







 本文通过sklearn库探讨支持向量机(SVM)的决策边界和超平面可视化,包括线性可分和非线性数据的SVC求解过程。通过在二维和三维空间中展示数据分布,解释了线性SVC在非线性数据上的局限性,并介绍了如何通过改变kernel参数实现非线性决策边界的构建。
本文通过sklearn库探讨支持向量机(SVM)的决策边界和超平面可视化,包括线性可分和非线性数据的SVC求解过程。通过在二维和三维空间中展示数据分布,解释了线性SVC在非线性数据上的局限性,并介绍了如何通过改变kernel参数实现非线性决策边界的构建。
需求及思路
- 需求:画出啊决策边界和两个超平面
- 实现思路:从坐标轴上去出大量的点,将点的坐标值当作两个特征放入SVC模型中,预测每个点对应的类别。利用matplotlib中contour函数画出等高线(到决策边界距离相同的点具有相同的高度),保留[-1, 0, 1]三条。0对应决策边界,其他的两条就是两个超平面
本文代码使用到的第三方库如下
from sklearn.datasets import make_blobs, make_circles
from sklearn.svm import SVC
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
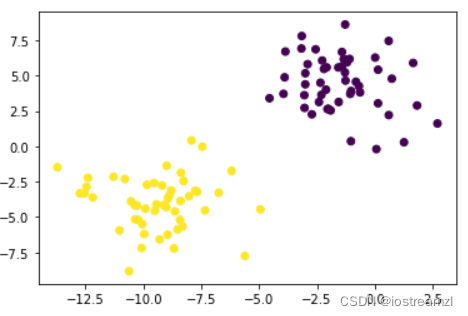
文中的使用数据集只有两个特征,一个标签,将两个特征作为横纵坐标,标签作为颜色就能画出数据的分布图了,画出分布情况的代码如下:
X, y = make_blobs(n_samples=100, n_features=2, centers=2, random_state=1, cluster_std=2)
# cluster_std 每个簇内部之间的标准差,用于控制每个簇的离散程度
# 第一个特征是横坐标,第二个特征是纵坐标
plt.scatter(X[:, 0], X[:, 1], c=y)
对于SVC的求解过程可以分为两种情况
-
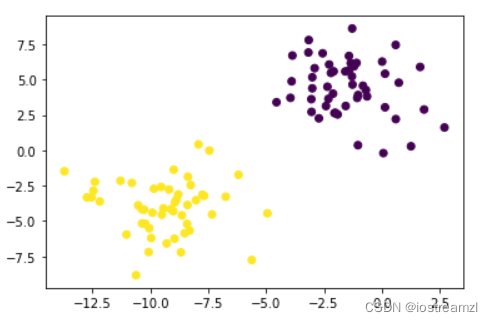
线性数据:可以直观的找到一条直线或一个平面,将数据分开,例如下面的数据就是线性可分的
-
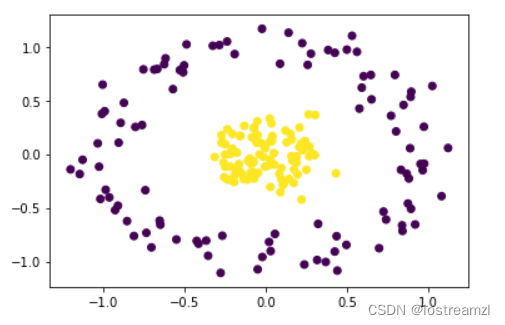
非线性数据:不能通过简单的直线或平面将数据分开,下面的数据就是非线性的
线性可分数据的SVC求解可视化
# 创建数据集
X, y = make_blobs(n_samples=100, n_features=2, centers= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









