







主要内容
1.感知器总述
1958年,美国心理学家Frank Posenblatt 提出一种具有单层计算单元的神经网络,称为Perceptron,即感知器。感知器模拟人的视觉接受环境信息,并由神经冲动进行信息传递。感知器研究中首次提出了自组织、自学习的思想,而且对所能解决的问题存在着收敛算法,并能从数学上严格证明,因而对神经网络的研究起了重要的推动作用。感知器的输出一般是0或1,当然也可以是-1或+1,实现对输入的矢量进行分类的目的。
2.感知器模型

图中, n 维向量[a1,a2,…,an]的转置作为感知机的输入,[w1,w2,…,wn]的转置为输入分量连接到感知机的权重(weifht),b 为偏置(bias),f(.)为激活函数,t 为感知机的输出。t 的数学表示为:
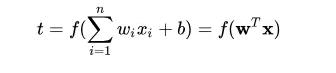
另外,这里的 f(.) 用的是符号函数:
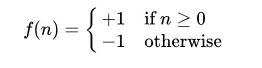
也可以记成:
f(x)= sign(w*x+b)
其中,x为输入向量,sign为符号函数,括号里面大于等于0,则其值为1,括号里面小于0,则其值为-1。w为权值向量,b为偏置。求感知机模型即求模型参数w和b。感知机预测,即通过学习得到的感知机模型,对于新的输入实例给出其对应的输出类别1或者-1。
3.感知器策略(建立损失函数)
假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练数据集中正负实例完全分开的分类超平面,为了找到分类超平面,即确定感知机模型中的参数w和b,需要定义一个损失函数并通过将损失函数最小化来求w和b。
这里选择的损失函数是误分类点到分类超平面S的总距离。输入空间中任一点x0到超平面S的距离为:
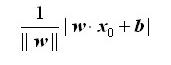
其中,||w||为w的L2范数。就是 w 中每个元素去平方,然后相加开根号,即 ||w|| = √w1^2 + w2^2 +…+ wn^2 。
其次,对于误分类点来说,当-yi (wxi + b)>0时,yi=-1,当-yi(wxi + b)<0时,yi=+1。所以对误分类点(xi, yi)满足:
-yi (wxi +b) > 0
所以误分类点(xi, yi)到分类超平面S的距离是:

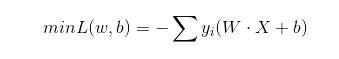
感知器学习的目的是找到合适的权值与阈值,使得感知器的输出、输入之间满足线性可分的函数关系。学习的过程往往很复杂,需要不断的调整权值与阈值,称为“训练”的过程。
若以t表示目标输出,a表示实际输出,则
e=t-a
训练的目的就是使t->a.
一般感知器的传输感受为阈值函数网络的输出a只能是0或1,所以只要网络表达的函数是线性可分的,则函数经过有限次迭代之后,将收敛到正确的权值与阈值,使e=0。
感知器的训练需要提供样本集,每个样本由神经网络的输入向量和输出向量对构成,n个训练样本构成的样本集为:
{p1,t1},{p2,t2}~~~~{pn,tn}
每一步学习过程,对各个神经元的权值与阈值的调整算法是:
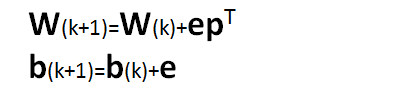
式子中W为权值向量;b为阈值向量;p为输入向量;k为第k步学习过程。上述学习过程称为标准化感知器学习规则,可以用函数learnp实现。
如果输入向量的取值范围很大,一些输入值太大,而一些输入值太小,按照上述公式学习的时间将会很长。为此,阈值的调整可以继续按照上述公式,而权值的调整可以采用归一化方法,即

上述归一化学习方式可以使用函数learnpn实现。
4.感知器算法(梯度下降和随机梯度下降)
4.1梯度下降
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。以山为例,就是坡度最陡的地方,梯度值就是描述坡度有多陡。
研究梯度,就要知道导数、偏导数、方向导数的知识,[机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent) 中讲得非常通俗易懂(原文链接放在参考资料里边).
梯度下降方向就是梯度的反方向,最小化损失函数 L(w,b) 就是先求函数在 w 和 b 两个变量轴上的偏导:
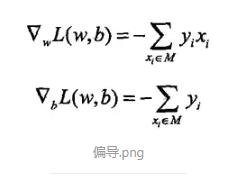
上面的式子,每更新一次参数,需要遍历整个数据集,如果数据集非常大的话,显然是不合适的,为了解决这个问题,只随机选取一个误分类点进行参数更新,这就是随机梯度下降(SGD)。
4.2随机梯度下降

这里的 η 指的是学习率,相当于控制下山的步幅,η 太小,函数拟合(收敛)过程会很慢,η 太大,容易在最低点方向震荡,进入死循环。
当没有误分类点的时候,停止参数更新,所得的参数就是感知机学习的结果,这就是感知机的原始形式。下面总结一下参数更新的过程:
(1)预先设定一个 w0 和 b0,即 w 和 b 的初值。
(2)在训练集中选取数据(xi,yi)。
(3)当 yi*(w xi +b) <= 0时,利用随机梯度下降算法进行参数更新。

这种算法的基本思想是:当一个实例点被误分类,即位于分类超平面错误的一侧时,则调整w和b,使分类超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类为止。
需要注意的是,这种感知机学习算法得到的模型参数不是唯一的,它会由于采用不同的参数初始值或选取不同的误分类点,而导致解不同。为了得到唯一的分类超平面,需要对分类超平面增加约束条件,线性支持向量机就是这个想法。另外,当训练数据集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。而对于线性可分的数据集,算法一定是收敛的,即经过有限次迭代,一定可以得到一个将数据集完全正确划分的分类超平面及感知机模型。
5.感知器MATLAB简单实现
MATLAB神经网络提供了大量的与神经网络感知器相关的函数。在MATLAB工作空间的命令行中输入help percept,便可得到与神经网络感知器相关的信息。
5.1newp函数:
用于创建一个感知器网络,函数的调用格式如下。
net=newp(P,T,TF,LF):其中,P为一个r✖2维的输入向量矩阵,其决定了r维输入向量的最大值和最小值取值范围;T表示神经元的个数;TF表示网络的传输函数,默认值为hardlim;LF表示网络的学习函数,默认值为learnp;net为生成的新感知器神经网络。
小应用:
% 1.1 生成网络
net=newp([0 2],1);%单输入,输入值为[0,2]之间的数
inputweights=net.inputweights{
1,1};%第一层的权重为1
biases=net.biases{
1};%阈值为1
5.2sim函数:
在MATLAB神经网络工具箱中,提供了sim函数用于进行网络仿真,函数的调用格式如下:
[Y,Pf,Af,E,perf]=sim(net,P,Pi,Ai,T):Y为网络的输出;Pf表示最终的输入延时状态;Af表示最终的层延时状态;E为实际输出与目标矢量之间的误差;perf为网络的性能值;NET为要测试的网络对象;P为网络的输入向量矩阵;Pi为初始的输入延时状态(可省略);Ai为初始的层延时状态(可省略);T为目标矢量(可省略)。
小应用:
% 1.2 网络仿真
net=newp([-2 2;-2 2],1);%两个输入,一个神经元,默认二值激活
net.IW{
1,1}=[-1 1];%权重,net.IW{
i,j}表示第i层网络第j个神经元的权重向量
net.IW{
1,1}
net.b{
1}=1;
net.b{
1}
p1=[1;1],a1=sim(net,p1)
p2=[1;-1],a2=sim(net,p2)
p3={
[1;1] [1 ;-1]},a3=sim(net,p3) %两组数据放一起
p4=[1 1;1 -1] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3414
3414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









