







最近有学习李沐老师讲解的注意力评分函数,根据自己的理解,记录一下学习过程,有错误的地方还恳请大家提出来。
目录
引言
在深度学习中,注意力评分函数是注意力机制的核心,它决定了在序列任务中每个部分的重要性。这一机制在自然语言处理(NLP)和图像识别等领域被广泛应用。接下来,我们将详细介绍注意力评分函数的工作原理,并通过加性注意力机制的例子进行说明。
1.注意力评分函数
注意力评分函数,简称评分函数,是一种计算查询(Query)与键(Key)之间相似度的函数。其输出通常是一个实数值,这个值经过进一步的处理(如softmax函数)后,可以解释为权重,指示了在注意力机制中对每个值(Value)的关注程度。该图是我从李沐老师讲义中截图的,链接:注意力评分函数
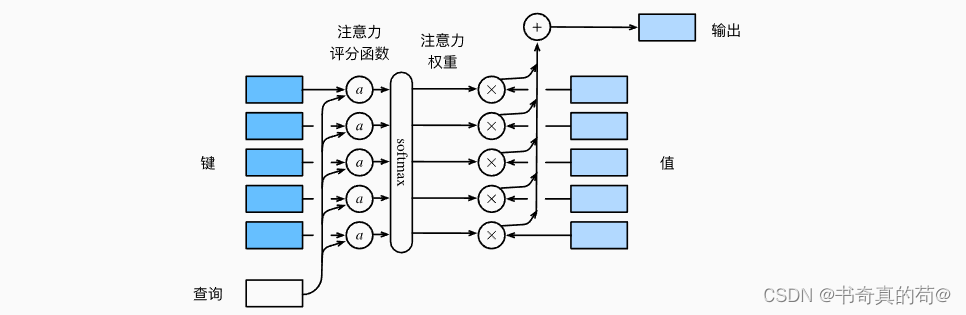
该图说明了如何将注意力汇聚的输出计算成为值的加权和, 其中a表示注意力评分函数。 由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
-
键(Key): 键是用来与查询进行比较的元素。在注意力机制中,键的作用是为了计算注意力权重。每个键与一个值相关联,并且查询与键之间的匹配程度决定了相应值的权重。
-
值(Value): 与每个键相关联的值决定了在计算加权和时每个元素的贡献。值的权重是由查询与对应键之间的关联程度决定的。
数学语言描述:
这个函数产生了一个输出向量,它是所有值向量
的加权和,每个值向量
的加权和的权重
由查询q和对应的
通过一个注意力评分函数
确定。
每个权重是通过softmax函数得到的,这个函数的输入是所有
的评分,softmax 函数将这些评分转换成概率分布,使得所有的权重相加等于 1,且每个权重都是正数。这个计算过程如下:
2.推导过程
给定一个查询 和一组键
, ... ,
我们可以使用评分函数
为每个键计算一个分数。这个分数表示查询和每个键之间的相似度或匹配程度。
2.1.计算评分
这里 是查询 与第
个键
的匹配评分。
2.2.应用指数函数
对每个评分应用指数函数,确保所有的评分都是正数
2.3.归一化评分
在这里,所有的被它们的总和归一化,得到了
和
之间的注意力权重
2.4.计算加权和
使用这些权重作为系数,将所有值的
加权求和,得到最终输出的向量。
这个过程就能够很好的解释了如何将注意力汇聚的输出计算成为值的加权和。
2.5.需要注意的点
还有一个点需要注意的是,上述公式中的和
容易弄混,在注意力机制中,
(通常称为注意力权重)和
(注意力评分函数)是两个关键的组成部分,它们在确定如何分配注意力时起着中心作用。下面我将详细解释它们:
2.5.1 注意力评分函数
- 评分函数 :
是一个计算特定查询
与特定键
之间相似度或兼容性的函数。这个函数的输出是一个实数值,我们称之为“评分”。
- 评分 反映了查询对于每个键的关注度。如果一个键与查询更“相似”或更“兼容”,那么它的评分就会更高。
例如,如果我们使用简单的点积来作为评分函数 ,那么评分会是这样计算的:
在这个例子中,点积直接衡量了查询向量和键向量之间的相似度。
2.5.2 注意力权重
- 注意力权重
是一个归一化的值,用于量化当计算加权和时每个值
的相对重要性。
- 归一化 意味着所有的注意力权重加起来等于 1,这样它们就可以被解释为概率分布。
注意力权重是通过 softmax 函数从评分 获得的:
这个公式确保了每个权重都是正的,并且所有键的权重之和为 1。这样,更高的评分会转化为更大的权重 α,意味着对应的键-值对对于最终输出的贡献也更大。
给大家举个例子说明一下,假设我们有一个查询和三个键值对
,评分函数
产生了以下评分:
应用到softmax函数中,我们得到了每个键的注意力权重:
这些权重 α 随后用来计算值的加权和,这样权重最大的 在最终结果中的贡献最大,因为它对应的键
与查询
的评分最高。
3.加性注意力机制
在这种注意力机制中,查询和
首先被线性变换,然后连接或相加,并通过一个非线性激活函数(通常是tanh)。这个过程涉及以下步骤:
首先是线性变换:
- 查询一个
被变换,其中
- 同样,键
通过另一个
被变换。
然后是非线性激活:
- 变换后的查询和键被相加:
。
- 对这个相加的结果应用tanh函数,以引入非线性,得到的结果是一个中间向量。
最后进一步变换:
- 这个中间向量再被一个权重
(通常是一个行向量)进一步变换。
- 最终我们对这个结果取转置
,得到一个标量值。
评分函数的加性版本可以写成:
- tanh是双曲正切激活函数,它将输入映射到 −1 和 1 之间。
这个评分函数的输出是一个实数值,表示查询和键之间的兼容性。这个值随后用于计算注意力权重 α,就像前面解释的那样。
下面举一个简单的例子:
假设我们有一个简单的NLP任务,我们的模型需要决定再给定的查询词,比如:apple,在这个词上应该关注哪些上下文词,我们有一个简化的上下文,其中三个词(fruit,book,company),分别对应三个键向量, 下面来展示如何使用加性注意力机制计算每个上下文词相关的注意力权重。
1.初始化
- 查询向量
表示词"apple"。
- 键向量
分别表示"fruit", "book", "company"。
- 假设
2. 定义权重矩阵和向量
- 权重矩阵
- 权重矩阵
- 权重向量
3. 线性变换:
对于每个
4.应用非线性激活函数
对于每个
5.计算评分
对于每个
6.应用softmax归一化
对于每个
7. 计算最终的加权
, 其中
是与
相关联的值向量。
假设我们已经有了嵌入好的向量和学习好的权重,我们可以进行以下计算:
- 假设
- 权重矩阵
都是2×2的矩阵,权重向量
计算加性注意力:
,
计算类似
,
计算类似
- 最终softmax归一化得到
最终我们可以得到上下文词对应的注意力权重,这些权重表明模型应该在多大程度上关注每个词
下面给大家演示一下计算过程:
import torch
import torch.nn.functional as F
# 假设的词向量
Q = torch.tensor([1, 0], dtype=torch.float32)
K1 = torch.tensor([0, 1], dtype=torch.float32)
K2 = torch.tensor([1, 1], dtype=torch.float32)
K3 = torch.tensor([0, 0], dtype=torch.float32)
# 假设的权重矩阵和向量,这里我们使用单位矩阵和一个简单的向量
Wq = torch.eye(2)
Wk = torch.eye(2)
w = torch.tensor([1, 1], dtype=torch.float32)
# 计算变换后的查询和键
Q_prime = torch.matmul(Wq, Q)
K1_prime = torch.matmul(Wk, K1)
K2_prime = torch.matmul(Wk, K2)
K3_prime = torch.matmul(Wk, K3)
# 应用非线性激活函数
S1 = torch.tanh(Q_prime + K1_prime)
S2 = torch.tanh(Q_prime + K2_prime)
S3 = torch.tanh(Q_prime + K3_prime)
# 计算评分
a1 = torch.dot(w, S1)
a2 = torch.dot(w, S2)
a3 = torch.dot(w, S3)
# 应用 softmax 归一化
scores = torch.tensor([a1, a2, a3])
alpha = F.softmax(scores, dim=0)
alpha # 注意力权重
RESULT
tensor([0.3716, 0.4549, 0.1735])在我们的例子中,计算得到的注意力权重 α 为:
- 对于第一个键("fruit"),权重是约 0.3716
- 对于第二个键("book"),权重是约 0.4549
- 对于第三个键("company"),权重是约 0.1735
这些权重表明模型在给定查询“apple”时,会更多地关注“book”,其次是“fruit”,而对“company”关注最少。这个结果可能反映了模型学习到的上下文信息,即“apple”与“book”和“fruit”更相关,这可以基于上下文的不同而变化。这个简化的例子展示了加性注意力在计算关注度时的基本逻辑。在实际应用中,这些权重会用于计算最终的输出,通常是值(V)的加权和。
4.总结
加性注意力机制是一个强大而灵活的工具,它可以根据任务的需要被调整和优化。通过上述的例子,我们展示了如何从头到尾计算加性注意力,从而为理解这一机制的工作原理提供了深刻的洞见。这种机制的优势在于它的普遍适用性和在处理长序列时的有效性。
















 1528
1528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











