







文章目录
来源:CVPR2023:Integrally Pre-Trained Transformer Pyramid Networks
一、标题 作者

二、摘要
In this paper , we present an integral pre-training framework based on masked image modeling (MIM). We advocate for pre-training the backbone and neck jointly so that the transfer gap between MIM and downstream recognition tasks is minimal. We make two technical contributions. First, we unify the reconstruction and recognition necks by inserting a feature pyramid into the pretraining stage. Second, we complement mask image modeling (MIM) with masked feature modeling (MFM) that offers multi-stage supervision to the feature pyramid. The pre-trained models, termed integrally pre-trained transformer pyramid networks (iTPNs), serve as powerful foundation models for visual recognition. In particular , the base/large-level iTPN achieves an 86.2%/87.8% top-1 accuracy on ImageNet-1K, a 53.2%/55.6% box AP on COCO object detection with 1× training schedule using Mask-RCNN, and a 54.7%/57.7% mIoU on ADE20K semantic segmentation using UPerHead – all these results set new records. Our work inspires the community to work on unifying upstream pre-training and downstream fine-tuning tasks. Code and the pre-trained models will be released at https://github.com/sunsmarterjie/iTPN.
在本文中,我们提出了一个基于掩蔽图像建模 (MIM) 的整体预训练框架。我们提倡联合预训练 backbone 和 neck,使 MIM 和下游识别任务之间的迁移差距最小。我们做出了两项技术贡献。首先,我们通过在预训练阶段插入特征金字塔来统一重建和识别颈部。其次,我们用屏蔽特征建模 (MFM) 补充屏蔽图像建模 (MIM),为特征金字塔提供多阶段监督。预训练模型称为整体预训练变压器金字塔网络 (iTPN),可作为视觉识别的强大基础模型。特别是,base/large-level iTPN 在 ImageNet-1K 上达到了 86.2%/87.8% 的 top-1 准确率,在使用 MaskRCNN 进行 1× 训练计划的 COCO 目标检测上达到了 53.2%/55.6% 的 box AP,以及在使用 UPerHead 的 ADE20K 语义分割上达到 54.7% /57.7% mIoU ——所有这些结果都创下了新记录。我们的工作激励社区致力于统一上游预训练和下游微调任务。代码和预训练模型将在 https://github.com/sunsmarterjie/iTPN 发布。
三、正文
1. Introduction
近年来,视觉识别取得了两大进展,即作为网络主干的 vision transformer 架构和用于视觉预训练的掩蔽图像建模 (MIM) 。结合这两种技术产生了一个通用的pipeline,在广泛的视觉识别任务中实现了最先进的技术,包括图像分类、对象检测和实例/语义分割。
上述pipeline的关键问题之一是上游预训练和下游微调之间的迁移差距。从这个角度来看,我们认为下游视觉识别,尤其是精细尺度识别(例如,检测和分割),需要分层视觉特征。然而,大多数现有的预训练任务(例如 BEiT 和 MAE )都是建立在普通视觉转换器之上的。即使使用了分层 vision transformers(例如,在 SimMIM、ConvMAE 和 GreenMIM 中),预训练任务只会影响backbone,但不会影响neck(例如,特征金字塔) 。这给下游微调带来了额外的风险,因为优化从随机初始化的颈部开始,不能保证与预训练的backbone契合。
在本文中,我们提出了一个完整的预训练框架来减轻风险。我们使用 HiViT(一种 MIM 友好的分层vision transformer)建立基线,并为其配备特征金字塔。为了联合优化骨干(HiViT)和neck(特征金字塔),我们做出了双重技术贡献。首先,我们通过将特征金字塔插入预训练阶段(用于重建)并在微调阶段再次使用权重(用于识别)来统一上游和下游neck。其次,为了更好地预训练特征金字塔,我们提出了一个新的掩蔽特征建模 (MFM) 任务,该任务 (i) 通过将原始图像输入moving-averaged backbone来计算中间目标,以及 (ii) 使用每个目标的输出金字塔阶段重建中间目标。 MFM 是 MIM 的补充,提高了重建和识别的准确性。 MFM 还可以适应从预先训练的教师(例如 CLIP)那里吸收知识以获得更好的性能。
moving-averaged backbone是指在训练过程中,对CNN的权重进行移动平均。具体来说,假设当前时刻的权重为 w t w_t wt,则通过以下公式计算移动平均后的权重 w t + 1 w_{t+1} wt+1:
w t + 1 = α w t + ( 1 − α ) w t − 1 w_{t+1} = \alpha w_t + (1-\alpha)w_{t-1} wt+1=αwt+(1−α)wt−1
其中, α \alpha α是一个小于1的数,用于控制移动平均的速度。通过对权重进行移动平均,我们可以使模型的训练过程更加稳定,并且得到更好的泛化性能
在上述文本中,moving-averaged backbone被用于计算中间目标,即通过对原始图像输入移动平均后的CNN中,得到一系列的中间特征图。这些中间特征图可以被用于进一步的模型训练和优化。
获得的模型被命名为整体预训练金字塔 transformers 网络(iTPN)。我们在标准视觉识别基准上评估它们。如图 1 中突出显示的那样,iTPN 系列报告了最著名的下游识别准确度。在 COCO 和 ADE20K 上,iTPN 很大程度上受益于预训练的特征金字塔。例如,base/large-level iTPN 在 COCO(1× schedule,Mask R-CNN)上报告了 53.2%/55.6% box AP,在 ADE20K(UPerNet)上报告了 54.7%/57.7% mIoU,大幅超越所有现有方法。在 ImageNet-1K 上,iTPN 也显示出显着的优势,这意味着在与 neck 的联合优化过程中,backbone 本身变得更强大。例如,base/largelevel iTPN 报告了 86.2%/87.8% 的 top-1 分类准确率,比之前的最佳记录高出 0.7%/0.5%,这在如此激烈的竞争中看起来不小。

图1 上图:在 ImageNet-1K 分类上,iTPN 显示出优于现有方法的显着优势,无论是仅使用像素监督(上图)还是利用预训练教师的知识(下图,括号中是教师模型的名称)。底部:iTPN 在几个重要基准测试中的识别准确率 (%) 超过了之前的最佳结果。注 – IN-1K:ImageNet-1K,MR:Mask R-CNN [27],UP:UPerHead [60]。
在诊断实验中,我们表明 iTPN 具有 (i) MIM 预训练中较低的重建误差和 (ii) 下游微调中更快的收敛速度——这证实缩小传输间隙对上游和下游部分都有好处。
总的来说,本文的主要贡献在于完整的预训练框架,除了设置新的最先进的技术之外,还启发了一个重要的未来研究方向——统一上游预训练和下游微调以缩小它们之间的迁移差距.
2. Related Work
在深度学习时代,视觉识别算法大多建立在深度神经网络之上。在过去十年中有两个重要的网络主干,即CNN和vision transformers。本文重点介绍了从自然语言处理领域移植而来的vision transformers。核心思想是通过将每个图像块视为标记并计算它们之间的自注意力来提取视觉特征。
普通的vision transformers 以一种简单的形式出现,其中,在整个backbone中,token 的数量保持不变,并且这些 token 之间的注意力是完全对称的。为了补偿计算机视觉中的归纳先验,社区设计了分层视觉转换器 ,它允许 token 的数量在整个主干中逐渐减少,即类似于CNN。
还继承了其他设计原则,例如将卷积引入 transformer 架构,以便更好地制定邻域token 之间的关系 ,混合信息之间的交互,使用窗口或局部自我注意取代全局自我注意,调整局部-全局交互的几何结构,分解自我注意,等等。结果表明,分层vision transformers可以提供高质量、多层次的视觉特征,这些特征可以轻松地与neck模块(用于特征聚合,例如特征金字塔)合作,并有利于下游视觉识别任务。
视觉数据的持续增长需要视觉预训练,特别是从未标记的视觉数据中学习通用视觉表示的自我监督学习。自我监督学习的核心是一个代理任务,即模型追求的无监督学习目标。社区从初步代理任务开始,例如基于几何的任务(例如,确定图像块之间的相对位置或应用于图像的变换)和基于生成的任务(例如,恢复删除了图像的内容或属性),但是当转移到下游识别任务时,这些方法的准确性不令人满意(即,明显落后于完全监督的预训练)。当引入新的代理任务时,情况发生了变化,特别是对比学习和掩码图像建模 (MIM),后者是另一种基于生成的学习目标。
这篇论文聚焦于MIM,它利用了vision transformers的优势,将每个图像块转化为一个token。因此,token可以被任意屏蔽(从输入数据中丢弃),学习目标是在像素级别、特征级别或频率空间。 MIM 展示了一个名为可扩展性的重要属性,即增加预训练数据量(例如,从 ImageNet-1K 到 ImageNet-22K)和/或增加模型大小(例如,从基本级别到大型或巨大级别)可以提高下游性能,这与语言建模中的观察结果一致。研究人员还试图了解 MIM 的工作机制,例如将表示学习与代理任务分开,改变框架的输入或输出,增加重构的难度,引入其他方式的监督,等等。
大多数现有的 MIM 方法都适用于普通vision transformers,但分层vision transformers在视觉识别方面具有更高的潜力。第一个试图弥合差距的工作是 SimMIM,但整体预训练开销大大增加,因为整个图像(带有虚拟掩码补丁)被馈送到编码器。这个问题后来通过改进分层vision transformers以更好地适应 MIM 而得到缓解。本文继承设计并更进一步,将neck(例如,特征金字塔)集成到预训练阶段,构建整体预训练的变压器金字塔网络。
3. The Proposed Approach
3.1. Motivation: Integral Pre-Training
1、预训练阶段:数据集
D
p
t
=
{
x
n
p
t
}
n
=
1
N
\mathcal{D}^{\mathrm{pt}}=\left\{\mathbf{x}_n^{\mathrm{pt}}\right\}_{n=1}^N
Dpt={xnpt}n=1N 其中n是样本的数量,且没有标签
2、微调阶段:数据集
D
f
t
=
{
x
m
f
t
,
y
m
f
t
}
m
=
1
M
\mathcal{D}^{\mathrm{ft}}=\left\{\mathbf{x}_m^{\mathrm{ft}}, \mathbf{y}_m^{\mathrm{ft}}\right\}_{m=1}^M
Dft={xmft,ymft}m=1M,
y
m
f
t
\mathbf{y}_m^{\mathrm{ft}}
ymft 是
x
m
f
t
\mathbf{x}_m^{\mathrm{ft}}
xmft的标签
设目标深度神经网络由backbone、neck和head组成,记为
f
(
⋅
;
θ
)
,
g
(
⋅
;
ϕ
)
,
h
(
⋅
;
ψ
)
f(\cdot ; \boldsymbol{\theta}), g(\cdot ; \boldsymbol{\phi}), h(\cdot ; \boldsymbol{\psi})
f(⋅;θ),g(⋅;ϕ),h(⋅;ψ),其中
θ
,
ϕ
,
ψ
\theta, \phi, \psi
θ,ϕ,ψ是可学习的参数,为简单起见可以省略,
f
(
⋅
)
f(\cdot)
f(⋅)以
X
\mathbf{X}
X作为输入,
g
(
⋅
)
g(\cdot)
g(⋅)和
h
(
⋅
)
h(\cdot)
h(⋅)作用于
f
(
⋅
)
f(\cdot)
f(⋅)和
g
(
⋅
)
g(\cdot)
g(⋅)的输出,整个函数是
h
(
g
(
f
(
x
;
θ
)
;
ϕ
)
;
ψ
)
h(g(f(\mathbf{x} ; \boldsymbol{\theta}) ; \boldsymbol{\phi}) ; \boldsymbol{\psi})
h(g(f(x;θ);ϕ);ψ)
在本文中,预训练任务是掩码图像建模(MIM),微调任务可以是图像分类、目标检测和实例/语义分割。现有的方法假设它们共享相同的主干,但需要不同的颈部和头部。
数学上,预训练和微调目标写为:
min
E
D
p
t
∥
x
n
p
t
−
h
p
t
(
g
p
t
(
f
(
x
n
p
t
;
θ
)
,
ϕ
p
t
)
,
ψ
p
t
)
∥
min
E
D
f
t
∥
y
m
f
t
−
h
f
t
(
g
f
t
(
f
(
x
m
f
t
;
θ
)
,
ϕ
f
t
)
,
ψ
f
t
)
∥
\begin{aligned} & \min \mathbb{E}_{\mathcal{D}^{\mathrm{pt}}}\left\|\mathbf{x}_n^{\mathrm{pt}}-h^{\mathrm{pt}}\left(g^{\mathrm{pt}}\left(f\left(\mathbf{x}_n^{\mathrm{pt}} ; \boldsymbol{\theta}\right), \boldsymbol{\phi}^{\mathrm{pt}}\right), \boldsymbol{\psi}^{\mathrm{pt}}\right)\right\| \\ & \min \mathbb{E}_{\mathcal{D}^{\mathrm{ft}}}\left\|\mathbf{y}_m^{\mathrm{ft}}-h^{\mathrm{ft}}\left(g^{\mathrm{ft}}\left(f\left(\mathbf{x}_m^{\mathrm{ft}} ; \boldsymbol{\theta}\right), \boldsymbol{\phi}^{\mathrm{ft}}\right), \boldsymbol{\psi}^{\mathrm{ft}}\right)\right\| \end{aligned}
minEDpt
xnpt−hpt(gpt(f(xnpt;θ),ϕpt),ψpt)
minEDft
ymft−hft(gft(f(xmft;θ),ϕft),ψft)
其中
ϕ
p
t
\phi^{\mathrm{pt}}
ϕpt,
ϕ
f
t
\phi ^ { f t }
ϕft和
ψ
p
t
\boldsymbol{\psi}^{\mathrm{pt}}
ψpt、
ψ
f
t
\psi^{\mathrm{ft}}
ψft之前的参数不共享,我们认为,这样的管道会导致预训练和微调之间的显著转移差距,从而带来双重缺陷。
第一,是骨干参数,
θ
\theta
θ , 没有优化用于多级特征提取。第二,优化阶段从随机初始化的
ϕ
f
t
\phi ^ { f t }
ϕft和
ψ
f
t
\psi^{\mathrm{ft}}
ψft开始,这可能会减慢训练过程,导致识别结果不理想。为了缩小差距,我们提倡将
g
p
t
(
⋅
)
g^{\mathrm{pt}}(\cdot)
gpt(⋅)和
g
f
t
(
⋅
)
g^{\mathrm{ft}}(\cdot)
gft(⋅)统一起来的整体框架,使预先训练的
ϕ
p
t
\phi^{\mathrm{pt}}
ϕpt易于重用为
ϕ
f
t
\phi ^ { f t }
ϕft的初始化,从而只有
ψ
p
t
\boldsymbol{\psi}^{\mathrm{pt}}
ψpt是随机初始化的。
整体框架如图2所示:
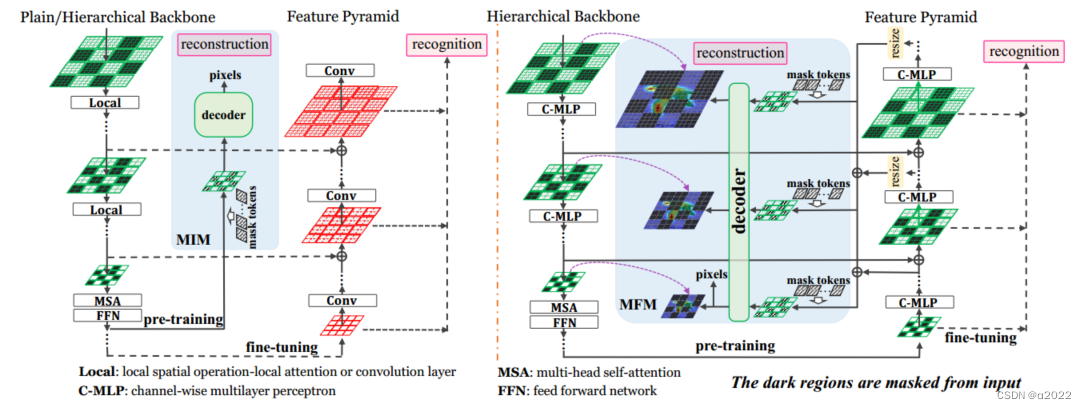
图2 传统的预训练(左)和提出的整体预训练框架(右)之间的比较。采用特征金字塔作为统一的颈部模块,采用掩码特征建模对特征金字塔进行预训练。绿色和红色块分别表示网络权重是预训练的和未训练的(即随机初始化进行微调)
3.2. Unifying Reconstruction and Recognition
设一个分层视觉transformer包含
S
S
S个阶段,每个阶段有几个transformer块。通常,backbone(即编码器)会逐渐对输入信号进行低采样,并生成
S
+
1
S + 1
S+1特征映射:
f
(
x
;
θ
)
=
U
0
,
U
1
,
…
,
U
S
f(\mathbf{x} ; \boldsymbol{\theta})=\mathbf{U}^0, \mathbf{U}^1, \ldots, \mathbf{U}^S
f(x;θ)=U0,U1,…,US
其中U0表示输入的直接嵌入,较小的上标索引表示更接近输入层的阶段。每个特征映射由一组标记(特征向量)组成,即
U
s
=
{
u
1
s
,
u
2
s
,
…
,
u
K
s
s
}
\mathbf{U}^s=\left\{\mathbf{u}_1^s, \mathbf{u}_2^s, \ldots, \mathbf{u}_{K^s}^s\right\}
Us={u1s,u2s,…,uKss},其中
K
s
K^s
Ks是第s个特征映射中的tokens数。
我们证明了
g
p
t
(
⋅
)
g^{\mathrm{pt}}(\cdot)
gpt(⋅)和
g
f
t
(
⋅
)
g^{\mathrm{ft}}(\cdot)
gft(⋅)可以共享相同的体系结构和参数,因为它们都以
U
s
U^s
Us开始,并逐渐将其与较低层次的特征聚合在一起。因此,我们将neck部分写成如下:
V
S
=
U
S
V
s
=
U
s
+
g
s
(
V
s
+
1
;
ϕ
s
)
,
1
⩽
s
<
S
\begin{aligned} & \mathbf{V}^S=\mathbf{U}^S \\ & \mathbf{V}^s=\mathbf{U}^s+g^s\left(\mathbf{V}^{s+1} ; \boldsymbol{\phi}^s\right), \quad 1 \leqslant s<S \end{aligned}
VS=USVs=Us+gs(Vs+1;ϕs),1⩽s<S
其中,
g
s
(
⋅
)
g^s(\cdot)
gs(⋅)向上采样
V
s
+
1
V^{s+1}
Vs+1,以拟合
V
s
V^s
Vs的分辨率。
注意,可学习参数
ϕ
\phi
ϕ是由一个分层参数集
{
ϕ
s
}
\left\{\phi^s\right\}
{ϕs}组成的。通过在微调中重新使用这些参数,我们在很大程度上缩小了迁移差距:在预训练和微调之间保持独立的唯一模块是头部(例如,用于MIM的解码器与用于检测的掩码R-CNN头部)。
在进入下一部分讨论损部分之前,我们提醒读者,预训练和微调之间存在其他差异,但它们不会影响网络架构的整体设计。
MIM对一个随机掩码
M
\mathcal{M}
M进行采样,并将其应用到
x
\mathbf{x}
x上,即
x
\mathbf{x}
x被
x
⊙
M
‾
\mathrm{x} \odot \overline{\mathcal{M}}
x⊙M取代,因此,所有的骨干输出
U
0
,
…
,
U
S
\mathbf{U}^0, \ldots, \mathbf{U}^S
U0,…,US,不包含
M
\mathcal{M}
M中有索引的token,以及
V
1
,
…
,
V
S
\mathbf{V}^1, \ldots, \mathbf{V}^S
V1,…,VS。在解码器开始时,
V
=
∑
s
=
1
S
V
s
\mathbf{V}=\sum_{s=1}^S \mathbf{V}^s
V=∑s=1SVs通过在掩码索引上添加虚拟标记来补充,然后输入解码器进行图像重建。
下游微调过程使用解码器的特定输出来完成不同的任务。对于图像分类,使用
V
S
\mathbf{V}^S
VS。对于检测和分割,所有
V
1
,
…
,
V
S
\mathbf{V}^1, \ldots, \mathbf{V}^S
V1,…,VS被使用。
3.3. Masked Feature Modeling
我们首先继承MIM的重构损失,使
∥
x
−
h
p
t
,
0
(
V
;
ψ
p
t
,
0
)
∥
\left\|\mathbf{x}-h^{\mathrm{pt}, 0}\left(\mathbf{V} ; \boldsymbol{\psi}^{\mathrm{pt}, 0}\right)\right\|
x−hpt,0(V;ψpt,0)
最小化,其中
h
p
t
,
0
(
⋅
)
h^{\mathrm{pt}, 0}(\cdot)
hpt,0(⋅)涉及几个transformer块,从
V
=
∑
s
=
1
S
V
s
\mathbf{V}=\sum_{s=1}^S \mathbf{V}^s
V=∑s=1SVs重建原始图像。为了获得捕获多阶段特征的能力,我们在每个阶段添加一个重建头,称为
h
p
t
,
s
(
⋅
;
ψ
p
t
,
s
)
h^{\mathrm{pt}, s}\left(\cdot ; \boldsymbol{\psi}^{\mathrm{pt}, s}\right)
hpt,s(⋅;ψpt,s),并优化以下多级损失:
L
=
∥
x
−
h
p
t
,
0
(
V
)
∥
⏟
image reconstruction
+
λ
⋅
∑
s
=
1
S
∥
x
s
−
h
p
t
,
s
(
V
s
)
∥
⏟
feature reconstruction
,
\mathcal{L}=\underbrace{\left\|\mathbf{x}-h^{\mathrm{pt}, 0}(\mathbf{V})\right\|}_{\text {image reconstruction }}+\lambda \cdot \underbrace{\sum_{s=1}^S\left\|\mathbf{x}^s-h^{\mathrm{pt}, s}\left(\mathbf{V}^s\right)\right\|}_{\text {feature reconstruction }},
L=image reconstruction
x−hpt,0(V)
+λ⋅feature reconstruction
s=1∑S
xs−hpt,s(Vs)
,
其中
x
s
\mathbf{x}^s
xs是第s个解码器阶段的预期输出,
λ
=
0.3
\lambda=0.3
λ=0.3是在保留的验证集中确定的。
由于目标是恢复屏蔽特征,我们将第二项命名为屏蔽特征建模(MFM)损失,它补充了第一项,屏蔽图像建模(MIM)损失。我们在图2中说明了MFM。
剩下的问题是确定中间重建目标,即
x
1
,
…
,
x
S
\mathbf{x}^1, \ldots, \mathbf{x}^S
x1,…,xS.我们借用知识蒸馏的思想,利用教师骨干层
f
^
back
(
⋅
)
\hat{f}^{\text {back }}(\cdot)
f^back (⋅)生成中间目标,即
f
^
(
x
;
θ
^
)
=
x
1
,
…
,
x
S
\hat{f}(\mathbf{x} ; \hat{\boldsymbol{\theta}})=\mathbf{x}^1, \ldots, \mathbf{x}^S
f^(x;θ^)=x1,…,xS教师模型被选择为移动平均编码器(在这种情况下,不引入外部知识)或另一个预先训练的模型(例如CLIP,如[57,58]所使用的,它是在图像-文本对的大型数据集上预先训练的)。在前一种情况下,我们只将屏蔽补丁(
x
⊙
M
\mathbf{x} \odot \mathcal{M}
x⊙M,而不是整个图像)提供给教师模型进行加速。在后一种情况下,我们遵循BEiT将整个图像馈送到预训练的CLIP模型。
顺便说一下,整体预训练和MFM带来的好处是单独的和互补的-我们将在消融中揭示这一点(表6)。
3.2. Unifying Reconstruction and Recognition
我们构建的系统超越了HiViT,这是一种最近提出的分层视觉转换器。HiViT通过以下方式简化了Swin变压器:(i)用通道级多层感知器(C-MLPs)替换早期移位窗口注意;(ii)删除7 × 7阶段,以便在14 × 14阶段计算全局注意。通过这些改进,当应用于MIM时,HiViT允许直接从输入中丢弃屏蔽令牌(相比之下,SimMIM使用Swin作为主干,要求使用整个图像作为输入),节省30%-50%的计算成本,并带来更好的性能。
表 1 总结了 iTPN 的配置。计算复杂度与 ViT 相当。我们按照惯例在预训练期间使用 224 × 224 图像。 HiViT 产生三个阶段 (S = 3) 与空间分辨率分别为 56×56、28×28 和 14×14。 S阶段的特征金字塔建立在主干之上。我们用 C-MLP 替换特征金字塔中的所有卷积,以避免信息从可见补丁泄漏到不可见补丁。正如我们将在消融(第 4.4 节)中看到的那样,在特征金字塔中使用 C-MLP 可以在各种视觉识别任务中获得一致的精度增益,并且这种改进是对 MFM 带来的改进的补充。
表 1. ViT、Swin、HiViT 和建议的 iTPN 在网络配置方面的比较。我们使用 224 × 224 输入大小来计算 FLOP。
†
\dagger
†:我们在 HiViT-B 中添加了 4 个 Stage-3 块,以保持 iTPN-B 的 FLOPs 与 ViT 相当

关于 MFM,我们研究了教师模型的两种选择。 (i) 第一个选项涉及计算在线目标模型的指数移动平均值 (EMA),系数为 0.996。我们从每个阶段的最后一层提取监督,因此对于任何
s
,
x
s
s, \mathbf{x}^s
s,xs 具有与
V
S
\mathbf{V}^S
VS 相同的空间分辨率,因此
h
s
(
⋅
)
h^s(\cdot)
hs(⋅) 是单独作用于每个token的线性投影。 (ii) 第二种选择直接继承一个CLIP预训练模型。请注意,CLIP 提供不生成多分辨率特征图的标准 ViT。在这种情况下,我们通过将所有特征映射下采样到最低空间分辨率(14×14),将它们加在一起,并将总和与 CLIP 模型的最后一层输出进行比较,将
S
S
S MFM 项统一为一个。















 1754
1754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









