级融合(Low level fusion)
以肉类光谱分析为例,高光谱成像技术可以结合可见光近红外(VNIR)和短波红外(SWIR)范围来提高检测和分类的精度。这种低级融合策略能够提供肉类的详细化学组成信息,这对于判断其新鲜度、预测保质期、检测病变和污染等方面至关重要。以下是一个基本的流程说明:
数据采集
- VNIR光谱采集:
- 采集肉类样品在400-1000nm波段的光谱反射率。在这个范围内,可以获取与肉色、血红蛋白和肌红蛋白等颜色相关的化学信息。
- SWIR光谱采集:
- 采集1000-2500nm波段的光谱反射率。SWIR区域的光谱信息对于检测肉类中的水分、脂肪以及其他化学成分如蛋白质具有较高的灵敏度。
数据预处理
-
校正与配准:
- 对VNIR和SWIR图像进行辐射校正和大气校正。
- 进行图像配准,确保两种光谱数据对应同一肉块的相同部位。
-
去噪和平滑:
- 使用各种滤波算法去除光谱数据中的噪声。
- 对光谱进行平滑处理,减少数据中的随机波动,突出化学成分的特征峰。
融合处理
-
像素级融合:
- 以像素为单位,直接将相应的VNIR和SWIR数据进行融合,例如,可以通过叠加、平均或其他数学运算来实现。
-
光谱校准:
- 对融合后的光谱数据进行校准,使用标准样品(如已知成分的肉类样品)建立定量模型。
分析与应用
-
化学计量学分析:
- 应用如偏最小二乘回归(PLSR)、主成分分析(PCA)等化学计量学方法对融合后的光谱数据进行分析,从而预测肉类的品质指标。
-
定性定量分析:
- 进行定性分析,识别不同类型的肉类。
- 进行定量分析,测定肉类中的水分、脂肪、蛋白质等成分的含量。
结果评估
-
验证:
- 使用一部分未参与模型训练的样品数据来验证融合模型的准确性和可靠性。
-
比较分析:
- 与传统的肉类检测方法(如化学分析、生物检测)进行比较,评估光谱融合方法的优势。
使用VNIR和SWIR的光谱融合分析可以大幅提升肉类检测的准确性和效率。例如,通过光谱融合,可以实时监测肉类加工过程中的微生物变化,或在超市货架上快速检测肉品的新鲜度。这种技术的非侵入性和快速性使其在食品质量控制领域尤其有价。
2.2 中级融合(Middle level fusion)
-
光谱特征提取:
- 从VNIR和SWIR光谱数据中提取有意义的特征,如吸收峰、反射率的最大值和最小值、波长范围内的平均反射率等。
- 特征提取可以通过统计方法、变换(如傅立叶变换、小波变换)或者基于模型的方法(如高斯拟合)进行。
-
图像特征提取:
- 除了光谱特征,还可以从肉类的高光谱图像中提取纹理特征、形状特征、颜色特征等。
特征融合
-
特征级别的融合方法:
- 特征级融合可能涉及到简单的特征叠加、特征选择和特征优化。
- 可以使用主成分分析(PCA)、线性判别分析(LDA)、CARS,SPA,UVE,正则化方法或是深度学习的特征学习方法来综合不同源的特征。
-
特征空间构建:
- 将提取的特征组合成一个特征矩阵,构建出一个综合的特征空间。
-
特征标准化:
- 特征来自不同的光谱范围,可能会有不同的量纲和分布,需要进行标准化或归一化处理,使得不同特征在数值上可比。
3.基于深度学习的融合
3.1 简介
一维卷积神经网络(1D CNN)已经成为处理光谱数据的一种强大工具,特别是在分析一维光谱信号时。光谱数据通常是一维的,记录了不同波长下的光强或其他电磁属性。
基于双分支卷积神经网络(CNN)的光谱分类是一种融合了深度学习的中级融合方法。在肉类光谱分析中,这种方法可以有效地利用高光谱数据(如VNIR和SWIR)中的空间特征和光谱特征进行分类。双分支CNN模型通常包括两个独立的网络分支,每个分支处理不同类型的数据输入(在这个例子中是VNIR和SWIR数据),然后在某个网络层面将这两个分支的信息进行融合。
使用双分支CNN进行肉类光谱分类的优点在于它能够自动学习和组合空间和光谱信息,这样可以避免传统特征工程中的人为偏差和繁琐工作。此外,深度学习模型尤其擅长处理高维数据,使得这种方法适用于复杂或者难以解释的光谱数据集。
3.2 代码实现
自定义加载数据集
class MyDataset(TensorDataset):
def __init__(self, X_vis, X_nir, labels):
self.X_vis = X_vis
self.X_nir = X_nir
self.labels = labels
def __getitem__(self, index):
vis, nir, target = self.X_vis[index], self.X_nir[index], self.labels[index]
return vis, nir, target
def __len__(self):
return len(self.labels)数据格式

定义是否需要标准化
def ZspProcess(X_vis_train, X_vis_test, X_nir_train, X_nir_test, y_train, y_test, need=True):
if need:
standscale_vis = StandardScaler()
X_vis_train_Nom = standscale_vis.fit_transform(X_vis_train)
X_vis_test_Nom = standscale_vis.transform(X_vis_test)
standscale_nir = StandardScaler()
X_nir_train_Nom = standscale_nir.fit_transform(X_nir_train)
X_nir_test_Nom = standscale_nir.transform(X_nir_test)
X_vis_train_Nom = X_vis_train_Nom[:, np.newaxis, :]
X_vis_test_Nom = X_vis_test_Nom[:, np.newaxis, :]
X_nir_train_Nom = X_nir_train_Nom[:, np.newaxis, :]
X_nir_test_Nom = X_nir_test_Nom[:, np.newaxis, :]
data_train = MyDataset(torch.tensor(X_vis_train_Nom, dtype=torch.float32),
torch.tensor(X_nir_train_Nom, dtype=torch.float32),
torch.tensor(y_train, dtype=torch.long))
data_test = MyDataset(torch.tensor(X_vis_test_Nom, dtype=torch.float32),
torch.tensor(X_nir_test_Nom, dtype=torch.float32),
torch.tensor(y_test, dtype=torch.long))
return data_train, data_test
else:
X_vis_train = X_vis_train[:, np.newaxis, :]
X_vis_test = X_vis_test[:, np.newaxis, :]
X_nir_train = X_nir_train[:, np.newaxis, :]
X_nir_test = X_nir_test[:, np.newaxis, :]
data_train = MyDataset(torch.tensor(X_vis_train, dtype=torch.float32),
torch.tensor(X_nir_train, dtype=torch.float32),
torch.tensor(y_train, dtype=torch.long))
data_test = MyDataset(torch.tensor(X_vis_test, dtype=torch.float32),
torch.tensor(X_nir_test, dtype=torch.float32),
torch.tensor(y_test, dtype=torch.long))
return data_train, data_test定义网络结构
class TwoBranchCNN(nn.Module):
def __init__(self, nls):
super(TwoBranchCNN, self).__init__()
# Visible branch
self.CONV1_vis = nn.Sequential(
nn.Conv1d(1, 8, 5, 1),
nn.BatchNorm1d(8),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=1)
)
self.CONV2_vis = nn.Sequential(
nn.Conv1d(8, 16, 3, 1),
nn.BatchNorm1d(16),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=0)
)
self.CONV3_vis = nn.Sequential(
nn.Conv1d(16, 32, 1, 1),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=0)
)
self.fc_vis = nn.Sequential(
nn.Linear(6848, 256),
)
# Near-infrared branch
self.CONV1_nir = nn.Sequential(
nn.Conv1d(1, 8, 5, 1),
nn.BatchNorm1d(8),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=1)
)
self.CONV2_nir = nn.Sequential(
nn.Conv1d(8, 16, 3, 1),
nn.BatchNorm1d(16),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=0)
)
self.CONV3_nir = nn.Sequential(
nn.Conv1d(16, 32, 1, 1),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1, padding=0)
)
self.fc_nir = nn.Sequential(
nn.Linear(6848, 256),
)
# Combined fully connected layer
self.fc_combined = nn.Sequential(
nn.Linear(512, 256),
)
self.out = nn.Linear(256, nls)
def forward(self, x_vis, x_nir):
x_vis = self.CONV1_vis(x_vis)
x_vis = self.CONV2_vis(x_vis)
x_vis = self.CONV3_vis(x_vis)
x_vis = x_vis.view(x_vis.size(0), -1)
out_vis = self.fc_vis(x_vis)
x_nir = self.CONV1_nir(x_nir)
x_nir = self.CONV2_nir(x_nir)
x_nir = self.CONV3_nir(x_nir)
x_nir = x_nir.view(x_nir.size(0), -1)
out_nir = self.fc_nir(x_nir)
combined_features = torch.cat((out_vis, out_nir), dim=1)
self.drop = nn.Dropout(0.2)
out_combined = self.fc_combined(combined_features)
out = F.softmax(out_combined, dim=1)
return out训练函数
def train_model(model, train_loader, test_loader, criterion, optimizer, device, num_epochs):
model = model.to(device)
# 记录每个 epoch 的损失函数值和准确率
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
total_loss = 0.0
total_correct = 0
for inputs_vis, inputs_nir, labels in train_loader:
inputs_vis, inputs_nir, labels = inputs_vis.to(device), inputs_nir.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs_vis, inputs_nir)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total_correct += (predicted == labels).sum().item()
avg_loss = total_loss / len(train_loader)
accuracy = total_correct / len(train_loader.dataset)
train_losses.append(avg_loss)
train_accuracies.append(accuracy)
# 测试模型
test_loss, test_accuracy, cm = test_model(model, test_loader, criterion, device)
test_losses.append(test_loss)
test_accuracies.append(test_accuracy)
print(f"Epoch [{epoch + 1}/{num_epochs}], Train Loss: {avg_loss:.4f}, Train Accuracy: {accuracy:.4f}, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.4f}")
return model, train_losses, train_accuracies, test_losses, test_accuracies, cm测试函数
def test_model(model, test_loader, criterion, device):
model.eval() # 设置模型为评估模式
total_loss = 0.0
total_correct = 0
y_true = []
y_pred = []
with torch.no_grad():
for inputs_vis, inputs_nir, labels in test_loader:
inputs_vis, inputs_nir, labels = inputs_vis.to(device), inputs_nir.to(device), labels.to(device)
outputs = model(inputs_vis, inputs_nir)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total_correct += (predicted == labels).sum().item()
y_true.extend(labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
avg_loss = total_loss / len(test_loader)
accuracy = total_correct / len(test_loader.dataset)
cm = confusion_matrix(y_true, y_pred)
return avg_loss, accuracy, cmdef main():
vis_train_path = "VNIR的训练数据路径,csv文件"
vis_test_path = "VNIR的测试数据路径,csv文件"
nir_train_path = "SWIR的训练数据路径,csv文件"
nir_test_path = "SWIR的训练数据路径,csv文件"
# 加载数据集
X_vis_train, X_vis_test, X_nir_train, X_nir_test, y_train, y_test = load_dataset(vis_train_path, vis_test_path, nir_train_path, nir_test_path)
# 数据预处理
data_train, data_test = ZspProcess(X_vis_train, X_vis_test, X_nir_train, X_nir_test, y_train, y_test, need=True)
# 创建 DataLoader
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=False)
# 创建模型
model = TwoBranchCNN(nls=3)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001, weight_decay=0.0001)
# 训练模型
num_epochs = 300
trained_model, train_losses, train_accuracies, test_losses, test_accuracies, cm = train_model(model, train_loader, test_loader, criterion, optimizer, device, num_epochs)
# 保存模型权重
torch.save(trained_model.state_dict(), "../twobranchcnn_weights.pth")
print("模型权重保存成功.")
import seaborn as sns
import matplotlib.pyplot as plt
# 设置图像的样式和字体大小
sns.set(style='whitegrid', font_scale=1.2)
# 准备字体
font = {'family': 'Times New Roman',
'color': 'black',
# 'size': 16,
}
# 绘制训练和测试损失
plt.figure(figsize=(8, 6))
plt.plot(range(1, num_epochs + 1), train_losses, label='Train Loss', color='b', linewidth=2)
plt.plot(range(1, num_epochs + 1), test_losses, label='Test Loss', color='g', linewidth=2, linestyle='--')
plt.xlabel('Epoch', fontsize=18, fontdict=font)
plt.ylabel('Loss', fontsize=18, fontdict=font)
plt.title('DC-CNN', fontsize=20, fontdict=font)
plt.xticks(fontsize=16) # 设置 x 轴刻度标签的字体大小
plt.yticks(fontsize=16) # 设置 y 轴刻度标签的字体大小
plt.legend(fontsize=18)
plt.grid(True)
plt.show()
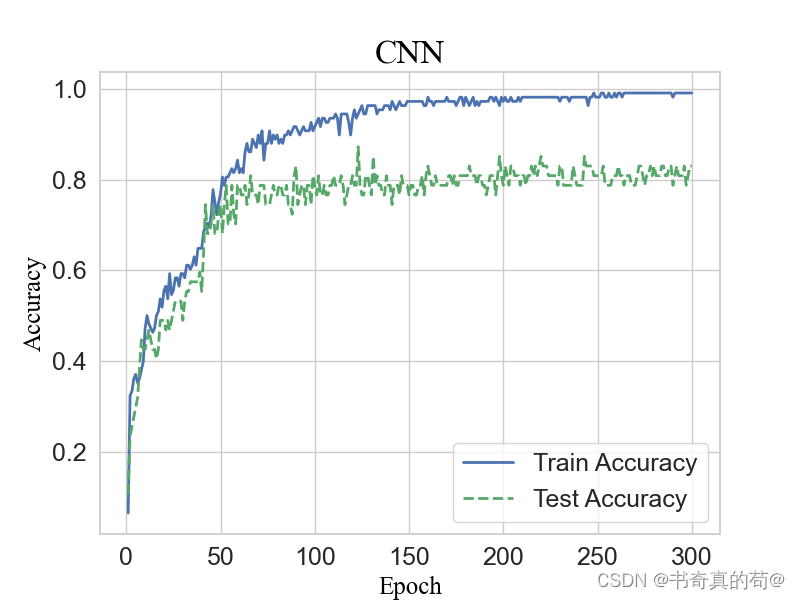
# 绘制训练和测试准确率
plt.figure(figsize=(8, 6))
plt.plot(range(1, num_epochs + 1), train_accuracies, label='Train Accuracy', color='b', linewidth=2)
plt.plot(range(1, num_epochs + 1), test_accuracies, label='Test Accuracy', color='g', linewidth=2, linestyle='--')
plt.xlabel('Epoch', fontsize=18, fontdict=font)
plt.ylabel('Accuracy', fontsize=18, fontdict=font)
plt.title('DC-CNN', fontsize=20, fontdict=font)
plt.xticks(fontsize=16) # 设置 x 轴刻度标签的字体大小
plt.yticks(fontsize=16) # 设置 y 轴刻度标签的字体大小
plt.legend(fontsize=18)
plt.grid(True)
plt.show()
# 输出混淆矩阵
print("混淆矩阵:")
print(cm)
sns.heatmap(cm, annot=True, fmt="d")
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.show()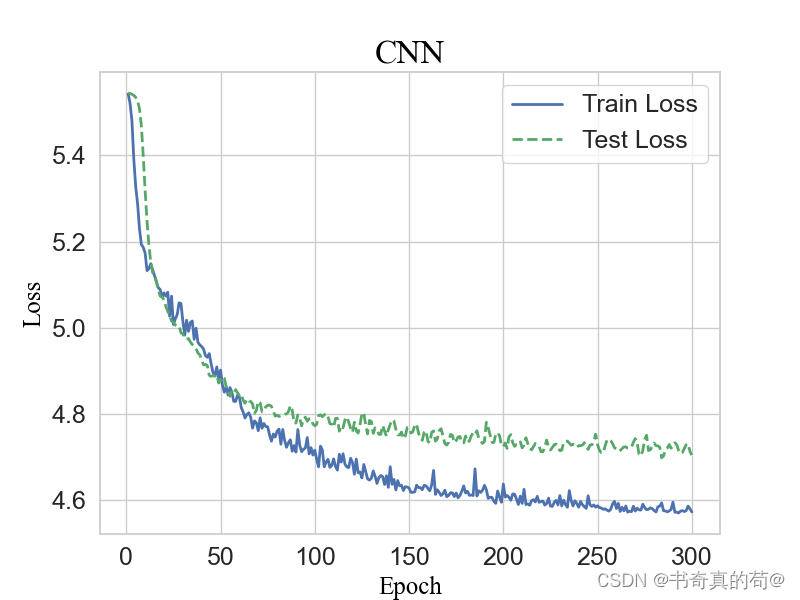
3.3 GradCAM++可视化
为了更好的看清CNN训练过程中光谱重要特征可视化,使用了GradCAM++给各个分支进行可视化,以我自己的光谱数据为例子。
VNIR
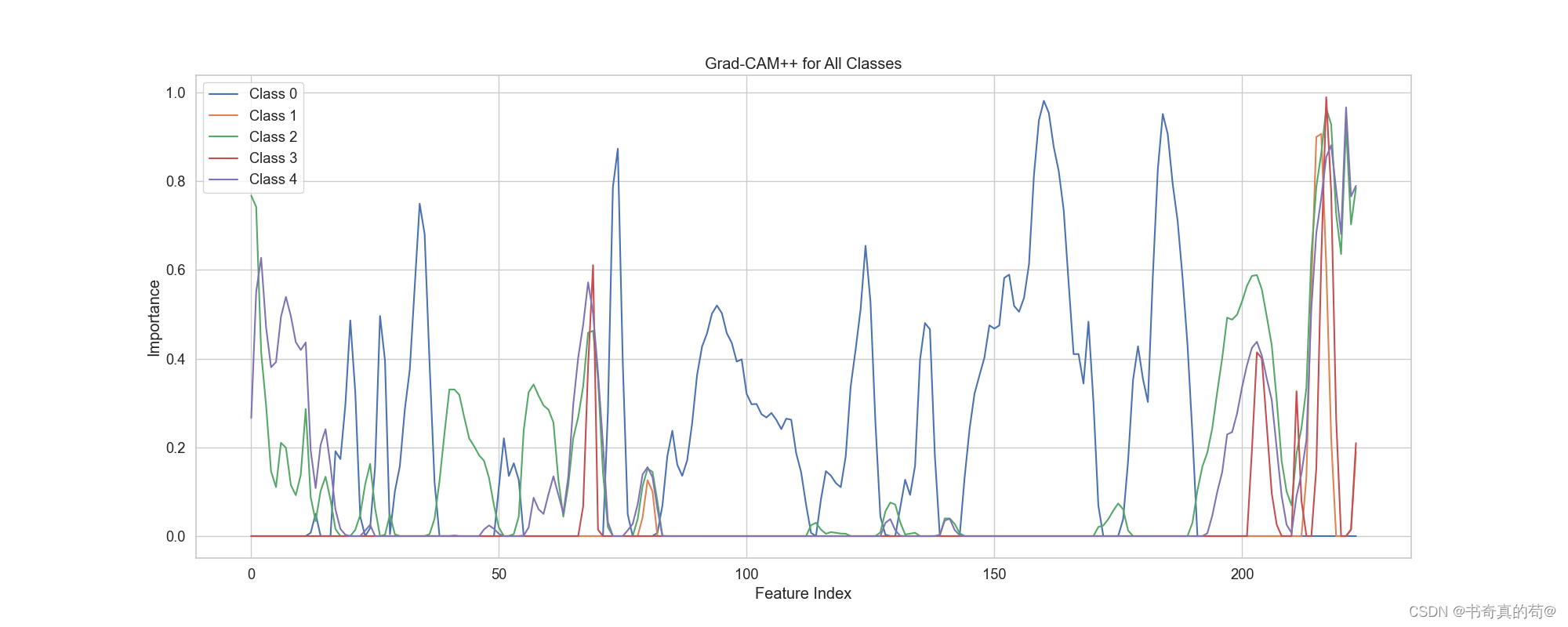
SWIR

















 24
24











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











