







来源:B站莫烦Python
目的:解决过拟合现象
过拟合指的是一个机器学习模型在训练集上表现良好,但在测试集上表现较差的现象。这种现象通常是因为模型过于复杂,以至于它能够完美地拟合训练集中的每一个数据点,但是在面对新数据时却无法正确泛化。
L1正则化
误差 J ( θ ) = [ y θ ( x ) − y ] 2 + [ ∣ θ 1 ∣ + ∣ θ 2 ∣ . . ] \text { 误差 } J(\theta)=\left[y_\theta(x)-y\right]^2+\left[\left|\theta_1\right|+\left|\theta_2\right| . .\right] 误差 J(θ)=[yθ(x)−y]2+[∣θ1∣+∣θ2∣..]
L2正则化
误差 J ( θ ) = [ y θ ( x ) − y ] 2 + [ θ 1 2 + θ 2 2 + . . . ] \text { 误差 } J(\theta)=\left[y_\theta(x)-y\right]^2+\left[\theta_1^2+\theta_2^2+. . .\right] 误差 J(θ)=[yθ(x)−y]2+[θ12+θ22+...]
细说
误差 J ( θ ) = [ y θ ( x ) − y ] 2 + [ θ 1 2 + θ 2 2 + . . . ] \text { 误差 } J(\theta)=\left[y_\theta(x)-y\right]^2+\left[\theta_1^2+\theta_2^2+. . .\right] 误差 J(θ)=[yθ(x)−y]2+[θ12+θ22+...]
机器学习是通过修改
θ
\theta
θ来减小误差的过程,非线性越强的参数就会修改的越多
对正则化项进行限制,即:
[
∣
θ
1
∣
+
∣
θ
2
∣
.
.
]
<
=
w
\left[\left|\theta_1\right|+\left|\theta_2\right| . .\right]<=w
[∣θ1∣+∣θ2∣..]<=w
[
θ
1
2
+
θ
2
2
+
.
.
.
]
<
=
w
\left[\theta_1^2+\theta_2^2+. . .\right]<=w
[θ12+θ22+...]<=w
降低了
θ
\theta
θ的大小范围,从而降低了复杂度,所以解决了过拟合
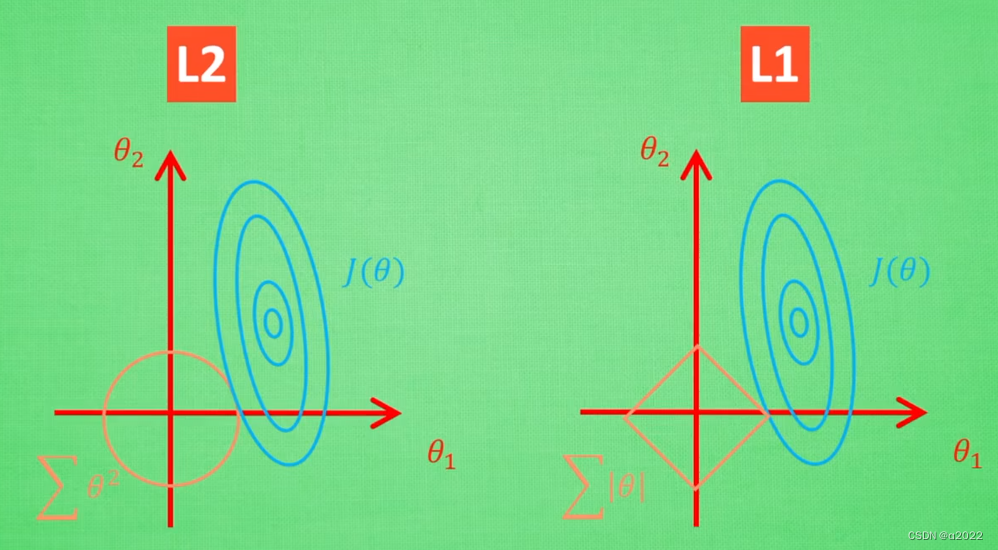
蓝色圆心是误差最小的地方,圆上的点误差相同,黄色为额外误差(可理解为惩罚度)
蓝色与黄线的交点能够让两个和最小,即
θ
1
θ
2
\theta_1 \theta_2
θ1θ2正规化后的解
L1能够保留对结果贡献最大的特征,如图只保留了
θ
1
\theta_1
θ1
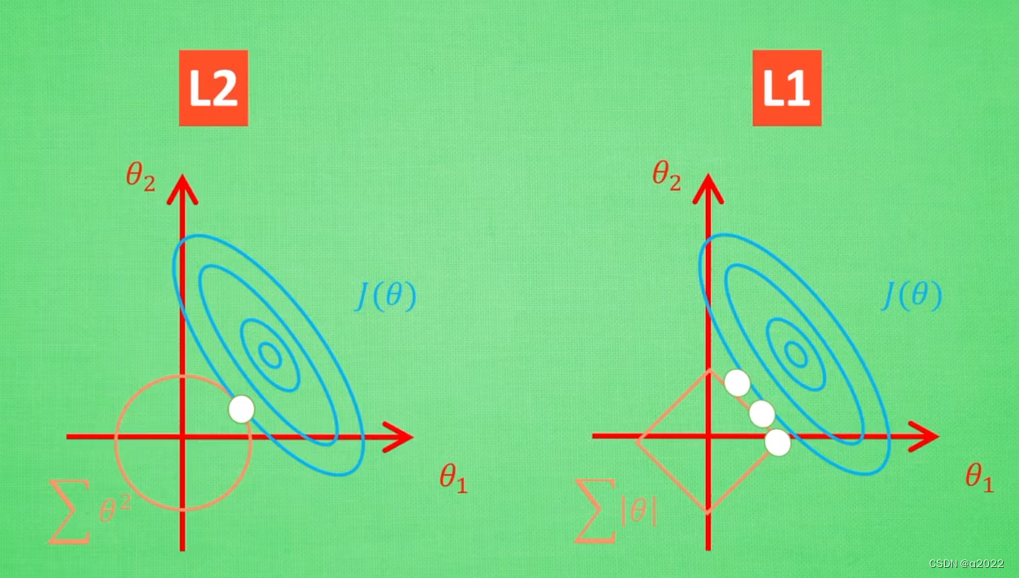
对于批数据量,数据的误差曲线发生变化
对于L2中的白点的位置可能不会移动很大,但是在L1中会跳到许多不同的地方,这也反映出L1正则化的解不稳定
通过控制正则化的强度加入
λ
\lambda
λ , 以及用
p
p
p来表示正则化程度
J
(
θ
)
=
[
y
θ
(
x
)
−
y
]
2
+
λ
∑
θ
i
p
J(\theta)=\left[y_\theta(x)-y\right]^2+\lambda \sum \theta_i^p
J(θ)=[yθ(x)−y]2+λ∑θip
通过交叉验证选择比较好的
λ
\lambda
λ















 7964
7964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









