








1. Motivation and Contribution
1.1 Motivation
-
在CV中,无监督的方法相对于有监督来说较为落后。
supervised pre-training is still dominant in computer vision, where unsupervised methods generally lag behind
-
我们假设字典的构建满足2个条件,容量大且和输入的query保持一致性,但是目前的存在的方法都只包含了其中一种。
we hypothesize that it is desirable to build dictionaries that are: (i) large and (ii) consistent as they evolve during training.
However, existing methods that use contrastive losses can be limited in one of these two aspects (discussed later in context).
1.2 Contribution
- We present Momentum Contrast (MoCo) for unsupervised visual representation learning.
- From a perspective on contrastive learning [29] as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder.
- MoCo can outperform its supervised pretraining counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, some- times surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
2. Method
2.1 Contrastive Learning as Dictionary Look-up
对比损失就是用来衡量样本在表示空间上的相似度。
Contrastive losses measure the similarities of sample pairs in a representation space.
InfoNCE,对于每一个q来说,有encoder中的一个k与之match,作为这个q的正样本,q与k则称作为正样本对positive pair。而其余的K个key坐标负样本,使用交叉熵损失函数计算每一个q的loss。
A contrastive loss is a function whose value is low when q is similar to its positive key k+ and dissimilar to all other keys (considered negative keys for q).
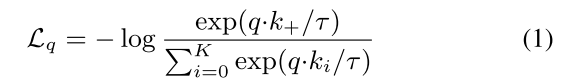
where τ is a temperature hyper-parameter per . The sum is over one positive and K negative samples. Intuitively, this loss is the log loss of a (K+1)-way softmax-based classifier that tries to classify q as k+.
The contrastive loss serves as an unsupervised objective function for training the encoder networks that represent the queries and keys.
q = f q ( x q ) q = f_q(x^q) q=fq(xq)以及 k = f k ( x k ) k = f_k(x^k) k=fk(xk)。对于输入 x q x^q xq与 x k x^k xk的定义:
The input x q x^q xq and x k x^k xk can be images, patches, or context consisting a set of patches .
The networks fq and fk can be identical , partially shared , or different.
本文中对于q与k为正负pair的定义为,如果是同一个图片中的编码(数据增强)的views,则q匹配k。
In this paper, we follow a simple instance discrimination task [61, 63, 2]: a query matches a key if they are encoded views (e.g., different crops) of the same image.
2.2 Momentum Contrast
-
Dictionary as a queue
The introduction of a queue decouples the dictionary size from the mini-batch size.
-
Momentum update
Using a queue can make the dictionary large, but it also makes it intractable to update the key encoder by back-propagation.
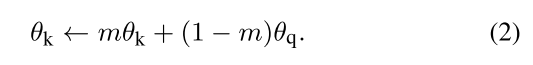
公式2中吗,只有 θ q \theta_q θq是通过反向传播更新的,m是超参数。
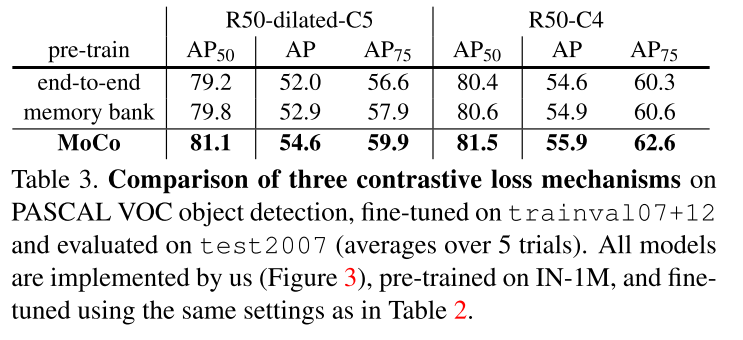
2.3 Relations to previous mechanisms
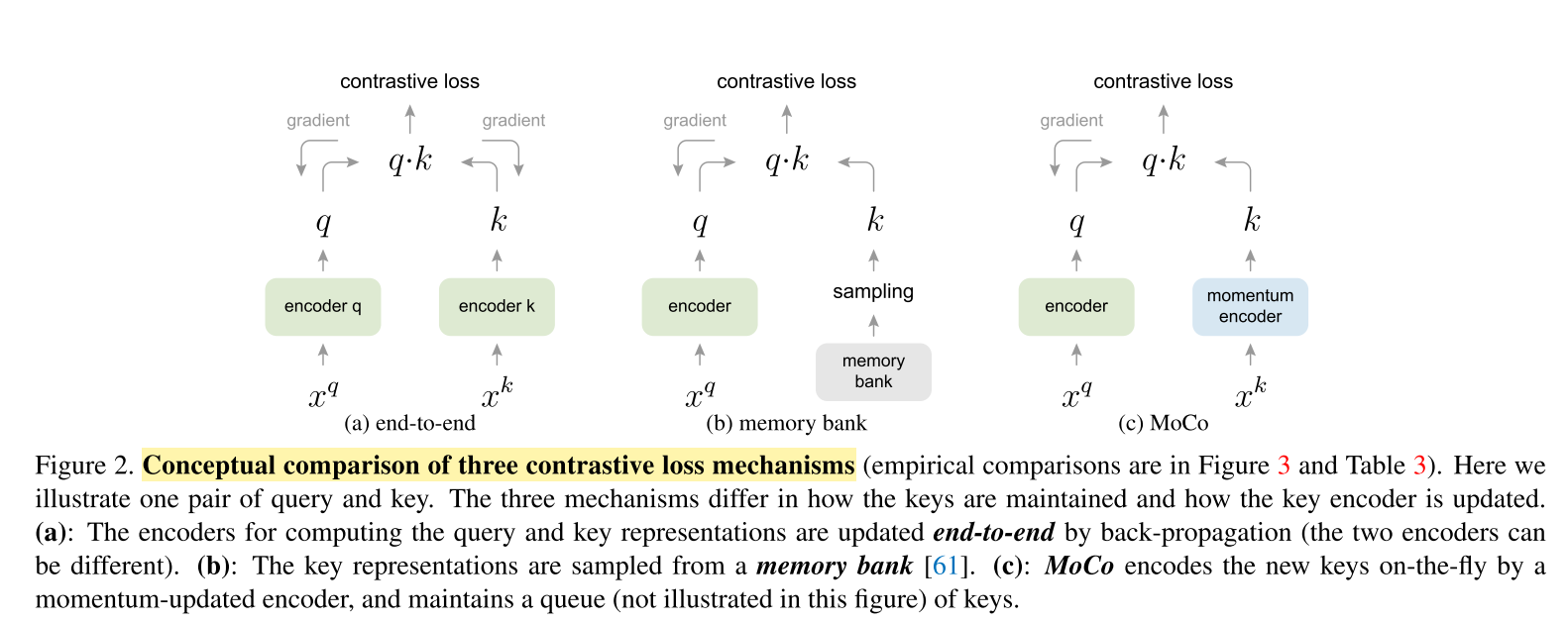
目前对比损失结构有三种,分别是end-to-end,基于memory-bank的,以及本文提出的MoCo。
-
end-to-end端到端的对比损失方法,是将目前mini-batch中的输入作为字典,因此query和key是保持一致性的,使用反向传播方法更新q和k。
端到端的优点在于consistent,但是缺点不够large,就是字典的大小是和mini batch-size的大小一致,也就是说会受到GPU显存的影响。
-
memory-bank记忆银行,是将数据集里面的所有sample的表示组成。因此,对于k来说,就不需要back-propagation,只是sample的操作。
但是对于memory bank中的一个采样的表示是在最后一次遇见的时候更新的,因此sampled keys的本质是关于之前的epoch的多个不同的steps的编码,因此一致性较少。
A memory bank consists of the representations of all samples in the dataset.
it can support a large dictionary size. However, the representation of a sample in the memory bank was updated when it was last seen, so the sampled keys are essentially about the encoders at multiple different steps all over the past epoch and thus are less consistent.
记忆银行的优点在于large,但是缺点在于不consistent。
-
本文提出的MoCo保留了large以及consistent的2种特性。使用同一个image的q和k,q进行梯度回传,而k进行momentum 更新,保持一种渐进性最小的更新;同时MoCo将字典使用队列的方法进行保存和替换,每次有新的key就将最早的mini-bach的key出队,并将新的key入队,保持了一种large dictionary。
2.4 pseudo code
输入的x_q以及x_k是通过各自不同的数据增强的方式得到,初始化q与k的decoder的参数一致。原始的字典是 C × K C \times K C×K
x_q和x_k经过各自的encoders得到q,k,将k的梯度进行截断。
计算positive和negative pair logits。对于正样本就是当前batch的q和k一对一的矩阵乘法,而负样本就是当前q和字典中的keys的矩阵乘法。维度为分别为 N × 1 N \times 1 N×1, N × K N \times K N×K。
然后将正负样本的logits进行cat,使用contrastive loss进行计算。
接着反向传播梯度,更新q的encoder f_q的参数。
动量更新k的encoder f_k的参数。
将当前batch的k进行入队,将最早mini batch的k进行出队。

2.5 Pretext Task
MoCo中正负样本对的定义如下,在当前batch中,queris和对应的keys作为正样本对(从伪代码中看出,其实就是第i个对q对应第i个k,一一对应的关系),维度为 N × 1 N \times 1 N×1;而queries与队列中的keys作为负样本对, N × K N \times K N×K。
Following [61], we consider a query and a key as a positive pair if they originate from the same image, and other- wise as a negative sample pair.
For the current mini-batch, we encode the queries and their corresponding keys, which form the positive sample pairs. The negative samples are from the queue
2.5.1 Technical details.
MoCo使用ResNet作为encoder,最后接一个128-d的vector,作为query和key的表示。也就是 q q q和 k k k。
数据增强的方法有:
The data augmentation setting follows [61]: a 224×224-pixel crop is taken from a randomly resized image, and then undergoes random color jittering, random horizontal flip, and random grayscale conversion, all available in PyTorch’s torchvision package.
2.5.2 Shuffling BN
BN对于实验效果有影响。
In experiments, we found that using BN prevents the model from learning good representations.
附录中的消融实验显示出,使用BN会泄露信息,而产生过拟合。
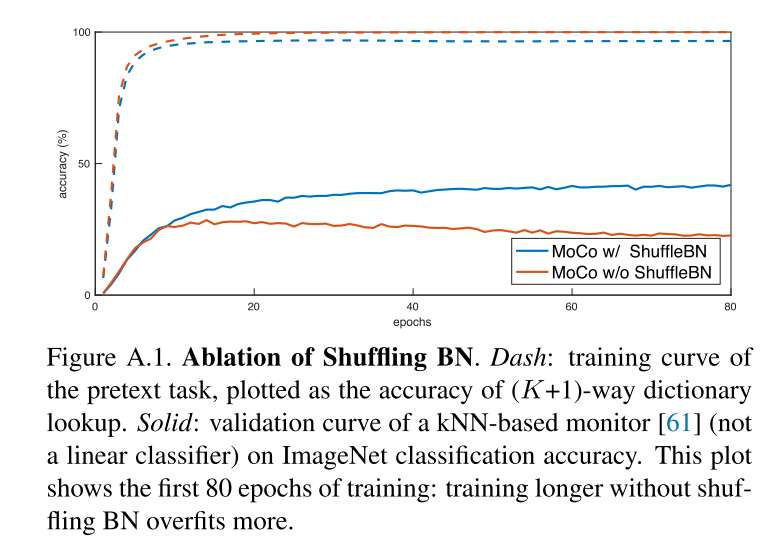
We resolve this problem by shuffling BN. We train with multiple GPUs and perform BN on the samples independently for each GPU.
3. Experiment
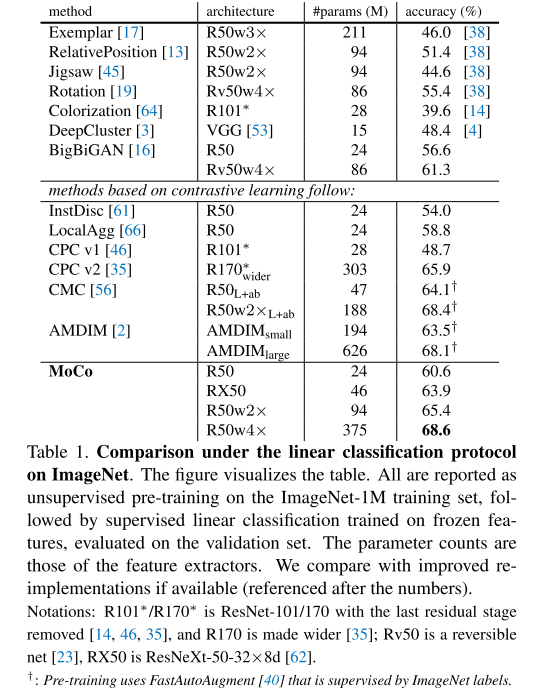
3.1 Linear Classification Protocol
在MoCo训练好后,冻结无监督训练好的参数,然后加入一个有监督的分类层,只保留q的encoder,利用coco中的标签信息进行训练。

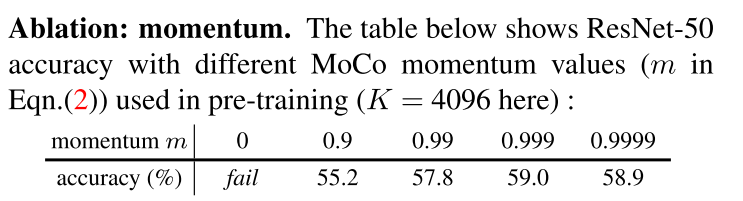
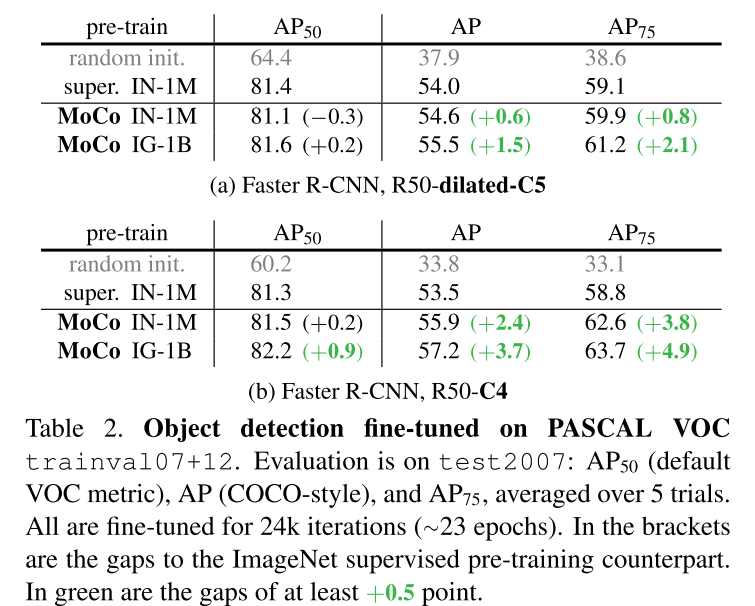
3.2 PASCAL VOC Object Detection

3.3 COCO Object Detection and Segmentation
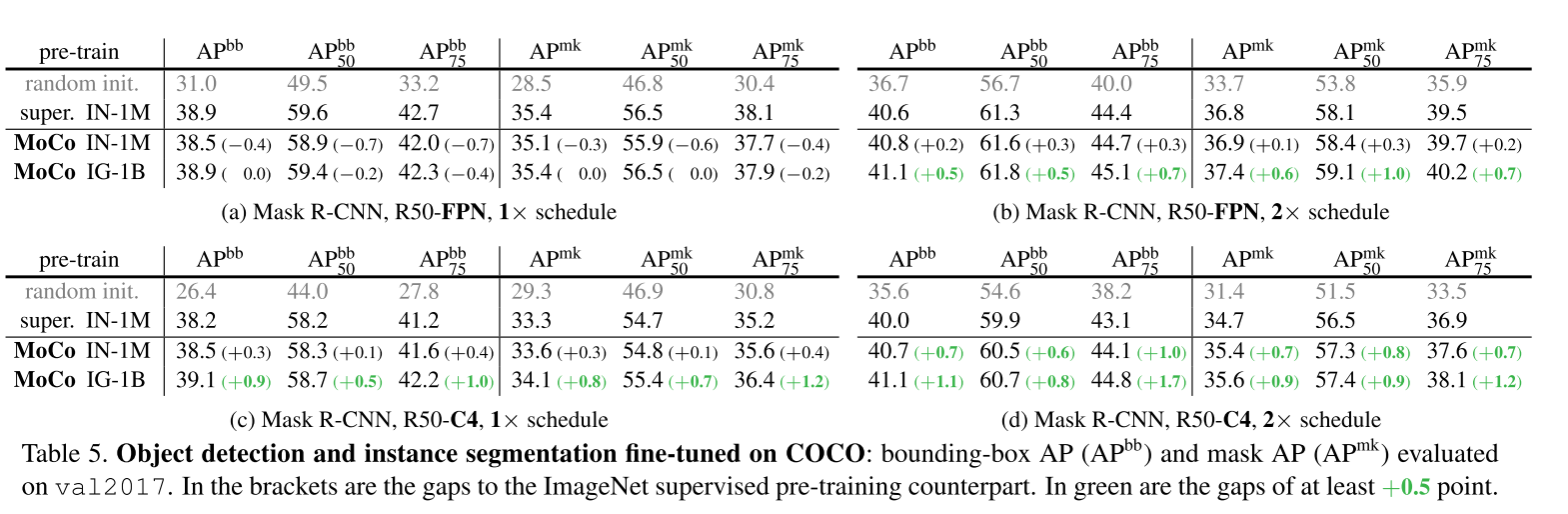
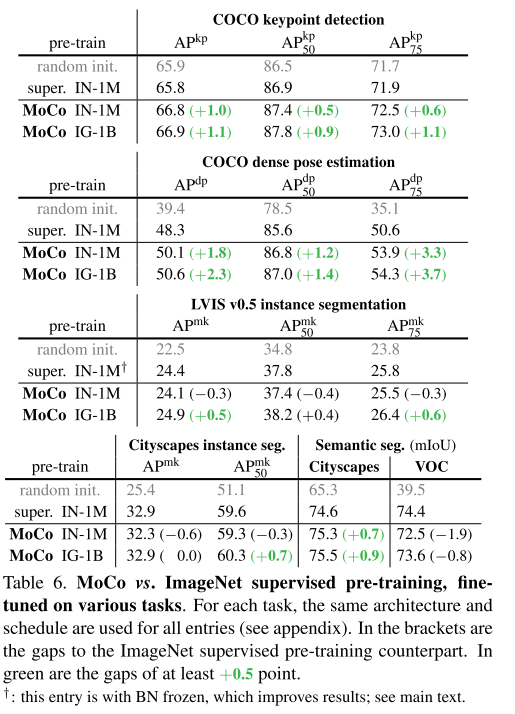
3.4 More Downstream Tasks















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









