







网络基础(三)
应用层
自定制协议
HTTP协议
传输层
UDP协议
TCP协议
1.1 自定制协议
-
首先需要知道的是,自定制协议是工作在应用层的,是被程序员所定义出来的协议,才被称之为自定制协议,我们在网络协议栈中其实已经听说过许多协议了,比如说在应用层的http协议,在传输层的UPD和TCP协议,在网络层的IP协议,在数据链路层的ARP协议,这些协议其实都是属于网络协议栈中的协议,而在有些情况下,网络协议栈中的协议不能满足我们的需求,所以说有可能在我们使用网络的时候发生不适配的现象,所以我们就需要在应用层中去自己定制一些别的协议,从而来适配我们的需求,是因为网络协议栈总的协议不能满足我们的需求,所以我们自己给出了自定制协议
-
那么为什么需要自定制协议呢?这个点就需要从TCP的特性来说起,TCP有一个特性是面向字节流,当我们在应用层调用send接口的时候,我们会把这个i放到传输层的TCP协议的缓冲区当中,TCP面向自己流的特性是会导致TCP粘包的问题产生的
-
那么,什么是缓冲区----send函数和reve函数都是在应用层来进行调用的,而我们应用层调用这个接口的话,其实是会把数据放在传输层当中的接收缓冲区和发送缓冲区当中的,当我们调用send函数的时候,其实会在传输层中有一个发送缓冲区,在发送缓冲区的下面有一个接收缓冲区,调用send其实就是将数据写入到发送缓冲区当中,至于TCP到底是怎么发送的,其实就和应用层没有任何的关系了,是属于TCP协议的东西,应用层只负责调用send接口,把数据发送到发送缓冲区当中,接收缓冲区其实就相当于是我们从网络层中接收道到的数据,首先会放在接收缓冲区当中,这个数据目前是在接收缓冲区的,紧接着我们去调用recv函数,然后就把数据拿回去了
-
对于发送方和接收方他们都有一个各自独立的接收缓冲区和发送缓冲区,对于数据的发送方和接收方而言他们都有各自的发送缓冲区和接收缓冲区,所以说TCP也是全双工通信的
-
应用层调用send接口,也只是把数据放在传输层的发送缓冲区里面,到底怎么发送,就与应用层没有任何的关系了,属于TCP的范畴了就

- 因为现在发送的数据1和1之前全部都是挨在一起的,没有明显的划分边界,就是说现在是说不清楚数据是第几次发送的了,那么,接收端如何区分哪些数据组合起来才是一条完整的数据呢,这其实就是所带来的问题,这其实也就是TCP粘包所带来的问题

TCP粘包问题
- TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾
- 出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成----发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一包数据。若连续几次发送的数据都很少,通常TCP会根据优化算法把这些数据合成一包后一次发送出去,这样接收方就收到了粘包数据。接收方引起的粘包是由于接收方用户进程不及时接收数据,从而导致粘包现象
为什么UDP不会产生粘包的问题
- UDP是一个无连接的,面向消息的传输层协议。UDP不会使用块的合并优化算法,发送方发送数据时,是一包一包的发送,不会把多个小包组合成大包一起发送,UDP发送数据是一次全部发送的,所以不会产生粘包的问题
如何解决TCP粘包问题
-
采用自定制协议解决TCP粘包的问题

-
那么我们如何去解决TCP粘包问题呢,我们提出了自定制协议的方式来解决TCP粘包问题,也就是说我么对数据提出一种格式,或者说是一种要求,也就是说我们对数据的发送与接收提出一种格式的控制
-
所以说,其实自定制协议其实就是在应用层对传输的数据,进行数据格式的约定,消息的发送方和接收方都遵守这个约定,这种约定一般是报头+分隔符的做法,报头中应该含有数据长度,当对端拿到报头的时候,对端就知道他要去拿的数据到底有多长了,报头里面包含有我们所要传输的数据的信息,报头的长度应该是固定的,如果报头的数据是不固定长度的,那么其实相当于我们每一次传输的数据的长度其实还是不固定长度的,如果长度是不固定的,接收方其实还是没有办法区分这些数据到底是哪次和哪次发送过来的数据,报头的内容我们可以使用一个结构体来表达

-
由报头数据和分隔符组成
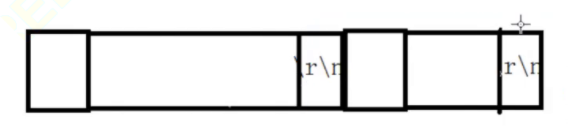

总结TCP粘包问题


长连接和短连接
-
长连接—Client方与Server方先建立通讯连接,连接建立后不断开, 然后再进行报文发送和接收
-
短连接—Client方与Server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。此种方式常用于一点对多点通讯,比如多个Client连接一个Server
-
短连接也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源,每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议
-
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件中设定这个时间。实现长连接需要客户端和服务端都支持长连接
-
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接
如何快速区分当前连接使用的是长连接还是短连接
- 凡是在一次完整的消息交互之后,立刻断开连接的情况都称为短连接
- 长连接的一个明显特征是会有心跳消息,且一般心跳间隔都在30S或者1MIN左右,用wireshark抓包可以看到有规律的心跳消息交互
什么时候用长连接,短连接?
- 需要频繁交互的场景使用长连接,如即时通信工具(微信/QQ,QQ也有UDP),相反则使用短连接,比如普通的web网站,只有当浏览器发起请求时才会建立连接,服务器返回相应后,连接立即断开。
- 维持长连接会有一定的系统开销,用户量少不容易看出系统瓶颈,一旦用户量上去了,就很有可能把服务器资源(内存/CPU/网卡)耗尽,所以使用需谨慎
序列化
- 序列化的本质其实就是将对象转换成为二进制
- 反序列化其实就是将二进制转换成为对象
HTTP协议—是在应用层的
-
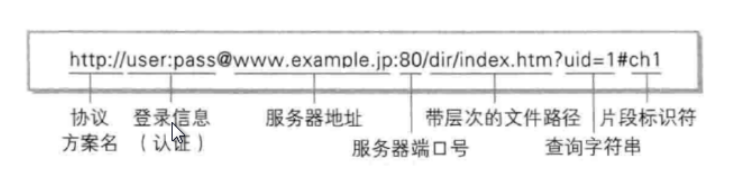
要去说应用层的协议,首先需要先认识一下url(也就是我们在浏览器中所输入的内容)
-
url指的是—统一资源定位系统,URL是由一串字符组成,这些字符可以是字母,数字和特殊符号。一个URL可以用多种方法来表现,例如:纸上的字迹,或者是用字符集编码的八位字节序列
-
其实是由用户名和密码的,只是用户名和密码不显示在这里,因为用户名和密码不显示其实是为了更加的安全
-
http它其实是协议方案名
-
@后面的内容其实是域名的内容,域名说的再直白一些,其实就是ip地址,域名在访问的时候其实会经过一层DNS协议的解析,然会就可以把域名解析成对应的ip地址,一般使用http的时候,默认的端口是80,使用https的时候,默认的端口是443端口,如果不传端口的话,其实浏览器是会默认给我们加上一个端口的,如果是http就加80,如果是https就加443(也就是说,其实是有一个默认的端口的,只是不传的话,才回去使用默认的端口)
-
带层次的文件路径其实就是说我现在想告诉当前的服务端我要请求的是哪一个文件,这个文件最前面的/相当于是我们当前http服务器的逻辑根目录,也就是说我去指定我在启动http服务的时候我的根目录是哪一个目录
-
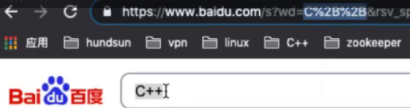
?之后的数据都是给服务器去进行提交的数据,是一种key=value的形式(键值对和键值对之间用&进行隔开,key=value最终是提交给服务端的),下面看到的内容之所以是不一样的,是因为起其会进行一层urlencode(也就是说将常用的字符进行转码,也就是说到底是要把C++看成一个C格式的字符串加上两个加号呢,还是说把C++看成一个整体的C字符串呢,这个时候就没有办法去进行区分了,所以我就需要想一种办法,我就需要去告诉他,这其实是一个整体)
-
要对URL进行编码,不然的话,其实是会引起歧义的
-
为什么要对URL进行重新编码----原因其实在于我们都知道Http协议中参数的传输是"key=value"这种简直对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?name1=value1&name2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出参数值,现在有这样一个问题,如果我的参数值中就包含=或&这种特殊字符的时候该怎么办。 比如“name1=value1”,其中value1的值是“va&lu=e1”字符串,那么实际在传输过程中就会变成这样“name1=va&lu=e1”。我们的本意是就只有一个键值对,但是服务端会解析成两个键值对,这样就产生了奇异,或者说是

-
运行结果—也就是相当于说加号在进行转码的时候,就把这个符号按照16进制来进行转化了
-
对转码之后的结果前面加上一个%,其实就是为了提醒服务端,这个东西我是经过url转码的,你在去进行解释的时候,需要进行一次解码,然后就可以把这个结果转换成原先的字符串
-
最后是以#相连接的片段标识符,片段标识符可以用来在我们的html页面当中进行定位(比如说回到首部的功能其实就是由片段标识符来完成的)

HTTP协议在传输层使用的是协议是TCP协议
- 超文本传输协议是一种用于分布式、协作式和超媒体信息系统的应用层协议
HTTP数据包格式

-
我们再说HTTP数据包格式的时候我们需要从两个方面来说这个数据包格式,第一个叫做请求,第二个叫做响应
-
按下F12,就会进入到我们浏览器的开发者模式,这样子使得我们可以快速的去看到网页的源码
-
响应报头和请求报头
-
http请求的协议表示:
-
**请求首行包含 请求方法+URL+协议版本 **

-
正文是我们真正所要展示的数据
-
当我们知道了请求格式之后,我们就需要去知道请求方法
-
Get提交的数据其实就在url中,Post提交数据是在正文之中



Get方法和Post方法哪个方法更安全一些
-
其实如果非要谈到安全问题的话,其实get方法和post方法都是不安全的,因为get是放在url中的,post适放在正文当中的,只要我已进行抓包我就是可以看到的,比如说我就可以看到登陆一个系统的账户名和密码,这个时候i其实只能说post方法比get方法能更私密一些,我们如果想要安全,其实还是需要通过ssl来进行加密的,也就是我们所说的非对称加密
-
我认为post,更安全一些,因为get传输方式将在URL中显示参数,例如上边出现了username和userpwd等特殊字符时,更容易给他们一些兴趣。虽然可以编码,当是也是可以解码的。而post则对方看不见,即使一些高手截获这些信息,也需要它筛选还有解码,相对来说比get方法更加安全。当然是没有绝对的安全的
GET和POST的区别
- get 提交的数据会放在 URL 之后,并且请求参数会被完整的保留在浏览器的记录里,由于参数直接暴露在 URL 中,可能会存在安全问题,因此往往用于获取资源信息。而 post 参数放在请求主体中,并且参数不会被保留,相比 get 方法,post 方法更安全,主要用于修改服务器上的资源。
- get 请求只支持 URL 编码,post 请求支持多种编码格式。
- get 只支持 ASCII 字符格式的参数,而 post 方法没有限制。
- get 提交的数据大小有限制(这里所说的限制是针对浏览器而言的),而 post 方法提交的数据没限制
- get 方法产生一个 TCP 数据包,post 方法产生两个(并不是所有的浏览器中都产生两个)。
http响应(响应首行,响应包头,空行,正文)
-
Respense Headers----其实就是响应头部

格式是: -
响应首行—其实就是HTTP/1.1—其实就是HTTP版本,然后第二个东西是状态码,第三个东西是状态码解释
-
4----错误码,比如说404
-
5----错误码,比如说502
-
响应状态行:包括 ** 协议版本号+状态码+状态码解释 **

-
重定向状态码指的是,假设我现在有一个浏览器,然后我想要通过这个浏览器去访问一个网址,假如说,就希望去访问百度这个网址,那么百度这个网址能被人访问的话,其实就需要他后台有一个服务器,那么假如说当前的服务器并不能正常去处理我们访问百度网页的这个业务请求(需要注意的是这里的不能正常去处理请求,并不是说我们的服务器现在没有收到这个请求,我收到是收到了,只是说你发送过来的这个请求,我现在是处理不了的),也就是说,重定向其实就是在告诉你你想要完成你希望完成的请求的话,你应该去哪里完成你的请求(但是,其实在状态码后面还存在有\r,\n,也就是说是回车和换行符)
-
重定向其实也就是在说,即使你现在的条件不满足我完成一件事情的需求,在后台我也会想尽一切办法让你现在的请求可以完成(这个过程是只有后台才会感知到的,用户本身其实是无法感知到的)


状态码

-
404 - 请求的资源(网页等)不存在
-
405 - 客户端请求中的方法被禁止
-
响应包头----响应包头其实一个key:value\r\n的格式,也就是说说,下面的这种格式,每个key和value之间都会隔开,然后Content-Type:其实指的是正文的类型;Content-Length是正文的长度,这两个东西是我们返回响应的时候,比较重要的内容

-
如果返回的是一个html页面,其实也就不需要Content-Length了,所以没有Content-Length,如果返回的是一个字符串的话,其实就还是要返回Content-Length的

-
下面的东西其实是支持分块传输,也就是说我可以把一个http数据包分成几个包从而去进行传输的操作

-
空行—其实就是我们所说的\r和\n
-
正文
http代码模拟
- 可以直接在之前的tcp代码之上进行改造,改造出来一个http代码
- 返回响应的时候,按照http响应格式去组织数据,也就是在调用send函数的时候,需要按照http响应的格式去组织数据,只有这样,浏览器才是可以识别的
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <string>
#include <sstream>
int main()
{
int listen_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if(listen_sock < 0)
{
perror("socket");
return -1;
}
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(19998);
addr.sin_addr.s_addr = inet_addr("0.0.0.0");
int ret = bind(listen_sock, (struct sockaddr*)&addr, sizeof(addr));
if(ret < 0)
{
perror("bind");
return -1;
}
ret = listen(listen_sock, 5);
if(ret < 0)
{
perror("listen");
return -1;
}
//当已完成连接队列为空的时候, 调用accept函数会阻塞
int new_sock = -1;
while(1)
{
new_sock = accept(listen_sock, NULL, NULL);
if(new_sock < 0)
{
perror("accept");
return -1;
}
char buf[1024] = {0};
//MyTCPHeader mth;
ssize_t recv_size = recv(new_sock, buf, sizeof(buf)-1, 0);
if(recv_size < 0)
{
perror("recv");
continue;
}
else if(recv_size == 0)
{
printf("perr shutdown\n");
close(new_sock);
close(listen_sock);
return 0;
}
printf("cli say: %s\n", buf);
memset(buf, '\0', sizeof(buf));
//memset之后需要自己去进行响应的操作
//1.响应头部
//类C风格格式化字符串的方式
// 下面这个函数的功能是格式化字符串,我们要把格式化的字符串放到buf里面去
// snprintf(buf, sizeof(buf) - 1, "HTTP/1.1 200 OK\r\nContent-Type: (这里有个空格)text/html\r\nContent-Length: %lu\r\n\r\n", body.size()); 用lu是因为返回的是无符号的整数
//下面这一行的内容是正文的内容
std::string body = "<html>i love linux</html>";
//但是因为上面的类C风格的东西写起来太麻烦了,所以我们换一种方式
//我们选择采用C++中的stringstream
//std::stringstream ss; //现在有一个类了
//然后我们就可以向类中去写入内容了
//ss << "HTTP/1.1 200 OK\r\n";
//ss << "Content-Type: text/html\r\n";
//ss << "Content-Length: " << body.size() << "\r\n";
//ss << "\r\n";
//体验一下重定向到底是什么东西
//std::stringstream ss;
//ss << "HTTP/1.1 302 Location\r\n";
//ss << "Content-Type: text/html\r\n";
//ss << "Content-Length: " << body.size() << "\r\n";
//location后面跟的是你即将要重定向的页面的url
//就是说你要告诉浏览器你现在要重定向道哪个页面去
//ss << "Location: https://www.baidu.com/\r\n";
//ss << "\r\n";
//404
//std::stringstream ss;
//ss << "HTTP/1.1 404 Page Not Found\r\n";
//ss << "Content-Type: text/html\r\n";
//ss << "Content-Length: " << body.size() << "\r\n";
//ss << "\r\n";
//502
std::stringstream ss;
ss << "HTTP/1.1 502 Bad Gateway\r\n";
ss << "Content-Type: text/html\r\n";
ss << "Content-Length: " << body.size() << "\r\n";
ss << "\r\n";
//两个send是要发头部和正文
ssize_t send_size = send(new_sock, ss.str().c_str(), ss.str().size(), 0);
if(send_size < 0)
{
perror("send");
continue;
}
//正文
send_size = send(new_sock, body.c_str(), body.size(), 0);
if(send_size < 0)
{
perror("send");
continue;
}
}
close(new_sock);
close(listen_sock);
return 0;
}
- 虽然他是一个404,但是他也只是一个状态码而已,并不会妨碍我们想要看到的数据和文字
- 404不会干扰我们的服务端给我们的浏览器去传输数据的这样子一个功能


- 502状态码

给出httplib.h头文件所在的地址
- cpp-httplib.h下载链接
- 这个头文件其实不只是定义,是真正的进行了实现了
- header-only风格,是会将代码的定义和实现全部放在头文件当中的
- httplib库,可以快速的搭建一个http服务,首先要完成tcp连接的接收,然后完成http协议的解析,然后进行响应的回复
- server类是专门用来搭建http服务的一个类
#include <cstdio>
#include <iostream>
#include "httplib.h"
void http_callback(const httplib::Request& req, httplib::Response& resp)
{
(void)req;
//p1是用来放大字体的
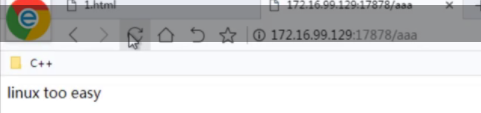
std::string body = "<html><p1>linux too easy</p1><html>";
//三个参数分别代表你要回的内容,以及你回复的内容有多长,以及你要回复的内容的类型
resp.set_content(body.c_str(), body.size(), "text/html");
}
int main()
{
httplib::Server svr; //定义一个server类这样子的对象
//如果想要去处理http请求的话,就需要去调用Get方法
//第一个参数是请求的路径
svr.Get("/aaa", http_callback);
svr.listen("0.0.0.0", 17878);
return 0;
}
- Handler是一个函数指针

负载均衡—nginx
- nginx(Engine x)是一个高性能的HTTP和反向代理服务器,并且因其稳定性、丰富的功能集、示例配置文件和低系统资源的消耗而闻名。其特点是占有内存少,并发能力强
- nginx采用C语言开发
nginx的安装
- 使用“su - root”命令切换到root用户
- 使用“yum list | grep nginx”命令, 查看当前yum是否有nginx安装包。如果使用上述命令, 得到如下输出, 则表示可以直接使用


- 安装成功, 则如下图

nginx目录
- 如果我们已经安装完成, 则nginx的目录在“/etc/nginx”下


- 其中,nginx.conf是nginx的主配置文件,还有若干个赋值的配置文件,都放在conf.d这个文件夹当中了,然后其中会有一个默认的conf文件

nginx的启动/关闭/重启/热加载配置文件
- 启动—systemctl start nginx,启动之后一般会有两个nginx进程,一个是nginx worker,一个是nginx master,使用stop停止之后就没有nginx进程了,就只剩一个grep了
- 停止—systemctl stop nginx
- 重启—systemctl restart nginx
- 热加载配置文件—nginx -s reload
nginx简单原理
- 前提知识-----守护进程
- 诞生缘由-----守护进程的提出源自于人们追求后台服务是7*24小时, 能够为客户提供服务(通常认为, 当服务器宕机则不能正常处理来自客户端的请求), 但是后台的应用程序也是程序员进行开发的, 没有办法保证代码无bug, 代码不会崩溃, 这点在C/C++的程序当中体会的尤为明显。 所以基于上面的需求和场景, 我们利用守护进程的方式, 保证后台服务进程在崩溃之后, 可以很快的被守护进程重新启动(通常也会有大神在讨论是说, 守护进程拉起来服务进程)
- 通常含义-----守护进程(Daemon Process),也就是通常说的 Daemon 进程(精灵进程),是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件;守护进程一般会脱离终端, 脱离终端是为了避免进程被任何终端所产生的信息所打断,其在执行过程中的信息也不在任何终端上显示。由于在 Linux 中,每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程都会自动关闭

- 先启动master进程,然后master进程回去创建出来一个worker进程,master是管理者,并不去处理具体的请求,而worker进程是干活的进程,是要去处理具体的请求的,换一个角度还可以理解成, 其实master进程是守护进程,然后worker进程是被守护进程,当被守护进程这个时候挂掉的话,我们的守护进程会再重新拉起来一个进程,那么我们如何去进行测验呢
- 首先,两个worker进程的进程号是并不一样的,然后现在我直接先去使用kill -9 去杀死一个进程

- 我们再kill一个工作进程之后,要看的是master进程会不会再拉起来一个工作进程
- kill之后我么发现进程号为51的进程已经没有了

- 然后我们还发现多出来了一个进程号为50160的进程,但是现在我们还需要去做的一件事情就是,我们需要去言这个这个进程号为50160的进程他的父进程到底是谁,如果是49950的话,那么就和我们之前所说的方式是一样的了,master进程会再拉起来一个进程

- 其实mysql后端的服务器也在用守护进程
- mysqld是守护进程

- kill掉之后依旧会重新拉起一个进程

子进程创建&进程程序替换&进程间通信

- 由于进程的独立性, 一旦替换完成, 则守护进程和子进程具有独立的进程地址空间,各自完成各自的事情。我们需要知道的是, 即使父子进程各自都是独立的, 但是守护进程(父进程)为了知道子进程是否正常工作, 父子进程需要不间断的进行进程间通信, 促使父进程“掌握”子进程的状态, 一旦子进程崩溃,或者非正常退出。 对于父进程而言, 需要立即重新启动子进程, 并且完成子进程程序替换为服务程序
nginx的进程模型
- nginx在启动后,在linux系统中会默认以守护进程(daemon)的方式在后台运行,后台进程包含一个master进程和多个worker进程,worker进程的数量可以在”nginx.conf“文件中进行配置

tcp连接管理
- 我们创建的tcp连接其实是和worker建立连接的,而不是和master建立连接的,那么现在就又有一个问题了,我该如何去分配tcp连接呢
- 我们先启动master进程,再去启动worker进程
- master进程侦听完毕之后,在文件描述符表中会多出来一个侦听描述符
- 每一个worker进程当中都具有了一个侦听套接字
- 三个worker进程之间其实是一个竞争的关系,三个进程谁能先从已完成连接队列中把东西拿出来,谁就可以讲其拿走
- 谁拿到了东西,谁就可以建立下一步的连接了

nginx反向代理http服务器
- 架构图如下:
- 假设说现在有一个浏览器,后台还有一个http服务器,本质上说,我在浏览器中可以直接去访问http服务器
- 先发数据到nginx,然后由nginx发送给http,然后http返回应答给nginx,然后nginx再给浏览器返回回去
- nginx其实控制了浏览器法国案例的数据到底给后台的哪个http服务器

创建一个http小项目(需要用到httplib.h)
#include <cstdio>
#include <cstring>
#include <iostream>
#include <string>
#include "httplib.h"
void http_callback_func(const httplib::Request& requ, httplib::Response& resp)
{
(void)requ;
std::string str = "<html><h1>84-linux</h1></html>";
resp.set_content(str.c_str(), str.size(), "text/html");
}
int g_count = 0;
int main(int argc, char* argv[])
{
if(argc != 3)
{
//num用来区分到底是哪一个http服务的
printf("using ./http_svr [port] [num]\n");
return 0;
}
uint16_t port = atoi(argv[1]);
std::string num = argv[2];
httplib::Server svr;
svr.Get("/aaa", [num](const httplib::Request& requ, httplib::Response& resp){
(void)requ;
char buf[1024] = {0};
snprintf(buf, sizeof(buf) - 1, "<html><h1>i am httpsvr : %s, i recv request num is : %d</h1></html>", num.c_str(), ++g_count);
resp.set_content(buf, strlen(buf), "text/html");
});
svr.listen("0.0.0.0", port);
return 0;
}















 3295
3295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









