







用到爬虫的selenium库、chromedriver
在与代码同一级的路径下创建文件:网址.txt,里面的每一行为要打开的网址:
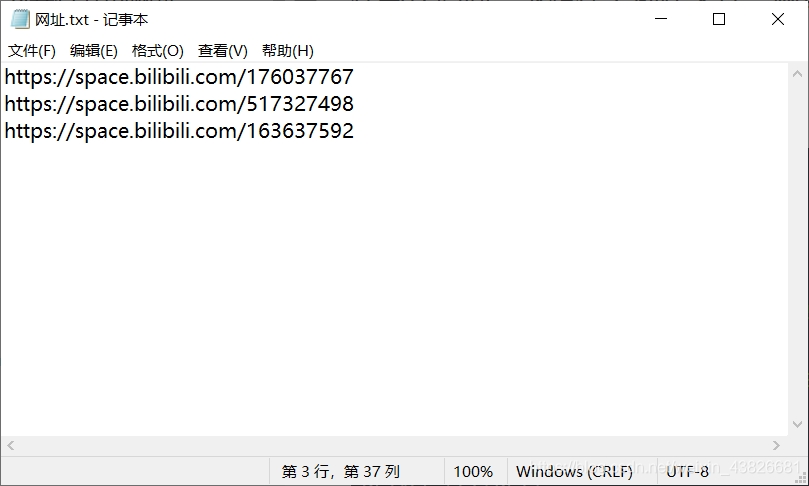
代码:
# 导入模块
from selenium import webdriver
# 打开浏览器
driver = webdriver.Chrome(r"C:\Users\53224\_jupyter\chromedriver.exe") # 记得修改chromedriver的路径
f = open("./网址.txt", encoding="UTF-8")
url = f.readline().strip()
print(url)
driver.get(url)
url = f.readline().strip()
while url:
print(url)
js = "window.open('" + url + "')"
driver.execute_script(js)
url = f.readline().strip()
f.close()
运行结果:
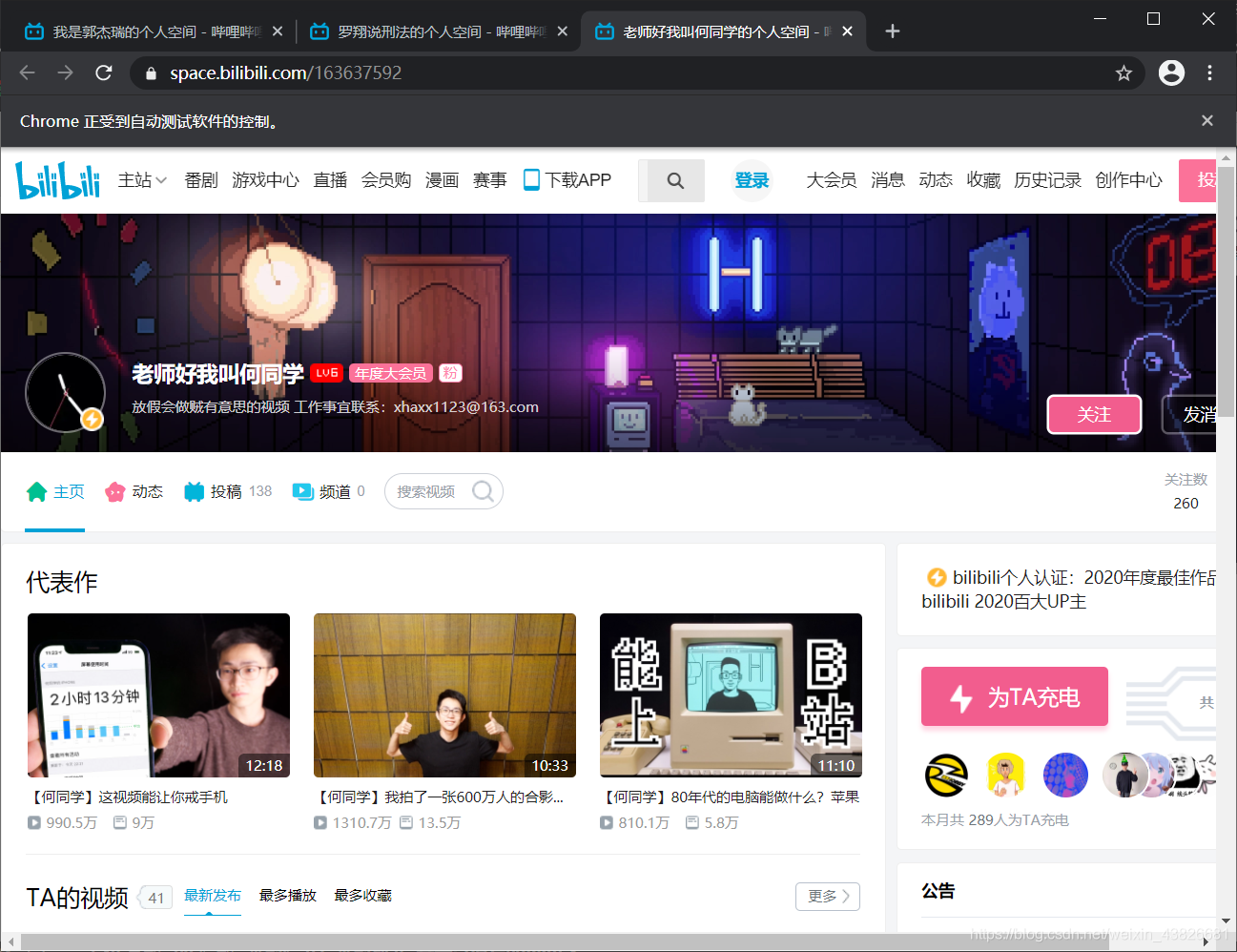
完。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









