









 本文介绍强化学习,用马尔可夫决策过程描述,目标是找到使长期累积奖赏最大化的策略。还阐述了k - 摇臂赌博机,涉及探索与利用的折中,介绍了贪心策略和Softmax算法,并通过简单例子对比不同算法在不同参数下的平均累积奖赏。
本文介绍强化学习,用马尔可夫决策过程描述,目标是找到使长期累积奖赏最大化的策略。还阐述了k - 摇臂赌博机,涉及探索与利用的折中,介绍了贪心策略和Softmax算法,并通过简单例子对比不同算法在不同参数下的平均累积奖赏。
1.强化学习简单介绍
强化学习任务通常用马尔可夫决策过程(MDP)来描述:机器处于环境E中,状态空间为X,其中每个状态x∈X是机器感知到的环境的描述,机器能采取的动作构成了动作空间A;若某个动作a∈A作用在当前状态x上,则潜在的转移函数P使得环境从当前状态按某种概率转移到另一个状态,在转移到另一种状态的同时,环境会根据潜在的“奖赏”函数R反馈给机器一个“奖赏”。综合起来,强化学 习任务对应了四元组E=<X,A,P,R>,机器要做的是通过在环境中不断地尝试而学得一个"策略"Π,根据这个策略,在状态x下就能得知要执行的动作a=Π(x)。
策略的好坏取决于长期执行这一策略后得到的累计奖赏,在强化学习任务中,学习的目的就是要找到能使长期累积奖赏最大化的策略。长期累积奖赏有多种计算方式,常用的有“T步累积奖赏”和“γ折扣累积奖赏”,公式分别如下:
T步累积奖赏:
γ折扣累积奖赏:
其中rt表示第t步获得的奖赏值,E表示对所有随机变量求期望。
2.k-摇臂赌博机
2.1探索与利用
强化学习任务的最终奖赏是在多步以后才能观察到,不妨假设一个简单的情形:最大化单步奖赏。但是这种情形下需要考虑两个因素:一是知道每个动作带来的奖赏,二是要执行奖赏最大的动作。若每个动作对应的奖赏是一个确定的值,那么尝试一遍所有的动作便能找到奖赏最大的动作。然而更一般的,一个动作的奖赏来自于一个概率分布,仅通过一次尝试不能确切地获得平均奖赏。事实上,这刚好对应一个理论模型——“k-摇臂赌博机”。k-摇臂赌博机有k个摇臂,赌徒在投入一个硬币后可以选择其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒是不知道的。赌徒的目的是通过一定的策略获得最多的硬币。
若仅获知每个摇臂的期望奖赏,则可采用“仅探索”法。将尝试所有的摇臂,最后以每个摇臂平均吐币概率作为其奖赏期望的估计。若仅为执行奖赏最大的动作,则采用“仅利用”法:只考虑目前最优的摇臂,若有多个则随机选取。显然,“仅探索”能很好地估计每个摇臂的奖赏,却会失去很多选择最优摇臂的机会;“仅利用”法虽然不能很好地估计每个摇臂的期望奖赏,却可能选不到最优摇臂。因此两种方法都难以达到最大奖赏。
显然,要尽可能地获得最大奖赏,应该对“仅探索”和“仅利用”进行折中,一边探索一边选择目前最优的摇臂。
2.2 贪心策略
E-贪心策略基于一个概率对探索和利用进行折中:每次尝试时,以概率E选择探索,以概率1-E进行利用。用Q(k)记录摇臂k的平均奖赏,则E-贪心算法如下: 该算法中,通过rand()函数尝试一个随机数,若该随机数小于E,则进行“探索”,否则进行“利用”。在经过这一步后选定了摇臂k,R(k)记录了摇臂的回报值,通过r累加记录累积奖赏,Q(k)的计算式更新摇臂k的平均奖赏,然后摇臂的词书count(k)增加一次。至此,完成一次工作。但是,若摇臂的不确定性较大,例如概率分布较宽时,则需更多的探索,即需要更大的E值;若摇臂的不确定性较小,则进行少量尝试就能很好的接近真实奖赏,此时需要E较小。随着工作地推进,在尝试次数较多以后,摇臂的奖赏都能很好地近似出来,这是应该减少探索而增加利用,此时可以令E=1/sqrt(t)
该算法中,通过rand()函数尝试一个随机数,若该随机数小于E,则进行“探索”,否则进行“利用”。在经过这一步后选定了摇臂k,R(k)记录了摇臂的回报值,通过r累加记录累积奖赏,Q(k)的计算式更新摇臂k的平均奖赏,然后摇臂的词书count(k)增加一次。至此,完成一次工作。但是,若摇臂的不确定性较大,例如概率分布较宽时,则需更多的探索,即需要更大的E值;若摇臂的不确定性较小,则进行少量尝试就能很好的接近真实奖赏,此时需要E较小。随着工作地推进,在尝试次数较多以后,摇臂的奖赏都能很好地近似出来,这是应该减少探索而增加利用,此时可以令E=1/sqrt(t)2.3 Softmax
Softmax算法基于2.2中的E-贪心策略,但是Softmax算法中摇臂概率的分配是基于Boltzmann分布:
(16.4)
其中,Q(k)记录当前摇臂的平均奖赏,T>0称为“温度”,越小则平均奖赏高的摇臂被选中的概率越高。若趋近于0时Softmax将趋近于“仅利用”,趋近于无穷大时,将趋近于“仅探索”。算法如下:
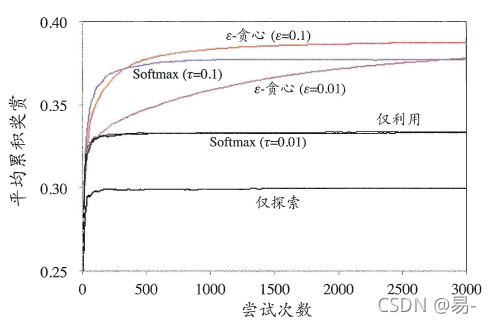
E-贪心算法与Softmax算法谁更好需要结合具体问题。现考虑一个简单的例子,假定2-摇臂赌博机的摇臂1以0.4的概率返回奖赏1,以0.6的概率返回奖赏0;摇臂2以0.2的概率返回奖赏1,以0.8的概率返回奖赏0。在下图中显示了不同算法在不同参数下的平均累积奖赏,其中每条曲线对应于重复1000次实验的平均结果。可以看出,Softmax中,当t=0.01时曲线与“仅利用”的曲线几乎重合。

将在后面一篇文章中介绍有模型学习:强化学习之有模型学习_易-的博客-CSDN博客
和免模型学习:https://blog.csdn.net/weixin_43797015/article/details/121588382
参考资料:《机器学习》周志华著,清华大学出版社


















 3717
3717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











