







2022吴恩达机器学习课程学习笔记(第三课第三周)
强化学习
1-1 什么是强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
在强化学习框架中,我们将只提供我们的算法一个奖励函数**,它指示学习代理何时做得好,当它做得不好。然后,学习算法的工作将是找出如何随时间选择行动,从而获得巨大的奖励。
强化学习系统一般包括四个要素:策略(policy),奖励(reward),价值(value)以及环境或者说是模型(model)。**
强化学习不需要我们打标签,不需要给出y的值,而是让机器自己学习什么是对的。所以需要一个奖励函数来告诉它怎么做是对的,怎么做是错的,激励其自动学习对的动作。
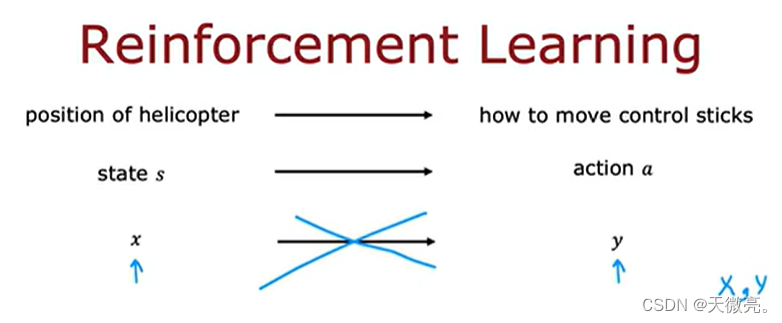
如以下直升机,我们也不知道应该怎么让它飞,所以只能让他自己学习。

实践证明,直升机通过自己学习,不仅可以正着飞,还可以倒着飞。
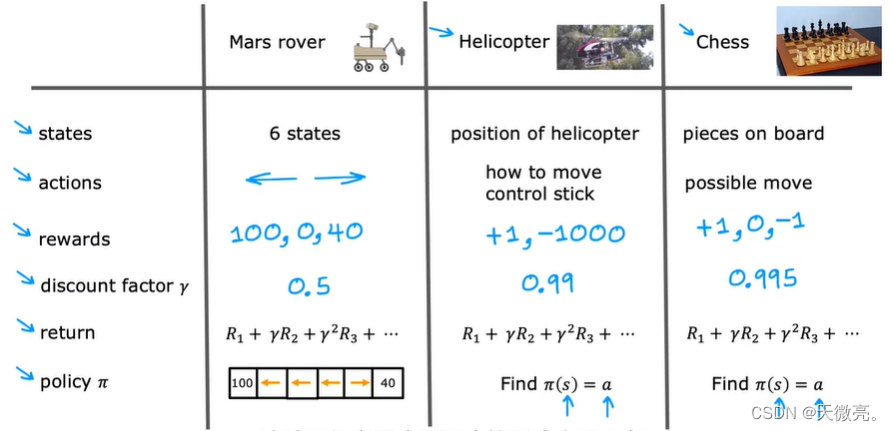
1-2 示例:火星探测器
受火星探测器的启发,通过对其代码的简化来理解强化学习。
火星探测器的位置在强化学习中称为状态。
探测器初始位于状态4,现在探测器被送往火星去执行不同的科学任务,它可以去往不同的流动站去使用它的传感器,例如钻头、雷达或光谱仪去分析不同地方的岩石,或拍些又去的照片给地球上的科学家看。
现在位置1有一个很有趣的表面,科学家想让探测器进行采样。位置6也有一个有趣的表面,科学家们想对其采样,但重要程度不如位置1。所以我们更希望探测器执行位置1的任务,但是位置1距离比较远,我们反应状态1更有价值的方式是通过奖励函数。状态1的奖励是100,而状态6的奖励是40,其他状态的奖励为0。每一步探测器可以往左走或者往右走。
从一个状态出发,采取一定的动作,到达新的状态,可以获得奖励。

1-3 强化学习的回报
折扣因子γ:一般是一个非常接近1的数值。

1-4 决策:强化学习中的策略
策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。因此我们可以知道策略是强化学习系统的核心,因为我们完全可以通过策略来确定每个状态下的行为。我们将策略的特点总结为以下三点:
- 策略定义智能体的行为
- 它是从状态到行为的映射
- 策略本身可以是具体的映射也可以是随机的分布
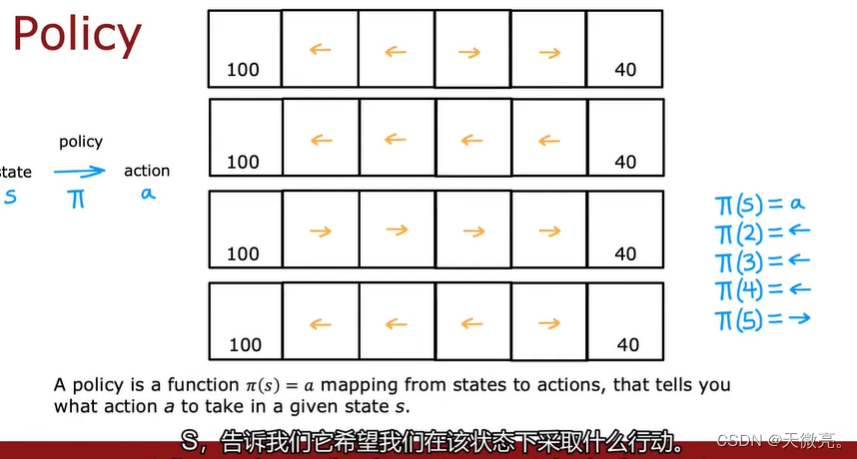
找到一个策略π,它告诉您在每个状态下要采取什么操作(a=π(s)),以使奖励最大化。

1-5 审查关键概念
马尔可夫决策过程(MDP)
未来处于什么状态,至于现在的状态有关,与过去的状态无关。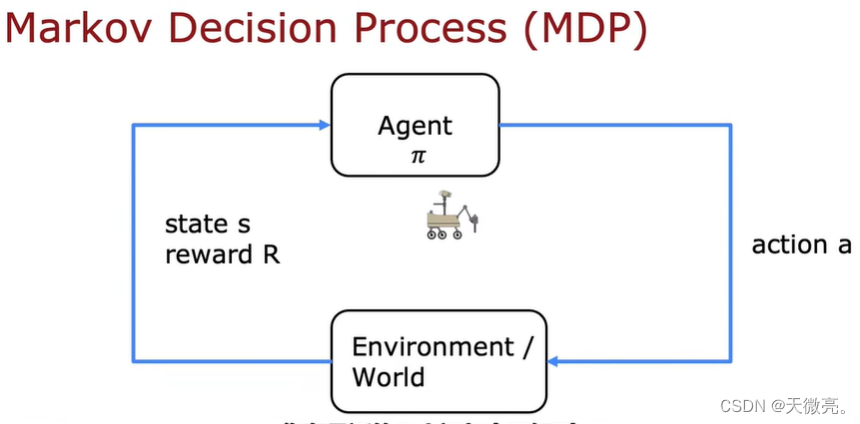
2-1 状态-动作价值函数定义
状态-动作价值函数即Q函数, 计算某个状态上采取某行动,之后一直按照最佳(已知)的策略行动,最终获得的奖励。

以上举出了三个计算示例:
- 从2开始,计算Q(2,→),行动轨迹为:2→3→2→1。
- Q(2,←),行动轨迹为:2←1.
- Q(4,←),行动轨迹为:4←3←2←1
这为机器人提供了一种选择动作的方法,即采取更大奖励的动作。

2-2 状态-动作价值函数示例
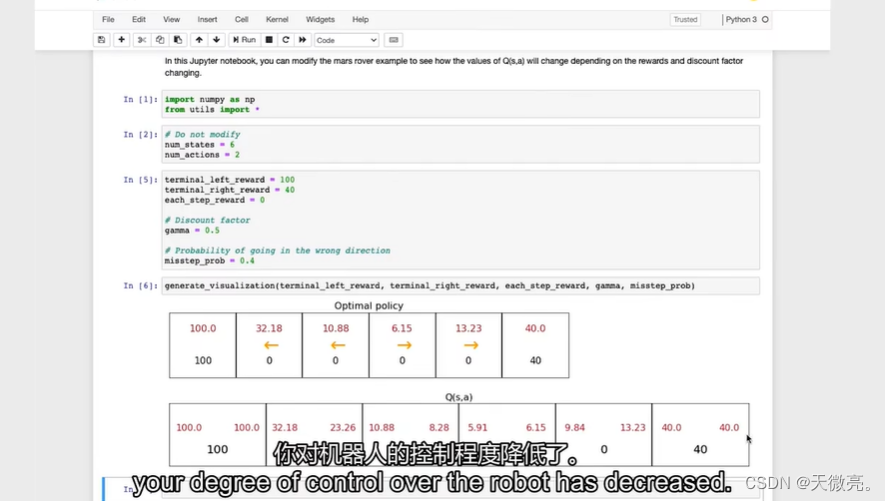
可选实验,修改参数值,体会Q函数如何改变以寻求最佳策略。
2-3 贝尔曼方程
当处于终端状态时,贝尔曼方程只剩下第一项。

贝尔曼方程可以分解为:现在做的事情+将来做的事情,等于当前的奖励+未来的奖励。

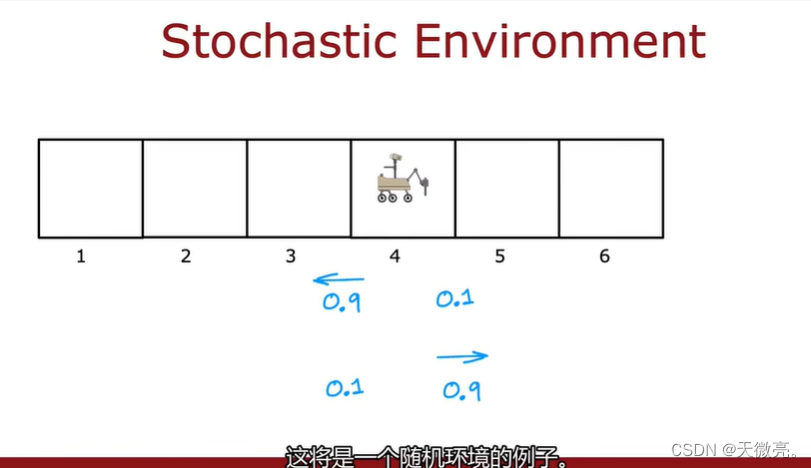
2-4 random·stochastic environment
在随机环境中,我们向探测器发出一个指令,比如向左,但是由于未知环境的原因,可能左边地面很滑,探测器滑到了右边的位置。所以探测器可能不会按照我们的指令行动。所以获得的奖励也是随机的。进行很多次实验,会得到一个随机序列。
此时我们的目标是:获得随机奖励的平均值*,并最大化平均值或期望。
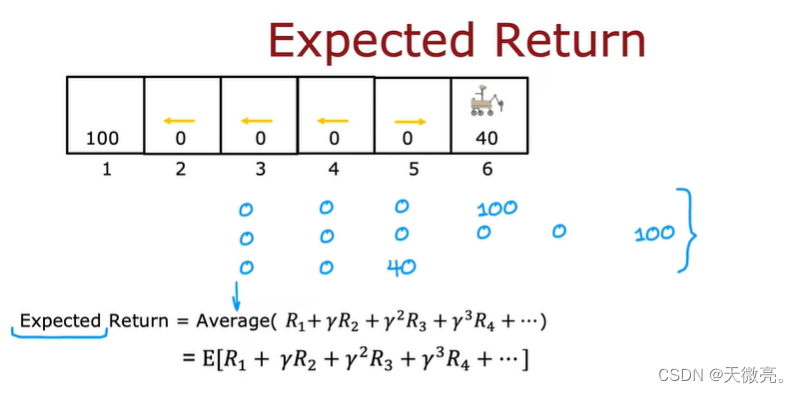
贝尔曼方程中第二项改为期望值**。

在可选实验中,我们可以发现,由于机器人不能完全遵守我们的指令,获得的奖励会下降。
3-1 示例:连续状态空间应用
推广到更大的状态空间和连续状态空间。
举个连续状态空间的例子,卡车可以位于状态空间中的任意一个位置,其状态用一个多维向量来表示,包括x坐标,y坐标,车身角度,轮子转速等。
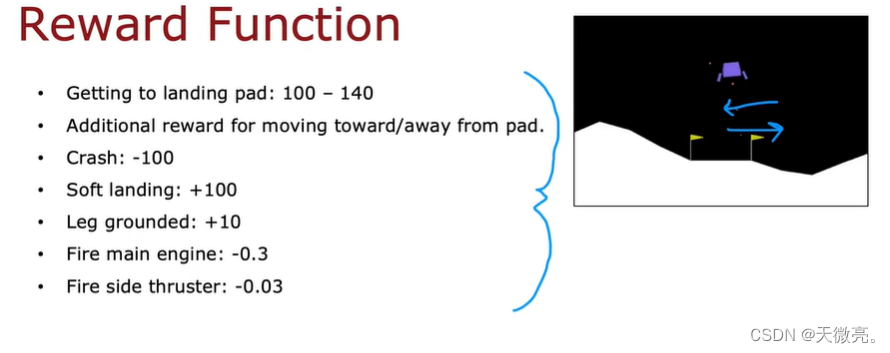
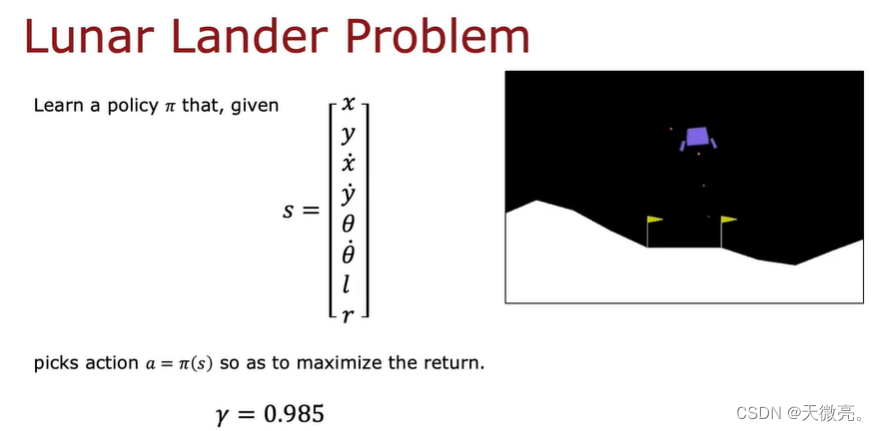
3-2 登月器
着陆器器的任务是在适当的位置上用适当的火力推进其安全降临到陆台上。
奖励函数应该编入我们想要和不想要的情况。
3-3 学习状态价值函数
使用深度学习来实现登月器。
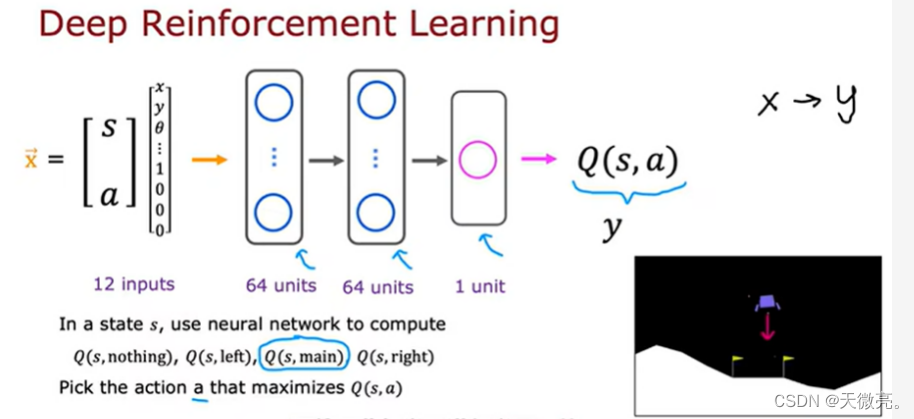
关键思想是:我们要训练一个神经网络,来逼近价值-动作值函数,以此选择更好的行动。
首先,在状态s下,使用神经网络计算Q(s,nothing),q(s,left),q(s,main),q(s,right)。
然后,选择一个最大化奖励Q的动作a。
注:四个可能的动作可用One-hot向量表示。
使用个贝尔曼方程创建训练集,10000个四元组(所有可能的状态下可能的动作和可能到达的状态和奖励)和目标(由贝尔曼方程计算出,其中第二项的maxQ由神经网络最初的随机初始化给出,然后迭代地计算)的奖励。

然后使用监督学习的方法学习X→Y的映射:
随机初始化网络中的参数,运行最近的10000个示例并存储到缓冲区,输入的是四元组,输出的是神经网络给出的价值。经过多轮的训练,使神经网络的输出更加接近由贝尔曼公式计算出(目标)的Q,这会提高对Q函数的猜测。
该算法称为DQN算法(deep-Q-network),因为我们正在使用 Deep Learing 的 Neural Network 来学习Q函数的。

实际上,DQN算法是使用两个网络来学习Q函数的,即目标网络和Q-网络,这在吴恩达老师的课程中没有体现,但是在可选实验中采用了,可以通过试验理解其中的细节。若果本文表述有误,请各位大佬批评指正。
以下是可选实验中对于目标网络的解释:
We can train the
Q
Q
Q-Network by adjusting it’s weights at each iteration to minimize the mean-squared error in the Bellman equation, where the target values are given by:
y = R + γ max a ′ Q ( s ′ , a ′ ; w ) y = R + \gamma \max_{a'}Q(s',a';w) y=R+γa′maxQ(s′,a′;w)
where w w w are the weights of the Q Q Q-Network. This means that we are adjusting the weights w w w at each iteration to minimize the following error:
R + γ max a ′ Q ( s ′ , a ′ ; w ) ⏟ y t a r g e t − Q ( s , a ; w ) ⏞ E r r o r \overbrace{\underbrace{R + \gamma \max_{a'}Q(s',a'; w)}_{\rm {y~target}} - Q(s,a;w)}^{\rm {Error}} y target R+γa′maxQ(s′,a′;w)−Q(s,a;w) Error
Notice that this forms a problem because the
y
y
y target is changing on every iteration. Having a constantly moving target can lead to oscillations and instabilities. To avoid this, we can create
a separate neural network for generating the
y
y
y targets. We call this separate neural network the target
Q
^
\hat Q
Q^-Network and it will have the same architecture as the original
Q
Q
Q-Network. By using the target
Q
^
\hat Q
Q^-Network, the above error becomes:
R + γ max a ′ Q ^ ( s ′ , a ′ ; w − ) ⏟ y t a r g e t − Q ( s , a ; w ) ⏞ E r r o r \overbrace{\underbrace{R + \gamma \max_{a'}\hat{Q}(s',a'; w^-)}_{\rm {y~target}} - Q(s,a;w)}^{\rm {Error}} y target R+γa′maxQ^(s′,a′;w−)−Q(s,a;w) Error
where w − w^- w− and w w w are the weights the target Q ^ \hat Q Q^-Network and Q Q Q-Network, respectively.
In practice, we will use the following algorithm: every C C C time steps we will use the Q ^ \hat Q Q^-Network to generate the y y y targets and update the weights of the target Q ^ \hat Q Q^-Network using the weights of the Q Q Q-Network. We will update the weights w − w^- w− of the the target Q ^ \hat Q Q^-Network using a soft update. This means that we will update the weights w − w^- w− using the following rule:
w − ← τ w + ( 1 − τ ) w − w^-\leftarrow \tau w + (1 - \tau) w^- w−←τw+(1−τ)w−
where τ ≪ 1 \tau\ll 1 τ≪1. By using the soft update, we are ensuring that the target values, y y y, change slowly, which greatly improves the stability of our learning algorithm.
3-4 算法改进:改进的神经网络架构
同时计算当前状态上,采取不同动作获得的价值,提高效率。
3-5 算法改进:ε-贪婪策略
选择采取什么行动时,有1-ε的概率选择回报最大化的动作,称为贪婪。
有ε的概率去采取其他动作,称为探索。
3-6 算法改进:小批量和软更新
小批量技巧不是适用于强化学习,也可用于监督学习,这会提高算法的效率。
软更新技巧可以使算法更好的收敛。
小批量梯度下降:
当训练集很大很大,比如1亿时,使用通常的平方误差梯度下降算法的计算量将会非常大。使用小批量梯度下降的思想是不用再每次迭代中使用1亿个示例,而是选择一个较小的数,如1000,这将花费较少的时间。
但是小批量更新时,损失函数的值是随机变化的,但是最终会趋于最小。
而在之前的梯度下降中,每次更新,损失函数都会向着最快的方向下降。
整体上,小批量梯度下降的时间和成本都是较小的。
软更新:
每次更新时,参数只会增加一点点新值,防止Q朝着更槽糕的方向更新(可能参数改变幅度是很大的),可以使算法更可靠的收敛。
3-7 强化学习的现状
- 在模拟中的难度要比真正的机器人容易得多。
- 比监督和无监督的使用要少很多。
- 但是,具有很多应用潜力和令人激动的研究方向。
3-8 课程总结和致谢
- 监督机器学习:回归与分类
线性回归、Logistic回归、梯度下降 - 高级学习算法
神经网络,决策树,ML建议 - 无监督学习,异常检测,推荐系统,强化学习
聚类,异常检测,协同过滤,基于内容的过滤,强化学习















 38
38











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









