




 本文详细介绍了隐马尔可夫模型(HMM)的基本概念,包括马尔可夫假设、初始状态概率向量、状态转移概率矩阵和发射概率矩阵。HMM主要用于模拟两个时序序列的联合分布,尤其在自然语言处理中,如词性标注。通过三个基本问题——样本生成、模型训练和序列预测,HMM在序列标注任务中发挥关键作用。
本文详细介绍了隐马尔可夫模型(HMM)的基本概念,包括马尔可夫假设、初始状态概率向量、状态转移概率矩阵和发射概率矩阵。HMM主要用于模拟两个时序序列的联合分布,尤其在自然语言处理中,如词性标注。通过三个基本问题——样本生成、模型训练和序列预测,HMM在序列标注任务中发挥关键作用。
隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model, HMM)是描述两个时序序列联合分布 p(x,y) 的概率模型: x x x序列外界可见(外界指的是观测者),成为观测序列(observation sequence); y y y序列外界不可见,称为状态序列(state sequence)。比如观测 x x x为单词,状态 y y y为词性,我们需要根据单词序列去猜测他们的词性。隐马尔可夫模型之所以称为“隐”,是因为从外界来看,状态序列(例如词性)隐藏不可见,是待求的因变量。从这个角度来讲,人们也称状态为隐状态,而称观测为显状态。隐马尔可夫模型之所以称为“马尔可夫模型”,是因为它满足马尔可夫假设。
通俗易懂的解释可以看以下链接:
https://www.cnblogs.com/fulcra/p/11065474.html
1、马尔可夫假设
每个事情的发生概率只取决于前一个事件。将满足该假设的连续多个事件串联在一起,就构成了马尔可夫链。在NLP的语境下,可以将事件具象为单词,于是马尔可夫模型就具象为二元语法模型。
再次基础上,隐马尔可夫模型理解起来就并不复杂了:它的马尔可夫假设作用于状态序列,假设①当前状态 y i y_i yi 仅仅依赖前一个状态 y i − 1 y_{i-1} yi−1 ,连续多个状态构成隐马尔可夫链 y y y。有了隐马尔可夫链,如何与观测序列x建立联系呢?
隐马尔可夫模型做了第二个假设:②任意时刻的观测 x t x_t xt 只依赖与该时刻的状态 y t y_t yt,与其他时刻的状态或观测独立无关。如果用箭头表示事件的依赖关系(箭头终点表示结果,依赖于起点的因缘),则隐马尔可夫模型可以表示为图4-7。
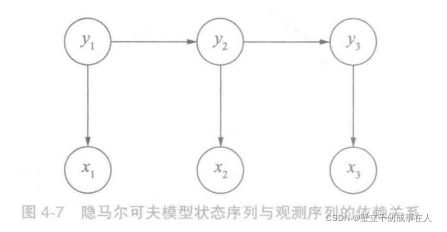
这张图也许有一丝违和感,按通常理解,应当是
x
x
x决定
y
y
y,而不是反过来。这是由于在联合概率分布
p
(
x
,
y
)
p(x,y)
p(x,y)中,两个随机变量并没有固定的先后与因果关系,即
p
(
x
,
y
)
=
p
(
y
,
x
)
p(x,y)=p(y,x)
p(x,y)=p(y,x)。从贝叶斯定理的角度来讲,联合分布完全可以做两种等价变换:
p
(
x
,
y
)
=
p
(
x
)
p
(
y
∣
x
)
=
p
(
y
)
p
(
x
∣
y
)
p(x,y) = p(x)p(y|x)=p(y)p(x|y)
p(x,y)=p(x)p(y∣x)=p(y)p(x∣y)
隐马尔可夫只不过在假设②中采用了后一种变换而已,即假定先有状态,后有观测,取决于两个序列的可见与否。这种因果关系在现实生活中也能找到例子,比如写文章可以想象为先在脑子中构思好一个满足语法词性的词性序列,然后再将每个词性填充为具体的词语。
状态和观测之间的依赖关系确定之后,隐马尔可夫模型利用三个要素来模拟时序序列的发生过程——即初始状态概率向量、状态转移概率矩阵和发射概率矩阵(也称作观测概率矩阵),接下来三小节中分别介绍。
2、初始状态概率向量
系统启动时进入的第一个状态 y 1 y_1 y1 称为初始状态,假设y有N中可能的取值,即 y ∈ s 1 , ⋅ ⋅ ⋅ , s N y∈{s_1,···,s_N} y∈s1,⋅⋅⋅,sN,那么y1 就是一个独立的离散型随机变量,由 p ( y 1 ∣ π ) p(y_1|\pi) p(y1∣π)描述。其中 π = ( π 1 , ⋯ , π N ) T , 0 ≤ π i ≤ 1 , ∑ i = 1 N π = 1 \pi=(\pi_1,\cdots,\pi_N)^T,0\leq\pi_i\leq1,\sum_{i=1}^{N}\pi=1 π=(π1,⋯,πN)T,0≤πi≤1,∑i=1Nπ=1是概率分布的参数向量,称为初始状态概率向量。让我们把它添加到示意图上,如图4-8虚线所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oup9HDeL-1645000219497)(image/image-20220210143022089.png)]](https://i-blog.csdnimg.cn/blog_migrate/153f9602b85f4d514f730d6ea10bfa41.png)
给定
π
\pi
π,初始状态
y
1
y_1
y1的取值分布就确定了。比如中文分词问题采用{B,M,E,N}标注集时,
y
1
y_1
y1所有可能的取值及对应概率如下:
p
(
y
1
=
B
)
=
0.7
p(y_1=B)=0.7
p(y1=B)=0.7
p
(
y
1
=
M
)
=
0
p(y_1=M)=0
p(y1=M)=0
p
(
y
1
=
E
)
=
0
p(y_1=E)=0
p(y1=E)=0
p
(
y
1
=
S
)
=
0.3
p(y_1=S)=0.3
p(y1=S)=0.3
那么此时隐马尔可夫模型的初始状态概率向量为 π = [ 0.7 , 0 , 0 , 0.3 ] \pi=[0.7,0,0,0.3] π=[0.7,0,0,0.3]。注意标签M和E的概率为0,因为句子第一个字符不可能称为单词的中部或尾部。另外, p ( y 1 = B ) > p ( y 1 = S ) p(y_1=B)>p(y_1=S) p(y1=B)>p(y1=S),也说明句子第一个词是单字的可能性要小一些。
3、状态转移概率矩阵
y
t
y_t
yt确定之后,如何转移到
y
t
+
1
y_t+1
yt+1呢?根据马尔可夫假设,
t
+
1
t+1
t+1时的状态仅仅取决于
t
t
t时的状态。既然一共有
N
N
N种状态,那么从状态
s
i
s_i
si到状态
s
j
s_j
sj的概率就构成了一个
N
×
N
N\times N
N×N的方阵,称为状态转移概率矩阵A:
A
=
[
p
(
y
t
+
1
=
s
j
∣
y
t
=
s
i
)
]
N
×
N
A=[p(y_{t+1}=s_j|y_t=s_i)]_{N\times N}
A=[p(yt+1=sj∣yt=si)]N×N
其中下注i、j分别表示状态的第i、j中取值,比如我们约定1表示标注集中的B,依序类推。
状态转移概率矩阵的作用范围添加到示意图上,得到图4-9.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gyi00oEB-1645000219498)(image/image-20220211152401858.png)]](https://i-blog.csdnimg.cn/blog_migrate/2ebaa12a6ef514f098e5d9e44da594cc.png)
状态转移概率的存在有其实际意义,在中文分词中,标签B的后面不可能是S,于是只需要赋予 p ( y t + 1 = S ∣ y t = B ) = 0 p(y_{t+1}=S|y_t=B)=0 p(yt+1=S∣yt=B)=0就可以模拟这种禁止转移的需求。此外,汉语中的长词相对较少,于是隐马尔可夫模型可以通过较小的 p ( y t + 1 = M ∣ y t = M ) p(y_{t+1}=M|y_t=M) p(yt+1=M∣yt=M)来模拟该语言现象。同样,词性标注中的“形容词 ⟶ \longrightarrow ⟶名词”“副词 ⟶ \longrightarrow ⟶动词”也可以通过状态转移概率来模拟。值得一提的是,这些概率分布的参数都不需要程序员手动赋予,而是通过语料库上的统计自动学习。
4、发射概率矩阵
有了状态
y
t
y_t
yt之后,如何确定观测
x
t
x_t
xt的概率分布呢?根据隐马尔可夫假设②,当前观测
x
t
x_t
xt仅仅取决于当前状态
y
t
y_t
yt。也就是说,给定每种y,x都是一个独立的离散型随机变量,其参数对应一个向量。假设观测x一共有M种可能的取值,即
x
∈
o
1
,
⋅
⋅
⋅
,
o
M
x∈{o_1,···,o_M}
x∈o1,⋅⋅⋅,oM,则x的概率分布参数向量维度为M。由于y一共有N种,所以这些参数向量构成了
N
×
M
N\times M
N×M的矩阵,称为发射概率矩阵B。
B
=
[
p
(
x
t
=
o
i
∣
y
t
=
s
j
)
]
N
×
M
B=[p(x_t=o_i|y_t=s_j)]_{N\times M}
B=[p(xt=oi∣yt=sj)]N×M
其中,第i行j列的元素下标i和j分别代表观测和状态的第i种和第j中取值,比如我们约定i=1表示字符集中的“阿”。此时
p
(
x
1
=
阿
∣
y
1
=
B
)
p(x_1=阿|y_1=B)
p(x1=阿∣y1=B)对应矩阵中左上角第一个元素。如果字符集大小为1000的话,则B就是一个
4
×
1000
4\times1000
4×1000的矩阵。
将发射概率矩阵B的作用范围添加到示意图上,得到图4-10。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-34o1rd00-1645000219498)(image/image-20220211160004922.png)]](https://i-blog.csdnimg.cn/blog_migrate/5a7c98ddc1b61ac2f5d4b4756ff692c9.png)
发射(emission)概率矩阵是一个非常形象的术语:将 y t y_t yt想象为不同的彩弹枪, x t x_t xt想象为不同颜色的子弹,则根据 y t y_t yt确定 x t x_t xt的过程就像拔枪发射彩弹一样。不同的彩弹枪弹舱内的每种色彩弹比例不同,导致有些彩弹枪更容易发射红色彩弹,另一些更容易发射绿色彩弹。
发射概率在中文分词中也具备实际意义,有些字符构词时的位置比较固定。比如作为词首的话,不容易观测到“忑”,因为“忑”一般作为“忐忑”的词尾出现。通过赋予 p ( x 1 = 忑 ∣ y 1 = B ) p(x_1=忑|y_1=B) p(x1=忑∣y1=B)较低的概率,隐马尔可夫模型可以有效的防止“忐忑”被错误切开。
初始状态概率向量、状态转移概率矩阵与发射概率矩阵被称为隐马尔可夫模型的三元组 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B),只要三元组确定了,隐马尔可夫模型就确定了。
5、隐马尔可夫模型的三个基本用法
隐马尔可夫模型的作用并不仅限于预测序列标注,它一共解决如下三个问题。
(1)样本生成问题:给定模型 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B),生成满足模型约束的样本,即一系列观测序列及其对应的状态序列{ ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))}。
(2)模型训练问题:给定训练集{ ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))},估计模型参数 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B)。
(3)序列预测问题:已知模型参数 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B),给定观测序列 x x x,求最可能的状态序列 y y y。
mbda=(\pi,A,B)$。
(3)序列预测问题:已知模型参数 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B),给定观测序列 x x x,求最可能的状态序列 y y y。


















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











