







0. 导读
0.1 文章是关于什么的?(what?)
用知识表示来做链接预测,其中使用了2D的卷积操作
0.2 要解决什么问题?(why?|challenge)
- 计算速度
- 对于复杂网络的适应性
0.3 用什么方法解决?(how?)
- 用了2D的卷积操作
0.4文章有什么创新?
- 首次引入一个简单的2D卷积操作来进行链接预测任务;
- 展示了一个1-N分数过程来加速训练;
- 提出的模型可以用于复杂图
0.5 效果如何?
0.6 还存在什么问题?
1 背景知识
通过使用2D而不是1D卷积,可以通过嵌入之间的其他交互点来提高模型的表达能力。作者考虑一个两行的1D 嵌入:
(
[
a
a
a
]
;
[
b
b
b
]
)
=
[
a
a
a
b
b
b
]
\left(\left[\begin{array}{lll}a & a & a\end{array}\right] ;\left[\begin{array}{lll}b & b & b\end{array}\right]\right)=\left[\begin{array}{llllll}a & a & a & b & b & b\end{array}\right]
([aaa];[bbb])=[aaabbb]
- 过滤器大小为 k = 3 k = 3 k=3的填充一维卷积将能够在连接点周围模拟这两个嵌入之间的相互作用(相互作用的数量与 k k k成正比)。
如果作者将尺寸为
m
×
n
m×n
m×n的两行2D嵌入进行串联(即堆叠),其中
m
=
2
m = 2
m=2和
n
=
3
n = 3
n=3,则将获得以下结果:
(
[
a
a
a
a
a
a
]
;
[
b
b
b
b
b
b
]
)
=
[
a
a
a
a
a
a
b
b
b
b
b
b
]
\left(\left[\begin{array}{lll}a & a & a \\ a & a & a\end{array}\right] ;\left[\begin{array}{lll}b & b & b \\ b & b & b\end{array}\right]\right)=\left[\begin{array}{lll}a & a & a \\ a & a & a \\ b & b & b \\ b & b & b\end{array}\right]
([aaaaaa];[bbbbbb])=⎣⎢⎢⎡aabbaabbaabb⎦⎥⎥⎤
- 过滤器大小为3×3的填充2D卷积将能够对整个串联线之间的相互作用进行建模(相互作用的数量与n和k成正比)。
作者可以将此原理扩展为交替模式,例如:
[
a
a
a
b
b
b
a
a
a
b
b
b
]
\left[\begin{array}{lll}a & a & a \\ b & b & b \\ a & a & a \\ b & b & b\end{array}\right]
⎣⎢⎢⎡abababababab⎦⎥⎥⎤
- 在这种情况下,二维卷积运算能够建模a和b之间的更多交互(交互数量与m,n和k成比例)。 因此,与1D卷积相比,2D卷积能够提取两个嵌入之间的更多特征交互。
2 模型ConvE
模型结构图
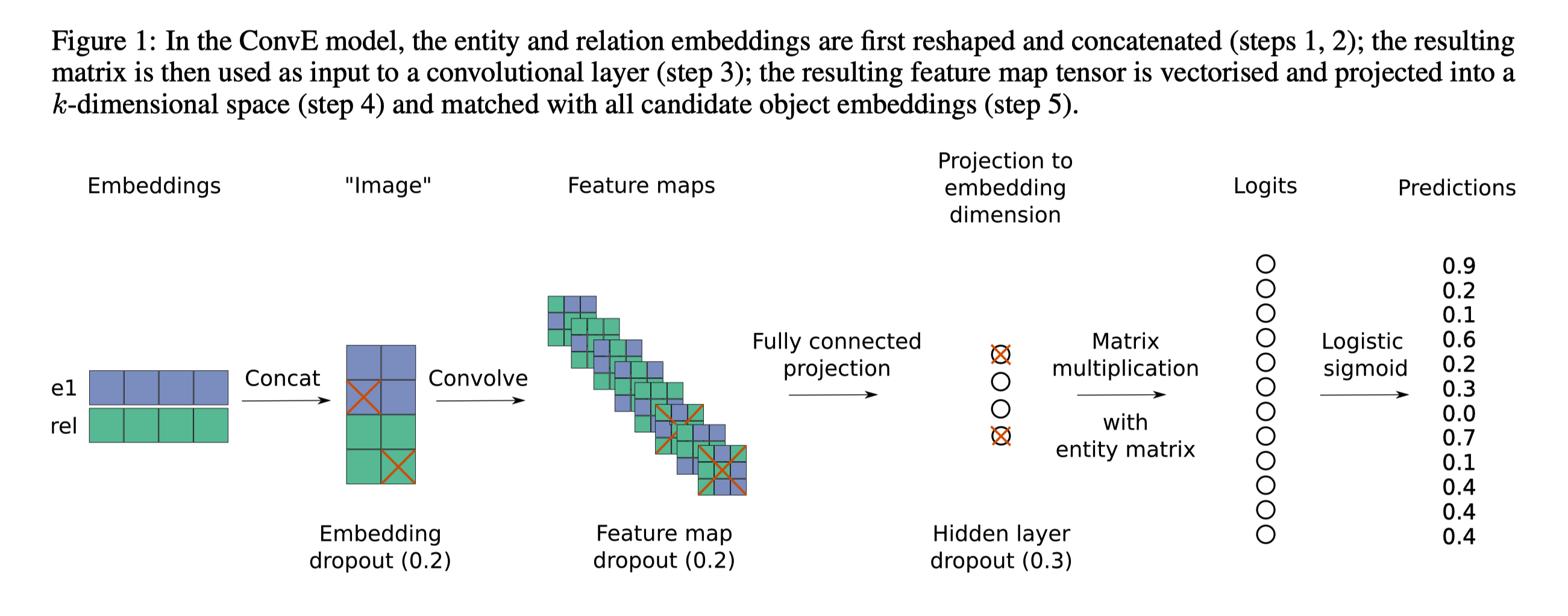
作者模型的主要特征是分数由2D形状嵌入上的卷积定义,数学公式如下所示:
ψ
r
(
e
s
,
e
o
)
=
f
(
vec
(
f
(
[
e
‾
s
;
r
‾
r
]
∗
ω
)
)
W
)
e
o
\psi_{r}\left(\mathbf{e}_{s}, \mathbf{e}_{o}\right)=f\left(\operatorname{vec}\left(f\left(\left[\overline{\mathbf{e}}_{s} ; \overline{\mathbf{r}}_{r}\right] * \omega\right)\right) \mathbf{W}\right) \mathbf{e}_{o}
ψr(es,eo)=f(vec(f([es;rr]∗ω))W)eo
- 其中 r r ∈ R k \mathbf{r}_{r} \in \mathbb{R}^{k} rr∈Rk是一个依赖关系 r r r的关系参数, e s ‾ , r r ‾ \overline{\mathbf{e}_{s}},\overline{\mathbf{r}_{r}} es,rr分别代表 e s \mathrm{e}_{s} es and r r \mathbf{r}_{r} rr的2D重塑:(如果 e s , r r ∈ R k \mathbf{e}_{s}, \mathbf{r}_{r} \in \mathbb{R}^{k} es,rr∈Rk,则 e s ‾ , r r ‾ ∈ R k w × k h \overline{\mathbf{e}_{s}}, \overline{\mathbf{r}_{r}} \in \mathbb{R}^{k_{w} \times k_{h}} es,rr∈Rkw×kh,其中 k = k w k h k=k_{w} k_{h} k=kwkh
整个ConvE的模型流程如下:
- 在前馈过程中,模型对两个嵌入矩阵执行行矢量查找操作,其中一个用于实体,表示为 E ∣ E ∣ × k \mathbf{E}|\mathcal{E}| \times k E∣E∣×k,另一用于关系式,表示为 R ∣ R ∣ × k ′ \mathbf{R}^{|\mathcal{R}| \times k^{\prime}} R∣R∣×k′。其中 k k k和 k ′ k^{\prime} k′是实体和关系嵌入维度, ∣ E ∣ |\mathcal{E}| ∣E∣ and ∣ R ∣ |\mathcal{R}| ∣R∣代表实体和关系的数量。
- 然后,模型将 e s ‾ \overline{\mathbf{e}_{s}} es and r r ‾ \overline{\mathbf{r}_{r}} rr进行串联,并将其用作带有滤波器 ω \omega ω的2D卷积层的输入。这样一层返回一个特征图张量 T ∈ R c × m × n \mathcal{T} \in \mathbb{R}^{c \times m \times n} T∈Rc×m×n,其中 c c c是维数为 m m m和 n n n的特征图的数量。
- 再将张量 T \mathcal{T} T整形为一个向量 vec ( T ) ∈ R c m n \operatorname{vec}(\mathcal{T}) \in \mathbb{R}^{c m n} vec(T)∈Rcmn
- 然后使用矩阵 W ∈ R c m n × k \mathbf{W} \in \mathbb{R}^{c m n \times k} W∈Rcmn×k设置的线性变化将其投影到 k k k维空间中,并通过内积与嵌入 e o e_o eo的对象匹配。
- 卷积滤波器和矩阵 W W W的参数与实体 s s s和 o o o以及关系 r r r的参数无关。
作者用一个非线性函数sigmoid来计算得分:
p
=
σ
(
ψ
r
(
e
s
,
e
o
)
)
p = \sigma\left(\psi_{r}\left(\mathbf{e}_{s}, \mathbf{e}_{o}\right)\right)
p=σ(ψr(es,eo))
最终的损失函数为:
L
(
p
,
t
)
=
−
1
N
∑
i
(
t
i
⋅
log
(
p
i
)
+
(
1
−
t
i
)
⋅
log
(
1
−
p
i
)
)
\mathcal{L}(p, t)=-\frac{1}{N} \sum_{i}\left(t_{i} \cdot \log \left(p_{i}\right)+\left(1-t_{i}\right) \cdot \log \left(1-p_{i}\right)\right)
L(p,t)=−N1i∑(ti⋅log(pi)+(1−ti)⋅log(1−pi))
- 其中对于1-1的分数 t t t是维度为 R 1 x 1 \mathbb{R}^{1 x 1} R1x1的标签向量,对于1-N分数来说是 R 1 x N \mathbb{R}^{1 x N} R1xN向量。当关系存在是 t = 1 t=1 t=1否则, t = 0 t=0 t=0
模型的空间复杂度

3 实验
3.1 数据集
WN18, FB15K,YAGO3-10,Countires
作者证明了FB15k和WN18存在test leakage through inverse relations的问题:简单地通过反转训练集中的三元组就可以获得大量的测试三元组。
所以作者使用了FB15K-237和WN18RR,并且建议以后不要使用FB15K和WN18.
3.2 实验结果
3.2.1 参数效率
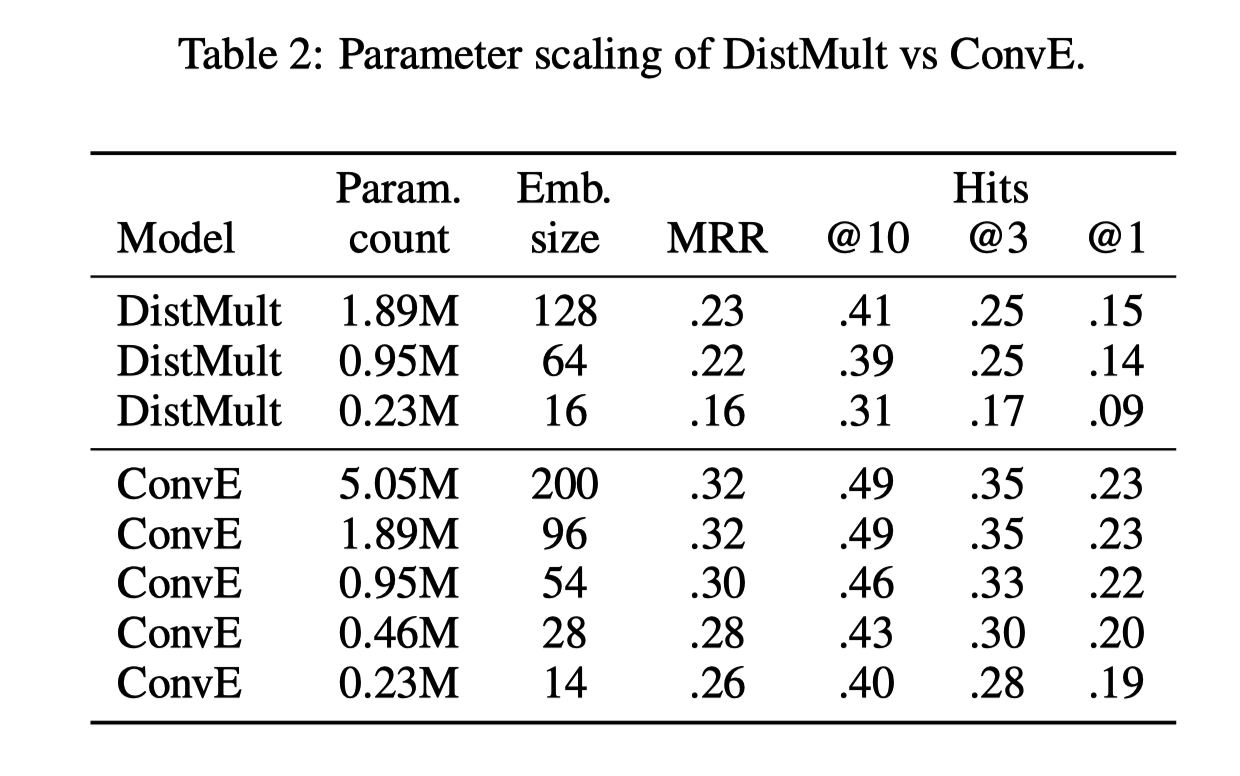
- 对比参数规模和实验结果,发现ConvE模型可以在使用较少参数的时候达到较好的实验效果。
3.2.2 链接预测结果
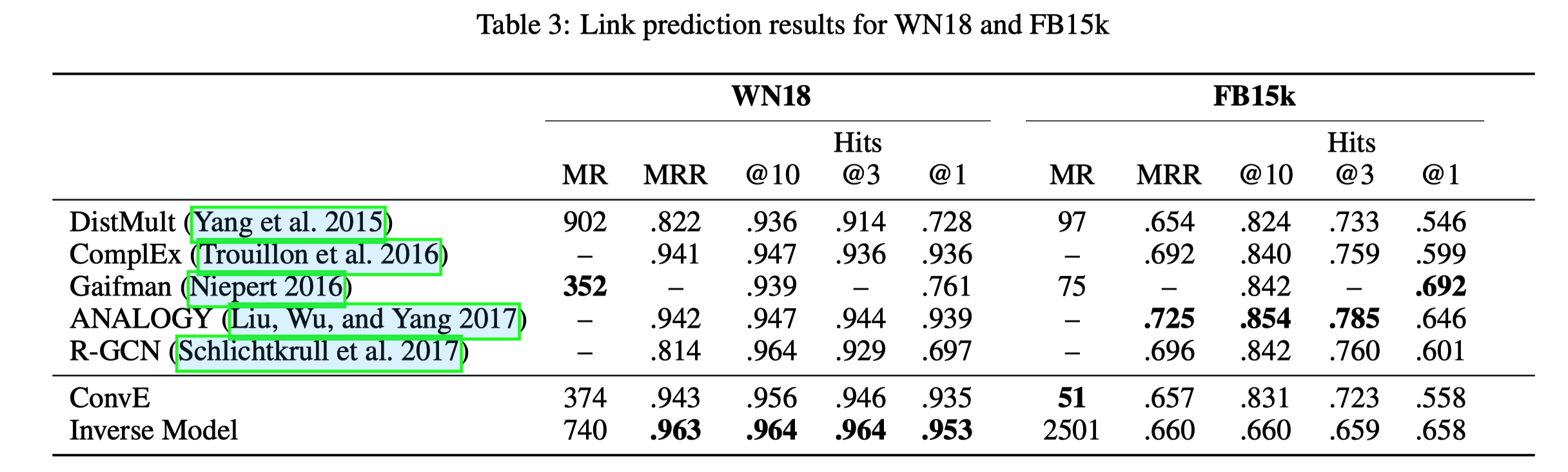
- 链接预测任务上各种模型的表现,ConvE模型在各个性能指标上都取得了很好的效果。
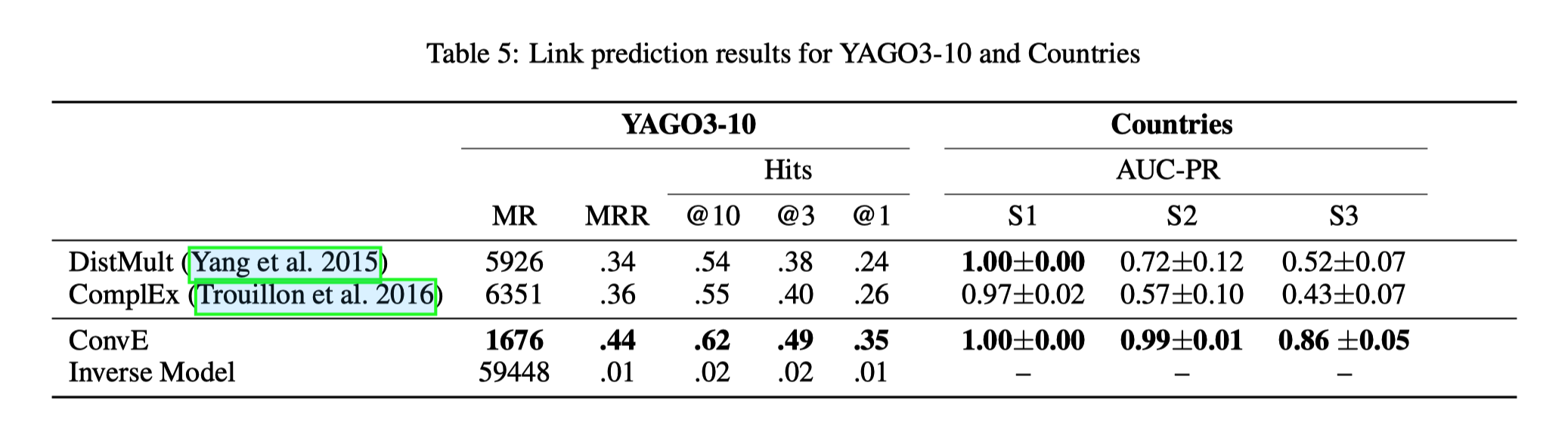
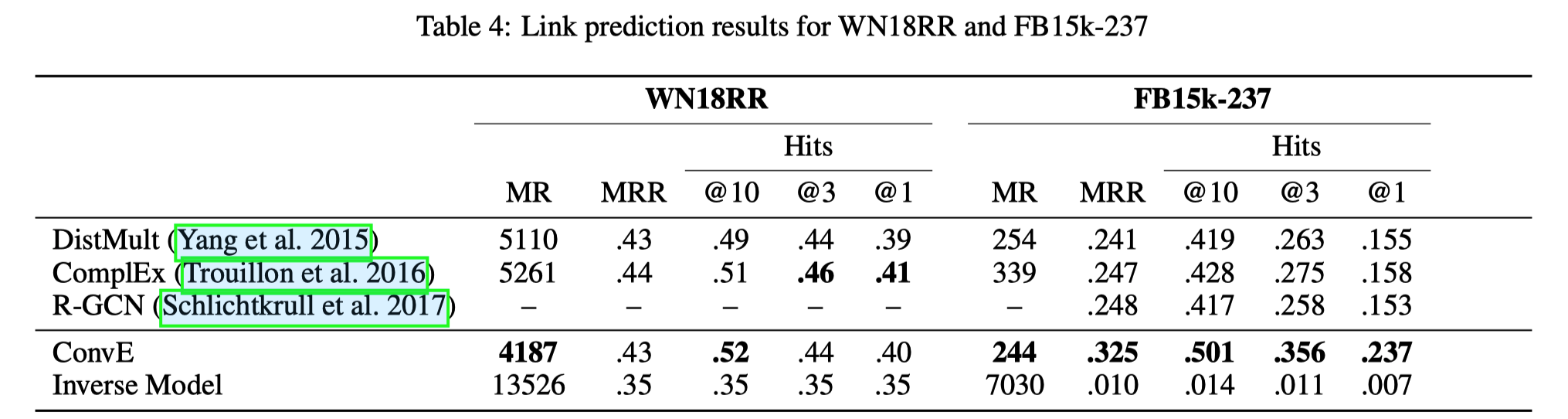
- Table 4是将逆关系去掉之后的各个模型在数据集上的表现,逆模型法处理YAGO310和FB15k-237的逆关系
- Toutanova和Chen(2015)用来推导FB15k-237的过程并未消除某些对称关系,例如“类似于”。 这些关系的存在解释了作者在WN18RR上的逆模型的良好评分,该评分是使用相同的过程得出的。
3.2.3 自反模型(inverse Model)
有统计数据指出在数据集WN18 和FB15K中,训练集中有94% 和81% 中三元组的逆关系在测试集中出现,可能会导致在数据集上表现的好,却只学习了某关系是其他的逆关系,而不是真正的知识图谱。
为了衡量此问题的严重性,作者构建了一个简单的基于规则的模型,该模型仅对逆关系建模。作者将此模型称为逆模型。该模型自动从训练集中提取逆关系:给定两个关系对 r 1 , r 2 ∈ R r_{1}, r_{2} \in \mathcal{R} r1,r2∈R,作者检查 ( s , r 1 , o ) \left(s, r_{1}, o\right) (s,r1,o)是否隐含 ( o , r 2 , s ) \left(o, r_{2}, s\right) (o,r2,s),反之亦然。
作者假设逆关系在训练,验证和测试集之间随机分布,因此,作者期望逆关系的数量与训练集的大小(与总数据集大小相比)成比例。因此,如果 ( S , r 1 , O ) \left(\mathcal{S}, \boldsymbol{r}_{1}, \boldsymbol{O}\right) (S,r1,O)的存在与 ( o , r 2 , s ) \left(o, r_{2}, s\right) (o,r2,s)的存在以至少 0.99 − ( f v + f t ) 0.99-\left(f_{v}+f_{t}\right) 0.99−(fv+ft)的频率同时出现,则作者检测到逆关系。 f v , f t f_{v},f_{t} fv,ft是验证和测试集相对于数据集总大小的分数。假定符合此标准的关系是彼此相反的。
在测试时,作者检查测试三元组是否在测试集之外具有逆匹配项:如果找到k个匹配项,则对这些匹配项的前k个排名进行抽样;如果找不到匹配项,则为测试三元组选择一个随机排名。
3.2.3 Indegree和PageRank分析
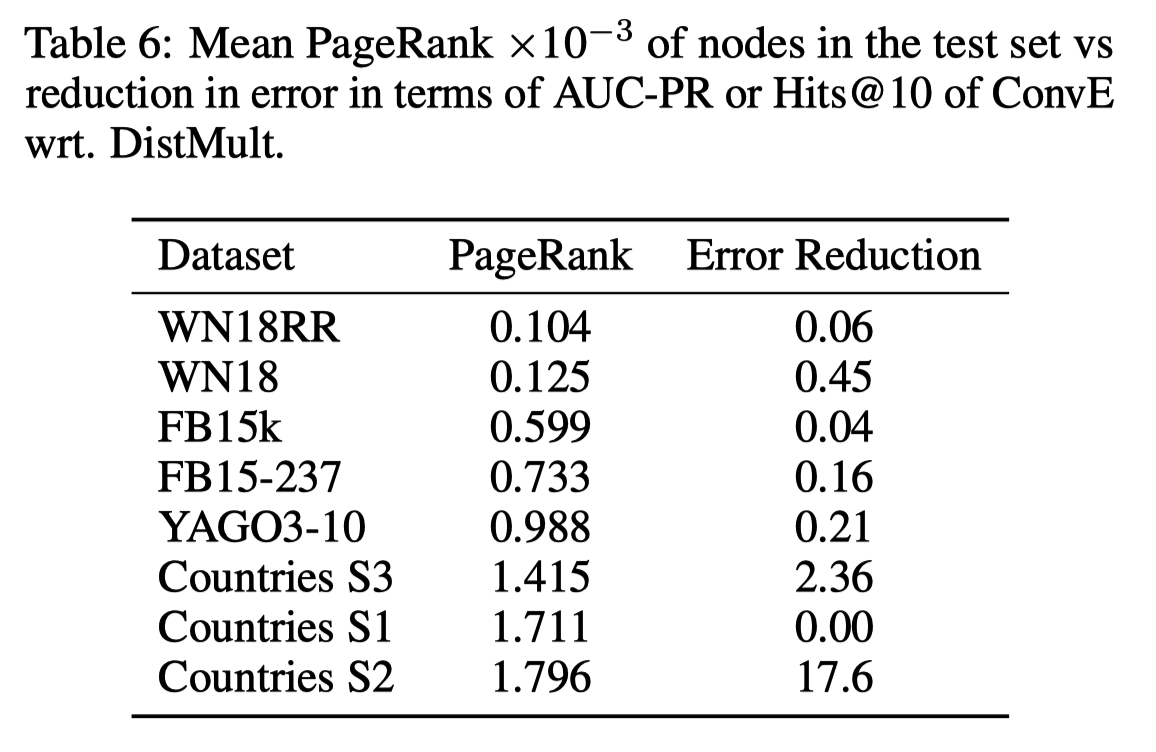
对于indegree,作者通过构建不同indegree的数据集发现:较深的模型(例如ConvE)具有对较复杂的图形进行建模的优势(例如FB15k和FB15k-237),而较浅的模型(例如DistMult)具有对较复杂的图形进行建模的优势(例如WN18 WN18RR)。
PageRank,它是节点中心性的度量。 PageRank也可以看作是节点的递归度的度量:节点的PageRank值与该节点的度数,其邻居度数,其邻居-邻居度数等相对于网络中所有其他节点成比例。
与标准链接预测变量DistMult相比,我们模型的性能提高可以部分解释,这是因为我们能够以较高的度数对节点进行高精度建模,这可能与其深度有关。















 5338
5338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









