







抓包详情
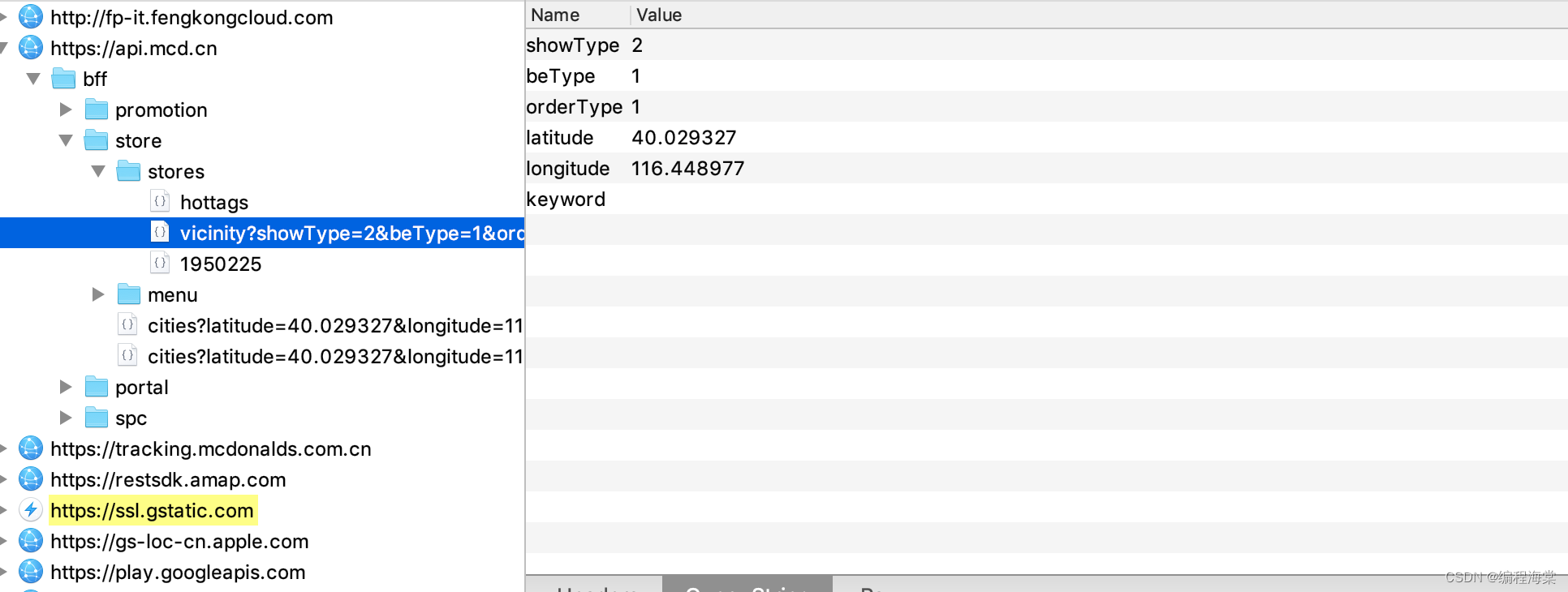
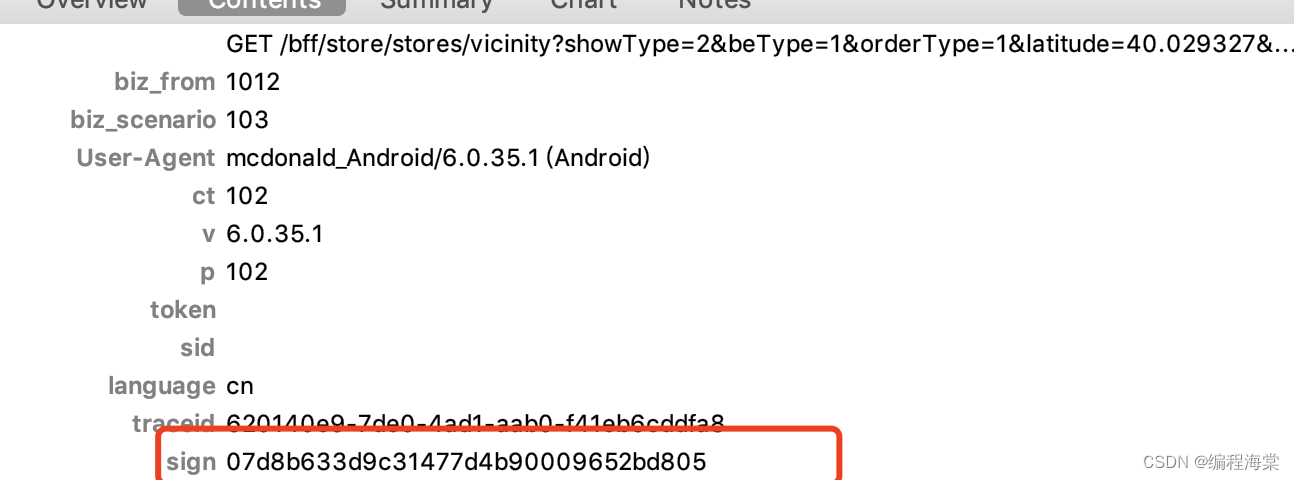
“communityQrcode”: “https://menu-img.mcd.cn/store/prod/store/communityQrcode/1950345_1.png”,
“deliveryFeeCode”: “7030”,
“duration”: null,
“deliveryTime”: null,
“estimatedDeliveryTime”: null,
“hotTagCodes”: [“breakfast”, “wifi”, “24h”, “mcCafe”, “mds”, “DT”, “gm”],
“businessHours”: null,
“dayparts”: [{
“daypartCode”: 1,
“daypartName”: “早餐”,
“startTime”: “05:00:00”,
“endTime”: “10:29:59”,
“daypartFlag”: false
}, {
“daypartCode”: 4,
“daypartName”: “下午茶”,
“startTime”: “14:30:00”,
“endTime”: “16:59:59”,
“daypartFlag”: false
}, {
“daypartCode”: 5,
“daypartName”: “夜市”,
“startTime”: “17:00:00”,
“end
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









