






简介
自然语言处理(NLP)作为计算机科学和人工智能领域的一个重要分支,旨在将人类语言转化为计算机可执行的命令,使计算机能够 处理和理解复杂多变的人类语言。本文主要基于NLP技术实现 ”智能对话系统”(又称聊天机器人),其中关键点在于首先使用各自场景的语料库对聊天机器人模型进行训练,当用户输入语句时对用户进行意图匹配,转到相应场景对应的聊天机器人模型进行答案生成。
源码
本项目主要使用python语言实现,如果想要完整代码,这里也提供了我的github链接Github。
程序架构设计
聊天机器人的架构由五个关键模块组成:意图匹配、身份管理、闲聊、信息问答检索以及餐厅预订交易。

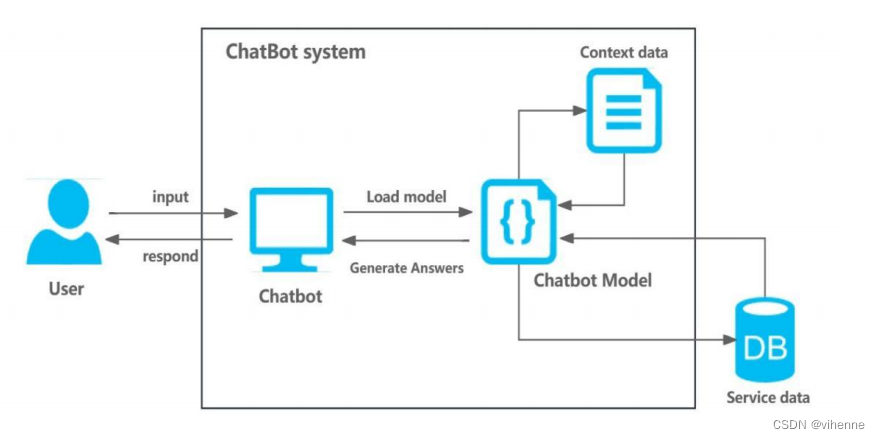
当用户输入一个句子时,系统首先将句子处理成词向量,然后通过计算输入句子的词向量与模型语料库之间的最大余弦相似度来进行意图匹配,使用相似度最高的模块来作为用户意图模块。对话系统将根据匹配的意图加载聊天机器人模型,使用该模型生成答案,最后进入下一个循环。如果用户的意图是退出系统,程序就会停止。
项目结构说明
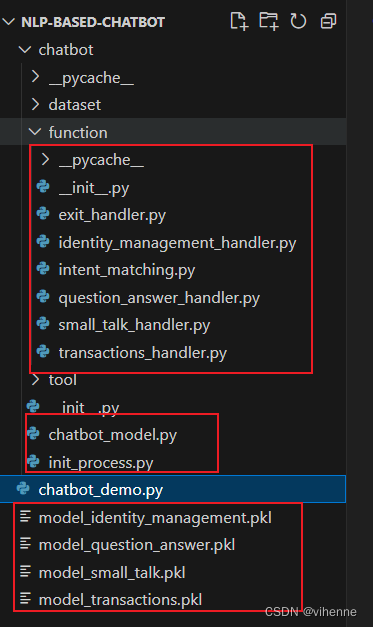
- 启动入口即 chatbot_demo.py文件,这是项目启动的入口,运行本文件,则启动并初始化聊天机器人。
from chatbot.function import intent_matching
from chatbot.function import exit_handler
from chatbot.tool import format_tool
from chatbot import init_process
# 训练聊天机器人模型
# init_process.train_model()
# 初始化聊天机器人,加载上下文信息
chatbot = init_process.init_chatbot()
format_tool.bot_response('Hello! What can I help you?')
# 竟然问答循环,直到结束
while True:
# 用户输入
input_text = format_tool.user_input()
# 意图匹配
user_intent = intent_matching.martch_intent(chatbot, input_text)
# 匹配到退出意图
if user_intent == 'exit':
exit_handler.operation(input_text)
break
elif user_intent == None:
format_tool.bot_response("I'm sorry, I don't understand that.")
else:
# 匹配到用户的意图
# 加载对应聊天机器人模型
init_process.init_chatbot_context(chatbot, user_intent, input_text)
# 调用模型生成答案
chatbot.answer()
-
chatbot_model.py 文件中主要是定义了chatbot class 和其他相关类,这块内容会在下面进行阐述。
-
init_process.py文件中主要是定义了聊天机器人初始化方法以及训练方法。由于语料库数据比较多,不可能每次问答时去调用语料库计算,所以聊天机器人需要先训练,然后将各个业务语言模型以及对应的处理后语料库数据一起保存到plk文件中。
初始化时就是把所有场景的聊天机器人语言模型从plk文件加载到内存中,这样可以节省训练和加载数据的时间。 -
语料库数据
每种业务场景都有对应语料库,这样才能计算用户意图以及生成答案。语料库中以(问题-答案)的数据形式存在,本项目主要是基于英语问答流实现,中文实现原理也相同,就不赘述了。
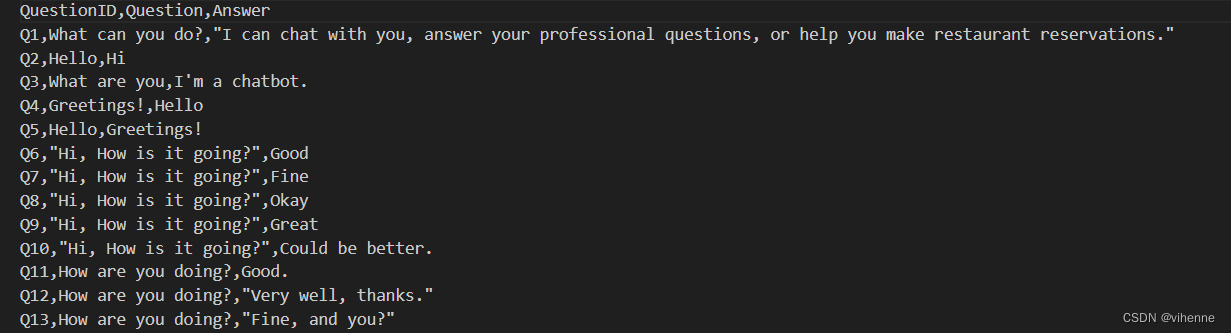
-
function目录下是核心功能的具体实现逻辑,包括意图匹配和四个业务功能,主要作用就是生成答案。当意图匹配完成时,就调用对应语言模型,语言模型根据用户输入以及业务模型中的上下文和语料库数据调用对应handler中的方法生成答案。

-
tool目录下主要是一些简单计算方法的抽象,比如余弦相似度计算、语句封装、读取文件、文本处理。
项目实体抽象设计
为了提高系统的可读性和可维护性,本文对系统的关键概念进行了抽象(定义在chatbot_model.py文件中)。
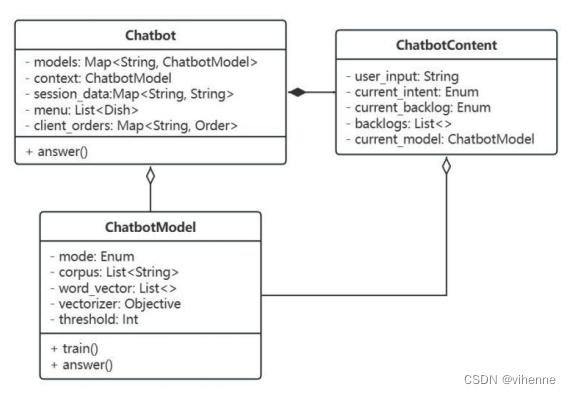
1.系统聊天机器人对象被抽象为聊天机器人Chatbot类。
# chatbot class
class Chatbot():
def __init__(self):
# Chatbot model list
self.models = {}
# Chatbot Context information
self.context = ChatbotContent()
# Session data
self.session_data = {}
# transactions data
self.menu = []
self.client_orders = {}
def answer(self):
if self.context == None:
return None
#load current chatbot_model
chatbot_model = self.context.current_model
if chatbot_model == None or self.context.user_input == None:
return None
# run the model to
chatbot_model.answer(chatbot=self)
2.为了支持上下文跟踪,系统的上下文将被抽象为 ChatbotContext 类,用于记录上下文数据和操作信息。该类用于记录上下文数据和操作信息。
# chatbot content class
class ChatbotContent():
def __init__(self):
self.user_input = None
self.current_intent = None
self.current_backlog = None
self.backlogs = []
self.current_model = None
3.由于聊天机器人在不同的业务场景中需要不同的语言模型和语料库,所以将其抽象为ChatbotModel类。
# chat model class
class ChatbotModel():
def __init__(self):
# chatbot mode: 1.identity_management, 2.small_talk, 3.question_answer, 4.transactions
self.mode = None
# corpora in the current mode
self.corpus = []
# word vectors for all sentences in the current corpus
self.word_vector = None
# vectorizer
self.vectorizer = None
# similarity threshold
self.threshold = 0.2
def train(self, vectorizer = TfidfVectorizer()):
self.vectorizer = vectorizer
# Generated word vector
if len(self.corpus) != 0:
word_vector = text_process.process_text_list(self.corpus['Question'])
word_vector = self.vectorizer.transform(word_vector)
self.word_vector = word_vector
return None
def answer(self, chatbot):
# Get chatbot context
intent = chatbot.context.current_intent
while chatbot.context != None:
intent_list = intent_matching.get_intents()
# enters different processing depending on the user's intent
if intent == intent_list[0]:
identity_management_handler.operation(chatbot, self)
elif intent == intent_list[1]:
small_talk_handler.operation(chatbot, self)
elif intent == intent_list[2]:
question_answer_handler.operation(chatbot, self)
elif intent == intent_list[3]:
transactions_handler.operation(chatbot, self)
else:
format_tool.bot_response("I'm sorry, I don't understand that.")
return None
4.餐厅订餐业务中,为了方便数据流转处理,抽象出Dish类和Order类。
# dish in menu
class Dish():
def __init__(self):
self.dish_name = None
self.price = 0
self.quantity = 0
# Customer order
class Order():
def __init__(self):
self.user_name = None
self.tel = None
self.time = None
self.diners_quantity = None
self.dishes = []
self.order_amount = 0
self.remark = None
# order_status: unpaid,complete
self.order_status = None
功能实现
输入语句文本处理
用户输入语句可能参杂噪音,所以需要将每次用户输入进行文本处理为词向量,文本处理流程如下:
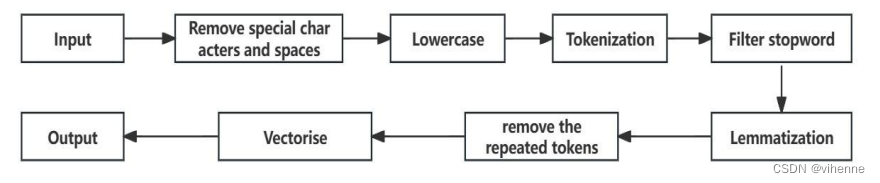
首先删除用户输入句子中的特殊字符和额外空格,并将其转换为小写字母。然后对生成的句子进行标记化处理,以获得与输入句子相对应的标记。下一步是停止词过滤和词素化,将标记词转换为 词素,最后对词素进行矢量化,得到相应的词向量。
# Process the text of the sentence
def process_text(input_text):
# Remove special characters and extra Spaces from text
input_text = re.sub(r'[^a-zA-Z0-9\s]', '', input_text)
input_text = re.sub(r'\s+', ' ', input_text)
# Lowercasing
input_text = input_text.lower()
# Tokenization
tokens = word_tokenize(input_text)
# stopword removal
tokens_without_sw = [word.lower() for word in tokens if not word in stopwords]
# Lemmatization
lemmatiser = WordNetLemmatizer()
posmap = {'ADJ': 'a','ADV': 'r','NOUN': 'n','VERB': 'v'}
post = nltk.pos_tag(tokens_without_sw, tagset='universal')
lemmas_sent = []
for word, pos_tag in post:
wordnet_pos = posmap.get(pos_tag,None)
lemma = lemmatiser.lemmatize(word, pos=wordnet_pos) if wordnet_pos else lemmatiser.lemmatize(word)
lemmas_sent.append(lemma)
# remove repeated tokens
lemmas_sent = list(OrderedDict.fromkeys(lemmas_sent))
# Rebuild text
input_text = (" ").join(lemmas_sent)
return input_text
意图匹配实现
意图匹配是自然语言处理(NLP)和对话系统中的一项关键任务,用于识别或预测用户输入的意图和需求。用户输入的意图和需求,引导用户进入不同的业务流程。在本文中,用户意图根据需求 根据需求分为五类:身份管理、闲聊、信息检索和问题解答、餐厅预订交易、退出。该对话系统基于余弦相似度实现用户意图匹配 通过计算用户输入句子与每个语料库之间的最大余弦相似度来匹配用户意图。余弦相似度的计算公式为:
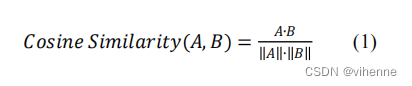
# calculate the vectors similarity, get return the max one
def get_max_similarity(vector = [], vectors = [], vectorizer = TfidfVectorizer(), threshold = 0):
max_similarity = 0
max_similarity_index = None
if(vector == None or vectors == None or vector.getnnz() == 0 or vectors.getnnz() == 0):
return max_similarity, max_similarity_index
similarities = cosine_similarity(vector, vectors)
max_similarity_index = similarities.argmax()
max_similarity = similarities[0][max_similarity_index]
if(max_similarity < threshold):
max_similarity = 0
max_similarity_index = None
return max_similarity, max_similarity_index
而意图匹配的具体实现就是计算用户输入语句与每个语料库的最大余弦相似度,哪一个最大相似度值最大,则这个语料库对应业务场景就是用户的可能意图。当然我们也需要设置阈值,防止匹配可能性都很低的情况。
# match user intent based similarity
def martch_intent(chatbot, input_text):
matched_intent = None
# The most similar item in intent
max_similarity = 0
max_similarity_index = None
# User input statement preprocessing
input_text = text_process.preprocess_input(input_text)
if input_text in exit_rules:
matched_intent = "exit"
return matched_intent
intents = intent_list[:-1]
for intent in intents:
# get model vectors
model = chatbot.models[intent]
word_vectors = model.word_vector
vectorizer = model.vectorizer
# Converts input statements to vectors
vector = calculate_similarity.generate_text_vectors(input_text, vectorizer)
# calculate the similarity
max_item_similarity, max_item_similarity_index = calculate_similarity.get_max_similarity(vector, word_vectors, vectorizer, model.threshold)
# Remember the most similar intent terms
if max_item_similarity > max_similarity:
max_similarity = max_item_similarity
max_similarity_index = max_item_similarity_index
matched_intent = intent
return matched_intent
闲聊模块实现
from sklearn.feature_extraction.text import TfidfVectorizer
import sys
sys.path.append('..')
from chatbot.tool import calculate_similarity
from chatbot.tool import format_tool
from chatbot.tool import text_process
# Use similarity to match answers
def operation(chatbot, chatbot_model):
corpus = chatbot_model.corpus
word_vector = chatbot_model.word_vector
vectorizer = chatbot_model.vectorizer
input_text = chatbot.context.user_input
# 用户输入语句处理
input_text = text_process.preprocess_input(input_text)
# 输入语句词向量化
vector = calculate_similarity.generate_text_vectors(input_text, vectorizer)
# 计算用户输入语句与语料库的最大相似度
max_similarity, max_similarity_index = calculate_similarity.get_max_similarity(vector, word_vector, vectorizer, chatbot_model.threshold)
if max_similarity_index == None:
format_tool.bot_response("I'm sorry, I don't understand that.")
chatbot.context = None
return None
# 返回相似度最大问答语句的答案
answer = corpus["Answer"][max_similarity_index]
format_tool.bot_response(answer)
# 清空上下文
chatbot.context = None
身份管理模块实现
身份管理的关键点在于从用户输入中切分出用户名,并保存在山下文(即chatbot.session_data[“user_name”])中,然后再答案生成时将用户名称按模板集成到回答语句中。
# Use similarity to match answers
def operation(chatbot, chatbot_model):
corpus = chatbot_model.corpus
word_vector = chatbot_model.word_vector
vectorizer = chatbot_model.vectorizer
input_text = chatbot.context.user_input
# Name ask process
if chatbot.context.current_backlog == "ask_name":
format_tool.bot_response("Sorry, Could you please tell me your name?")
name_input = format_tool.user_input()
user_name = extract_name_from_sentences(name_input)
if user_name == None:
format_tool.bot_response("I'm sorry, I don't understand that.")
chatbot.context = None
return None
store_name_data(chatbot, user_name)
# User input statement preprocessing
input_text_processed = text_process.preprocess_input(input_text)
# Converts input statements to vectors
vector = calculate_similarity.generate_text_vectors(input_text_processed, vectorizer)
# calculate the similarity
max_similarity, max_similarity_index = calculate_similarity.get_max_similarity(vector, word_vector, vectorizer, chatbot_model.threshold)
if max_similarity_index == None:
format_tool.bot_response("I'm sorry, I don't understand that.")
chatbot.context = None
return None
# query user name
user_name = query_user_name(chatbot, input_text, max_similarity_index, corpus)
# generate the answer
answer = generate_answer(chatbot, user_name, max_similarity_index, corpus)
return None
用户名称切割使用NLTK库的post_tag()函数进行语音标记,然后使用ne_chunk()函数识别命名实体,从而获得用户的名称数据,切割语句中的用户名称方法实现如下:
# Extract names from sentences
def extract_name_from_sentences(input_text):
words = word_tokenize(input_text)
pos_tags = pos_tag(words)
named_entities = ne_chunk(pos_tags)
# get names
names = []
for entity in named_entities:
if isinstance(entity, nltk.Tree) and entity.label() == 'PERSON':
name = ' '.join([word for word, tag in entity.leaves()])
names.append(name)
name_str = None
if len(names) != 0:
name_str = names[0]
else:
return None
return name_str
知识问答模块实现
信息检索系统的主要目的是帮助用户快速有效地查询信息。该系统使用收集的问题解答知识库来训练对话系统,计算余弦相似度从而匹配最有可能的问题答案。当然,未来还可以使用基于 TF-IDF 或知识图谱的检索方法对该模型进行优化。
from sklearn.feature_extraction.text import TfidfVectorizer
import sys
sys.path.append('..')
from chatbot.tool import calculate_similarity
from chatbot.tool import format_tool
from chatbot.tool import text_process
# Use similarity to match answers
def operation(chatbot, chatbot_model):
corpus = chatbot_model.corpus
word_vector = chatbot_model.word_vector
vectorizer = chatbot_model.vectorizer
input_text = chatbot.context.user_input
# User input statement preprocessing
input_text = text_process.preprocess_input(input_text)
# Converts input statements to vectors
vector = calculate_similarity.generate_text_vectors(input_text, vectorizer)
# calculate the similarity
max_similarity, max_similarity_index = calculate_similarity.get_max_similarity(vector, word_vector, vectorizer, chatbot_model.threshold)
if max_similarity_index == None:
format_tool.bot_response("I'm sorry, I don't understand that.")
chatbot.context = None
return None
# query the answer
answer = corpus["Answer"][max_similarity_index]
format_tool.bot_response(answer)
# clearn
chatbot.context = None
订餐交易模块实现
聊天机器人的交易模块主要实现餐厅预订系统。通过意图匹配进入该模块的用户将进入交易对话流程。由于餐厅业务的复杂性和多变性,该系统将餐厅订餐业务分为七个主要业务小流程:预订、查看预订、修改预订、点餐、取消订单、查看订单和结算订单。
事务系统的业务流程总是复杂、冗长和不稳定的。如下图所示,系统将七个主要业务流程进一步划分为更细的子任务,不同子任务的组合将产生不同类型的业务流程。不同子任务的组合将产生不同类型的业务流程。通过设计和抽象,该系统可以很好地适应灵活多变的业务场景。
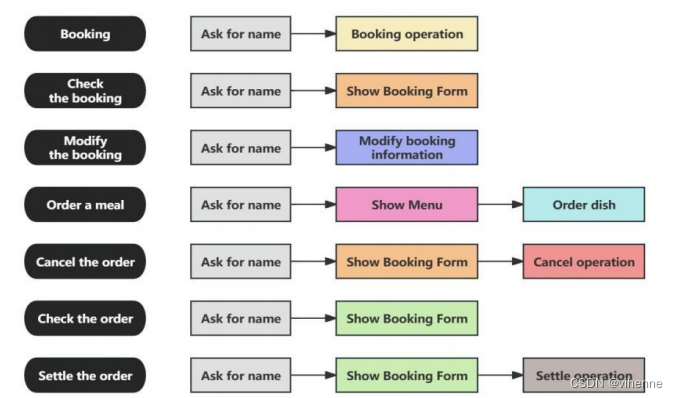
当用户进入一个业务流程时(如订餐),则系统会将这个流程的几个步骤(如询问姓名,展示菜单,下单等)步骤逆序压入待办事项栈,每次从栈中取一个步骤进行操作,直到所有的步骤都完成,则这个业务流程停止,业务数据保存在上下文中。
以下只展示核心代码,详细代码实现请参考我的git项目。
# 定义每个业务流程以及具体步骤
transactions_intents = ["BOOKING","ORDER","CANCEL","CHECK_ORDER","SETTLE","SHOW_MENU","CHECK_BOOKING","MODIFY_BOOKING"]
intent_backlog = {
"BOOKING": ["ask_name","booking"],
"CHECK_BOOKING": ["ask_name","show_booking"],
"MODIFY_BOOKING": ["ask_name","modify_booking"],
"ORDER": ["ask_name","show_menu","order_dish"],
"CANCEL": ["ask_name","show_order","cancel_order"],
"CHECK_ORDER": ["ask_name","show_order"],
"SETTLE": ["ask_name","show_order","settle_order"],
"SHOW_MENU": ["show_menu"]
}
def operation(chatbot, chatbot_model):
# 取代办事项列表
backlogs = chatbot.context.backlogs
if(backlogs is not None and len(backlogs) > 0):
chatbot.context.current_backlog = chatbot.context.backlogs[-1]
current_backlog = chatbot.context.current_backlog
# operation result: succeed, fail, cancel, next
result = "succeed"
# 取一个步骤进行具体操作
if current_backlog == "ask_name":
result = ask_name(chatbot)
elif current_backlog == "booking":
result = booking(chatbot)
elif current_backlog == "show_menu":
result = show_menu(chatbot)
elif current_backlog == "order_dish":
result = order_dish(chatbot)
elif current_backlog == "show_order":
result = show_order(chatbot)
elif current_backlog == "settle_order":
result = settle_order(chatbot)
elif current_backlog == "show_booking":
result = show_booking(chatbot)
elif current_backlog == "modify_booking":
result = modify_booking(chatbot)
else:
result = cancel_order(chatbot)
# 后续处理
if result == "cancel":
# Clear context
chatbot.context = None
return None
elif result == "fail":
# try again
return None
elif result == 'next':
# go to next step
return None
else:
if len(backlogs) == 1:
chatbot.context = None
return None
elif len(backlogs) > 1:
# remove the last element
chatbot.context.backlogs.pop()
return None
else:
return None
# 确定业务流程
question_intent = get_question_intent(chatbot, chatbot_model)
if question_intent is None:
format_tool.bot_response("I'm sorry, I don't understand that.")
chatbot.context = None
return None
# 将业务流程对应的步骤逆序压入栈中
chatbot.context.backlogs = []
chatbot.context.backlogs.extend(intent_backlog.get(question_intent,[]))
chatbot.context.backlogs.reverse()
return None
演示
- 预定演示
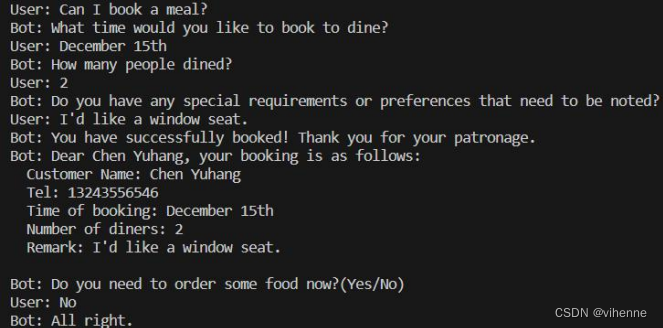
2.取消预定演示
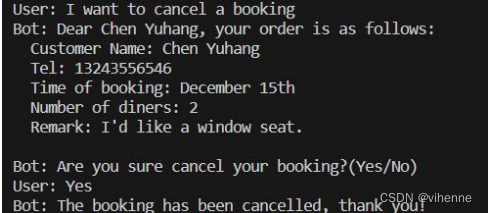
3.上下文演示
总结
本次实现的聊天机器人其实并不复杂,主要是用到了NLP的基础知识和基本准则,且大多数关键功能都是基于余弦相似度的简单实现,如果有兴趣的话,可以将意图匹配的实现改为基于机器学习模型实现,其实就是基于输入语句词向量预测输出语句词向量,再去生成答案。不过本系统对于NLP初学者来说是很好的锻炼机会。
















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









