




 本文详细介绍了numpy库中用于数据拼接的vstack和hstack函数,包括它们在不同情况下的使用,如数据形状匹配、行数列数变化等场景,帮助理解这两者在二维数组拼接时的区别和应用。
本文详细介绍了numpy库中用于数据拼接的vstack和hstack函数,包括它们在不同情况下的使用,如数据形状匹配、行数列数变化等场景,帮助理解这两者在二维数组拼接时的区别和应用。
序言
两个方法都是用作数据拼接,只不过拼接的维度方向不同,这篇文章会详细将两个方法的各种使用以及产生的结果
注意点:两个方法都只接受一个参数
vstack使用
vstack要求拼接的数据具用相同的列数。vstack相当于将数据一行一行的向后堆叠
a = np.array([1, 2, 3])
b = np.array([11, 22, 33])
c = np.array([111, 222])
d = np.array([[1111, 2222], [3333, 4444]])
e = np.array([[11111, 22222, 33333], [11111, 22222, 33333]])
display(a, b, c, d, e)

数据有相同的shape
# 同样shape
np.vstack((a, b))
array([[ 1, 2, 3],
[11, 22, 33]])
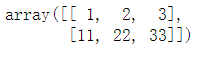
行数相同列数不同
# 行数相同,列数不同
np.vstack((a, c))

行数不同,列数相同
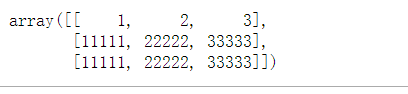
# 行数不同,列数相同
np.vstack((a, e))
行数列数都不同
# 行数不同,列数不同
np.vstack((a, d))

hstack使用
hstack要求数据具有有相同的行数,hstack将同一纬度的数据按照原始数据的顺序合并为一个新的列表,作为该维度新的数据
同样的shape
# 同样shape
np.hstack((a, b))
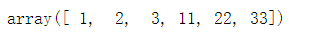
行数相同列数不同
# 行数相同,列数不同
np.hstack((d, e))
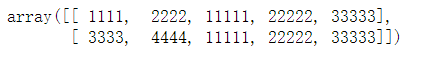
行数不同列数相同
# 行数不同,列数相同
np.hstack((a, e))
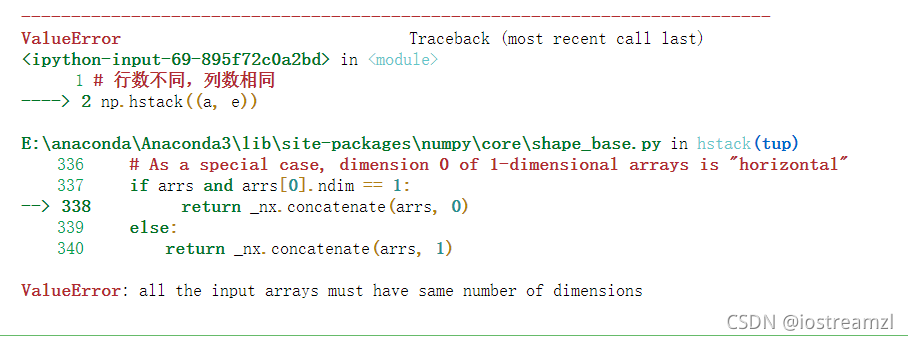
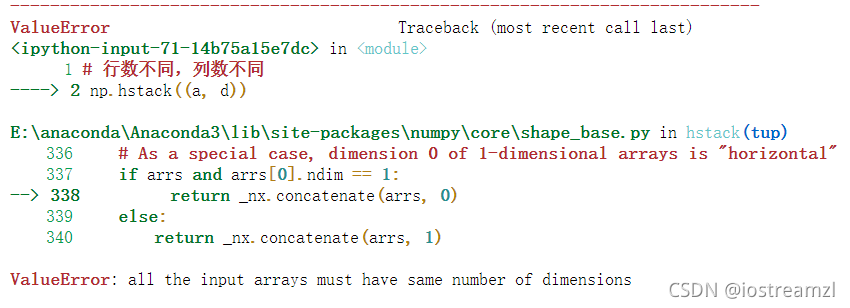
行数列数都不同
# 行数不同,列数不同
np.hstack((a, d))

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









