




 文章介绍了推荐系统的基本概念,如通过用户评分预测电影喜好,协同过滤算法的学习和预测过程,以及二进制标签在逻辑回归中的应用。此外,还讨论了数据预处理中的均值归一化,以及如何使用TensorFlow实现协同过滤。文章进一步对比了协同过滤与基于内容的过滤,提出了基于内容过滤的深度学习方法,并探讨了推荐系统在大型目录中的应用优化和伦理问题。
文章介绍了推荐系统的基本概念,如通过用户评分预测电影喜好,协同过滤算法的学习和预测过程,以及二进制标签在逻辑回归中的应用。此外,还讨论了数据预处理中的均值归一化,以及如何使用TensorFlow实现协同过滤。文章进一步对比了协同过滤与基于内容的过滤,提出了基于内容过滤的深度学习方法,并探讨了推荐系统在大型目录中的应用优化和伦理问题。
2022吴恩达机器学习课程学习笔记(第三课第二周)
推荐系统
1-1 提出建议
推荐系统在学术界和商业领域都有着巨大的影响力。
以电影为例介绍推荐系统:一组用户和一组电影,每个用户对看过的电影进行评分(0-5),没看过的电影用 ?表示,可通过查看用户未看过的电影并尝试预测用户对电影的评分,这样就可以想用户推荐预测评分高的电影。

也可以使用电影的额外信息,比如分类(动作片、爱情片等)用于推荐系统的开发。
1-2 使用每个特征
我们将电影的分类数据纳入特征,
x
1
x_1
x1,
x
2
x_2
x2 表示该电影
i
i
i 在多大程度上是爱情片或者动作片,并组合为二维向量的表示方式
x
(
i
)
x^{(i)}
x(i) 。
用已知数据对每个用户拟合不同的线性回归模型。
w
(
j
)
⋅
x
(
i
)
+
b
j
w^{(j)}\cdot x^{(i)}+b^j
w(j)⋅x(i)+bj
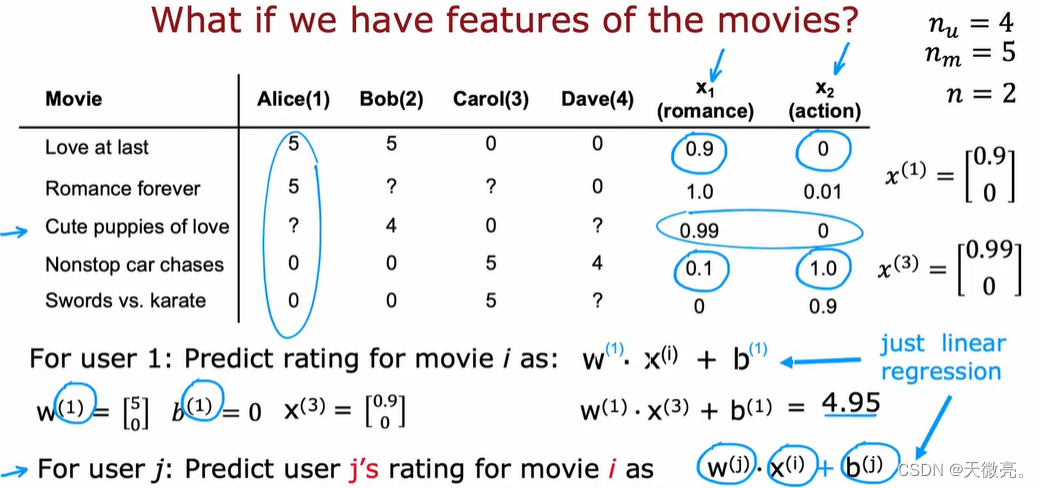
与线性回归类似,通过损失函数来拟合参数w和b,每次只关注一个用户。

由于
m
(
j
)
m^{(j)}
m(j) 是常数,为了简化计算可以省略。
建立单个用户的预测模型是不够的,需要建立系统所有用户的预测模型,按照以下损失函数进行拟合,使整体模型适合系统中的每一个用户。
矩阵运算可以加快计算速度。

1-3 协同过滤算法
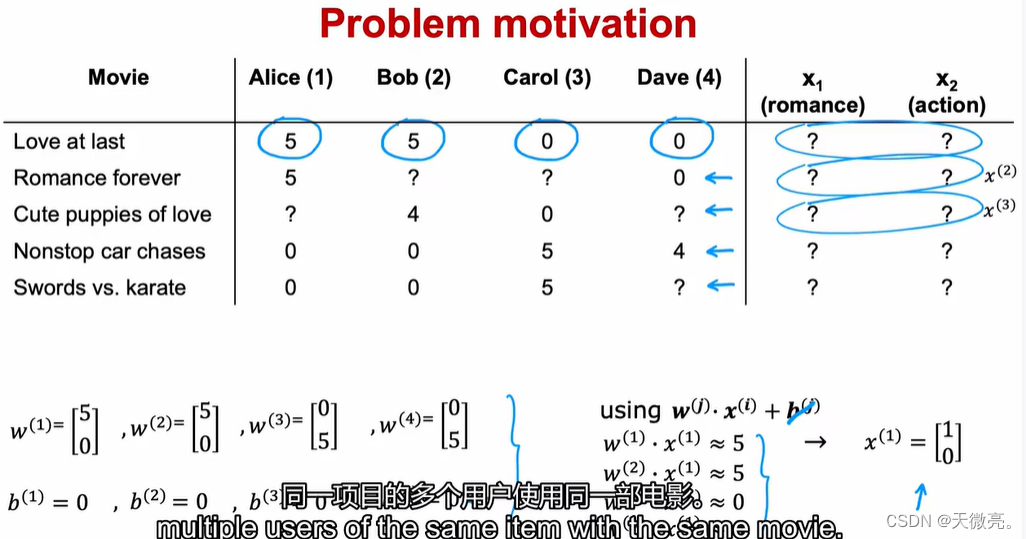
与上节不同,假如我们没有额外特征,比如不知道每部电影的爱情指数以及每部电影的动作指数。
但是我们尝试从多个用户对电影的评分中推测每部电影的爱情指数以及每部电影的动作指数(学习特征)。
省略参数b以简化线性回归,推测
x
(
1
)
x^{(1)}
x(1)可能值,并根据上下文的一些信息做出更可靠的猜测。
同理,推测下一部电影的特征,只有样本量足够的时候才能使用线性回归进行预测特征的信息,即当每一行的评分都完整时。
预测特征之后,使用特征进一步预测用户的评分。
要预测特征,需要像平常一样最小化损失函数。
我们通过用户的评分共同学习特征,又通过电影特征推测用户的评分…
但实际上,存在一个更有效率地算法,可以让我们不再需要这样不停地计算 x 和 θ,而是能够将 x 和 θ 同时计算出来,即同时学习w, b, x 的整体损失函数。
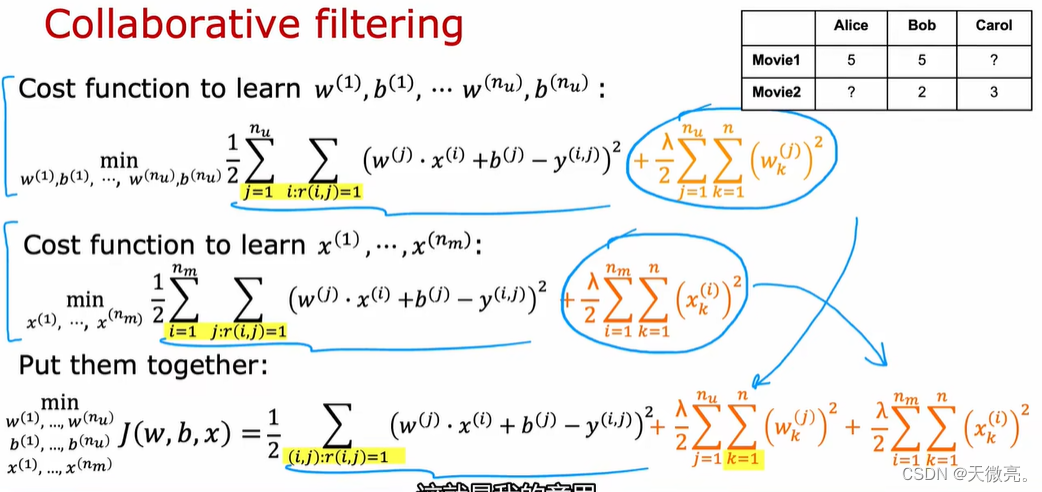
更新参数的方式变化:
注意:x也是一个变量/参数。

x
k
(
i
)
x^{(i)}_k
xk(i)是特征的向量化表示,表示第i个电影的第k个特征。
既通过用户的评分共同学习特征(可以认为用户之间是协作的),反过来又通过电影特征推测其他用户的评分,这就是协同过滤的思想。
1-4 二进制标签
很多推荐算法都会涉及二进制标签,即以某种方式告诉我们它喜欢或不喜欢这部电影,而不是0-5范围内的评分。
本节我们将算法从心性回归推广到逻辑回归,再做预测。
这里图中不再记录评分,而是喜欢1或不喜欢0,为1时,可以是用户明确点击了喜欢选项,也可能是从电影开头到结尾完整地看完了电影,否则为0。没有看过的电影用?表示。(0、1、?的定义不唯一)。接下来我们预测用户对电影的喜好程度。
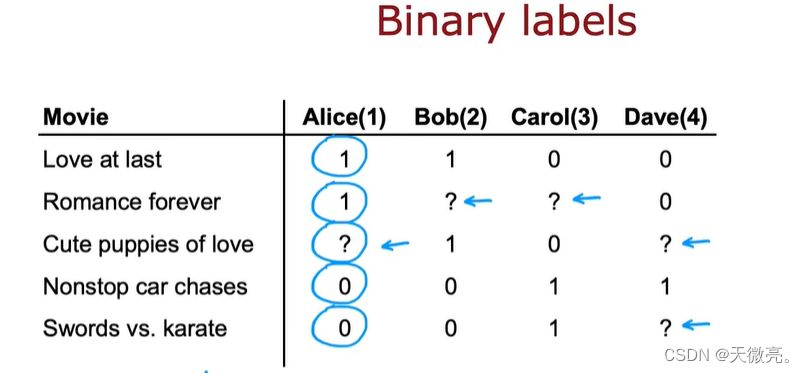
0、1、?的定义举例:

推广到逻辑回归:

g(z)是逻辑函数。
还需要根据平方误差学习参数,损失函数是对所有(i,j)的整体损失函数 。

2-1 均值归一化
数据归一化就是将所有的数据映射到同一尺度,即让每一个特征数据的影响力是相同的。
如下,若用户Eve(5)没有对任何电影评过分,在训练模型时,它只影响损失函数的中间项,要最大程度地减少损失,则
w
(
5
)
=
0
w^{(5)} = 0
w(5)=0,在对Eve做评分预测时,会导致七对每个电影的评分都相同(b=0时所有评分都为0),这无法选择推荐哪些电影。
将评分写成矩阵形式。

我们首先需要对评分做均值归一化处理,将每一个用户对某一部电影的评分减去所有用户对该电影的平均值。
然后用新的评分来训练算法。
预测评分时,需要将平均值重新加回去。
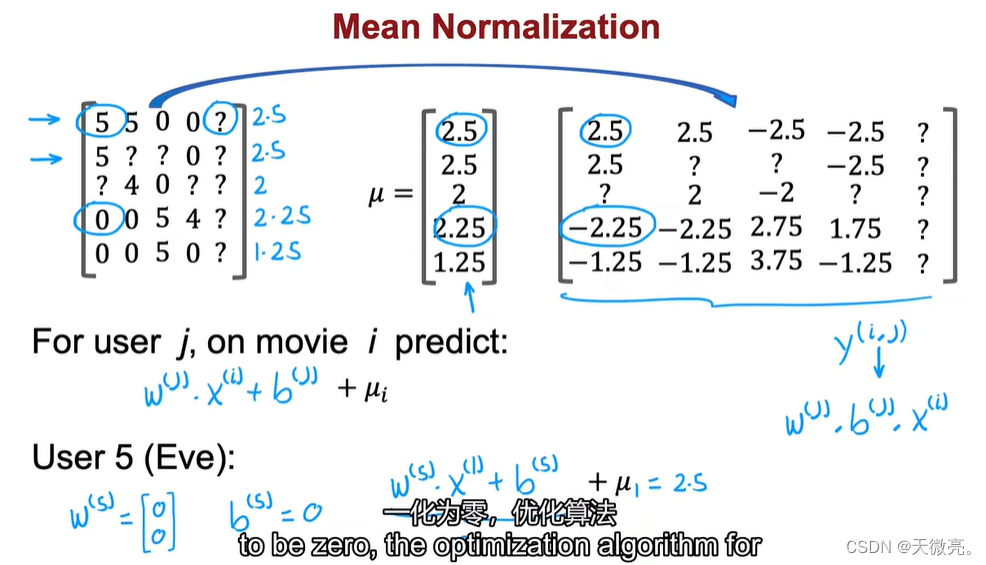
这样做不会因为用户没有评过分而将所有电影预测为0分,实际上,他预测的结果恰巧是某电影已知评分的平均值,此时可以选择分数较高的电影推荐给用户。
均值归一化好处是,可以使算法运行得更快,更重要的是,对没进行过任何评价的用户,它预测结果更加合理。
另外,还可以将评分矩阵的每一列进行均值归一化,结果是将用户所有打分中平均分作为一部未经评价过的电影的预测分数。但是其意义不大,在实际的推荐系统中,比起关心这种没被评价过的电影,关注这些没进行过任何评价的用户来得更重要一些。
2-2 协同过滤TensorFlow实现
对很多模型来说,计算损失函数的的导数是非常重要且比较困难的,而TensorFlow可以自动求出所需要的导数,我们只需要告诉TensorFlow损失函数的计算公式。

自动求出的导数在运算时,需要使用特殊的函数assign_add()。
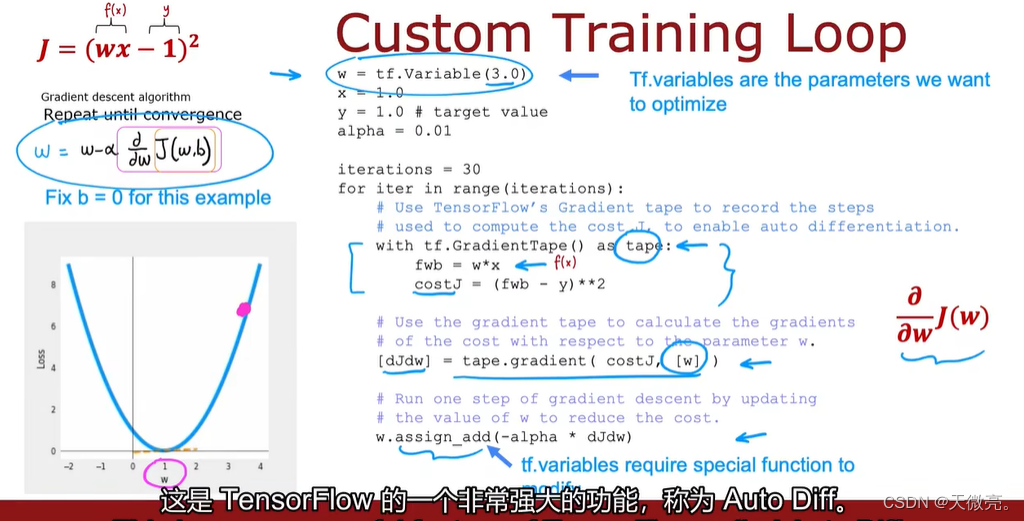
自动求导,是TensorFlow的一个非常强大的功能。称为Auto-DIff。
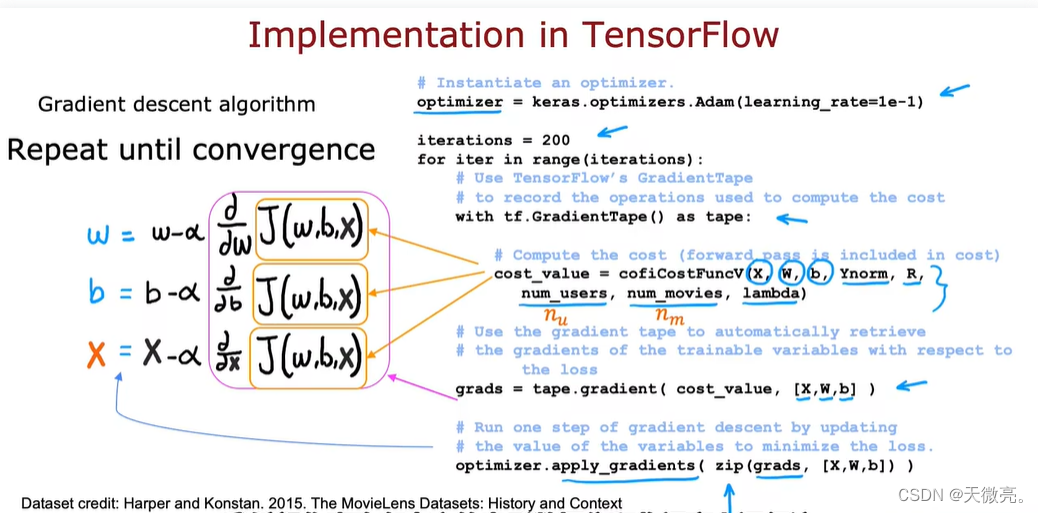
实际上,我们在训练模型时,会用更高级的优化方法,比如Adam优化器,如下。
2-3 寻找相关特征
当我们在看一部特定的电影时,网页会展示相似的电影给我们,做到这一点的关键是:寻找相关特征。
我们知道,预测物品的特征是非常困难的。
我们可以寻找与当前物品 特征相似 的其他物品,通过平方距离来计算。

这是构建更强的推荐系统的关键一步。
协同过滤推荐算法也有缺点:
- 冷启动问题。
- 边信息也可以用来推测用户的偏好及电影的特征,而不是仅仅使用评分。

3-1 协同过滤与基于内容过滤对比
咋本节中,我们学习第二种重要的协同过滤推荐算法:基于内容的过滤算法。

与协同过滤相比,基于内容的过滤,更偏向于使用用户画像和物品描述(特征)来向用户推荐潜在的相似的物品。
可以使用的特征如下,我们分别为用户和物品构建一个特征向量,两个向量的大小可能相差很大。
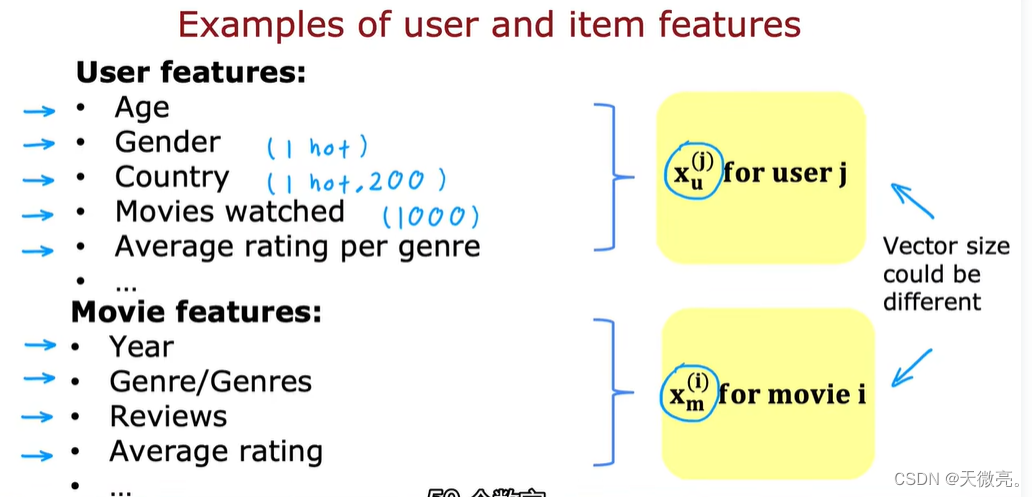
使用我们获取到的特征对可能的用户和物品进行匹配:
首先,我们需要根据收集到的原始信息,构建两个向量用于实际的计算,即从用户特征
x
v
(
j
)
x^{(j)}_v
xv(j)中提取向量
v
u
(
j
)
v^{(j)}_u
vu(j),从项目特征
x
m
(
i
)
x^{(i)}_m
xm(i)中提取
v
m
(
i
)
v^{(i)}_m
vm(i)。
进行预测时,计算匹配程度的方式是在用户偏好和物品特征之间取点积。
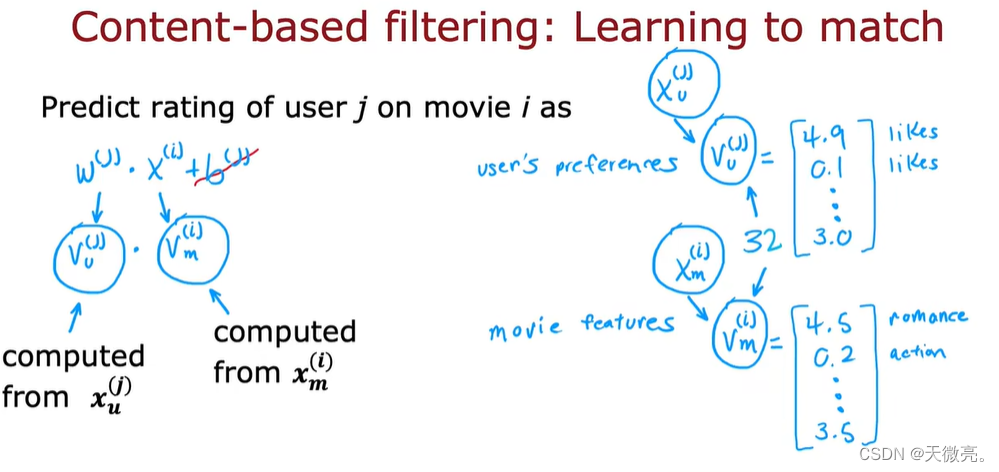
总之,基于内容的过滤算法是根据一系列用户和项目信息,找到一种好的匹配。
3-2 基于内容过滤的深度学习方法
用深度学习的方式实现基于内容的过滤算法是一种很好的方法。
从用户特征
x
v
(
j
)
x^{(j)}_v
xv(j)中提取向量
v
u
(
j
)
v^{(j)}_u
vu(j),我们需要构建一个神经网络,叫做用户网络。
从项目特征
x
m
(
i
)
x^{(i)}_m
xm(i)中提取向量
v
m
(
i
)
v^{(i)}_m
vm(i),我们需要构建一个神经网络,叫做项目网络。
他们的输出是相同的大小。
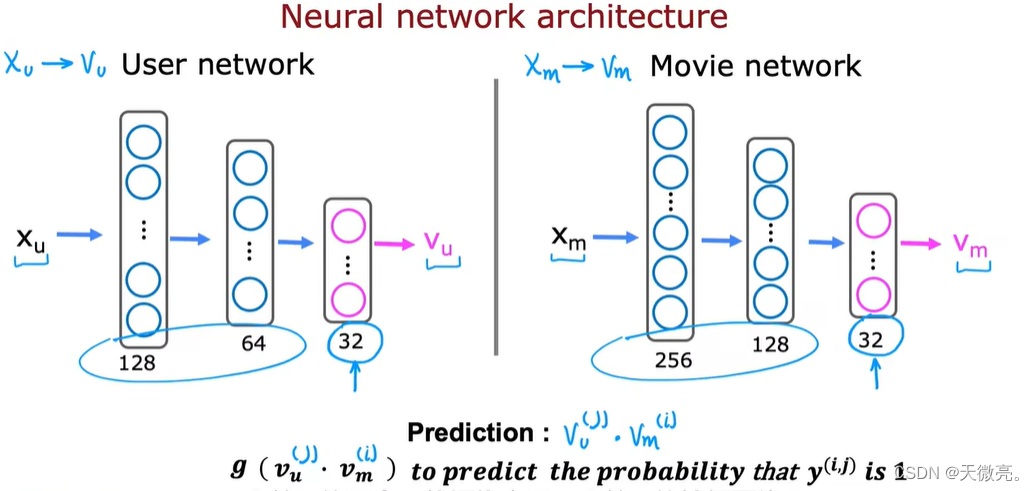
可以将两个网络组合到一起同时训练,将两个输出做点积运算,作为最后的预测结果。
神经网络中有很多需要训练的参数,也就需要使用损失函数,然后用梯度下降或其他优化算法来调整参数使损失函数最小。损失函数可以添加网络正则化项来防止过拟合。
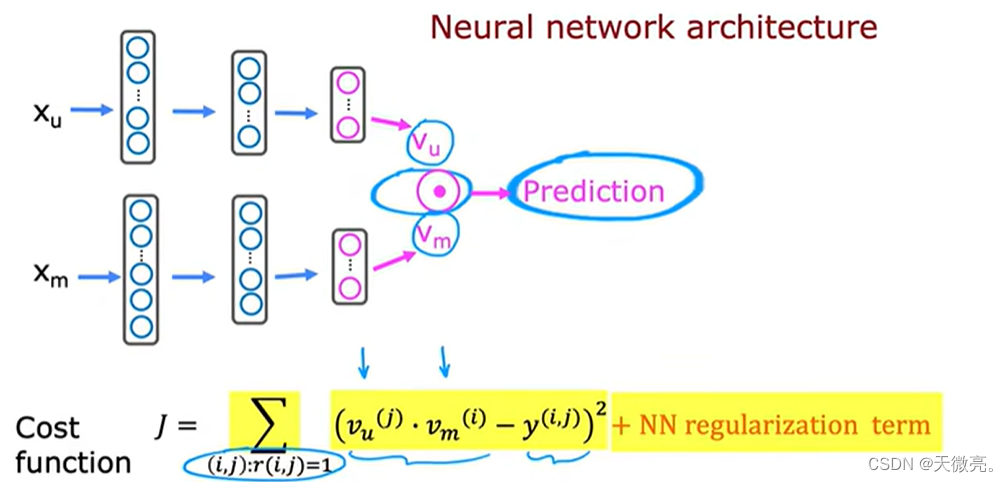
通过以上思想,我们也可以计算项目之间的相似度:即两个项目的特征向量之间的点积。

在实际应用中,我们可以在前一个夜晚预先爬取大量电影的信息并预测他们的相似度,在第二天用户浏览某电影时,将最相似的一些电影推荐给用户。
3-3 从大型目录中推荐
从数干万甚至更多的目录中挑选少数物品进行推荐。
运行一次以下推荐的代价非常大,如果有1000w个项目中做出推荐,需要运行1000w次以下的神经网络。所以如何提高推荐效率呢?
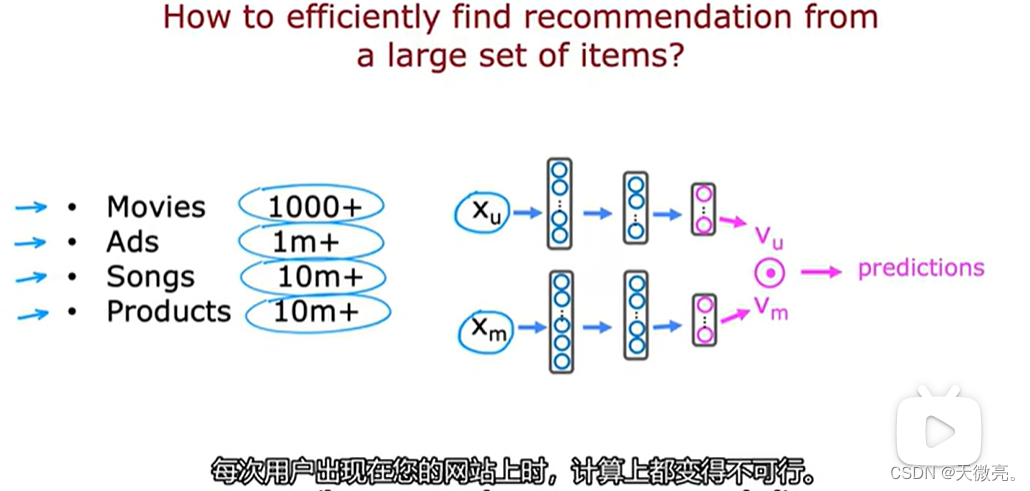
检索步骤中,可以在与用户最近观看的10部电影中各找出10部最相似的电影,作为需要推荐的候选电影列表;也可以在用户最常看的体裁中各选择最受欢迎的10部电影;也可以根据用户地区选择当地最受欢迎的20部电影。
因此,检索步骤可以很快的完成,我们可以获得数百个电影列表。
接下来,需要删除用户不喜欢或看过的的电影,,在这个列表中进行进一步选择会更加高效。
排名步骤中,在教唆的列表中训练模型。根据匹配度的大小排序展示给用户。
若提前完成了从
x
m
(
i
)
x^{(i)}_m
xm(i)中提取向量
v
m
(
i
)
v^{(i)}_m
vm(i)的过程,则在排名步骤中只需要提取向量
v
u
(
j
)
v^{(j)}_u
vu(j)并计算点积,排序推荐即可。这会进一步加快推荐速度。
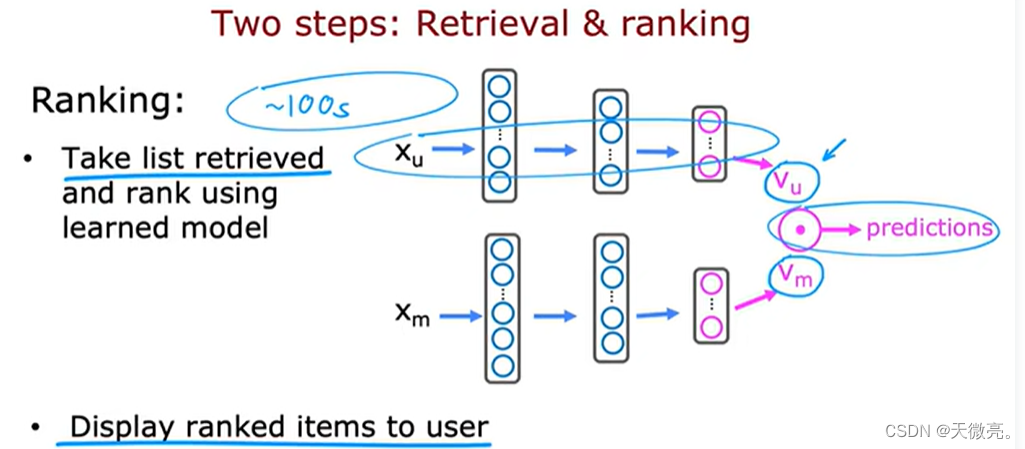
下面讨论如何选择检索列表的大小。
- 检索更多的条目可以获得更好的性能,但推荐速度更慢。
- 为了分析/优化交易,进行离线实验,看看检索额外的项目是否会带来更多的相关推荐。
3-4 推荐系统中的伦理
如果使用不当,推荐系统可能会成为有害业务的放大器。
当构建推荐系统时,不仅要考虑利益问题,也要关注其是否有负面影响。
3-5 基于内容过滤的TensorFlow实现
介绍几个可能使用到的关键技术。
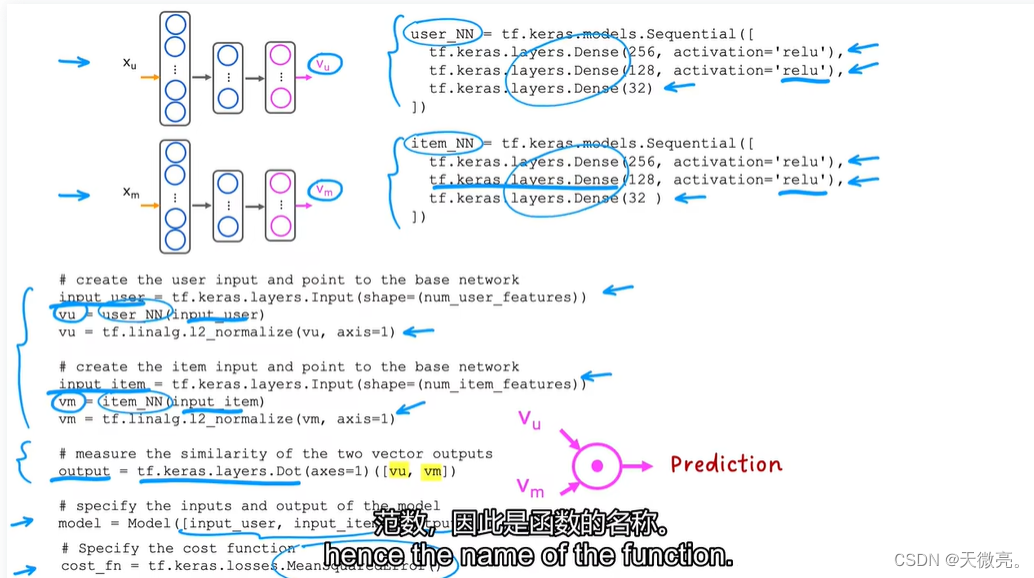
课后在实验中体会代码含义!

















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









